Рисунок 5. Компоненты модели Anchor Modeling - LMS
реклама

Правительство Российской Федерации
Федеральное государственное автономное образовательное
учреждение высшего профессионального образования
«Национальный исследовательский университет
«Высшая школа экономики»
Факультет Компьютерных наук
Департамент программной инженерии
ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА
по направлению 09.03.04 «Программная инженерия»
подготовки бакалавра
Система поддержки принятия решений
на основе темпорального хранилища данных
Портновой Ольги Николаевны
Студентки группы 402ПИ
____________
Научный руководитель
доцент, к.т.н
«____»__________ 2015 г.
Брейман Александр Давидович
____________
Москва, 2015
«____»__________ 2015 г.
Оглавление
Реферат .............................................................................................................................................................. 3
Abstract .............................................................................................................................................................. 4
Список сокращений ......................................................................................................................................... 5
Введение............................................................................................................................................................ 6
1
2
3
Обзор аналогов ....................................................................................................................................... 10
1.1
Корпоративная информационная фабрика Инмона ......................................................................... 11
1.2
Хранилище с архитектурой шины Кимбалла ................................................................................... 14
1.3
Архитектура Data Vault ...................................................................................................................... 17
1.4
Выводы по аналогам ........................................................................................................................... 20
Предлагаемое решение .......................................................................................................................... 22
2.1
Основные характеристики Anchor Modеling .................................................................................... 22
2.2
Описание модели Anchor Modeling ................................................................................................... 23
2.3
Особенности темпоральности ............................................................................................................ 25
2.4
Физическая интерпретация модели ................................................................................................... 28
2.5
Обработка NULL-значений в хранилище ......................................................................................... 30
2.6
Вопросы производительности............................................................................................................ 30
2.7
Преимущества методологии............................................................................................................... 32
2.8
Область применения методологии .................................................................................................... 34
Реализация СППР ................................................................................................................................... 35
3.1
Выбор инструментов решения ........................................................................................................... 35
3.2
Создание источника данных .............................................................................................................. 36
3.3
Создание темпорального хранилища данных................................................................................... 49
3.4
ETL-модуль .......................................................................................................................................... 61
3.5
Создание многомерной виртуальной витрины ................................................................................. 65
3.6
Встраивание инструмента визуализации данных ............................................................................ 67
Заключение ..................................................................................................................................................... 68
Список использованных источников ........................................................................................................... 69
2
Реферат
Количество страниц отчета
70
Количество глав
3
Количество иллюстраций
35
Количество таблиц
2
Количество источников
23
Количество приложений
3
Ключевые слова: Бизнес-аналитика, BI, ХД, decision support system, СППР, Anchor
Modeling, шестая нормальная форма, темпоральное хранилище данных, OLAP, звезда, 3NF,
Data Vault.
Объектом разработки выпускной квалификационной работы является система поддержки
принятия
решений,
предназначенная
для
интеллектуального
хранения
слабо
структурированных данных больших объемов с целью извлечения из них важной для
аналитики информации и своевременного предоставления ее лицам, принимающим
стратегические решения. Ключевым компонентом системы является хранилище данных.
Область изучения хранилищ данных сложная
и стремительно развивающаяся. Однако
недостаток поддержки темпоральности (данных, зависящих от времени) является актуальной
проблемой, которая до сих пор остается не глубоко изученной и нерешенной.
Целью работы является реализация системы, основанной на темпоральном хранилище
данных, позволяющем отслеживать историю изменения данных, а также быстро изменять
структуру данных в условиях постоянных модификаций бизнес логики компании.
В данной работе представлен анализ существующих архитектур систем, выявлены их
достоинства и недостатки. Также подробно рассмотрены особенности построения
темпорального хранилища данных по инновационной методологии Anchor Modeling,
предлагающей создание модели в 6NF.
Результатом
работы
является
система
на
основе
темпорального
хранилища,
представляющего из себя гибкую легко расширяемую модель, хранящую все версии
темпоральных данных независимо друг от друга. Также модель позволяет быстро изменять
структуру данных, подстраиваясь под новые бизнес требования, исключая необходимость
полного перепроектирования.
Дальнейшая работа может быть направлена на внедрение системы в реальной
организации,
а
также
улучшение
функциональности
путем
встраивания
мощных
аналитических инструментов, обладающих возможностью проведения интеллектуального
анализа данных.
3
Abstract
Key words: Business intelligence, BI, data warehousing, decision support system, DSS, Anchor
Modeling, 6NF, temporal data warehouse, OLAP, star schema, 3NF, Data Vault.
The object of this graduate qualification work is primarily a decision support system. It refers to a
system dealing with utilization of unstructured data and further analysis in order to resolve
problems, predict trends, and help people make the right decisions. The data warehouse is the root
of the system. Data warehousing is a complex field which is evolving rapidly. Despite the large
body of knowledge on data storing techniques for decision support, there has been a notable gap in
research related to tracking changes in data structure. This issue has been brought forefront, because
unhandled changes in a structure of a data warehouse directly affect the accuracy of the data
extracted from a report.
The chief purpose of this work is to provide a solution to the problem noted earlier – to develop
the decision support system based on the temporal data warehouse that stores all states of the data
structure preventing the system from the loss of information. The data warehouse also should
represent a model that can be easily modified under conditions of constant changes of business
requirements.
The work is structured as follows. The first section puts forward an analysis of related works; it
consists of three subsections. In the next section the basic theory of the proposed methodology
Anchor Modeling is described. Finally, main features of implementation are presented in the last
section.
Thus, the result of the work is the decision support system which provides the opportunity of
remaking queries depending on the concrete period of time without information loss. Consequently,
the modification of the data structure does not lead to redesigning the whole system; this is one of
the most essential competitive advantages of the system.
Practical applicability of such system is relatively wide, especially in those areas where business
processes are changing constantly and tracking historical changes has indeed high importance. The
future work may focus on the system rollout in a company and also the functional improvements of
the system by embedding analytical tools for data mining.
4
Список сокращений
БД – База данных
ИЭ – Информационная экосистема
КИФ – Корпоративная Информационная Фабрика
НИУ ВШЭ – Национальный исследовательский университет «Высшая школа экономики»
СППР – Система поддержки принятия решений
СУБД – Система управления базами данных
ХД – Хранилище данных
BI – Business Intelligence
BPMN – Business Process Model and Notation
DV – Data Vault
ETL – Extract Transform Load
ER – Entity Relationship
KPI – Key Performance Indicator
OLAP – Online Analytical Processing
5
Введение
В последнее время является все более очевидным тот факт, что современный бизнес не
может нормально функционировать без анализа данных. Все чаще в IT-сфере стал звучать
термин «Big Data», подразумевающий управление данными очень большого размера и
разнородного состава, часто обновляемых и требующих обработки во времени близком к
реальному. Действительно, значительное число больших компаний хранит в своих базах
огромные объемы данных, нуждающихся в аналитической обработке, объем которых
достигает терабайты. Со временем стало понятно, что интеллектуальное хранение данных и
их дальнейшее использование является одним из ключевых аспектов успешной деятельности
компании [19].
С развитием информационных технологий применение систем бизнес-аналитики стало
широко распространенной практикой не только во многих областях бизнеса (торговля,
банки), но и в сфере здравоохранения, страхования, транспорта, телекоммуникаций,
промышленности и т.д. До сих пор нет одного четкого определения для термина бизнесаналитика. В данной работе под бизнес-аналитикой (Business Intelligence) понимается набор
техник и инструментов, используемый для преобразования большого объема разнородных
неструктурированных данных с дальнейшим проведением анализа с целью обнаружения
проблем, скрытых зависимостей, а также прогнозирования [18].
В частности, BI включает в себя: инструменты для извлечения и трансформации данных
(ETL), хранилища данных (ХД) (data warehousing), инструменты визуализации (dashboarding)
и создания отчетности (reporting), генерации нерегламентированных отчетов «на лету» (adhoc), инструменты для многомерного анализа (OLAP), интеллектуального анализа (data
mining) и оценки производительности бизнеса (KPI).
Более узкое определение данного
понятия заключает, что бизнес-аналитика есть совокупность процессов, направленных на
извлечение знаний из данных и их последующий анализ [18].
Основная цель BI систем – предоставление своевременной и качественной информации,
способствующей принятию стратегически правильных решений по эффективному контролю
и управлению компанией. Таким образом, BI системы являются важнейшим конкурентным
преимуществом
организации,
ведь
в
условиях
постоянно
меняющихся
реалий
благоприятный исход зависит именно от того, как быстро удается адаптироваться как к
негативным, так и к позитивным изменениям [15].
Объектом внимания данной работы является такая разновидность систем BI, как система
поддержки принятия решений (Decision Support System). По сути, СППР является
синонимичным понятием для системы BI, но BI есть более широкое понятие. В данном
6
случае, СППР можно определить как гибкую информационно-аналитическую систему,
разработанную для управления неструктурированными или слабоструктурированными
задачами для улучшения процесса принятия решений. Отметим следующие характеристики
СППР [14]:
1. СППР создаются не для автоматизации принятия решений, а для их поддержки.
2. СППР поддерживают принятие решений, сопоставляя вместе оценку эксперта и
вычислительные итоги
3. СППР объединяют в себе как данные, так и модели.
4. СППР создаются для прямого взаимодействия с лицом, принимающим решение.
Существует множество критериев для классификации СППР. Далее рассмотрены виды
СППР, различающиеся по способу поддержки [14]:
1. Управляемые документами (Document-driven DSS)
2. Управляемые коммуникациями (Communication-driven DSS)
3. Управляемые данными (Data-driven DSS)
4. Управляемые моделями (Model-driven DSS)
5. Управляемые знаниями (Knowledge-driven DSS)
В данной работе рассмотрена управляемая данными СППР, ориентированная на
манипуляции с историческими данными организации и проведение анализа данных для
принятия решений. Говоря о структуре СППР, необходимо перечислить основные
компоненты системы:
1. Источник данных (data source) – как правило, реляционная база данных или иная
учетная система, где данные представлены в «сыром» виде.
2. Модуль ETL (extract transform load) – блок, где происходит очистка, преобразование и
загрузка данных в ХД.
3. Хранилище данных (data warehouse) – блок хранения данных, представляющий
специальный репозиторий, хранящий интегрированную информацию из разнородных
источников данных как в атомарном, так и в агрегированном виде.
4. Модуль анализа – блок, в котором используются инструменты для различного анализа
данных. В данной работе рассматривается OLAP-анализ (Online Analytical Processing)
5. Отчетность (необязательный модуль) – блок, в котором формируются результаты
анализа для демонстрации значимых данных конечному пользователю.
7
Взаимосвязь всех компонентов СППР представлена на рисунке 1:
Рисунок 1. Общая схема СППР [23].
Поскольку ХД является ключевым компонентом СППР, в данной работе особое место
выделено принципам построения ХД. Работы Кимбалла [9] и Инмона [4] лежат в основе
учений о ХД. Методология Линстедта [11] менее известена, но также рассмотрена. Тем не
менее, внимание современных разработчиков привлекает инновационная методология
Ронбека [17], рассматриваемая в условиях Big Data как наиболее подходящее средство для
достижения целей, поставленных в этой работе.
Область изучения ХД сложная
и стремительно развивающаяся. Однако недостаток
поддержки темпоральности (данных, зависящих от времени) и отслеживания исторических
изменений является актуальной проблемой, которая до сих пор остается не глубоко
изученной и нерешенной.
Этот вопрос выдвинут на первый план, потому что отсутствие отслеживания изменений в
данных и в их структуре напрямую влияет на точность информации, получаемой в отчете в
результате анализа. Более того, изменения в структуре ведут к перепроектированию всей
схемы и повторной загрузке данных в ХД. Поскольку все изменения должны быть вовлечены
8
в дальнейший анализ, только отслеживание исторических изменений позволит конечному
пользователю получить от СППР корректные результаты за конкретный период времени.
Основные цели данной работы заключаются в предоставлении решения проблемы,
описанной выше, а именно:
1. Обеспечить руководство компании/аналитический отдел корректной оперативной
информацией о текущем состоянии компании для оптимизации процесса принятия
решений.
2. Обеспечить хранение данных компании в темпоральном ХД, позволяющем
отслеживать историю изменения данных, а также быстро изменять структуру
данных в условиях постоянных модификаций бизнес логики компании.
Результат работы можно достигнуть, выполнив ряд следующих задач:
1. Проанализировать источник данных, построить диаграмму бизнес-процессов,
спроектировать и создать учетную реляционную базу.
2. Спроектировать
и реализовать темпоральное ХД, используя выбранную
методологию.
3. Выполнить очистку, трансформацию и загрузку (ETL) данных из источника в ХД.
4. Спроектировать и построить многомерную виртуальную витрину данных поверх
ХД для OLAP-анализа.
5. Обеспечить проведение анализа путем встраивания инструмента визуализации
данных, полученных из темпорального ХД.
Данная работа структурирована таким образом: в первой главе идет обзор аналоговых
архитектур СППР; во второй главе описана предлагаемая методология для достижения
поставленной цели; третья глава посвящена техническим деталям реализации СППР; в
заключении подводятся итоги проделанной работы.
9
1 Обзор аналогов
В данной главе описаны три основных вида архитектур построения ХД в порядке их
появления. Далее следует краткая справка об истории возникновения ХД.
Концепция ХД была впервые упомянута спустя два десятка лет после создания СУБД в
1960х годах и считается относительно новой в области баз данных и аналитики.
Возникновение ХД можно связать с потребностью получения точных агрегированных
корпоративных данных, интегрированных из различных источников. В 1988 в журнале IBM
Systems Journal в статье Барри Девлина впервые упомянут термин «информационное
хранилище» (information warehouse). Однако «отцом-основателем» ХД считается Билл
Инмон, опубликовавший в 1991 году свою книгу «Building the Data Warehouse» [7].
После выхода книги модель Инмона стала активно использоваться индустрией.
Остальные разработчики баз данных также начали создавать ХД. Основной конкурентной
моделью стала архитектура Ральфа Кимбалла, описанная в его работе «The Data Warehouse
Toolkit» в 1996 году. Отметим, что методологии значительно отличаются друг от друга,
однако оба совершенствуются, используются до сих пор и считаются классическими
методологиями для создания СППР [5].
Методология Дэна Линстедта [11], появившаяся в 2000 году, предполагает наличие
гибридной архитектуры, совмещающим главные черты моделей Инмона и Кимбалла, также
известных под названиями 3NF (третья нормальная форма) и Star Schema (схема Звезда).
Далее аналоги рассмотрены более детально. В ходе небольшого анализа выявлены
достоинства и недостатки каждого из них друг перед другом, а также определено, возможно
ли решить проблему, заявленную в данной работе, используя эти подходы к построению
СППР.
10
1.1 Корпоративная информационная фабрика Инмона
Модель Инмона стала первой созданной моделью ХД. По Инмону [4], ХД это предметноориентированная, интегрированная, неизменяемая, отслеживаемая во времени коллекция
корпоративных данных, созданная для поддержки принятия решений.
Разберем указанные характеристики ХД подробней. Предметная ориентированность
подразумевает, что данные, касающиеся определенных объектов в предметной области,
организованы в базе едиными сущностями. В качестве примера можно привести такую
бизнес-область как Торговля, где компонентами предметной области будут являться
Покупатель, Поставщик, Продукт и т.д [4].
Инмон считает, что самая важная характеристика ХД это интегрированность. Несмотря на
тот факт, что неструктурированные данные попадают в ХД из разнородных источников,
попадая в ХД, они трансформируются, форматируются, агрегируются и т.д. Поэтому ХД
представляет собой единый физический объект, который является консолидированным
представлением всего предприятия, включая все его департаменты [4].
Следующая немаловажная характеристика ХД это неизменяемость. Данные загружаются в
ХД и становятся доступными только для чтения. Невозможно удалить или обновить данные.
Каждый раз при новой загрузке делается статический снимок базы на определенный момент
времени. Когда происходят дальнейшие изменения, добавляется новый снимок. Таким
образом, ХД накапливает историю данных [4].
Последняя характеристика ХД по Инмону это отслеживаемость информации во времени.
Данные в ХД валидны на конкретный промежуток времени. Поэтому, чтобы получать
корректные данные из ХД, необходимо добавлять к определенным полям в таблицах
временные метки [4].
Переходя к рассмотрению непосредственно модели Инмона, определим, что же автор
понимает под Корпоративной Информационной Фабрикой. В первую очередь, определим
понятие Информационная Экосистема (ИЭ). Последнее является системой с различными
компонентами,
каждый
из
которых
обслуживает
сообщество,
взаимодействуя
непосредственно с другими компонентами, поддерживая сбалансированную связную
информационную среду. Адаптируемость, гибкость и баланс – три важнейших черты ИЭ.
Экосистема должна быстро адаптироваться к изменениям, преобразовываясь по мере
изменения ее компонентов, а также внешней среды. Баланс при этом также меняется, что
может способствовать обнаружению связей между ранее несвязными частями. ИЭ
обеспечивает контекст для понимания потребностей бизнеса и принятия мер для реализации
этих потребностей. Таким образом, ИЭ предоставляет предприятию комплексное решение,
11
поддерживающее все информационные процессы, основываясь на взаимодействии трех
главных компонентов: бизнес-операции, бизнес-аналитика, бизнес-менеджмент. Физическим
же представлением Информационной Экосистемы является Корпоративная Информационная
Фабрика (КИФ) [5].
Архитектура КИФ состоит из четырех основных уровней: операционный уровень, уровень
ХД с атомарными данными, уровень витрин данных и индивидуальный уровень.
Операционный уровень состоит из ежедневных примитивных транзакций, выполняемых в
высокопроизводительных операционных базах данных. Далее данные проходят процедуры
очистки, трансформации и попадают на следующий уровень – в нормализованное ХД
(построенное в третьей нормальной форме), которое хранит интегрированную, историческую
информацию, которая не может быть изменена или удалена. Далее в зависимости от
требований отдельных групп пользователей информация распределяется по следующему
уровню - витрин данных. Данные в каждой витрине агрегированы и подстроены под нужды
определенной бизнес-области. Тем не менее, вся информация, представленная в витринах,
является согласованной, поскольку данные поступают в витрины из единого ХД. Наконец, на
индивидуальном уровне конечные пользователи оперируют данными из ХД в рамках анализа
поддержки принятия решений [2].
Архитектура КИФ представлена на рисунке 2.
Рисунок 2. Корпоративная информационная фабрика [6].
Помимо архитектуры КИФ, рассмотрим принципы моделирования данных по Инмону.
Предложенный подход, по мнению самого автора, позволяет исключить нарушение
12
целостности
данных
в
витринах
департаментов.
Инмон
определяет
три
уровня
моделирования данных: диаграммы сущность-связь (ER), DIS-диаграммы (data-item set),
физические диаграммы. Самый верхний уровень это ER-диаграммы, определяющие
сущности, атрибуты и связи отдельно для каждой витрины департамента. DIS-диаграмма
среднего уровня является логическим продолжением ER-диаграммы, только содержит более
детальную информацию о сущностях, включая определение типов полей и выявление
ключей. Нижний уровень это физическая диаграмма, связанная с первыми двумя,
представляющая физическое расположение сущностей и связей в ХД. На данном уровне
представления данных также происходит процесс оптимизации модели с целью достижения
высокой
производительности.
В
частности,
это
может
быть
достигнуто
путем
денормализации таблиц [2].
Подводя краткие итоги по Инмону, перечислим достоинства и недостатки методологии. К
положительным чертам можно отнести [7]:
1. Физически единое ХД.
2. Целостность данных в витринах.
3. Нормализованное ХД способствует получению высокой степени детальности
данных.
4. ХД отражает деятельность всего предприятия в целом (подход «сверху-вниз»).
5. Возможность постепенного построения ХД (локально в витринах).
6. ВременнОе структурирование данных (наличие меток времени).
К отрицательным чертам можно отнести [7]:
1. Отсутствие прямого доступа к атомарным данным (при необходимости приходится
делать нетривиальный запрос к ХД через витрину).
2. Относительно медленное выполнение запросов ввиду нормализованности ХД.
3. Значительный объем ресурсов на создание и поддержание ХД.
4. Ориентирование на IT-специалистов при использовании, а не на «простых»
пользователей.
13
1.2 Хранилище с архитектурой шины Кимбалла
Перечислим критерии, которые Кимбалл выдвигает к ХД [9]:
1. ХД должно делать корпоративные данные легкодоступными.
Под
этим
понимается,
что
данные
должны
предоставляться
конечному
пользователю (не IT-специалисту) в понятном для него виде. Средства доступа к
ХД должны быть максимально простыми, а время ожидания результатов запросов
должно быть минимальным.
2. ХД должно предоставлять целостную корпоративную информацию.
Под этим понимается, что данные, извлеченные из ХД, должны быть
достоверными. Информация из одного бизнес-процесса должна коррелировать с
информацией из другого. Это также означает, что данные, поступающие из разных
источников в ХД, должны быть интегрированы, очищены и преобразованы.
3. ХД должно быть адаптивным к изменениям.
Под этим понимается, что ХД должно обрабатывать неизбежные изменения
бизнес-области не должны приводить к изменению уже существующих данных.
Все преобразования и добавления в ХД должны проводиться гибко.
4. ХД должно быть надежным местом для хранения ценной корпоративной
информации.
Под этим понимается, что ХД должно эффективно контролировать процесс
доступа к конфиденциальной корпоративной информации.
5. ХД должно служить основой для улучшения процесса принятия решений.
Под этим понимается, что данные, получаемые из ХД, являются основаниями для
принятия решений, поскольку они формируют показатели, которые влияют на
состояние бизнеса.
6. Предприятие должно принимать использование ХД, если действительно считает
его успешным.
Под этим понимается, что наличие СППР в компании напрямую не влияет на ее
успешное развитие. ХД можно рассматривать лишь как дополнительный
функционал, использование которого каждая компания решает сама для себя.
Рассмотрим принципы моделирования данных по Кимбаллу, поскольку они значительно
отличаются от стандартных принципов моделирования по Инмону. Отметим, что Кимбалл
представляет свой подход как «снизу-вверх», поскольку его модель ХД предполагает набор
14
витрин данных, каждая из которых характеризует определенный бизнес-процесс, а не
бизнес-объект, как в модели Инмона [2].
Все данные в модели разбиты на таблицы измерений и фактов. Факты представляют собой
таблицы, хранящие числовые показатели, характерные для определенных событий в бизнеспроцессе, например, Заказы, Платежи, Продажи и т.д. Значения показателей определяют
измерения – таблицы, обеспечивающие контекст события и отражающие данные о
конкретных бизнес-единицах, примерами которых могут служить Продукт, Покупатель,
Магазин. Поскольку показатели берутся на пересечении измерений, в их качестве могут
выступать такие метрики как количество, стоимость, процент и т.д. В добавление, нужно
указать, что измерения образуют иерархии, позволяющие анализировать данные различного
уровня агрегации. Например, измерение Время представляет собой иерархию: День – Неделя
– Месяц – Квартал – Год. Набор измерений, связанных с таблицей фактов, определяет
степень гранулярности (granularity) каждого факта [2].
Таким образом, модель такого вида позволяет пользователям получать информацию как
на верхнем агрегированном уровне, так и «проваливаться» вниз для более детального
рассмотрения. Более того, таблица фактов и прилежащие к ней измерения визуально
напоминают звезду, отсюда и название модели Кимбалла «звезда». Отличительной чертой
звезды является то, что данная модель предполагает денормализацию данных в измерениях с
целью увеличения скорости выполнения запросов [2].
Что касается архитектуры Кимбалла, то ее можно считать более простой, чем архитектуру
Инмона. Кимбалл определяет четыре компонента СППР: операционный источник, область
подготовки данных, область представления и пользовательская область. Под операционным
источником понимается наличие учетной системы, хранящей неструктурированные данные
и способной выполнять четыре базовые функции: SELECT, UPDATE, DELETE, and INSERT.
Из такой системы далее данные попадают в область подготовки данных, где происходит
обработка информации и дальнейшее преобразование в пригодный для грамотного хранения
вид. Основное требование к модулю подготовки данных это изолированность от
вмешательства бизнес пользователей, а также отсутствие возможности выполнения запросов
для анализа данных. После процедуры подготовки, организованные данные загружаются в
витрины данных, находящиеся на представительском уровне. Если по Инмону, витрина
данных – это часть ХД, то по Кимбаллу витрина – само ХД, причем представленное не
физическим объектом, а набором виртуальных витрин, использующих модель звезды с
согласованными измерениями (общими для каждого бизнес-процесса). Каждая витрина
основана на одном бизнес-процессе. Таким образом, удается избежать избыточной загрузки
повторных данных в ХД. Отметим, что ХД с архитектурой шин хранит в одном месте как
15
атомарные, так и суммарные данные. На последнем пользовательском уровне конечные
пользователи могут напрямую оперировать данными из витрин для проведения дальнейшей
аналитики [9].
Архитектура Кимбалла представлена на рисунке 3.
Рисунок 3. Хранилище данных с архитектурой шины [6].
Подводя краткие итоги для модели звезды, укажем достоинства и недостатки данной
методологии. К достоинствам можно отнести [7]:
1. Прямой доступ конечных пользователей к ХД.
2. Доступность использования (не только для IT-специалистов).
3. Виртуализация витрин (ХД не физический объект).
4. Простота реализации.
5. Высокая скорость выполнения запросов ввиду хранения атомарных и суммарных
данных вместе.
К недостаткам можно отнести [7]:
1. Отсутствие физически целостного репозитория данных.
2. Сложный процесс обработки изменений в ХД ввиду денормализации таблиц.
3. Изменение в ХД ведет к нарушению логики ETL-процессов.
16
1.3 Архитектура Data Vault
Перейдем к рассмотрению последнего аналога построения СППР, Data Vault (DV)
моделирования, который, в отличие от классических КИФ и звезды, считается современной
методологией проектирования ХД.
DV позиционируется как особая техника для построения крайне гибких, масштабируемых
и адаптивных моделей. Автор данной методологии, Линстедт, определил DV следующим
образом: ориентированный на детали, отслеживающий историю, уникально связный набор
нормализованных таблиц, поддерживающий одну или более бизнес-область [20].
DV представляет собой гибридную архитектуру, обладающую лучшими свойствами
моделей Инмона и Кимбалла. В отличие от последних двух, DV может обрабатывать
массивные наборы детализированных данных, занимая при этом значительно меньше
физического места. По Линстедту, его методология основана на математических принципах,
поддерживаемых нормализованными моделями данных. DV также свойственны такие
традиционные особенности моделей КИФ и 3NF, как стандартные структуры таблиц,
измерения и отношения многие-ко-многим. Отличие же DV от «классики» заключается в
организации связей, структуры полей, а также в хранении темпоральных данных [20].
Автор методологии заключает, что ХД должно быть спроектировано «сверху-вниз», а
реализовано «снизу-вверх», что позволит дизайну и архитектуре быть достаточно гибкими и
адаптивными для роста и изменения при постоянных переменах в процессах конкретной
бизнес области. Поскольку принципы моделирования корпоративных ХД остаются не
формализованными, что зачастую приводит к несоответствиям, усложняющим реализацию,
Линстедт утверждает, что именно DV определяет нормализацию моделирования, используя
техники отношения М-М, ссылочной целостности, минимальной избыточности. Эти техники
позволяют обеспечивать расширяемость, согласованность и итеративность модели [20].
Что касается архитектуры СППР по DV модели, то она сочетает в себе «начало» КИФ и
«конец» архитектуры шин. Операционный уровень, на котором хранятся сырые данные, и
подготовительный уровень, где происходят процессы обработки данных, аналогичны ранее
описанным моделям. Представительский уровень, на котором формируются виртуальные
витрины данных, и индивидуальный уровень, на котором конечные пользователи проводят
аналитику, также совпадают. Однако на уровне ХД, идущем вслед за подготовительным
уровнем, наблюдаются серьезные изменения, о которых рассказано далее.
DV модель имеет сильно нормализованную структуру. Она представляет бизнеспроцессы, соединенные между собой бизнес-ключами. Модель состоит из трех основных
компонентов: хабы (hubs), линки (links) и сателлиты (satellites). Хабы представляют собой
17
таблицы, хранящие наборы уникальных бизнес-ключей. Таблицы также содержат
дополнительные поля с метаданными, используемыми для отслеживания изменений:
искусственный ID, дата загрузки в ХД, источник данных. Примером хаба могут служить
такие сущности как Покупатель, Заказ, Счет и т.д. Хабы не содержат внешних ключей,
однако, между ними должны существовать связи. Это возможно благодаря второму
компоненту модели – линкам. Линки представляют собой ассоциации между двумя и более
хабами. Более того, линки предполагают реализацию М-М отношений в модели ХД. Данный
компонент составляет основу гибкости DV. Его составляющими полями являются:
искусственный ID, суррогатные ключи хабов, дата загрузки и источник данных. Линки не
должны хранить уникальные бизнес-ключи, поскольку это значительно усложнит процесс
загрузки в ХД. Последним компонентом является Сателлит, хранящий детальную
информацию о двух других компонентах. Задача сателлита – обеспечить контекст хабов и
линков.
Данная таблица состоит из искусственного ключа хаба или линка, который
определяет сателлит, даты загрузки, дату окончания, источника данных. Первичный ключ
сателлита определяет пара первых двух перечисленных атрибутов. Таким образом, сателлит
предоставляет информацию о бизнес ключах и связях, валидную на конкретный момент
времени или целый период. Опять же немаловажен факт, что сателлит не должен содержать
внешних ключей. По своей сути, сателлит близок к компоненту «измерение» в модели
Кимбалла, которое хранит изменения на детальном уровне и обеспечивает контекст бизнессобытия [11].
Общий план действий по построению модели DV выглядит следующим образом [20]:
1. Смоделировать хабы (выделить бизнес-ключи определенной бизнес-области).
2. Смоделировать сателлиты (проанализировать текущие бизнес-процессы).
3. Смоделировать линки (определите контекст ассоциаций бизнес-ключей и связей).
4. Смоделировать point-in-time таблицы, производные от таблиц сателлитов (с целью
отслеживания истории изменения данных).
18
Архитектура DV представлена на рисунке 4. Под компонентом нормализованное ХД
понимается модель DV с хабами, линками и сателлитами.
Рисунок 4. Архитектура Data Vault [8].
Подводя краткие итоги для модели DV, укажем достоинства и недостатки данной
методологии. К достоинствам можно отнести [11]:
1. Гибкая реализация ввиду нормализации модели.
2. Хорошая адаптируемость к изменениям бизнес-логики (расширяемость).
3. Отслеживаемость исторических изменений.
4. Направленность
на
уменьшение
избыточности
данных
и
увеличение
производительности.
К недостаткам можно отнести [11]:
1. Отсутствие прямого доступа к ХД, необходимость построения витрин данных.
2. Необходимость двойного выполнения ETL-процессов.
19
1.4 Выводы по аналогам
Обобщая сказанное в предыдущих подразделах, приведем сравнительную таблицу всех
трех рассмотренных методологий по основным критериям:
Таблица 1
Сравнение трех методологий создания СППР
Критерий
сравнения
КИФ
Звезда
Data Vault
Данные хранятся в
сильно
нормализованном
ХД, требующем
построения витрин
для запросов.
Данные хранятся в
неочищенном и
непреобразованном
виде. Структура ХД
приспособлена для
хранения слабо
согласованных
данных
ETL-процессы
необходимо
проводить дважды
(двойная загрузка
данных).
Первым грузится ХД
(хабы, потом линки,
потом сателлиты),
вторым загружаются
витрины данных
Хранение данных
Разграничение
хранения данных:
атомарные данные
хранятся в ХД 3NF,
суммированные
данные хранятся в
витринах.
Данные хранятся в
очищенном,
согласованном и
преобразованном
виде
Суммарные и
атомарные данные
хранятся совместно в
виртуальных
витринах,
построенных по
модели «звезда».
Данные хранятся в
очищенном,
согласованном и
преобразованном
виде
ETL процессы
ETL-процессы
необходимо
проводить дважды
(двойная загрузка
данных). Порядок
внутри загрузки
каждой таблицыисточника
определяется
зависимостями 3NF
ETL-процесс
выполняется один
раз: данные из
источника грузятся в
витрины. В первую
очередь грузятся
измерения, затем
факты
Очистка данных
Перед загрузкой
данных в ХД
Перед загрузкой
данных в ХД
Перед загрузкой
данных в Витрины
Данных
Моделирование
Трехуровневый
подход к
моделированию
(концептуальный,
промежуточный,
физический).
Используется подход
от бизнес-процессов
предприятия
Модель «звезды»:
таблица фактов с
набором связанных с
ней измерений.
Используется подход
от требований
пользователей к
анализу данных
Двух уровневый
подход (логическая
модель ХД,
физическая модель
ХД)
Используется подход
от источника данных
20
Критерий
сравнения
Целевая аудитория
Производительность
Отслеживаемость
изменения данных
Адаптивность к
изменениям
структуры
Гибкая методология
разработки
Восстановление
первоначальных
данных источника
данных из данных
ХД
КИФ
Звезда
Data Vault
IT-специалисты
Конечные
пользователи
(аналитики,
менеджеры)
Конечные
пользователи
(аналитики,
менеджеры)
Высокая
производительность
благодаря прямому
доступу как к
атомарным, так и к
суммарным данным в
витрине
Прямые запросы к
нормализованному
ХД крайне трудны,
наличие витрин в
увеличивает время
загрузки данных
Использование
концепции медленно
изменяющихся
измерений, чтобы
отследить
исторические
изменения
Исторические
изменения
отслеживаются
просто ввиду
наличия метаданных
в каждой таблице
компонентов
Изменение
требований и
масштабирование
критично
Сложная адаптация к
изменению ввиду
сильной
денормализации
модели
Адаптируемость к
изменениям
удовлетворительная в
силу расширяемости
модели и высокой
нормализации
Нет
Нет
Да
Нет
Нет
Да
Прямые запросы к
ХД 3NF занимают
большое кол-во
времени. Для
выполнения запросов
и создания
отчетности
необходимо наличие
витрин данных
Относительно
простая.
Наличие меток
времени для
отслеживания
времени валидности
данных, а также
времени транзакций
Итак, проанализированы три методологии создания СППР. Выбор методологии зависит от
ее способности выполнения конкретных задач. Возвращаясь к задачам данной работы,
отметим, что ни одна из архитектур в полной мере не удовлетворяет заданным требованиям.
Модели Инмона и Кимбалла не подходят по причине отсутствия возможности для быстрого
и гибкого изменения структуры данных. Архитектура DV, на первый взгляд, демонстрирует
приемлемую гибкость своей модели, но существенен факт сложных и длительных ETLпроцессов загрузки данных в ХД. Поэтому перейдем к следующему разделу данной работы
для рассмотрения особенностей и преимуществ Anchor Modeling - предлагаемой здесь
методологии для реализации СППР.
21
2 Предлагаемое решение
В данной главе подробно рассмотрена современная методология Anchor Modeling,
созданная в 2003 году шведской группой разработчиков во главе с Ларсом Ронбеком.
Первоначально с использованием данной методологии проектирования было создано ХД для
страховой компании. Вскоре после удачного опыта был спроектирован еще ряд ХД, а в 2007
году методология была официально представлена на конференции TDWI. Первая статья по
Anchor Modeling была впервые представлена в 2009 году на конференции 28th International
Conference on Conceptual Modeling [16].
С тех пор данная методология не перестает вызывать огромный интерес для
разработчиков ХД во всем мире. В целом, Anchor Modeling является методологией
построения ХД нового поколения, обладающим рядом уникальных особенностей. Далее
следует описание этой методологии, разделенное на тематические подразделы.
2.1 Основные характеристики Anchor Modеling
Прежде
всего,
определим,
что
понимается
под
предлагаемой
методологией,
разработанной специально для проектирования в условиях постоянно изменяющейся логики
в
бизнес
области.
Anchor
Modeling
-
это
разновидность
agile-методологий
для
моделирования данных, предлагающая механизмы расширяемости и обеспечивающая
надежное и гибкое управление изменениями. Цель методологии заключается в достижении
сильно нормализованной модели, которая эффективно обрабатывает изменения и увеличение
ХД без отмены предыдущих действий. Поэтому ключевая особенность методологии
заключается в том, что изменения в ХД происходят за счет расширений, а не модификаций,
что позволяет хранить все предыдущие версии модели в качестве подмножеств последней
версии [17].
Развитие
модели
путем
расширения
обеспечивает
модульность,
позволяющую
декомпозировать модель данных на небольшие, устойчивые и хорошо управляемые
компоненты, развивающиеся итеративно. Действительно, первым делом строится небольшой
блок, включающий основные бизнес-сущности, далее, по мере роста осведомленности,
достраивается более детальная часть модели, что значительно позволяет снизить риски
разработки СППР. В целом, методология нацелена на то, что большие изменения во внешней
среде бизнеса должны приводить к малым изменениям в модели данных. Уменьшение
необходимости перепроектирования ХД существенно повышает «жизненный цикл» системы,
сокращает время внедрения и загрузки данных, а также упрощает обслуживание [17].
22
Итак, обобщая все сказанное, приведем ряд важнейших характеристик Anchor Modeling:
1. Устойчивость к изменениям (Resilience to change)
2. Гибкость (Agility)
3. Расширяемость (Extensibility)
4. Инкрементальность и итеративность разработки (Iterative and incremental development)
5. Отслеживание истории (History tracking)
6. Простота и скорость выполнения темпоральных запросов (Еase of temporal querying and
high run-time performance) (Примечание: данному пункту уделено особое внимание в
подразделе «Вопросы производительности»)
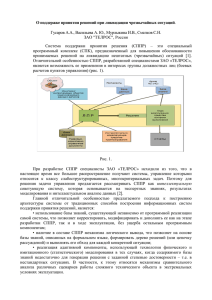
2.2 Описание модели Anchor Modeling
Методология Anchor Modeling предлагает свою собственную графическую нотацию для
построения моделей. По внешнему виду она близка к ER-диаграмме (entity-relationship),
однако содержит специальное расширение для темпоральных данных. Тем не менее, модель
Anchor Modeling все равно можно построить, используя различные техники моделирования.
Визуальное представление четырех основных компонентов представлено на рисунке 5. Далее
следует описание составляющих модели.
Якорь (anchor)
Якорь представляет собой набор уникальных бизнес-ключей. Логическое реляционное
представление: реляционная таблица 𝐴 (𝐾#) с одним столбцом 𝐾, где 𝐾 – первичный ключ
таблицы 𝐾 [13].
Атрибут (attribute)
Атрибуты, следующий компонент модели, содержат дополнительные сведения о якорях.
Логическое реляционное представление: реляционная таблица Attr (𝐾 ∗ , P), где 𝐾 –
первичный ключ атрибута, являющийся внешним ключом, связанным с первичным ключом
относящегося к нему якоря; 𝑃 – ненулевое значение [13].
В модели Anchor атрибуты бывают нескольких видов:
1. Статический (как правило, неизменяемый во времени)
2. Исторический (используется, когда важно отслеживать различные состояния, при
этом к первичному ключу добавляется поле с типом даты)
3. Узловой статический (используется, когда атрибут представляет собой небольшое
множество категорий/состояний)
4. Узловой исторический (свойства аналогичны узловому статическому, однако
добавляется возможность отслеживания значений во времени)
23
Связь (tie)
Отношения между якорями хранятся в специальном компоненте – связи. Логическое
реляционное представление: реляционная таблица 𝑇𝑖𝑒(𝐾1∗ , … , 𝐾𝑛∗ ). Где 𝑛 – количество
ассоциированных якорей и каждое 𝐾𝑖 для
𝑖 = {1, … , 𝑛} является внешним ключом,
соответствующим -му якорю. Первичным ключом в данном случае является совокупность
первичных ключей всех якорей, что позволяет гарантировать уникальность каждой строки
связи. Аналогично атрибутам, связи также бывают четырех видов [13]:
1. Статическая (используется для неизменяемых отношений)
2. Историческая (для ситуаций, когда отношение меняется во времени, при этом к
первичному ключу добавляется поле с типом даты)
3. Узловая статическая (используется для связей объектов, принадлежащих
определенным категориям)
4. Узловая историческая (свойства аналогичны узловой статической, но добавляется
еще поле с типом даты для отслеживания изменений в связях)
Узел (knot)
Последний компонент, узел, представляет собой неизменяемый, как правило, небольшой,
набор уникальных значений. Логическое реляционное представление: реляционная таблица
𝐾𝑛𝑜𝑡 (𝐾 ∗ , 𝑃), где К – первичный уникальный ключ узла, Р – ненулевое значение. Самым
простым примером узла является «пол человека». Это неизменяемый справочник, состоящий
из двух значений: Мужской и Женский [13].
24
Рисунок 5. Компоненты модели Anchor Modeling
Таким образом, якори и узлы представляют в модели Anchor Modeling неизменяемую
составляющую, в то время как атрибуты и связи адаптированы для изменений во времени. В
целом, становится понятно, что модель Anchor является очень гибкой и легко расширяемой.
2.3 Особенности темпоральности
В данном подразделе рассмотрены основные моменты, связанные с темпоральностью ХД,
построенного по методологии Anchor Modeling. Прежде всего, определимся, что конкретно
подразумевается под термином «темпоральность» в данном контексте. Темпоральное
моделирование включает набор техник для построения моделей, представляющих не только
наборы данных и их структуру, но и изменения самой модели и ее содержимого во времени,
в частности, когда определенные изменения произошли и когда они были валидны. В свою
очередь, темпоральная база данных предполагает наличие таких аспектов как темпоральная
модель и темпоральная версия для языка запросов. Если назначение «обычной» базы данных
заключается в хранении информации и ее поиске, то темпоральная база позволяет хранить
данные в условиях их изменения и обеспечивает выполнение поиска по историческим
данным. Подход к моделированию в Anchor Modeling не предполагает поддержки никаких
специфических элементов языка (операторов) для поддержки темпоральных запросов.
Однако методология обеспечивает функции, триггеры и представления для упрощения и
оптимизации запросов темпоральных данных. Что касается модели Anchor Modeling, то она
25
содержит расширение в виде меток времени для исторических атрибутов, а также
исторических связей [1].
Далее описаны три типа времени, используемые в модели: время изменения (changing
time), время транзакции (recording time) и время события (happening time). Данное
разграничение позволяет охватить те виды меток времени, которые представляют
информацию о том, когда значения данных изменялись, когда информация была загружена и
когда событие произошло.
Время изменения (changing time)
Время изменения для исторических атрибутов или связей представляет собой временной
интервал, в течение которого значение атрибута или отношение является действительным. В
модели Anchor этот интервал представлен лишь одной меткой времени, обозначающей время
изменения состояния объекта. По сути, эта дата является началом для интервала в явном
виде. Когда в ХД добавляется новый объект, имеющий тот же идентификатор, но более
позднее время, он неявно закрывает интервал для старого объекта.
В случае, когда необходимо явно сделать объект недействительным, вместо удаления
(NULL-значения недопустимы в Anchor модели) и обновления создается узел, хранящий
информацию о состоянии валидности атрибута или связи. Таким образом, время изменения
позволяет находить в ХД информацию, актуальную на конкретный период времени [ 1].
Время события (happening time)
Время события используется для определения даты события, произошедшего в реальной
жизни. В модели Anchor такой тип времени рассматривается как атрибут некого объекта.
Данное время является зачастую мгновенным (момент времени) и представляет собой всего
одну метку времени. Однако время события также может представлять собой временной
интервал.
Важно отличать время события от времени изменения. Будучи атрибутом в модели, время
события может иметь собственное время изменения и время транзакции. Данное замечание
относится к историческим атрибутам, период валидности которых меняется во времени.
Если значение атрибута может измениться и у него есть время изменения, то это не значит,
что событие произошло в другое время. В этом есть тонкая грань между двумя типами
времени [1].
Время транзакции (recording time)
В целях обслуживания и сбора аналитики в ХД существует третий тип времени – время
транзакции. Данный тип показывает время, в течение которого информация была записана
на определенном носителе памяти, в данном случае, в ХД. Поскольку время транзакции
является информацией об информации, то его относят к расширению метаданных в ХД.
26
Во многих случаях одной метки времени записи на носитель информации достаточно для
соотнесения ее со временем, когда информация была загружена в модель. Однако, возникают
моменты, когда необходимо хранить целый набор временных меток, поскольку данные
проходят через множество систем перед тем, как попасть в ХД [1].
Проекции темпоральности (perspectives)
Таким образом, разграничение по типам временных меток дает возможность определения
в Anchor модели трех проекций темпоральности: последняя (latest), моментная (point-in-time)
и интервальная (interval). Последняя перспектива показывает последнюю доступную
информацию. Моментная перспектива представляет информацию на конкретную точку
времени. Интервальная соответственно позволяет увидеть изменения, произошедшие в
определенном интервале времени [17].
Темпоральная независимость (temporal independence)
Темпоральная независимость модели достигается благодаря разделению на изменяемый и
неизменяемый контент, где изменяемый всегда ссылается на неизменяемый. Получается, что
изменения в одной таблице остаются независимыми от всех остальных таблиц.
В модели Anchor неизменяемый контент составляют якори и узлы, в то время как
атрибуты и связи изменяются во времени транзакции и времени изменения [17].
Темпоральная целостность (temporal integrity)
Темпоральная
ссылочная
целостность
(temporal
referential
integrity)
достигается
следующим образом: для каждого момента времени изменения и времени транзакции модель
ведет себя так, будто все компоненты в ней полностью неизменны. Если рассмотреть две
точки времени: прошедшее и настоящее, то объекты модели прошедшего времени остаются
существовать в настоящем благодаря неизменности. Поэтому ссылочная целостность
прошлого будет также удовлетворять ссылочной целостности настоящего, составляя при
этом общую темпоральную ссылочную целостность.
Что касается темпоральной целостности сущностей (temporal entity integrity), то она
обеспечивает согласованность для атрибутов и связей, поскольку значения данных
компонентов в ходе развития модели во времени не перекрывают друг друга на временной
ленте. Более того, в 6NF атрибуты и связи хранятся в отдельных таблицах, поэтому
целостность
компонентов
обеспечивается
наложением
выполнении изменения, записи или удаления [17].
27
простых
ограничений
при
2.4 Физическая интерпретация модели
Шестая нормальная форма (6NF)
При трансляции концептуальной модели Anchor в физическую данные соотносятся в базе
данных в виде реляционной схемы в шестой нормальной форме (6NF). Термин 6NF,
придуманный К. Дейтом, в теории реляционных баз данных используется для обозначения
баз, схема которых декомпозирована до состояния, при котором дальнейшая декомпозиция
приводит уже к потере информации. Также существуют идеи о том, что 6NF можно считать
понятием, сходным с DKNF (доменно-ключевая нормальная форма) формой, где
присутствует только два ограничения: на домен и на ключ. Тем не менее, в данной работе
рассматривается понятие 6NF именно по Дейту, которое тесно связано с принципами
темпоральности,
описанными
подробно
в
предыдущем
подразделе.
Эта
форма
приспособлена к обработке темпоральных данных в базе путем добавления в определенные
таблицы меток времени, позволяющих отследить информацию как за конкретный момент
времени, так и за временной промежуток. По сути, схема базы в шестой нормальной форме
содержит таблицы, включающие поля-ключи, поля-значения и временные метки [10].
Anchor модель не считается в полной мере соответствующей шестой нормальной форме,
поскольку 6NF предполагает наличие временных меток отслеживания темпоральности для
всех сущностей в схеме. Как известно, компонент модели якорь (anchor) не может быть
темпоральным, поскольку содержит уникальные ключи сущностей, которые не меняются.
Этот же момент касается такого компонента модели как узел (knot), включающий в себя
стандартный набор значений, отслеживание которых не является необходимым в Anchor
Modeling. Что касается атрибутов (attribute) и связей (tie), они являются темпоральными в
зависимости от конкретной ситуации. Таким образом, можно утверждать, что методология
Anchor Modeling подразумевает селективную темпоральность, а схема данных соотносится с
принципами 6NF [10].
Далее рассмотрены основные моменты, касающиеся реализации вспомогательных
компонентов для темпорального ХД, построенного по методологии Anchor Modeling.
Индексы, как известно, создаются для упрощения поиска в базе, а, следовательно, для
увеличения производительности. В свою очередь, функции и представления служат для
упрощения выполнения запросов, путем денормализации ХД и извлечения данных в нужной
темпоральной перспективе. Именно данные компоненты напрямую отвечают за возможность
отслеживания исторических данных в ХД. Наконец, триггеры отвечают за корректные
манипуляции данными в таблицах [17].
28
Индексы (indexes)
Наличие индексов напрямую влияет на производительность СППР. В частности,
кластеризованные индексы используются для уменьшения количества просматриваемых
строк во время выполнения запроса. Кластеризованный индекс представляет собой индекс,
отсортированный в порядке аналогичном сортировке физического расположения данных на
хранителе информации. Индексы такого типа уникальны и, как правило, представляют собой
первичные ключи в таблицах ХД. Применительно к модели Anchor, где ввиду сильной
нормализации должно быть связано большое количество таблиц, якори и узлы содержат
первичные ключи, являющиеся кластеризованными индексами. Для атрибутов также
создается индекс, состоящий из внешнего ключа, ссылающегося на якорь, отсортированного
в порядке возрастания, и из столбца с меткой времени, отсортированного в порядке
убывания. Последнее необходимо для эффективного извлечения последней версии данных,
хранящейся на физическом носителе в начале списка. Наконец, таблицы связей также
должны иметь кластеризованные индексы, построенные из первичных ключей [17].
Представления (views)
В методологии Anchor Modeling определены следующие виды представлений: полное,
последнее, естественное. Полное представление представляет собой соединение (left outer
join) таблицы конкретного якоря со всеми его атрибутами. Последнее представление
основывается на данных из полного представления, однако содержит только последнюю
версию значений для исторических атрибутов.
Поэтому последнее представление
используется для ограничения вывода результирующих строк запроса, оставляя только
самый актуальный набор. Естественное представление используется для ситуаций, когда
натуральный ключ для якоря определяется несколькими атрибутами. Представление
собирает все такие атрибуты из разных якорей в единую таблицу с целью преобразовать
значения натуральных ключей в соответствующие им суррогатные ключи [17].
Функции (functions)
Функции в методологии Anchor Modeling тесно связаны с представлениями. Определены
два типа функций: моментная и интервальная. Моментная представляет собой функцию,
принимающую в качестве аргумента временную метку и возвращающую множество данных.
Она основывается на полном представлении, однако возвращает актуальные значения для
исторических атрибутов на заданный момент времени. Что касается интервальной функции,
то данная функция принимает в качестве аргументов две метки времени и возвращает
множество данных. Она также основана на полном представлении, однако возвращает для
каждого атрибута значения, лежащие в заданном временном интервале [17].
29
Триггеры (triggers)
Триггеры в методологии Anchor Modeling также играют немаловажную роль. Они
представляют собой особые процедуры, представляющие определенные правила, которые
контролируют манипуляции над таблицами. В частности, триггеры реагируют на
модификацию данных при помощи операторов UPDATE, DELETE, INSERT. Поскольку в
Anchor модели предъявляются особые требования на выполнение данных операций,
триггеры служат некими обработчиками для них. Таким образом, триггеры контролируют
целостность темпорального ХД, проверяя корректность выполняемых операций. Более того,
триггеры не нужно вызывать в отличие от функций [17].
2.5 Обработка NULL-значений в хранилище
Одной из важных отличительных особенностей методологии является обработка NULLзначений. В Anchor Modeling принято, что в ХД не должно содержаться NULL-значений
(absence of null values). Методология предполагает два варианта развития событий при
появлении отсутствующих значений [17]:
1. Неизвестное значение может иметь бизнес-смысл, поэтому оно должно быть
представлено в ХД явно, например, поле с отсутствующими данными заполняется
строкой «unknown» и является видимым для конечного пользователя.
2. Неизвестное значение может не иметь бизнес смысла, поэтому оно должно представлять
разрыв во временной линии транзакций и являться невидимым для конечного
пользователя в течение данного промежутка.
2.6 Вопросы производительности
Производительность играет большую роль при сравнении методологий построения ХД.
Казалось бы, сильно нормализация при построении Anchor модели негативно сказывается на
производительности СППР. Такая точка зрения подтвердилась в результатах исследования
[12], в котором проводился ряд экспериментов, и анализировалось время выполнения
запросов в моделях, построенных по методологии Anchor Modeling
и по классической
методологии Кимбалла «звезда». Исследование, проведенное в [17], показало, что снижение
скорости запросов не зависит напрямую от высокой степени нормализации. В эксперименте
участвовало несколько моделей, среди которых была Anchor модель и другая, менее
нормализованная модель (3NF).
30
Поскольку высокая скорость выполнения запросов в условиях Big Data является
важнейшим конкурентным преимуществом, разберем, за счет чего в методологии Anchor
Modeling достигаются высокие показатели по данному аспекту.
Устранение таблиц (Table/join elimination)
Эффективное хранение данных и высокую производительность также обеспечивает такая
техника как устранение таблиц. В сильно денормализованной схеме данных возникает
трудность выполнения запросов, поскольку приходится связывать между собой большое
количество таблиц. В целях улучшения ситуации современные оптимизаторы запросов в
СУБД используют данную технику, позволяющую выполнить запрос, не обращаясь при этом
ко всем таблицам, к которым этот запрос обращается. Устранение таблиц из плана
выполнения запроса повышает производительность при использовании представлений, а
также пользовательских функций, возвращающих таблицы. Таким образом, количество
считываемых данных существенно снижается. Оптимизатор исключает таблицы из запроса
при выполнении двух условий [17]:
1. Ни один столбец из исключаемой таблицы не выбран в явном виде.
2. Количество возвращаемых запросом строк не зависит от присоединения с данной
таблицей.
Наличие первичных и внешних ключей является обязательным, потому что в операциях
присоединения таблиц (join), используемых в представлениях и функциях, таблицы
связываются по ключам. Это обеспечивает уникальность данных, а также одинаковое
количество возвращаемых строк (при отсутствии накладываемых условий). При наличии
условий на запрос существование ключей также обеспечивает устранение таблиц в
подзапросе. Никаких других ограничительных правил (constraints), кроме ключей, в модели
не предполагается по причинам снижения производительности. В итоге получается, что для
сущности с несколькими атрибутами, часть из которых используется в запросе через
функции/представления, остальные атрибуты остаются незатронутыми при выполнении
запроса [17].
Разбиение (Секционирование) таблиц (Partitioning of Tables)
Как и использование индексов, принцип разбиения таблиц также используется в Anchor
Modeling для облегчения доступа к данным ХД. Опять же при наличии огромного
количества строк данных в таблицах возникает ситуация, когда необходимо часто выбирать
оттуда данные по конкретному признаку. Секционирование заключается в разбиении
таблицы на отдельные части, хранящиеся в отдельных файлах. Это позволяет значительно
ускорить процесс поиска данных ввиду отсутствия необходимости перебора большого
количества
лишних
строк.
Применительно
31
к
модели
Anchor,
необходимость
в
секционировании наиболее вероятна для узлов, где количество разбиений будет равно
кардинальности отдельного узла, а также для атрибутов с типом даты, поскольку зачастую в
запросах важны именно поля, представляющие даты [17].
Принципы загрузки данных (Loading Practices)
Затрагивая тему отслеживания изменений путем расширяемости модели, отметим пару
моментов, связанных с загрузкой данных в ХД. Методология Anchor Modeling предполагает
обновление информации только с помощью добавления новых строк (INSERT), а не
обновление через удаление (UPDATE). Чтобы обработать ситуации, когда необходимо
удаление, для сущностей или связей, состояние которых часто меняется, следует
использовать специальный узел, в котором будет храниться и отслеживаться текущее
состояние. В целом, данный метод позволяет хранить полную историю с самыми точными
данными [17].
Принцип отказа от операции обновления через удаление также связан с принципом
грамотного оперирования метаданными в ХД. С его помощью, становится возможным найти
партию данных, принадлежащих определенному пакету, относящемуся к конкретному
источнику данных или загруженному в обозначенный период времени. Данный принцип
также позволяет эффективно отслеживать возможные ошибки, возникающие в системе при
загрузке [17].
Итак, возвращаясь к вопросам производительности СППР, заметим, что операция
добавления требует значительно меньшее количество времени и ресурсов в отличие от
операции
обновления.
Исключив
обновление,
также
устраняется
необходимость
блокирования строк в потоках, что сильно сокращает влияние на производительность
системы во время чтения данных.
2.7 Преимущества методологии
Подводя определенные итоги рассмотрению методологии Anchor Modeling в качестве
предлагаемого в данной работе решения для реализации СППР, обобщим все достоинства
выбранной методологии, разбив их на три главные группы, отражающие существенные
преимущества Anchor Modeling перед аналогами [17].
Простота моделирования (Ease of Modeling)
1. Удобная графическая нотация (отдельное графическое представление для всех четырех
компонентов; особое отображение для темпоральных элементов; возможность прямой
трансляции из концептуальной модели в физическую).
32
2. Гибкое моделирование (возможность проектировать модель постепенно, подстраиваясь
под постоянные изменения требований; возможность реализовывать модель по частям
несколькими разработчиками в отдельности, не влияя друг на друга с возможностью
дальнейшей интеграции в единую модель).
3. Возможность
многократного
использования
(все
виды
компонентов
созданы
однотипным образом, имеют практически одинаковую структуру; при необходимости
модель можно быстро подстроить «под себя»).
Удобство обслуживания (Simplified Database Maintenance)
1. Простота изменения полей (исторические изменения обрабатываются на уровне
отдельных полей (атрибутов), а не целых строк; связи между сущностями также
хранятся в отдельных таблицах).
2. Легкость выполнения темпоральных запросов (возможность рассматривать модель в
трех
временных
проекциях
(моментная,
интервальная,
последняя),
используя
соответствующие функции и представления).
3. Простота обновления новых данных (новые данные обновляют модель, не используя
при этом удаление старых версий; обновление происходит путем добавления новой
информации, не зависящей от старой).
4. Отсутствие NULL-значений (нет необходимости обрабатывать и хранить пустые
значения).
Высокая производительность (High Performance Databases)
1. Большая скорость выполнения запросов (техника устранения таблиц, а также
минимальная избыточность данных ввиду сильной нормализации способствует
сокращению времени выполнения запросов).
2. Эффективное хранение (минимальное количество значимых столбцов в таблицах,
отсутствие null-значений, возможность избежать дублирования данных путем
отслеживания изменений).
3. Параллельный доступ (отсутствие операций удаления и вставки избавляет от
необходимости блокировки строк, сокращая вероятность появления аномалии в виде
взаимной
блокировки;
минимальное
количество
распараллеливает доступ к отдельным атрибутам).
33
столбцов
в
таблице
также
2.8 Область применения методологии
Методология Anchor Modeling нацелена на разработку темпоральных ХД в условиях Big
Data. Речь идет о больших компаниях, объемы сырых данных которых составляют терабайты
(1 Тб = 1012 байт), количество новых записей в ХД за сутки достигает сотен миллионов, а
требование ко времени обработки информации сводится к реальному.
Начиная с 2003 года, методология активно используется и по сегодняшний день во всем
мире. Системы, построенные на основе Anchor Modeling, разрабатываются для компаний из
таких областей бизнеса как: страхование, логистика, торговля, начиная от отдельных
департаментов и заканчивая ХД для целого предприятия.
Различные аспекты методологии являются ключевым при выборе ее, а не другой техники
в качестве основы построения ХД. Например, для страховых компаний надежность и
расширяемость являются самыми приоритетными показателями, так как ХД в таких
компаниях развивается инкрементально, а источников данных наблюдается огромное
количество. Для корпоративного менеджмента Anchor Modeling является наиболее
приемлемым из-за легкости доступа к историческим данным, а также возможности
повторного использования ETL-скриптов для загрузки данных. Для торговых компаний, где
требования для анализа данных не всегда очевидны и изменчивы, методология дает
возможность выполнения быстрых запросов с высокой производительностью, что, в
конечном счете, позволяет снизить проектные риски. Anchor Modeling также применима в
здравоохранении, где ее способность обработки исторических данных особо актуальна [17].
В России Anchor Modeling остается практически неизвестной методологией. Только в
2014 году для крупнейшей российской интернет-компании было построено первое в стране
ХД, основанное на модели Anchor. Это позволило значительно ускорить ETL-процессы,
обеспечить поддержание историчности, быстрой расширяемости, а также управляемости ХД
[3].
34
3 Реализация СППР
Данная глава раскрывает технологическую часть работы. Она разделена на подразделы, в
которых подробно описаны детали создания СППР на соответствующих этапах. Также в
начале главы присутствует подраздел, посвященный выбору инструментов, используемых
для реализации СППР.
3.1 Выбор инструментов решения
Создавая СППР, где главной составляющей является темпоральное ХД, необходимо
серьезно подойти к выбору СУБД, в которой будет выполняться реализация ХД. Поскольку в
основе физической модели ХД лежит реляционная модель в шестой нормальной форме
(6NF), то подходящим средством реализации можно считать реляционную СУБД MS SQL
Server.
Во-первых, данная СУБД отвечает многим требованиям к производительности ХД, в
частности, оптимизатор запросов в SQL Server обладает функциями устранения таблиц, а
также секционирования таблиц, от которых было написано в предыдущей главе в подразделе
«Вопросы производительности».
Во-вторых, SQL Server обладает одной исключительной способностью, крайне удобной
для ETL-процесса загрузки данных в ХД, а именно: СУБД позволяет загружать данные не
только в таблицы, но и в представления (views), автоматически загружая при этом таблицы, к
которым они обращаются. Забегая вперед, поясню, что сильно нормализованное ХД
усложняет процесс загрузки, ведь данные необходимо грузить сразу во все таблицы,
сохраняя ссылочную целостность. Выходом из этого являются представления, собирающие
все атрибуты и позволяющие производить загрузку всех таблиц одной трансформацией.
В-третьих, СУБД SQL Server оперирует с языком Transcact SQL (T-SQL), являющимся
классическим и удобным языком запросов. Он представляет удобный синтаксис для
написания триггеров, функций, а также сложных запросов, необходимых для формирования
представлений и получения необходимой информации из базы данных.
Что касается ETL-модуля для преобразования и загрузки данных из источника в ХД, то
подходящим средством можно считать открытое программное обеспечение Pentaho Data
Integration (Kettle), обладающее удобным интерфейсом для создания необходимых сценариев
трансформаций
данных.
Данное
ПО
написано
на
Java,
что
обеспечивает
кроссплатформенность приложения. Более того, Pentaho Kettle является эффективным
инструментом для работы с Big Data, позволяя выполнять загрузку большого количество
данных за минимальное время.
35
Для реализации многомерной виртуальной модели выбран инструмент MS SQL Server
Analysis Services, входящий в комплект продуктов MS SQL Server, поддерживающий язык
многомерных запросов MDX, который используется для проведения многомерного анализа.
3.2 Создание источника данных
Источником
данных
в
СППР
выступает
некая
учетная
система,
ежедневно
обрабатывающая большое количество транзакций, в результате которых данные попадают в
реляционную, как правило, базу данных. Поскольку готовые базы данных не лежат в
открытом доступе ввиду того, что это коммерческая тайна, пришлось спроектировать и
создать источник данных самостоятельно.
За основу я взяла учетную систему «1С. Управление торговлей» [22]. Именно такая
область бизнеса торговля нуждается в отслеживании темпоральных данных для получения
корректных сведений о текущем состоянии бизнеса. Более того, современные торговые
компании хранят огромные объемы данных (Big Data), нуждающихся в анализе.
Проанализировав бизнес-процессы, с которыми работает система «1С. Управление
торговлей», я выбрала для себя область оптовых продаж и закупок, выделив следующие
процессы:
1. Заказ покупателя.
2. Резервирование товаров.
3. Внутренний заказ.
4. Заказ поставщику.
5. Поступление товаров и услуг.
6. Продажи.
7. Возврат товаров поставщику.
8. Возврат товаров от покупателя.
9. Перемещение товаров между складами.
10. Списание товаров.
36
Инфологическая модель взаимодействия бизнес-процессов, построенная в нотации BPMN,
представлена на рисунке 6.
Рисунок 6. Инфологическая модель бизнес-процессов.
37
Далее по частям представлена даталогическая модель источника, спроектированная в
нотации IDEF1X.
Рисунок 7. Заказ покупателя и продажи.
Рисунок 8. Списание товаров со склада.
38
Рисунок 9. Заказ поставщику и поступление товаров.
Рисунок 10. Внутренний заказ.
39
Рисунок 11. Резервирование товара.
Рисунок 12. Перемещение товаров между складами.
40
Рисунок 13. Возврат товара поставщику.
41
Рисунок 14. Возврат товаров от покупателя.
42
На самом нижнем уровне, физическая схема базы данных спроектирована в соответствии
с третьей нормальной формой (3NF). Для удобства рассмотрения, далее представлены
фрагменты физической схемы, разделенные по бизнес-процессам.
Рисунок 15. Заказ покупателя.
Рисунок 16. Резервирование товаров.
43
Рисунок 17. Внутренний заказ.
Рисунок 18. Заказ поставщику.
44
Рисунок 19. Поступление товаров и услуг.
Рисунок 20. Продажи.
45
Рисунок 21. Возврат товаров от покупателя.
Рисунок 22. Возрат товаров поставщику.
46
Рисунок 23. Перемещение товаров между складами.
Рисунок 24. Списание товаров.
Поясним кратко назначение таблиц в базе:
Таблица 2
Описание таблиц источника данных
№
таблицы
1
2
3
4
5
6
7
Название
Назначение
ArrivalProductHeader
ArrivalProductDetails
City
CommunicationType
Company
Contract
Contractor
Заголовок документа поступления
Детали документа поступления
Город
Тип связи с контрагентом
Организация
Договор
Контрагент
47
№
таблицы
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
Название
Назначение
ContractorStatus
ContractorType
ContractType
Country
CustomerOrderHeader
CustomerOrderDetails
Division
DivisionCompanyAssignment
FaceType
InternalOrderHeader
InternalOrderDetails
MoveBetweenWarehouseHeader
MoveBetweenWarehouseDetails
OrderStatus
Product
ProductLine
ProductType
ReasonCancel
ReasonReturn
ReasonWriteOff
Region
ReservationProductHeader
ReservationProductDetails
Responsible
ReturnFromCustomerHeader
ReturnFromCustomerDetails
ReturnToSupplierHeader
ReturnToSupplierDetails
SalesHeader
SalesDetails
SettleType
Stock
SupplierOrderHeader
SupplierOrderDetails
Warehouse
WarehouseType
WriteOffProductHeader
WriteOffProductDetails
Статус контрагента
Тип контрагента
Тип договора
Страна
Заголовок заказа покупателя
Детали заказа покупателя
Подразделение компании
Организация – подразделение
Тип организации
Заголовок внутреннего заказа
Детали внутреннего заказа
Заголовок перемещения товаров
Детали перемещения товаров
Статус заказа
Товар
Линия товаров
Тип товара
Причина отмены заказа
Причина возврата товаров
Причина списания товаров
Регион
Заголовок документа резервирования
Детали документа резервирования
Ответственный
Заголовок возврата покупателя
Детали возврата покупателя
Заголовок возврата поставщику
Детали возврата поставщику
Заголовок документа продаж
Детали документа продаж
Вид оплаты
Остатки на складе
Заголовок заказа поставщику
Детали заказа поставщику
Склад
Тип склада
Заголовок списания товаров
Детали списания товаров
Что касается заполнения источника, то в целом данные в базе обезличены за исключением
списка товаров, взятого из прайс-листа компании «Сервис бар» [21].
Таким образом, источник данных для СППР готов. Далее рассмотрим основные моменты
построения темпорального ХД.
48
3.3 Создание темпорального хранилища данных
При проектировании темпорального ХД нужно максимально денормализовать схему базы
источника, представив ее в шестой нормальной форме. Все сущности, представляющие
ключевые бизнес значения, становятся якорями, атрибуты которых будут храниться в
отдельных таблицах. Отношения между якорями выносятся в отдельные таблицы связей.
Узлами, в свою очередь, являются неизменяемые атрибуты. Примеры вышеперечисленных
компонентов рассмотрены далее.
Для начала определимся, какие компоненты следует представить темпоральными.
Другими словами, нужно понять, изменения каких бизнес объектов важно отслеживать для
дальнейшего анализа. Наиболее оправданным будет хранение следующих темпоральных
связей:
1. Все связи (ties), содержащие Склады (пример связи: Компания – Склад).
2. Все связи, определяющие отношения parent-child (пример: Ответственный –
Вышестоящий ответственный).
3. Связи, содержащие города (пример: Компания – Город).
4. Связи, содержащие статус заказа (пример: Заказ покупателя – Статус заказа).
5. Частный случай связи: Договор – Тип оплаты.
6. Частный случай связи: Контрагент – Тип коммуникации.
Также выделим следующие темпоральные атрибуты:
1. Атрибут Количество в якоре Остатки.
2. Атрибуты Цена, Производитель, Артикул в якоре Товар.
3. Атрибут Фактический адрес в якоре Компания.
4. Атрибут Фактический адрес в якоре Контрагент.
Что касается узлов, то в данной модели определены пять таких компонентов:
1. Тип склада.
2. Тип оплаты.
3. Тип юридического лица.
4. Тип контрагента.
5. Тип договора.
49
Концептуальная схема темпорального ХД в общем виде представлена на рисунке 25.
Рисунок 25. Концептуальная схема темпорального ХД.
50
Ниже представлен фрагмент модели, относящийся к процессам «Поступление товаров»
(Arrival Header), «Заказ поставщику» (Supplier Order Header) и «Возврат товаров
поставщику» (Return To Supplier Header).
Рисунок 26. Фрагмент Anchor модели.
51
Переходя к физической реализации модели, рассмотрим на примерах представление каждого
компонента в отдельности. Якори реализованы в таблицах следующим образом:
CO_Country
Название якоря (Страна)
CO_ID
Первичный ключ (суррогатный, автоинкрементальный)
Metadata_CO
Поле для метаданных, необходимых для отслеживания загрузки
Примеры статического и исторического атрибута представлены далее:
CO_NAM_Country_Name
Название атрибута (Имя страны)
Первичный ключ (идентифицирующая связь с первичным
CO_NAM_CO_ID
ключом якоря)
CO_NAM_Country_Name
Значение атрибута
Metadata_CO_NAM
Поле для метаданных, необходимых для отслеживания загрузки
OK_QTT_Stock_Quantity
Название (Количество товаров в остатках)
Первичный ключ (идентифицирующая связь с первичным
OK_QTT_OK_ID
ключом якоря)
OK_QTT_Stock_Quantity
Значение атрибута
OK_QTT_ChangedAt
Временная метка для отслеживания изменений атрибута
Metadata_OK_QTT
Поле для метаданных, необходимых для отслеживания загрузки
Пример узла и узлового атрибута показан ниже:
STN_SettleType
Название узла (Оплаты)
STN_ID
Первичный ключ
STN_SettleType
Уникальное значение узла
Metadata_STN
Поле для метаданных, необходимых для отслеживания загрузки
ST_STE_SettleType_Type
ST_STE_ST_ID
Название узлового атрибута (Оплата)
Первичный ключ (идентифицирующая связь с первичным
ключом якоря)
ST_STE_STN_ID
Внешний ключ на узел
Metadata_ST_STE
Поле для метаданных, необходимых для отслеживания загрузки
52
Наконец, представлен пример статической и исторической связи:
SO_1_SS_m
Название связи (Заказ поставщику заголовок - детали)
SO_ID_1
Внешний ключ на идентификатор якоря-заголовка
SS_ID_m
Первичный ключ на идентификатор якоря-деталей
Metadata_SO_1_SS_m
Поле для метаданных, необходимых для отслеживания загрузки
OS_1_IH_m
Название исторической связи (Внутренний заказ - статус)
IH_ID_m
Первичный ключ на якорь - заказ
OS_1_IH_m_ChangedAt
Временная метка для отслеживания изменений (входит в
первичный ключ)
OS_ID_1
Внешний ключ на идентификатор якоря - статуса заказа
Metadata_OS_1_IH_m
Поле для метаданных, необходимых для отслеживания загрузки
Далее рассмотрим, как при помощи функций и представлений реализована концепция
временных проекций.
Функции бывают двух типов: моментные и интервальные. Ниже рассмотрен пример
моментной функции, позволяющей получить данные, актуальные на (или в) определенный
момент времени для якоря с темпоральными атрибутами:
Вспомогательная:
CREATE FUNCTION [dbo].[rCP_FAD_Company_FactAddress] (
@changingTimepoint datetime
)
RETURNS TABLE WITH SCHEMABINDING AS RETURN
SELECT
Metadata_CP_FAD,
CP_FAD_CP_ID,
CP_FAD_Company_FactAddress,
CP_FAD_ChangedAt
FROM
[dbo].[CP_FAD_Company_FactAddress]
WHERE
CP_FAD_ChangedAt <= @changingTimepoint;
Основная:
CREATE FUNCTION [dbo].[pCP_Company] (
@changingTimepoint datetime2(7)
)
RETURNS TABLE WITH SCHEMABINDING AS RETURN
SELECT
[CP].CP_ID,
[CP].Metadata_CP,
[CID].CP_CID_CP_ID,
[CID].Metadata_CP_CID,
[CID].CP_CID_Company_CompanyId,
53
[NAM].CP_NAM_CP_ID,
[NAM].Metadata_CP_NAM,
[NAM].CP_NAM_Company_OfficName,
[COD].CP_COD_CP_ID,
[COD].Metadata_CP_COD,
[COD].CP_COD_Company_Code,
[SNM].CP_SNM_CP_ID,
[SNM].Metadata_CP_SNM,
[SNM].CP_SNM_Company_ShortName,
[INN].CP_INN_CP_ID,
[INN].Metadata_CP_INN,
[INN].CP_INN_Company_Inn,
[LAD].CP_LAD_CP_ID,
[LAD].Metadata_CP_LAD,
[LAD].CP_LAD_Company_LegalAddress,
[FAD].CP_FAD_CP_ID,
[FAD].Metadata_CP_FAD,
[FAD].CP_FAD_ChangedAt,
[FAD].CP_FAD_Company_FactAddress
FROM
[dbo].[CP_Company] [CP]
LEFT JOIN
[dbo].[CP_CID_Company_CompanyId] [CID]
ON
[CID].CP_CID_CP_ID = [CP].CP_ID
LEFT JOIN
[dbo].[CP_NAM_Company_OfficName] [NAM]
ON
[NAM].CP_NAM_CP_ID = [CP].CP_ID
LEFT JOIN
[dbo].[CP_COD_Company_Code] [COD]
ON
[COD].CP_COD_CP_ID = [CP].CP_ID
LEFT JOIN
[dbo].[CP_SNM_Company_ShortName] [SNM]
ON
[SNM].CP_SNM_CP_ID = [CP].CP_ID
LEFT JOIN
[dbo].[CP_INN_Company_Inn] [INN]
ON
[INN].CP_INN_CP_ID = [CP].CP_ID
LEFT JOIN
[dbo].[CP_LAD_Company_LegalAddress] [LAD]
ON
[LAD].CP_LAD_CP_ID = [CP].CP_ID
LEFT JOIN
[dbo].[rCP_FAD_Company_FactAddress](@changingTimepoint) [FAD]
ON
[FAD].CP_FAD_CP_ID = [CP].CP_ID
AND
[FAD].CP_FAD_ChangedAt = (
SELECT
max(sub.CP_FAD_ChangedAt)
FROM
[dbo].[rCP_FAD_Company_FactAddress](@changingTimepoint) sub
WHERE
sub.CP_FAD_CP_ID = [CP].CP_ID
Для темпоральных связей моментная функция реализуется через одну основную:
CREATE FUNCTION [dbo].[pWH_1_OK_m] (
@changingTimepoint datetime2(7)
)
54
RETURNS TABLE WITH SCHEMABINDING AS RETURN
SELECT
tie.Metadata_WH_1_OK_m,
tie.WH_1_OK_m_ChangedAt,
tie.WH_ID_1,
tie.OK_ID_m
FROM
[dbo].[WH_1_OK_m] tie
WHERE
tie.WH_1_OK_m_ChangedAt = (
SELECT
max(sub.WH_1_OK_m_ChangedAt)
FROM
[dbo].[WH_1_OK_m] sub
WHERE
sub.OK_ID_m = tie.OK_ID_m
AND
sub.WH_1_OK_m_ChangedAt <= @changingTimepoint
55
В свою очередь, интервальная функция возвращает набор данных, актуальных в течение
указанного периода времени. Пример для якоря с атрибутами:
CREATE FUNCTION [dbo].[Difference_Stock] (
@intervalStart datetime2(7),
@intervalEnd datetime2(7),
@selection varchar(max) = null
)
RETURNS TABLE AS RETURN
SELECT
timepoints.[Time_of_Change],
timepoints.[Subject_of_Change],
[pOK].*
FROM (
SELECT DISTINCT
OK_QTT_OK_ID AS OK_ID,
OK_QTT_ChangedAt AS [Time_of_Change],
'Quantity' AS [Subject_of_Change]
FROM
[dbo].[OK_QTT_Stock_Quantity]
WHERE
(@selection is null OR @selection like '%QTT%')
AND
OK_QTT_ChangedAt BETWEEN @intervalStart AND @intervalEnd
) timepoints
CROSS APPLY
[dbo].[Point_Stock](timepoints.[Time_of_Change]) [pOK]
WHERE
[pOK].Stock_Id = timepoints.OK_ID
Для темпоральных связей реализация в два этапа:
Вспомогательная:
CREATE FUNCTION [dbo].[dCP_m_CY_1] (
@intervalStart datetime2(7),
@intervalEnd datetime2(7)
)
RETURNS TABLE AS RETURN
SELECT
tie.Metadata_CP_m_CY_1,
tie.CP_m_CY_1_ChangedAt,
tie.CP_ID_m,
tie.CY_ID_1
FROM
[dbo].[CP_m_CY_1] tie
WHERE
tie.CP_m_CY_1_ChangedAt BETWEEN @intervalStart AND @intervalEnd
Основная:
CREATE FUNCTION [dbo].[Difference_Company_m_City_1] (
@intervalStart datetime2(7),
@intervalEnd datetime2(7)
)
RETURNS TABLE AS RETURN
SELECT
tie.CP_m_CY_1_ChangedAt as [Time_of_Change],
tie.CP_ID_m as [Company_m_Id],
tie.CY_ID_1 as [City_1_Id]
FROM
[dbo].[dCP_m_CY_1](@intervalStart, @intervalEnd) tie
56
Что касается темпоральных представлений (views), то во 2 главе уже упоминалось об их
разновидностях
в
методологии
Anchor
Modeling.
Приведем
пример
последнего
представления, позволяющего собрать данные из одного якоря и всех прилежащих к нему
атрибутов, выбирая при этом только последний актуальный набор для темпоральных
атрибутов:
SELECT
CP.CP_ID, CP.Metadata_CP, CID.CP_CID_CP_ID, CID.Metadata_CP_CID,
CID.CP_CID_Company_CompanyId, NAM.CP_NAM_CP_ID, NAM.Metadata_CP_NAM,
NAM.CP_NAM_Company_OfficName, COD.CP_COD_CP_ID, COD.Metadata_CP_COD,
COD.CP_COD_Company_Code, SNM.CP_SNM_CP_ID, SNM.Metadata_CP_SNM,
SNM.CP_SNM_Company_ShortName, INN.CP_INN_CP_ID, INN.Metadata_CP_INN,
INN.CP_INN_Company_Inn, LAD.CP_LAD_CP_ID, LAD.Metadata_CP_LAD,
LAD.CP_LAD_Company_LegalAddress, FAD.CP_FAD_CP_ID, FAD.Metadata_CP_FAD,
FAD.CP_FAD_ChangedAt, FAD.CP_FAD_Company_FactAddress
FROM
dbo.CP_Company AS CP LEFT OUTER JOIN
dbo.CP_CID_Company_CompanyId AS CID ON CID.CP_CID_CP_ID = CP.CP_ID LEFT OUTER
JOIN
dbo.CP_NAM_Company_OfficName AS NAM ON NAM.CP_NAM_CP_ID = CP.CP_ID LEFT OUTER
JOIN
dbo.CP_COD_Company_Code AS COD ON COD.CP_COD_CP_ID = CP.CP_ID LEFT OUTER JOIN
dbo.CP_SNM_Company_ShortName AS SNM ON SNM.CP_SNM_CP_ID = CP.CP_ID LEFT OUTER
JOIN
dbo.CP_INN_Company_Inn AS INN ON INN.CP_INN_CP_ID = CP.CP_ID LEFT OUTER JOIN
dbo.CP_LAD_Company_LegalAddress AS LAD ON LAD.CP_LAD_CP_ID = CP.CP_ID LEFT OUTER
JOIN
dbo.CP_FAD_Company_FactAddress AS FAD ON FAD.CP_FAD_CP_ID = CP.CP_ID AND
FAD.CP_FAD_ChangedAt =
(SELECT
MAX(CP_FAD_ChangedAt)
FROM
dbo.CP_FAD_Company_FactAddress AS sub
WHERE
(CP_FAD_CP_ID = CP.CP_ID))
Теперь приведем пример, представления, позволяющего получить текущий набор данных
по атрибутам,
относящимся к определенному якорю. Для этого вызываем моментную
функцию с параметром текущая дата (sysdatetime):
SELECT
CR_ID, Metadata_CR, CR_CID_CR_ID, Metadata_CR_CID,
CR_CID_Contractor_ContractorId, CR_NAM_CR_ID, Metadata_CR_NAM,
CR_NAM_Contractor_ShortName, CR_ONA_CR_ID, Metadata_CR_ONA,
CR_ONA_Contractor_OfficName, CR_LAD_CR_ID, Metadata_CR_LAD,
CR_LAD_Contractor_LegalAddress, CR_LAS_CR_ID, Metadata_CR_LAS, CR_LAS_ChangedAt,
CR_LAS_Contractor_FactAddress
FROM
dbo.pCR_Contractor(sysdatetime())
Таким образом, функции и представления позволяют позволяют получить данные из ХД в
различных темпоральных проекциях, а именно: последней, моментной и интервальной.
В довершение всего, проследует информация о триггерах, контролирующих добавление
данных в ХД. Для добавления данных и контроля версий используется Insert-триггер:
57
ALTER TRIGGER [dbo].[itRS_m_CR_1] ON [dbo].[lRS_m_CR_1]
INSTEAD OF INSERT
AS
BEGIN
DECLARE @now datetime2(7) = sysdatetime();
DECLARE @maxVersion int;
DECLARE @currentVersion int;
DECLARE @inserted TABLE (
Metadata_RS_m_CR_1 int not null,
RS_ID_m int not null,
CR_ID_1 int not null,
primary key (
RS_ID_m
)
);
INSERT INTO @inserted
SELECT
ISNULL(i.Metadata_RS_m_CR_1, 0),
i.RS_ID_m,
i.CR_ID_1
FROM
inserted i
WHERE
i.RS_ID_m is not null;
INSERT INTO [dbo].[RS_m_CR_1] (
Metadata_RS_m_CR_1,
RS_ID_m,
CR_ID_1
)
SELECT
i.Metadata_RS_m_CR_1,
i.RS_ID_m,
i.CR_ID_1
FROM
@inserted i
LEFT JOIN
[dbo].[RS_m_CR_1] tie
ON
tie.RS_ID_m = i.RS_ID_m
WHERE
tie.RS_ID_m is null;
END
Контроль удаления данных осуществляется при помощи Delete-триггера:
ALTER TRIGGER [dbo].[dtPD_Product] ON [dbo].[lPD_Product]
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE [PID]
FROM
[dbo].[PD_PID_Product_ProductId] [PID]
JOIN
deleted d
ON
d.PD_PID_PD_ID = [PID].PD_PID_PD_ID
DELETE [NAM]
FROM
[dbo].[PD_NAM_Product_Name] [NAM]
JOIN
deleted d
ON
58
d.PD_NAM_PD_ID = [NAM].PD_NAM_PD_ID
DELETE [PRO]
FROM
[dbo].[PD_PRO_Product_Producer] [PRO]
JOIN
deleted d
ON
d.PD_PRO_PD_ID = [PRO].PD_PRO_PD_ID
DELETE [PRC]
FROM
[dbo].[PD_PRC_Product_Price] [PRC]
JOIN
deleted d
ON
d.PD_PRC_PD_ID = [PRC].PD_PRC_PD_ID
AND
d.PD_PRC_ChangedAt = [PRC].PD_PRC_ChangedAt;
DELETE [ART]
FROM
[dbo].[PD_ART_Product_Article] [ART]
JOIN
deleted d
ON
d.PD_ART_PD_ID = [ART].PD_ART_PD_ID
DELETE [PD]
FROM
[dbo].[PD_Product] [PD]
LEFT JOIN
[dbo].[PD_PID_Product_ProductId] [PID]
ON
[PID].PD_PID_PD_ID = [PD].PD_ID
LEFT JOIN
[dbo].[PD_NAM_Product_Name] [NAM]
ON
[NAM].PD_NAM_PD_ID = [PD].PD_ID
LEFT JOIN
[dbo].[PD_PRO_Product_Producer] [PRO]
ON
[PRO].PD_PRO_PD_ID = [PD].PD_ID
LEFT JOIN
[dbo].[PD_PRC_Product_Price] [PRC]
ON
[PRC].PD_PRC_PD_ID = [PD].PD_ID
LEFT JOIN
[dbo].[PD_ART_Product_Article] [ART]
ON
[ART].PD_ART_PD_ID = [PD].PD_ID
WHERE
[PID].PD_PID_PD_ID is null
AND
[NAM].PD_NAM_PD_ID is null
AND
[PRO].PD_PRO_PD_ID is null
AND
[PRC].PD_PRC_PD_ID is null
AND
[ART].PD_ART_PD_ID is null;
END
59
Для таблиц с темпоральными полями дополнительно определяется Update-триггер:
ALTER TRIGGER [dbo].[utSD_m_WH_1] ON [dbo].[lSD_m_WH_1]
INSTEAD OF UPDATE
AS
BEGIN
DECLARE @now datetime2(7) = sysdatetime();
IF(UPDATE(SD_ID_m))
RAISERROR('The identity column SD_ID_m is not updatable.', 16, 1);
INSERT INTO [dbo].[SD_m_WH_1] (
Metadata_SD_m_WH_1,
SD_ID_m,
WH_ID_1,
SD_m_WH_1_ChangedAt
)
SELECT
i.Metadata_SD_m_WH_1,
i.SD_ID_m,
i.WH_ID_1,
u.SD_m_WH_1_ChangedAt
FROM
inserted i
CROSS APPLY (
SELECT
CASE WHEN UPDATE(SD_m_WH_1_ChangedAt) THEN i.SD_m_WH_1_ChangedAt
ELSE @now END
) u (
SD_m_WH_1_ChangedAt
);
END
60
3.4 ETL-модуль
После того, как ХД построено и есть источник данных, необходимо особым образом
обеспечить загрузку данных из источника в ХД. Для этого нужно сформировать ЕTL-модуль,
содержащий множество трансформаций, предназначенных для очистки и загрузки данных в
определенные компоненты модели ХД. На этапе ETL-процессов происходит заполнение
модели метаданными, необходимыми для отслеживания темпоральных изменений в данных,
пришедших из источника. Далее рассмотрим особенности загрузки в компоненты модели
Anchor.
Загрузка якорей и атрибутов
Ранее уже была отмечена возможность в СУБД MS SQL Server загрузки данных в
представления. Это дает нам преимущество, заключающееся в создании всего одной
трансформации для заполнения как якоря, так и связанных с ним атрибутов. В этом случае
данные из источника грузятся в Latest представление, в котором уже собраны все
необходимые элементы. Таким образом, производится загрузка одновременно нескольких
таблиц.
Для обеспечения процесса загрузки, первым делом нужно создать соединение (connection)
с источником и ХД (Рис. 27).
Рисунок 27. Создание соединения с источником данных
После этого, соединение можно расшарить и использовать его всякий раз при создании
новой трансформации. Простая трансформация загрузки якоря без темпоральных атрибутов
включает в себя извлечение данных из источника, мэппинг с существующими данными в ХД
61
и отслеживание загрузки. Если загрузка была, то не загружать данные повторно, в противном
случае, проводить загрузку, заполнив при этом поле с метаданными. Для наглядности далее
приведен пример простой трансформации с загрузкой якоря City и всех его атрибутов (Рис.
28).
Рисунок 28. Пример загрузки якоря City без темпоральных атрибутов.
Что касается загрузки компонента с темпоральными атрибутами, то помимо отслеживания
загрузки данных, добавляется необходимость отслеживать исторические изменения в
темпоральных атрибутах, а также добавление меток времени (Рис. 29).
Рисунок 29. Пример загрузки якоря Product c темпоральными атрибутами.
Загрузка узлов
В отличие от якорей, загрузка узлов требует двух отдельных трансформаций: сначала
произвести загрузку в таблицу для узла, затем грузить данные в представление, содержащее
62
поля атрибута, а также связанные с ним поля узла. Аналогично загрузке якорей, в данном
случае также происходит заполнение метаданных, а также отслеживание загрузки. Пример
второй трансформации представлен на рисунке 30.
Рисунок 30. Пример загрузки узла ContractType.
Загрузка связей
Трансформации для связей подобно трансформациям для якорей делятся на два вида:
простые загрузки для нетемпоральных связей и сложные для темпоральных. В первом
случае, данные извлекаются из источника, затем происходит мэппинг (mapping) с
соответствующими таблицами ХД, после чего происходит отслеживание загрузки с
последующим заполнением метаданных. Пример простой загрузки связей представлен на
рисунке 31.
Рисунок 31. Пример загрузки простой связи ReservationHeader_m_Responsible_1.
Во
втором
случае,
для
отслеживания
темпоральных
изменений,
добавляется
дополнительное условие на идентификаторы данных, пришедших из источника, а также
появляются метки времени (Рис. 32).
Рисунок 32. Пример загрузки темпоральной связи CustomerOrderHeder_m_OrderStatus_1.
Итого,
построено
154
трансформации.
Реализация
ETL-модуля
есть
довольно
нетривиальный процесс ввиду высокой нормализации и темпорализации ХД. После создания
63
всех трансформаций их необходимо объединить в единый поток загрузки (job), который в
дальнейшем может запускаться по заранее установленному расписанию. Отметим, что при
построении цепочки трансформаций нужно соблюдать определенный порядок загрузки, а
именно: первым делом грузятся узлы, потом якори и атрибуты, далее грузятся узлы, и только
в конце грузятся связи. Более того, модель Anchor позволяет параллельно проводить загрузку
перечисленных компонентов. Фрагмент итогового потока с загрузкой узлов, якорей и
атрибутов представлен на рисунке 33.
Рисунок 33. Загрузка узлов, якорей и атрибутов.
64
3.5 Создание многомерной виртуальной витрины
После того как обеспечена загрузка данных в ХД, необходимо спроектировать и создать
многомерную виртуальную витрину данных, преобразовав существующую модель ХД в
многомерную модель, состоящую из отдельных подвитрин. Каждая такая подвитрина
представляет собой денормализованную схему «звезда», отражающую определенный бизнеспроцесс.
Таким образом, необходимо создать специальную область между ХД и пользователем,
содержащую данные в агрегированном виде. Ввиду денормализации витрины доступ к
данным значительно упрощается и ускоряется. В данной работе будем рассматривать
Закупки и Продажи в качестве фактов.
Схема звезды Продажи представлена в общем виде на рисунке 34. Схема звезды Закупки
выглядит аналогично.
Рисунок 34. Схема звезды «Продажи».
После этого, на основе спроектированной модели необходимо создать OLAP-куб для
возможности многомерного анализа данных. Выделим основные измерения для фактов
Закупки и Продажи:
1. Контрагент.
2. Компания.
3. Ответственный.
4. Договор.
5. Склад.
6. Товар.
65
Также определим иерархии для измерений:
1. Тип контрагента - вышестоящий контрагент – контрагент.
2. Родительская компания – компания.
3. Вышестоящий ответственный – ответственный.
4. Тип договора – договор.
5. Тип склада – склад.
6. Тип товара – товарная линия – товар.
В качестве мер определим следующие показатели: количество закупок, количество
продаж, сумма закупок, сумма продаж, количество документов.
Для реализации куба воспользуемся инструментом MS SQL Server Analysis Services.
Порядок действий при этом следующий:
1. Настроить соединение с ХД (data source).
2. Создать представление данных (data source view).
3. Создать измерения, объединить в иерархии, обозначить ключи.
4. Создать особое измерение «Календарь», обеспечивающее связь существующих
измерений и фактов с временной линией.
5. Создать группы мер, обозначить функции агрегирования.
6. Настроить связи между измерениями и фактами.
7. Обеспечить обработку NULL-значений.
8. Собрать (process) и развернуть (deploy) куб на сервере.
66
3.6 Встраивание инструмента визуализации данных
Теперь, когда многомерная виртуальная витрина построена, необходимо обеспечить
визуализацию данных, чтобы конечный пользователь мог проводить анализ самостоятельно
без помощи IT-специалиста, выбирая из модели данные по нужным измерениям и фактам.
Существует множество инструментов для визуализации данных. В общем виде для работы с
ними выполняются следующие действия:
1. Разворачивается определенный BI-сервер.
2. Проверяется, поддерживает ли выбранный инструмент работу с многомерными
базами (в данном случае с MS SQL Server Analysis Services). При этом
устанавливаются
нужные
драйверы,
проводятся
работы,
связанные
с
администрированием компьютера (сервера), а также сервера баз данных.
3. Настраивается соединение с моделью данных (с OLAP-кубом).
4. Создается стенд (dashboard) или отчет (report), включающий таблицы/графики с
данными из многомерной витрины.
Большинство инструментов визуализации, поддерживающих соединение с многомерными
источниками,
является
коммерческими
продуктами.
Поскольку
в
данной
работе
используются в основном продукты Microsoft, возьмем в качестве инструмента визуализации
MS Excel. Настроим соединение с многомерной витриной и получим следующий результат:
Рисунок 35. Пример визуализации OLAP-куба в MS Excel.
67
Заключение
Проектирование и создание СППР на основе темпорального ХД – очень трудоемкий и
затратный процесс, требующий не только высокой квалификации разработчика, но также
внимания и аккуратности. Тем не менее, использование такого рода систем дает
существенное конкурентное преимущество, ведь лица, принимающие решения, могут
извлечь огромную пользу из ключевого компонента СППР – темпорального ХД. Оно
предоставляет наиболее точную информацию о текущем состоянии бизнеса, поскольку
позволяет отслеживать исторические изменения данных.
В данной работе представлен анализ существующих архитектур СППР, выявлены их
достоинства и недостатки. Также рассмотрены особенности построения темпорального ХД
по инновационной методологии Anchor Modeling, предлагающей создание гибкой модели в
6NF. После этого подробно описаны решения поставленных в работе задач, а именно:
1. Проанализирована учетная система, выявлены бизнес-процессы, на основе которых
спроектирована и создана реляционная база-источник данных.
2. Спроектировано и создано темпоральное ХД по методологии Anchor Modeling.
3. Реализован ETL-модуль очистки и загрузки данных из источника в ХД.
4. Спроектирована
и
построена
многомерная
виртуальная
витрина
поверх
темпорального ХД.
5. Встроен инструмент визуализации данных для проведения дальнейшего анализа.
Результатом работы стала готовая СППР на основе темпорального ХД, представляющего
из себя гибкую легко расширяемую модель, хранящую все версии темпоральных данных
независимо друг от друга. Более того, реализованная модель позволяет быстро изменять
структуру данных, подстраиваясь под новые бизнес требования, исключая необходимость
полного перепроектирования. Таким образом, СППР позволяет повысить качество
принимаемых решений за счет отслеживания изменений данных во времени (темпоральность
ХД), а также глубины анализа данных (многомерность витрины).
В дальнейшей работе можно встроить данную СППР в реальную организацию,
работающую с учетной системой «1С.Управление торговлей». Для этого необходимо
обеспечить модуль загрузки данных из системы в базу-источник данных. Более того, можно
обеспечить сценарии загрузки, оперирующие сразу с несколькими источниками данных.
Также СППР может быть улучшена путем встраивания аналитических инструментов,
обладающих более широкой функциональностью, в частности, возможностью проведения
интеллектуального анализа данных (data mining).
68
Список использованных источников
1. Anchormodeling.com, 'Three concepts of Time in Anchor Models', 2015. [Электронный
ресурс]. URL: http://www.anchormodeling.com/wpcontent/uploads/2010/08/Three_Concepts_of_Time_in_Anchor_Models.pdf [Дата
обращения: 20.04.2015].
2. Breslin, M. Data warehousing battle of the giants, Business Intelligence Journal, vol.9, no.
1, 2004.
3. Habrahabr.ru, 'HP Vertica, проектирование хранилища данных, больших данных', 2014.
[Электронный ресурс]. URL: http://habrahabr.ru/post/227111/ [Дата обращения:
22.04.2015].
4. Inmon, W. Building the Data Warehouse, 3rd Edition. New York:Wiley, 2002.
5. Inmon, W., Imhoff, C., and Sousa, R. Corporate information factory. New York: John
Wiley & Sons, 2002.
6. Intuit.ru, 'Обработка и хранение информации | Лекция | НОУ ИНТУИТ', 2015.
[Электронный ресурс]. URL:
http://www.intuit.ru/studies/courses/13860/1257/lecture/24002?page=5 [Дата обращения:
16.04.2015].
7. Irkinfo.ru, 'Информационные хранилища | IT-технологии', 2015. [Электронный ресурс].
URL: http://www.irkinfo.ru/informatsionnye-khranilishcha.html [Дата обращения:
16.04.2015].
8. Iso.ru, 'Сходство И Различия Двух Подходов К Архитектуре Хранилищ Данных', 2005.
[Электронный ресурс]. URL: http://www.iso.ru/print/rus/document6083.phtml [Дата
обращения: 18.04.2015].
9. Kimball, R., and Ross, M. The data warehouse toolkit: the complete guide to dimensional
modelling. New York: Wiley, 2002.
10. Knowles, C. 6NF Conceptual Models and Data Warehousing 2.0. InProceedings of the
Southern Association for Information Systems Conference, 160-165, 2012.
11. Linstedt, D., and Graziano, K. Introduction to Data Vault Modeling, USA, 2011.
12. Němec, R. The Comparison of Anchor and Star Schema from a Query Performance
Perspective. World Academy of Science, Engineering and Technology, 71, 1718-1722, 2012.
13. Němec, R., & Zapletal, F. The Design of Multidimensional Data Model Using Principles of
the Anchor Data Modeling: An Assessment of Experimental Approach Based on Query
Execution Performance. WSEAS Transactions on Computers, 13, 2014.
69
14. Nižetić, I., Fertalj, K., & Milašinović, B. An Overview of Decision Support System
Concepts. In Proceedings of the 18th International Conference on Information and
Intelligent Systems/Boris Aurer and Miroslav Bača (ur.). Varaždin, 251-256, 2007.
15. Ranjan, J. Business intelligence: Concepts, components, techniques and benefits. Journal of
Theoretical and Applied Information Technology, 9(1), 60-70, 2009.
16. Regardt, O., Rönnbäck, L., Bergholtz, M., Johannesson, P. 'Anchor Modeling'. Proceedings
of the 28th International Conference on Conceptual Modeling. ER '09 (Gramado, Brazil:
Springer-Verlag): 234–250, 2009.
17. Rönnbäck, L., Regardt, O., Bergholtz, M., Johannesson, P., and Wohed, P. Anchor
modeling—Agile information modeling in evolving data environments, Data & Knowledge
Engineering, vol. 69, 12, 1229-125, 2010.
18. Sites.google.com, 'BI технологии - Управление знаниями', 2015. [Электронный ресурс].
URL: https://sites.google.com/site/upravlenieznaniami/tehnologii-upravlenia-znaniami/bitehnologii [Дата обращения: 09.04. 2015].
19. TAdviser.ru, 'Большие данные (Big Data). ИТ-Директору, BI, Cloud Computing, Data
Mining, ГИС - Геоинформационные системы, ЦОД, Центры обработки данных технологии для ЦОД, Россия', 2015. [Электронный ресурс]. URL:
http://www.tadviser.ru/index.php/Статья:Большие_данные_(Big_Data) [Дата обращения:
22.04.2015].
20. Tdan.com. 'Data Vault Series 1 - Data Vault Overview', 2015. [Электронный ресурс].
http://www.tdan.com/view-articles/5054/ [Дата обращения: 18.04.2015].
21. ЗАО «Сервис бар». 'Сервис Бар. Прайс лист на все товары' , 2011. [Электронный
ресурс]. URL: http://servis-bar.ru/catalog/page.php [Дата обращения: 04.01.2015].
22. ООО «1С». '1С:Предприятие8. Управление торговлей', 2015. [Электронный ресурс].
URL: http://v8.1c.ru/trade/ [Дата обращения: 5.04.2015].
23. Пучков, Е. 'Методы и системы поддержки принятия управленческих решений', 2015.
[Электронный ресурс]. URL: http://i-intellect.ru/business-intelligence/decision-supportsystems.html [Дата обращения: 9.04.2015].
70