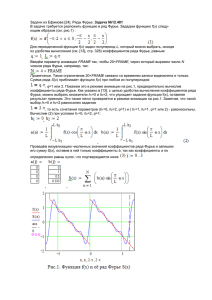
Аналитический подход к построению регрессионных моделей объектов
исследования предполагает возможность формализации физических
закономерностей протекающих в них процессов. Но для большинства
реальных объектов в виду их сложности такой подход не всегда возможен.
В этом случае может быть использован “экспериментальный” подход.
Если ошибками измерения выходов объектов, в виду их малости, можно
пренебречь, то задача построения регрессионных моделей сводится к задаче
выбора разложения выхода исследуемого объекта по соответствующим
базисным функциям 𝑢1 (𝑡), 𝑢2 (𝑡), . . . , 𝑢𝑛 (𝑡). Построенные таким способом
модели обычно называются имитационными.
При этом как в первом, так и во втором случаях математические модели
определяются с точностью до неизвестных параметров и учитывают только
существенные факторы, которые, по мнению разработчика модели, в
основном определяют поведение реальной системы.
Теоретическим обоснованием возможности проведения таких разложений
является следующая теорема, которая приводится без доказательства.
Теорема. Для того чтобы выход системы 𝑦(𝑡) мог быть представлен своим
разложением 𝑦(𝑡) = ∑∞
𝑛=1 𝑎𝑛 𝑢𝑛 (𝑡), где 𝑢1 (𝑡), 𝑢2 (𝑡), . . . , 𝑢𝑛 (𝑡), . .. система
ортонормированная функций, необходимо и достаточно, чтобы эта система
была полной.
Замечание. Такого рода разложения называются разложениями Фурье, а
коэффициенты an называются коэффициентами Фурье для yt по системе
функций 𝑢1 (𝑡), 𝑢2 (𝑡), . . . , 𝑢𝑛 (𝑡).
Определение №1. Система функций {𝑢𝑛 (𝑡)} называется полной, если не
существует функции 𝑢𝑛+1 (𝑡) отличной от нуля и ортогональной всем
функциям, образующим систему {𝑢𝑛 (𝑡)}.
Определение №.2. Система функций 𝑢1 (𝑡), 𝑢2 (𝑡), . . . , 𝑢𝑛 (𝑡)…, для которой
𝑏
0, для 𝑖 ≠ 𝑗
∫ 𝑤(𝑡)𝑢𝑖 (𝑡)𝑢𝑗 (𝑡)𝑑𝑡 = {
1, для 𝑖 = 𝑗
𝑎
называется ортогональной с весом 𝑤(𝑡).
Замечание
𝑏
∫𝑎 𝑤(𝑡)𝑢𝑖 (𝑡)𝑢𝑗 (𝑡)𝑑𝑡 = (𝑢𝑖 , 𝑢𝑗 ) называется скалярным произведением с весом
wt двух функций 𝑢𝑖 (𝑡) и 𝑢𝑗 (𝑡), определенных на промежутке [𝑎, 𝑏].
Следует отметить, что ортонормированные системы функций зависят как от
интервала a, b, на котором производится построение модели, так и от выбора
весовых множителей wt , придающих различную значимость ошибкам
модели. Кроме того, выбор ортонормированной системы в большой степени
определяет сложность получаемой модели и, следовательно, затраты на ее
реализацию.
Технология построения ортонормированной системы функций составляет
содержание теоремы ортогонализации Грама-Шмидта.
Теорема ортогонализации (Грама-Шмидта). Пусть 𝑥1 , 𝑥2 , . . . , 𝑥𝑛 ,… линейно
независимая система элементов. Тогда существует система 𝑢1 , 𝑢2 , . . . . , 𝑢𝑛 ,…,
удовлетворяющая условиям:
- система 𝑢1 , 𝑢2 , . . . . , 𝑢𝑛 ,… ортогональная и нормированная,
- каждый элемент 𝑢𝑛 представим в виде
𝑢𝑛 = 𝛼𝑛1 𝑥1 + 𝛼𝑛2 𝑥2 +. . . +𝛼𝑛𝑛 𝑥𝑛 ,
причем 𝛼𝑛𝑛 ≠ 0.
Доказательство
Будем искать элемент 𝑢1 в виде 𝑢1 = 𝛼11 𝑥1 , при этом 𝛼11 определяется из
условия
(𝑢1 , 𝑢1 ) = 𝛼11 2 (𝑥1 , 𝑥1 ) = 1.
Тогда
𝛼11 = ±
1
√(𝑥1 , 𝑥1 )
=±
1
1
=
.
‖𝑥1 ‖ 𝑏11
Пусть элементы 𝑢𝑘 (k < n), удовлетворяющие условиям теоремы, построены.
Тогда 𝑥𝑛 можно представить в виде 𝑥𝑛 = 𝑏𝑛1 𝑢1 +. . . +𝑏𝑛,𝑛−1 𝑢𝑛−1 + 𝑐𝑛 при
(k < n), где (𝑐𝑛 , 𝑢𝑘 ) = 0.
Действительно, соответствующие коэффициенты 𝑏𝑛𝑘 , а значит и элемент 𝑐𝑛 ,
однозначно определяется из условия
(𝑐𝑛 , 𝑢𝑘 ) = (𝑥𝑛 − 𝑏𝑛1 𝑢1 − ⋯ − 𝑏𝑛,𝑛−1 𝑢𝑛−1 , 𝑢𝑛 ) =
(𝑥𝑛 , 𝑢𝑘 ) − 𝑏𝑛𝑘 (𝑢𝑘 , 𝑢𝑘 ) = 0.
Очевидно, что (𝑐𝑛 , 𝑐𝑛 ) > 0, поскольку предположение
противоречило бы линейной независимости 𝑥1 , 𝑥2 , . . . , 𝑥𝑛 .
Положим
𝑐𝑛
𝑐𝑛
𝑢𝑛 =
=
√(𝑐𝑛 , 𝑐𝑛 ) ‖𝑐𝑛 ‖
(𝑐𝑛 , 𝑐𝑛 ) = 0
но тогда нетрудно понять, что поскольку cn выражается через xn , то и 𝑢𝑛
выражается также через 𝑥𝑛 .
Переход от системы 𝑥1 , 𝑥2 , . . . , 𝑥𝑛 к системе 𝑢1 , 𝑢2 , . . . , 𝑢𝑛 ,… называется
процедурой ортогонализации.
2
Определение №.3 Ряд называется полным, если y(t) можно представить без
ошибки бесконечным числом его членов.
Приведем несколько примеров построения регрессионных моделей
объектов, использующего различные системы ортонормированных функций.
В качестве системы функций 𝑥1 (𝑡), 𝑥2 (𝑡), . . . , 𝑥𝑛 (𝑡) выбираются функции
1, 𝑡, 𝑡 2 , . . . , 𝑡 𝑛 , . .., линейные комбинации которых образуют некоторые
степенные относительно t полиномы.
Пример №.1. Пусть состояние объекта описывается функцией 𝑦(𝑡), 𝑡 ∈ [0, ∞),
а при построении модели должны полностью учитываться ошибки
аппроксимации при 𝑡 = 0.
Решение
В качестве весовой функции 𝑤(𝑡) может быть взята функция 𝑤(𝑡) =
𝑒𝑥𝑝{−𝑡}., которая при больших значениях t уменьшает влияние разности
𝑦(𝑡) − 𝑠𝑛 (𝑡) на ошибку аппроксимации, где 𝑠𝑛 (𝑡) = ∑𝑛𝑘=0 𝑎𝑘 𝑢𝑘 (𝑡).
Эта система с помощью процедуры Грама-Шмидта ортогонализируется
относительно скалярного произведения
∞
(𝐿𝑖 (𝑡), 𝐿𝑗 (𝑡)) = ∫0 𝐿𝑖 (𝑡)𝐿𝑗 (𝑡) 𝑒𝑥𝑝{−𝑡} 𝑑𝑡,
где
𝐿𝑖 (𝑡)- полиномы, называемые полиномами Лагерра.
Из условий ортогональности
∞
∫0 𝐿𝑖 (𝑡)𝐿𝑗 (𝑡) 𝑒𝑥𝑝{−𝑡} 𝑑𝑡 = 0,
и условия нормирования
∞
∫ 𝐿𝑗2 (𝑡) 𝑒𝑥𝑝{−𝑡} 𝑑𝑡 = 1.
0
строятся полиномы Лагерра.
Последовательно находим эти полиномы.
Для j = 0 имеем 𝐿0 (𝑡) = 1.
Для 𝑗 = 1, 𝐿1 (𝑡) = 𝑎𝑡 + 𝑏 имеем
∞
∫ 1 ⋅ (𝑎𝑡 + 𝑏) 𝑒𝑥𝑝{−𝑡} 𝑑𝑡 = 0;
0
3
i≠j
∞
∫ (𝑎𝑡 + 𝑏)2 𝑒𝑥𝑝{−𝑡} 𝑑𝑡 = 1
и, следовательно,
0
𝐿1 (𝑡) = −𝑡 + 1.
Для j = 2
1
𝐿2 (𝑡) = 𝑡 2 − 2𝑡 + 1
2
и вообще для j = n
1
𝑑𝑛 𝑛
𝐿𝑛 (𝑡) = 𝑒𝑥𝑝{−𝑡} (𝑡 𝑒𝑥𝑝{−𝑡}).
𝑛!
𝑑𝑡
Тогда разложение 𝑠𝑛 (𝑡) = ∑𝑛
- неизвестный
𝑘=0 𝑎𝑘 𝐿𝑘 (𝑡), где 𝑎𝑘
коэффициент, может быть, в силу доказанного утверждения, выбрано в
качестве регрессионной модели системы.
Действительно, если измерения выхода объекта проводить в моменты времени
𝑡𝑖 ∈ [0, ∞), i 1,2,..., m , то элементами матрицы C будут значения полиномов
Лагерра в указанные моменты времени.
Проведем теперь анализ возникающих ошибок аппроксимации с
использованием полиномов Лагерра. Для этого рассмотрим простейший
пример.
Пример №2. Построить модель объекта, используя только первые четыре
полинома Лаггера, если ее состояние описывается функцией 𝑦(𝑡) = 𝑒𝑥𝑝{−𝑡}..
Решение
Коэффициенты разложения, вычисляемые по правилу
∞
1
1
1
1
𝑎𝑛 = ∫0 𝑦(𝑡)𝐿𝑛 (𝑡) 𝑒𝑥𝑝{−𝑡} 𝑑𝑡, имеют вид 𝑎0 = , 𝑎1 = , 𝑎2 = , 𝑎3 = .
2
4
8
16
Тогда
1
1
1 1
1
1
3
𝑒𝑥𝑝{−𝑡} ≈ ⋅ 1 + (−𝑡 + 1) + ( 𝑡 2 − 2𝑡 + 1) + (− 𝑡 3 + 𝑡 2 − 3𝑡 + 1)
2
4
8 2
16 6
2
15 11
5 2
1 3
=
− 𝑡++ 𝑡 − 𝑡 .
16 16
32
96
Заметим, что разложение этой функции в ряд Тейлора, учитывающего первые
четыре члена, имеет вид
1
1
𝑒𝑥𝑝{−𝑡} ≈ 1 − 𝑡 + 𝑡 2 − 𝑡 3 .
2
6
Значения этих частичных сумм, например, при t = 2 для разложения по
полиномам Лагерра 𝑠4 (2) = 0,1042, а для разложения Тейлора 𝑠4 (2) =
−0,333 в то время как 𝑒𝑥𝑝{−2}=0,1353.
4
Пример №3. Пусть состояние объекта описывается функцией yt , 𝑡 ∈
(−∞, ∞), а при построении модели должны учитываться ошибки при 𝑡 = 0. В
качестве весовой функции w(t) можно использовать функцию 𝑤(𝑡) =
𝑒𝑥𝑝{−𝑡 2 }. Поскольку выбранная функция является четной, то наибольший вес
она будет придавать ошибкам, возникающим при достаточно малых t.
Решение
В качестве системы функций 𝑥1 (𝑡), 𝑥2 (𝑡), . . . , 𝑥𝑛 (𝑡), … используется система
1, 𝑡, 𝑡 2 , . . . , 𝑡 𝑛 , …
Эта система ортогонализируется относительно скалярного произведения
∞
(𝐻𝑖 (𝑡), 𝐻𝑗 (𝑡)) = ∫−∞ 𝐻𝑖 (𝑡)𝐻𝑗 (𝑡) 𝑒𝑥𝑝{−𝑡 2 } 𝑑𝑡,
где 𝐻𝑖 (𝑡) полиномы, называемые полиномами Эрмита.
Из условий ортогональности
∞
∫−∞ 𝐻𝑖 (𝑡)𝐻𝑗 (𝑡) 𝑒𝑥𝑝{−𝑡 2 } 𝑑𝑡 = 0,
и нормирования
𝑖 ≠ 𝑗,
∞
∫−∞ 𝐻𝑗2 (𝑡) 𝑒𝑥𝑝{−𝑡 2 } 𝑑𝑡 = 1
находятся ортонормированные полиномы Эрмита.
1
∞
Для j=0 из ∫−∞ 𝐻𝑗2 (𝑡) 𝑒𝑥𝑝{−𝑡 2 } 𝑑𝑡 = 1 имеем 𝐻0 (𝑡) = 𝜋 −4 .
1
Для j=1 соответственно имеем 𝐻1 (𝑡) = √2𝜋 −4 𝑡
Вообще для j = n
𝐻𝑛 (𝑡) =
(−1)𝑛
√2𝑛 𝑛! √𝜋
𝑒𝑥𝑝{−𝑡
2}
𝑑𝑛
𝑒𝑥𝑝{−𝑡 2 }
𝑛
𝑑𝑡
∞
𝑎𝑗 = ∫ 𝑓(𝑡)𝐻𝑗 (𝑡) 𝑒𝑥𝑝{−𝑡 2 } 𝑑𝑡.
−∞
5
Пример №4. Построить модель системы, использующую три первых
полинома Эрмита, если состояние системы описывается функцией
𝑒𝑥𝑝{−𝑡 2 } , 𝑡 > 0,
𝑦(𝑡) = {
0, 𝑡 < 0.
Решение
Первые три коэффициента имеют вид
∞
𝑎0 = ∫
0
∞
𝑎1 = ∫
1
1
𝑒𝑥𝑝{−𝑡 2 } 𝜋 −4 𝑒𝑥𝑝{−𝑡 2 } 𝑑𝑡 =
𝜋4
2√2
,
1
−
1
4
𝜋
𝑒𝑥𝑝{−𝑡 2 } √2𝜋 −4 𝑡 𝑒𝑥𝑝{−𝑡 2 } 𝑑𝑡 =
,
2
0
∞
1
𝑎2 = ∫ 𝑒𝑥𝑝{−𝑡 2 } (√2𝜋 −4 𝑡 2 −
0
1
𝜋
= (2−4 − 1).
4
1
√2
1
𝜋 −4 ) 𝑒𝑥𝑝{−𝑡 2 } 𝑑𝑡
Тогда математической моделью будет
𝑒𝑥𝑝{−𝑡 2 } ≈ −0,188𝑡 3 − 0,0567𝑡 2 + 0,563𝑡 + 0,382..
При больших значениях t аппроксимация рядом Тейлора хуже, чем
аппроксимация полиномами Эрмита.
Замечания
1) Полиномы Эрмита широко используются также и в математической
статистике по следующим причинам: во-первых, функции определяются на
интервале (−∞, ∞) и, во-вторых, функция 𝑤(𝑡) = 𝑒𝑥𝑝{−𝑡 2 } идентична
функции нормального закона распределения и, следовательно, уже первый
член разложения дает хорошее приближение для распределений близких к
нормальным.
2) Если y(t) определена на (-1,1), а аппроксимация осуществляется при условии
1
минимума интегральной квадратичной ошибки с весовой функции
, то
1 t2
система
функций
1, 𝑡, 𝑡 2 , . . . , 𝑡 𝑛 , . ..
порождает
множество
ортонормированных полиномов
𝑇0 (𝑡) =
1
√𝜋
,
6
2
𝑇1 (𝑡) = √ 𝑡,
𝜋
8
1
𝑇2 (𝑡) = √ (𝑡 2 − ),
𝜋
2
32
3
𝑇3 (𝑡) = √ (𝑡 3 − 𝑡),
𝜋
4
………………………….
2
𝑇𝑛 (𝑡) = √ 𝑐𝑜𝑠 𝑡 (𝑛 𝑎𝑟𝑐𝑐𝑜𝑠 𝑡), 𝑛 ≥ 1
𝜋
1
𝑎𝑛 = ∫ 𝑦(𝑡)𝑇𝑛 (𝑡)
−1
𝑑𝑡
√1 − 𝑡 2
,
которые называются полиномами Чебышева. Несмотря на то, что полиномы
Чебышева получаются из условия наилучшей аппроксимации y(t) при
минимуме интегральной среднеквадратичной ошибки с весовой функцией
wt
1
1 t 2
, аппроксимация с помощью этих полиномов дополнительно
минимизирует максимальное отклонение 𝑠𝑛 (𝑡) от истинных значений y(t).
3) Существует еще одна, хорошо Вам известная, система функций. Такой
системой на промежутке [0, 2𝜋] является система 1, Sint, Cost, Sin2t,
Cos2t,…, Sin nt, Cosnt,…
В этом случае приходим к классическому в инженерном понимании
разложению в ряды Фурье. Однако использование таких систем функций не
всегда приводит к желаемым результатам. Так, например, разложение
импульсного выхода возникает эффект, называемый эффектом Гиббса. Он
состоит в том, что любая частичная сумма 𝑆𝑚 (𝑡) ряда Фурье превосходит
максимальное значение y(t) приблизительно на 18% вблизи точек разрыва y(t).
Для исключения возникновения такого эффекта используется специальная
система функций, называемых вейвлетами. В настоящее время теория
вейвлетов используется в различных прикладных задачах связанных с
математической обработкой измерений, например, для обработки
видеоизображений.
При использовании экспериментального подхода задача построения
регрессионной модели объекта сводится к задаче аппроксимации результатов
измерения, содержащих некоторые случайные ошибки.
7
Пример №.5 Построение модели тарировочной (статической) характеристики
датчика первичной информации, учитывающей ошибки измерения является
типичной аппромаксимационной задачей.
Решение.
Как уже показывалось, тарировочная характеристика датчика задается
моделью вида
𝑧̃ = 𝐶𝜃 + 𝜉,
где
- векторный параметр, образованный коэффициентами
аппроксимирующего полинома,
T вектор ошибок измерений.
Поскольку, этот параметр не имеет физической интерпретации, то по
определению, эта модель является регрессионной непараметрической
моделью.
Замечание
При рассмотренном подходе к построению регрессионных математических
моделей объектов исследования наибольший интерес представляет задача о
наилучшей аппроксимации yt рядом Фурье содержащим конечное число
членов.
Она важна потому, что ее решение определяет, во-первых, затраты на
реализацию такой модели и, во-вторых, степень соответствия модели
реальному объекту.
С математической точки зрения эта задача эквивалентна задаче
исследования сходимости частичных сумм ряда Фурье. При этом возникает
вопрос о совпадении пределов частичных сумм с 𝑦(𝑡) , 𝑡 ∈ [𝑎, 𝑏].
Пусть при построении регрессионных моделей допустимо использовать m
членов ряда Фурье 𝑠𝑚 (𝑡) = ∑𝑚
𝑛=1 𝛼𝑛 𝑢𝑛 (𝑡).
Требуется подобрать так коэффициенты n , чтобы ‖𝑦(𝑡) − 𝑠𝑚 (𝑡)‖2 была
бы минимальной.
Другими словами, искомые 𝛼𝑛 должны являться решением экстремальной
задачи
𝛼𝑛 = 𝑎𝑟𝑔 𝑚𝑖𝑛 ‖𝑦(𝑡) − 𝑠𝑚 (𝑡)‖2 .
𝛼
Итак
𝑏
𝑏
𝑚
2
‖𝑦(𝑡) − 𝑠𝑚 (𝑡)‖2 = ∫ [𝑦(𝑡) − 𝑠𝑚 (𝑡)]2 𝑑𝑡 = ∫ [𝑦(𝑡) − ∑ 𝛼𝑛 𝑢𝑛 (𝑡)] 𝑑𝑡
𝑎
𝑏
𝑎
𝑚
𝑏
𝑛=1
𝑚
= ∫ 𝑦 2 (𝑡)𝑑𝑡 − 2 ∑ 𝛼𝑛 ∫ 𝑦(𝑡)𝑢𝑛 (𝑡)𝑑𝑡 + ∑ 𝛼𝑛2 .
𝑎
𝑛=1
8
𝑎
𝑛=1
𝑏
Поскольку 𝑎𝑛 = ∫𝑎 𝑦(𝑡)𝑢𝑛 (𝑡)𝑑𝑡, а система функций 𝑢1 (𝑡), 𝑢2 (𝑡), . . . , 𝑢𝑛 (𝑡), . ..
ортонормированная, то
𝑏
𝑚
2
‖𝑦(𝑡) − 𝑠𝑚 (𝑡)‖2 = ∫𝑎 𝑦 2 (𝑡)𝑑𝑡 + ∑𝑚
𝑛=1 𝑎𝑛 − 2 ∑𝑛=1 𝑎𝑛 𝛼𝑛 +
𝑏
𝑚
𝑚
𝑚
2
2
2
2
2
∑𝑚
𝑛=1 𝛼𝑛 − ∑𝑛=1 𝑎𝑛 = ∫𝑎 𝑦 (𝑡) 𝑑𝑡 + ∑𝑛=1(𝑎𝑛 − 𝛼𝑛 ) − ∑𝑛=1 𝑎𝑛 =
𝑚
𝑚
‖𝑦(𝑡)‖2 + ∑ (𝑎𝑛 − 𝛼𝑛 )2 − ∑ 𝑎𝑛2 .
𝑛=1
𝑛=1
Так как ‖𝑦(𝑡) − 𝑠𝑚 (𝑡)‖2 0, а в правой части полученного соотношения
только второе слагаемое зависит от 𝛼𝑛 и оно всегда неотрицательно, то
минимальное значение ‖𝑦(𝑡) − 𝑠𝑚 (𝑡)‖2 будет иметь место при 𝛼𝑛 = 𝑎𝑛 .
Таким образом, алгоритм вычисления коэффициентов рядов Фурье с
конечным числом его членов совпадает с классическим алгоритмом для рядов
с бесконечным числом его членов.
Выводы по разделу “Построение регрессионных моделей объектов
исследования”
Подведем теперь основные итоги по проблеме построения регрессионных
математических моделей объектов исследования:
1. Регрессионные математические модели строятся для установившихся
процессов, протекающих в объектах исследования при этом коэффициенты
этих моделей, являются неизвестными константами, оценки которых являются
результатом математической обработки измерений.
2. Решение проблемы построения математических моделей объектов
исследования связана с нахождением компромисса между простотой их
формализации и полнотой описания процессов, протекающих в объектах
исследования. При этом существенное значение приобретает выделение
существенных факторов, влияющих простоту их формализации.
3. При формировании математических объектов исследования обычно
используются два подхода:
аналитический, который связан с формализацией на подходящем
математическом языке физических законов, описывающих процессы
протекающие в объектах исследования. Такие модели строятся с
точностью до неизвестных параметров. Основным недостатком такого
подхода к построению математических моделей являются громоздкость
аналитического описания процессов, протекающих в сложных объектах.
9
экспериментальный, который связан с решением задачи аппроксимации
выхода объектов исследования “отрезками” разложения Фурье по
специально выбранным системам функций. При таком подходе не
требуются знания физических законов, которым подчиняются процессы
протекающие в объектах исследования. Получившиеся математические
модели определены с точностью до неизвестных коэффициентов
разложения Фурье. Основным недостатком такого подхода является
выполнение условия отсутствия ошибок измерений либо условия их
малости.
общность этих подходов к построению регрессионных моделей состоит
в том, что значения неизвестных параметров моделей являются
решением задачи математической обработки результатов измерений.
10