И.А. КУЗНЕЦОВ Научный руководитель – А.И. ГУСЕВА, д.т.н., профессор НЕСТРУКТУРИРОВАННЫХ ДАННЫХ
реклама

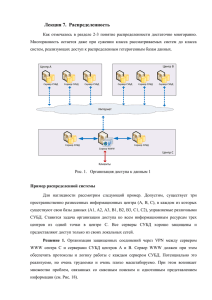
И.А. КУЗНЕЦОВ Научный руководитель – А.И. ГУСЕВА, д.т.н., профессор Национальный исследовательский ядерный университет «МИФИ» ПОДХОДЫ К ХРАНЕНИЮ БОЛЬШИХ ОБЪЕМОВ НЕСТРУКТУРИРОВАННЫХ ДАННЫХ Управление и хранение больших объемов данных вызывают определенные проблемы. Существующие СУБД не справляются с нарастающим объемом данных, ввиду чего были предложены новые методы управления большими объемами данных. Повсеместное распространение интернета приводит к экспоненциальному росту объемов данных. По прогнозам, к 2020 году, объем цифровой информации достигнет 40 зеттабайт. Традиционные системы хранения данных не позволяют работать с такими объемами данных, которые стали называться Big Data [1]. Под «большими данными» понимается набор данных, который обладает рядом характеристик [2]: 1. Объем – генерируются новые данные, как людьми, так и машинами, появляются новые требования к хранению данных; 2. Разнообразие – вся информация является разнообразной и имеет разную структуру; 3. Скорость – важным критерием является не только скорость получения, но также важна скорость обработки данных; 4. Ценность – способность с помощью полученных данных дать ответы на интересующие вопросы. На текущий момент, для хранения «больших данных» используются распределенные файловые системы. При использовании реляционных СУБД, рано или поздно будет достигнут предел, при котором сервер не сможет обрабатывать нарастающие объемы данных. Определив, что традиционные СУБД не дают возможности работать с «большими данными» появились подходы, способные решить поставленную задачу. Инженеры компании Google предложили распределенную файловую систему GFS в совокупности с вычислительной моделью MapReduce. GFS строилась исходя из ряда критериев: состоит из большого количества недорогого оборудования, который может давать сбои и следовательно должна существовать система мониторинга, с возможностью восстановить функционирование системы; файлы делятся на блоки данных, которые в основном читаются или увеличиваются в размерах, но не перезаписываются; файлы обрабатываются на нескольких серверах одновременно. Распределенная файловая система представлена на рисунке 1: Рисунок 1. Распределенная файловая система GFS Файлы в GFS организованы иерархически, при помощи каталогов, как и в любой другой файловой системе, и идентифицируются своим путем. С файлами в GFS можно выполнять обычные операции: создание, удаление, открытие, закрытие, чтение и запись. Система состоит фактически из двух составляющих: мастер-сервер (головной сервер) и чанк-сервер (фрагментарный сервер). Вся информация хранится на фрагментарном сервере, информация на которых может реплицироваться (обычно используется три реплики). При этом вся информация разбивается на фрагменты размером 64 мегабайта. Доступ клиента осуществляется напрямую к фрагментарному серверу, однако всю информацию о текущем положении фрагментарного сервера, контроль доступа к серверу, отображение файлов и прочее осуществляет головной сервер. Также головной сервер отвечает за управление свободными фрагментарными серверами, перемещение фрагментов между фрагментарными серверами и сборку мусорных файлов. Список литературы 1. 2. Рост объема информации - реалии цифровой вселенной. - Журнал "Технологии и средства связи" #1, 2013 П.А. Клеменков, С.Д. Кузнецов - Большие данные: современные подходы к хранению и обработке. - Труды ИСП РАН, 2012, том 23