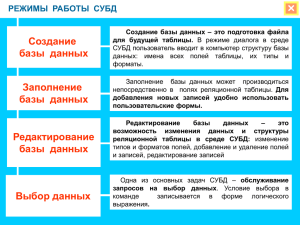
1. Базы данных. Основные определения: информация, данные, БД,
СУБД, АИС.
Информация - сведения (сообщения, данные) независимо от формы их
представления (из 149-ФЗ). Подробнее - лекция № 1 по информатике.
Данные - это информация, представленная в определенном виде,
позволяющем автоматизировать ее сбор, хранение и дальнейшую обработку
человеком или информационным средством. Для компьютерных технологий
данные это информация в дискретном, фиксированном виде, удобная для
хранения, обработки на ЭВМ, а также для передачи по каналам связи.
База данных (БД) - это именованная совокупность данных,
отражающая состояние объектов и их отношений в рассматриваемой
предметной области, или иначе БД - это совокупность взаимосвязанных
данных при такой минимальной избыточности, которая допускает их
использование оптимальным образом для одного или нескольких приложений
в определенной предметной области. БД состоит из множества связанных
файлов.
Система управления базами данных (СУБД) - совокупность
языковых и программных средств, предназначенных для создания. ведения и
совместного использования БД многими пользователями.
Автоматизированная информационная система (АИС) - это система,
реализующая автоматизированный сбор, обработку, манипулирование
данными, функционирующая на основе ЭВМ и других технических средств и
включающая соответствующее программное обеспечение (ПО) и персонал.
Автоматизированная информационная система (АИС)
АИС, основанная на базе данных, служит для сбора, накопления,
хранения информации, а также е её эффективного использования для
поставленных целей. Информация представляется в виде данных, хранимых в
памяти ЭВМ. При проектировании АИС, с одной стороны, решается вопрос о
том, какие сведения и для каких целей будут содержаться в системе, с другой
- как соответствующие данные будут организованы в памяти ЭВМ и как они
будут обрабатываться при эксплуатации АИС.
По сферам применения и правилам организации различают два
основных класса АИС, основанных на базе данных: информационнопоисковые (ИПС) и системы обработки данных (СОД).
Информационно-поисковые системы (ИПС)
ИПС ориентированы, как правило, на извлечение подмножества
хранимых данных, удовлетворяющих некоторому поисковому критерию.
Пользователя ИПС интересуют, в основном, сами извлекаемые из базы данных
сведения, а не результаты их обработки. Примером ИПС является любая
справочная служба: к ней обращаются с запросом и получают в результате те
данные, которые удовлетворяют этому запросу.
Любой браузер.
Системы обработки данных (СОД)
Обращения пользователя к СОД чаще всего приводят к обновлению
данных. Вывод данных может вовсе отсутствовать или представлять собой
результат программной обработки хранимых сведений. Пример СОД - ИАС
Университет, которая ведет учет успеваемости студентов, формирует сводные
таблицы документы.
2. Виды пользователей БД. Их функционал и зоны ответственности.
1) Прикладные программисты. Отвечают за написание прикладных
программ, использующих базу данных. Прикладные программы получают
доступ к базе данных посредством выдачи соответствующего запроса к СУБД
(обычно это некоторый оператор SQL). Подобные программы могут быть
простыми
пакетными
предложениями
или
же
интерактивными
приложениями, предназначенными для поддержки работы конечных
пользователей. Они предоставляют пользователям непосредственный
оперативный доступ к базе данных через рабочую станцию, терминал или
персональный компьютер.
2) Конечные пользователи. Работают с системой баз данных в
интерактивном режиме. Конечный пользователь может получать доступ к базе
данных, применяя интерактивные приложения или же интерфейс,
интегрированный в программное обеспечение самой СУБД.
3) Администраторы базы данных. Отвечают за общее управление
системой и базами данных на техническом уровне.
3. Уровни архитектуры СУБД.
Одним из важнейших аспектов развития СУБД является идея отделения
логической структуры БД и манипуляций данными, необходимыми
пользователям, от физического представления, требуемого компьютерным
оборудованием.
Одна и та же БД в зависимости от точки зрения может иметь различные
уровни описания. По числу уровней описания данных, поддерживаемых
СУБД, различают одно-, двух- и трехуровневые системы.
В настоящее время чаще всего поддерживается трехуровневая
архитектура описания БД, с тремя уровнями абстракции, на которых можно
рассматривать базу данных.
Трехуровневая архитектура состоит из:
1) внешнего уровня, на котором пользователи воспринимают данные, и
отдельные группы пользователей имеют свое представление на базу данных;
(фронтэнд)
2) внутреннего уровня, на котором СУБД и операционная система
воспринимают данные; (бэкенд)
3) концептуального уровня представления данных, который предназначен для
отображения внешнего уровня на внутренний уровень, а также для
обеспечения необходимой их независимости друг от друга.
Описание структуры данных на любом уровне называется схемой.
Существует три различных типа схем базы данных, которые
определяются в соответствии уровнями абстракции трехуровневой
архитектуры.
На самом высоком уровне имеется несколько внешних схем или
подсхем, которые соответствуют разным представлениям данных.
На концептуальном уровне описание базы данных называют
концептуальной схемой, а на самом низком уровне абстракции внутренней
схемой.
Основным назначением трехуровневой архитектуры является
обеспечение независимости от данных. Суть этой независимости
заключается в том, что изменения на нижних уровнях никак не влияют на
верхние уровни.
Различают два типа независимости от данных: логическую и
физическую.
Логическая независимость (независимость фронтэнда) от данных
означает полную защищенность внешних схем от изменений, вносимых
концептуальную схему. Такие изменения концептуальной схемы, как
добавление или удаление новых сущностей, атрибутов или связей, должны
осуществляться без необходимости внесения изменений в уже существующие
внешние схемы для других групп пользователей.
Физическая независимость(независимость бэкенда) от данных
означает защищенность концептуальной схемы от изменений, вносимых во
внутреннюю схему.
Такие изменения внутренней схемы, как использование различных
файловых систем или структур хранения, разных устройств хранения,
модификация индексов или хеширование, должны осуществляться без
необходимости внесения изменений в концептуальную или внешнюю схемы.
Это абстракция так как в реальности уровни зависимы друг от друга.
4. Функции СУБД.
1) Управление данными во внешней памяти.
2) Управление транзакциями.
3) Восстановление базы данных.
4) Поддержка языков БД.
5) Управление параллельным доступом
6) Управление буферами в оперативной памяти
7) Контроль доступа к данным
8) Поддержка целостности данных
Управление данными во внешней памяти
Данная
функция предоставляет пользователям возможности
выполнения самых основных операций, которые осуществляются с данными,
это сохранение, извлечение и обновление информации.
Она включает в себя обеспечение необходимых структур внешней
памяти как для хранения данных, непосредственно входящих в БД, так и для
служебных целей, например для ускорения доступа к данным.
Управление транзакциями
Транзакция - это последовательность операций над БД,
рассматриваемых СУБД как единое целое. Транзакция представляет собой
набор действий, выполняемых с целью доступа или изменения содержимого
базы данных.
Примерами простых транзакций может служить добавление,
обновление или удаление в базе данных сведений о некоем объекте. Сложная
же транзакция образуется в том случае, когда в базу данных требуется внести
сразу несколько изменений. Инициализация транзакции может быть вызвана
отдельным пользователем или прикладной программой.
Транзакция говорит нам, что мы выполняем все условия, либо не
выполняем ничего. Нельзя выполнить что-то частично. Одна из главных
задач, так как сохраняет целостность БД.
Восстановление базы данных
Одним из основных требований к СУБД является надежность хранения
данных во внешней памяти. Под надежностью хранения понимается то, что
СУБД должна быть в состоянии восстановить последнее согласованное
состояние БД после любого аппаратного или программного сбоя. Обычно
рассматриваются два возможных вида аппаратных сбоев:
a) мягкие сбои, которые можно трактовать как внезапную остановку
работы компьютера (например, аварийное выключение питания);
б) жесткие сбои, характеризуемые потерей информации на носителях
внешней памяти.
Поддержание надежности хранения данных в БД требует избыточности
хранения данных.
Наиболее распространенным методом поддержания такой избыточной
информации является ведение журнала изменений БД.
Поддержка языков БД
Для работы с базами данных используются специальные языки,
называемые языками баз данных.
B
современных
СУБД
обычно
поддерживается
единый
интегрированный язык, содержащий все необходимые средства для работы с
БД, начиная от ее создания, и обеспечивающий базовый пользовательский
интерфейс
с
базами
данных.
Стандартным
языком
наиболее
распространенных B настоящее время реляционных СУБД является язык SQL
(Structured Query Language язык структурированных запросов). Язык SQL
позволяет определять схему реляционной БД и манипулировать данными.
Управление параллельным доступом
Одна из основных целей создания и применения СУБД заключается в
организации параллельного доступа множества пользователей к совместно
обрабатываемым данным.
Параллельный доступ сравнительно просто организовать, если все
пользователи выполняют только чтение данных, поскольку в этом случае они
не могут помешать друг другу.
Однако, когда два или больше пользователей одновременно получают
доступ к базе данных, конфликт с нежелательными последствиями легко
может возникнуть, например, если хотя бы один из них попытается обновить
данные.
СУБД должна гарантировать, что при одновременном доступе к базе
данных нескольких пользователей подобных конфликтов не произойдет.
Управление буферами в оперативной памяти
В настоящее время, СУБД работают с БД значительного размера. И если
при обращении к любому элементу данных будет производиться обмен с
внешней памятью, то вся система будет работать со скоростью устройств
внешней памяти. Практически единственным способом реального увеличения
этой скорости является буферизация данных в оперативной памяти. В
современных СУБД поддерживается собственный набор буферов в
оперативной памяти с собственной дисциплиной управления ими и
предвыборки данных.
Контроль доступа к данным
B настоящее время СУБД должна иметь механизмы, гарантирующие
возможность доступа к базе данных только санкционированных
пользователей и защищающие ее от любого несанкционированного доступа.
В современных СУБД поддерживается один из двух широко
распространенных подходов к вопросу обеспечения безопасности данных:
избирательный подход или обязательный подход.
B большинстве современных систем предусматривается избирательный
подход, при котором каждый пользователь обладает набором прав для работы
с разными объектами БД.
Во втором, обязательном подходе, каждому объекту данных
присваивается классификационный уровень, пользователю - уровень допуска
каждому.
Поддержка целостности данных
Термин целостность используется для описания корректности и
непротиворечивости хранимых в БД данных. Реализация поддержки
целостности данных предполагает, что СУБД должна содержать сведения о
тех правилах, которые нельзя нарушать при работе с данными, и обладать
инструментами контроля за тем, чтобы данные и их изменения
соответствовали заданным правилам.
5. Модель данных. Определение и состав.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Модель данных состоит из:
1) Структурной части - типы данных и правила их использования.
2) Части управления (Управляющей части) набор операторов и команд,
которые могут быть применены к любым правильным типам данных, чтобы
искать, вводить, выводить или преобразовывать информацию, содержащуюся
в любых типах данных в любых комбинациях.
3) Части обеспечения целостности - набор общих правил целостности,
которые прямо или косвенно определяют множество непротиворечивых
состояний базы данных и/или множество изменений её состояния. Нужно для
того, чтобы делать бэкапы и не терять данные.
6. Модель данных. Определение и классификация.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Классификация моделей данных:
- объектные модели данных;
- модели данных на основе записей;
- физические модели данных.
Первые две категории используются для описания данных на внешнем
и концептуальном уровнях, а последняя категория - на внутреннем уровне.
Виды моделей:
- ER- модели
- Объектно-ориентированные модели
7. Модель данных. ER-модели.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
ER-модели ER-модель (от англ. Etity-Relationship model, модель
«сущность - связь») - модель данных, позволяющая описывать
концептуальные схемы предметной области.
ER-модель используется при концептуальном (высокоуровневом)
проектировании баз данных. С её помощью выделяются ключевые сущности
и обозначаются связи, которые сущностями. устанавливаются между этими.
При проектировании баз данных происходит преобразование схемы,
созданной на основе ER-модели, в конкретную схему базы данных на основе
выбранной модели данных (реляционной, объектной, сетевой или др.).
ER-модель представляет собой формальную конструкцию, которая сама
по себе не предписывает никаких графических средств её визуализации. В
качестве стандартной графической нотации, с помощью которой можно
визуализировать ER-модель, была предложена диаграмма «сущность-связь»
(англ. Entity- Relationship diagram, ERD, ER-диаграмма).
ER-модели Основной способ представления ER-моделей в виде
диаграмм предложен Питером Ченом в 1976 году.
Множества сущностей изображаются в виде прямоугольников,
множества отношений изображаются в виде ромбов. Если сущность участвует
в отношении, они связаны линией. Если отношение не является обязательным,
то линия пунктирная. Атрибуты изображаются в виде овалов и связываются
линией с одним отношением или с одной сущностью.
Для визуализации ER-моделей могут быть использованы любые другие
подходящие графические нотации или визуализация может вообще не
применяться (то есть быть только текстовое описание).
8. Модель данных. Объектно-ориентированные модели.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Объектно-ориентированная модель представляет собой структуру,
которую можно изобразить графически в виде дерева, узлами которого
являются объекты. Между записями базы данных и функциями их обработки
устанавливаются связи с помощью механизмов, подобных тем, которые
имеются в объектно- ориентированных языках программирования. Такая
модель позволяет идентифицировать отдельные записи базы. целью.
Определяемый пользователем объект называют объектом.
Поиск в объектно-ориентированной базе состоит в выяснении сходства
между объектом, задаваемым пользователем, и объектами, хранящимися в
базе.
Базовыми понятиями этой модели являются: объекты, классы, методы,
инкапсуляция, наследование, полиморфизм.
По своей сути это попытка применить идеологию объектноориентированного программирования к технологии баз данных.
Достоинствами этой модели являются возможность отображения
информации о сложных взаимосвязях объектов и возможность
идентификации отдельных записей в базе данных и определения для них
функций обработки.
Недостатками являются высокая сложность и малая скорость работы.
Модели данных на основе записей
Делятся на:
1) теоретико-графовые (ТГ):
а) сетевые модели.
б) иерархические модели.
2) теоретико-множественные (ТМ):
а) реляционные модели.
9. Модели данных. Сетевая модель.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Сетевая модель опирается на математическую структуру. которая
называется направленным графом. Направленный граф состоит из узлов,
соединенных ребрами. В контексте моделей данных узлы представляют собой
объекты в виде типов записей данных, а ребра - связи между объектами. Эти
связи могут быть «один к одному» или «один ко многим».
Иерархическая модель данных является частным случаем сетевой
модели.
Структуры данных:
1) Элемент данных - наименьшая поименованная единица данных, к
которой СУБД может обращаться непосредственно и с помощью которой
выполняется построение всех остальных структур. Для каждого элемента
данных должен быть определён его тип (не структурный, а простой).
2) Агрегат данных - поименованная совокупность элементов данных
внутри записи, которую можно рассматривать как единое целое. Агрегат
может быть простым (включающим только элементы данных) и составным
(включающим наряду с элементами данных и другие агрегаты).
Агрегат фактически является следующим уровнем обобщения модели
данных.
3) Запись - поименованная совокупность элементов данных или
элементов данных и агрегатов. Является агрегатом, не входящим в состав
никакого другого агрегата.
Она может иметь сложную иерархическую структуру, поскольку
допускается многократное применение агрегации.
Различают тип записи (её структуру) и экземпляр записи, т.е. запись с
конкретными значениями элементов данных. Одна запись описывает свойства
одной сущности предметной области (экземпляра).
Иногда термин «запись» заменяют термином «группа».
Среди элементов данных (полей записи) выделяются одно или
несколько ключевых полей. Значения ключевых полей позволяют
классифицировать сущность, к которой относится конкретная запись. Ключи
с уникальными значениями называются потенциальными. Каждый ключ
может представлять собой агрегат данных. Один из ключей назначается
первичным, остальные являются вторичными. Первичный ключ
идентифицирует экземпляр записи, его значение должно быть уникальным и
обязательным для записей одного типа. К единице хранения мы присваиваем
номер.
4) Набор (или групповое отношение) - поименованная совокупность
записей, образующих двухуровневую иерархическую структуру. Каждый тип
набора представляет собой связь между двумя или несколькими типами
записей. Для каждого типа набора один тип записи объявляется владельцем
набора, остальные типы записи объявляются членами набора. Каждый
экземпляр набора должен содержать только один экземпляр записи типа
владельца и столько экземпляров записей типа членов набора, сколько их
связано с владельцем. Для группового отношения также различают тип и
экземпляр.
10.Модели данных. Иерархическая модель.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Основными информационными единицами в иерархической модели
данных являются сегмент и поле.
Поле данных определяется как наименьшая неделимая единица данных,
доступная пользователю.
Для сегмента определяются тип сегмента и экземпляр сегмента.
Экземпляр сегмента образуется из конкретных значений полей данных.
Тип сегмента - это поименованная совокупность входящих в него типов
полей данных. Сегмент стал записью, он стал полем записи.
Иерархическая модель представляет собой связный неориентированный
граф древовидной структуры, объединяющий сегменты. Иерархическая БД
состоит из упорядоченного набора деревьев.
Древовидная система иерархий. Чем дальше вниз по иерархии, тем больше
данных; если есть направление, то модель ориентированная.
Дерево - это связный неориентированный граф, который не содержит
циклов. При работе с деревом выделяют какую-то конкретную вершину,
определяют её как корень дерева и рассматривают особо - в эту вершину не
заходит ни одно ребро. В этом случае дерево становится ориентированным,
ориентация определяется от корня.
Дерево как ориентированный граф определяется образом:
- имеется единственная особая вершина, называемая корнем, в которую
не заходит ни одно ребро;
- во все остальные вершины заходит только одно ребро, а исходит
произвольное количество ребер; а у бинарных деревьев выхода только два;
- граф не содержит циклов.
Конечные вершины, то есть вершины, из которых не выходит ни одной
дуги, называются листьями дерева. Количество вершин на пути от корня к
листьям в разных ветвях дерева может быть различным.
Не может иметь циклов и несколько входов; Дерево частный случай
графов.
Иерархическая модель является предшественником сетевой модели, но
в настоящее время рассматривается как её частный случай. В иерархической
модели данных вершине графа соответствует тип сегмента или просто
сегмент, а дугам типы связей предок - потомок. В иерархических структурах
сегмент потомок должен иметь в точности одного предка.
11. Модели данных. Реляционная модель. Определение. Достоинства.
Недостатки.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Из лекции ИТМО:
Реляционная модель - совокупность данных, состоящая из набора
двумерных таблиц. В теории множеств таблице соответствует термин
отношение (relation), физическим представлением которого является таблица,
отсюда и название модели – реляционная. Соответственно теория построения
баз данных, которая является приложением к задачам обработки данных таких
разделов математики, как теория множеств и логика первого порядка.
В сравнении с иерархической и сетевой моделью данных, реляционная
модель отличается более высоким уровнем абстракции данных.
Реляционная модель является удобной и наиболее привычной формой
представления данных, так в настоящее время эта модель является
фактическим стандартом, на который ориентируются практически все
современные коммерческие СУБД. На реляционной модели данных строятся
реляционные базы данных.
Достоинства
● Изложение информации в простой и понятной для пользователя форме
(таблица).
● Реляционная модель данных основана на строгом математическом
аппарате, что позволяет лаконично описывать необходимые операции над
данными.
● Независимость данных от изменения в прикладной программе при
изменении.
● Позволяет создавать языки манипулирования данными не процедурного
типа.
● Для работы с моделью данных нет необходимости полностью знать
организацию БД.
Недостатки
● Относительно медленный доступ к данным.
● Трудность в создании БД основанной на реляционной модели.
● Трудность в переводе в таблицу сложных отношений.
● Требуется относительно большой объем памяти.
Из нашей лекции (нет точно определения и четких недостатков):
Реляционная модель данных (РМД) была предложена в 1970 г.
математиком Эдгаром Коддом (Codd E.F.). Она является наиболее широко
распространенной моделью данных и единственной из трёх основных моделей
данных, для которой разработан теоретический базис с использованием
теории множеств.
В своей статье «A Relational Model of Data for Large Shared Data Banks»,
вышедшей в свет в 1970 году, Э. Кодд показал, что любое представление
данных сводится к совокупности двумерных таблиц особого вида, известного
в математике как отношение (relation).
Положив теорию отношений в основу реляционной модели, он
обосновал реляционную замкнутость отношений и ряда некоторых
специальных операций, которые применяются сразу ко всему множеству
строк отношения, а не к отдельной строке. Указанная реляционная
замкнутость означает, что результатом выполнения операций над
отношениями является также отношение, над которым в свою очередь можно
осуществить некоторую операцию.
Из вышеуказанного следует, что в реляционной модели можно
оперировать реляционными выражениями, а не только отдельными
операндами в виде простых имен таблиц.
Одним из основных преимуществ реляционной модели является ее
однородность. Все данные рассматриваются как хранимые в таблицах и только
в таблицах. Каждая строка такой таблицы имеет один и тот же формат.
К числу достоинств реляционного подхода можно отнести:
- наличие небольшого набора абстракций, которые позволяют
сравнительно просто моделировать большую часть распространенных
предметных областей и допускают точные формальные определения,
оставаясь интуитивно понятными;
- наличие простого и в то же время мощного математического аппарата,
опирающегося главным образом на теорию множеств и математическую
логику и обеспечивающего теоретический базис реляционного подхода к
организации БД;
- возможность ненавигационного манипулирования данными без
необходимости знания конкретной физической организации баз данных во
внешней памяти. В настоящее время не является достоинством, так как
появилось трехуровневая модели БД.
12. Модели данных. Реляционная модель. Двенадцать правил Кодда.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Кодд сформулировал двенадцать правил,
соответствовать настоящая реляционная база данных:
которым
должна
1. Правило информации. Вся информация в базе данных должна быть
представлена исключительно на логическом уровне и только одним способом
- в виде значений, содержащихся в таблицах.
2. Правило гарантированного доступа. Логический доступ ко всем и
каждому элементу данных (атомарному значению) в реляционной базе данных
должен обеспечиваться путем использования комбинации имени таблицы,
первичного ключа и имени столбца.
3. Правило поддержки недействительных значений. В настоящей
реляционной базе данных должна быть реализована поддержка
недействительных значений, которые отличаются от строки символов нулевой
длины, строки пробельных символов и от нуля или любого другого числа и
используются для представления отсутствующих данных независимо от типа
этих данных.
4. Правило динамического каталога, основанного на реляционной
модели. Описание базы данных на логическом уровне должно быть
представлено в том же виде, что и основные данные, чтобы пользователи,
обладающие соответствующими правами, могли работать с ним с помощью
того же реляционного языка, который они применяют для работы с основными
данными
5. Правило исчерпывающего подъязыка данных. Реляционная система
может поддерживать различные языки и режимы взаимодействия с
пользователем (например, режим вопросов и ответов). Однако должен
существовать, по крайней мере, один язык, операторы которого можно
представить в виде строк символов в соответствии с некоторым четко
определенным синтаксисом и который в полной мере поддерживает
следующие элементы:
- определение данных;
- определение представлений;
- обработку данных (интерактивную и программную);
- условия целостности;
- идентификацию прав доступа;
- границы транзакций (начало, завершение и отмена).
6. Правило обновления представлений. Все представления, которые
теоретически можно обновить, должны быть доступны для обновления.
7. Правило добавления, обновления и удаления. Возможность работать с
отношением как с одним операндом должна существовать не только при
чтении данных, но и при добавлении, обновлении и удалении данных.
8. Правило независимости физических данных. Прикладные программы и
утилиты для работы с данными должны на логическом уровне оставаться
нетронутыми при любых изменениях способов хранения данных или методов
доступа к ним.
9. Правило независимости логических данных. Прикладные программы и
утилиты для работы с данными должны на погическом уровне оставаться
нетронутыми при внесении в базовые таблицы любых изменений, которые
теоретически позволяют сохранить нетронутыми содержащиеся в этих
таблицах данные.
10. Правило независимости условий целостности. Должна существовать
возможность определять условия целостности, специфические для конкретной
реляционной базы данных, на подъязыке реляционной базы данных и хранить
их в каталоге, а не в прикладной программе.
11. Правило независимости распространения. Реляционная СУБД не
должна зависеть от потребностей конкретного клиента.
12. Правило единственности. Если в реляционной системе есть
низкоуровневый язык (обрабатывающий одну запись за один раз), то должна
отсутствовать возможность использования его для того, чтобы обойти правила
и условия целостности, выраженные на реляционном языке высокого уровня
(обрабатывающем несколько записей за один раз).
13. Модели данных. Реляционная модель. Домены. Кортежи.
Отношения. Атрибуты.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Базовой структурой реляционной модели данных является отношение,
основанное на декартовом произведении доменов.
Домен - это множество значений, которое может принимать элемент
данных (например, множество целых чисел, множество дат, множество
комбинаций символов длиной N и т.п.). Домен может задаваться
перечислением элементов, указанием диапазона значений, функцией и т.д.
Пусть D1, D2 …, Dk, - произвольные конечные и не обязательно
различные множества (домены). Декартово произведение этих множеств
определяется следующим образом:
D1 ×D2×…×Dk = {(d1, d2,…, dk) | di Di, i = 1,…k}
Таким образом, декартово произведение позволяет получить все
возможные комбинации значений элементов исходных множеств.
Пример.
Для доменов D1 = (1, 2), D2, = (А, B, C) декартово произведение D = D1 х D2,
будет таким: D = {(1,A), (1,B), (1,C), (2,A), (2,B), (2,C)}.
Подмножество
отношением.
декартова
произведения
доменов
называется
Отношения используются для представления сущностей, а также для
представления связей между сущностями.
Отношение - это двумерная таблица, имеющая уникальное имя и
состоящая из строк и столбцов, где строки соответствуют записям, а столбцы
- атрибутам.
Каждая строка в таблице представляет некоторый объект реального
мира или соотношения между объектами.
Атрибут - это поименованный столбец отношения. Свойства сущности,
его характеристики определяются значениями атрибутов.
Порядок следования атрибутов не влияет на само отношение.
Элементы отношения называют кортежами (или записями). Каждый
кортеж отношения соответствует одному экземпляру сущности
определённого типа. Атрибуты таблицы, атрибуты кортежи.
Элементы кортежа принято называть атрибутами (или полями).
Множество кортежей называется телом отношения. Тело отношения
отражает состояние сущности, поэтому во времени оно постоянно меняется.
Тело отношения характеризуется кардинальным числом, которое равно
количеству содержащихся в нем кортежей.
Одной из главных характеристик отношения является его степень.
Степень отношения определяется количеством атрибутов, которое в нем
присутствует. Эта характеристика отношения имеет еще названия: ранг и
арность. Отношение с одним атрибутом называется унарным, с двумя
атрибутами - бинарным, с тремя - тернарным, с п атрибутами п-арным.
Определение
отношения.
степени
отношения
осуществляется
по
заголовку
14.Модели данных. Реляционная модель. Свойства отношений.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Реляционная модель - совокупность данных, состоящая из набора
двумерных таблиц. В теории множеств таблице соответствует термин
отношение (relation), физическим представлением которого является таблица,
отсюда и название модели – реляционная. Соответственно теория построения
баз данных, которая является приложением к задачам обработки данных таких
разделов математики, как теория множеств и логика первого порядка.
Отношение - это двумерная таблица, имеющая уникальное имя и
состоящая из строк и столбцов, где строки соответствуют записям, а столбцы
- атрибутам. Каждая строка в таблице представляет некоторый объект
реального мира или соотношения между объектами.
Свойства отношений:
Отношение по структуре подобно таблице, но таблице, обладающей
определенными свойствами. Сведем воедино все свойства отношения:
1) Отношение имеет имя, которое отличается от имен всех других
отношений.
2) Отношение представляется в виде табличной структуры.
3) Каждый атрибут имеет уникальное имя, его значения берутся из
одного и того же домена.
4) Каждый компонент кортежа является простым, атомарным
значением, не состоящим из группы значений.
5) Упорядочение атрибутов теоретически несущественно, однако оно
может влиять на эффективность доступа к кортежам.
6) Все строки (кортежи) должны быть различны.
7) Теоретически порядок следования кортежей не имеет значения.
15.Модели данных. Реляционная модель. Виды отношений.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Реляционная модель - совокупность данных, состоящая из набора
двумерных таблиц. В теории множеств таблице соответствует термин
отношение (relation), физическим представлением которого является таблица,
отсюда и название модели – реляционная. Соответственно теория построения
баз данных, которая является приложением к задачам обработки данных таких
разделов математики, как теория множеств и логика первого порядка.
Отношение - это двумерная таблица, имеющая уникальное имя и
состоящая из строк и столбцов, где строки соответствуют записям, а столбцы
- атрибутам. Каждая строка в таблице представляет некоторый объект
реального мира или соотношения между объектами.
Виды отношений:
В реляционной теории встречается несколько видов отношений, но не
все они поддерживаются реальными системами. Различают:
1) Именованное отношение — это переменная отношения,
определенная в СУБД посредством специальных операторов.
2) Базовое отношение — это именованное отношение, являющееся
частью базы данных.
3) Производное отношение — это отношение, определенное
посредством реляционного выражения через базовые отношения.
4) Представление — это именованное виртуальное производное
отношение, представленное в системе исключительно через определение в
терминах других именованных отношений.
5) Снимки — это отношения, подобные представлениям, но они
сохраняются, доступны для чтения и периодически обновляются.
6) Результат запроса — это неименованное производное отношение,
получаемое в результате запроса, которое для сохранения необходимо
преобразовать в именованное отношение.
7) Хранимое отношение — это отношение, которое поддерживается в
физической памяти.
В отношении могут существовать несколько одиночных или составных
атрибутов, которые однозначно идентифицируют кортеж отношения. Это
потенциальные ключи.
16. Модели данных. Реляционная модель. Ключи.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Реляционная модель - совокупность данных, состоящая из набора
двумерных таблиц. В теории множеств таблице соответствует термин
отношение (relation), физическим представлением которого является таблица,
отсюда и название модели – реляционная. Соответственно теория построения
баз данных, которая является приложением к задачам обработки данных таких
разделов математики, как теория множеств и логика первого порядка.
Отношение - это двумерная таблица, имеющая уникальное имя и
состоящая из строк и столбцов, где строки соответствуют записям, а столбцы
- атрибутам. Каждая строка в таблице представляет некоторый объект
реального мира или соотношения между объектами.
В отношении могут существовать несколько одиночных или составных
атрибутов, которые однозначно идентифицируют кортеж отношения. Это -потенциальные ключи.
Говорят, что множество атрибутов К = {A, A1, …, Ak} отношения r
является потенциальным ключом r тогда и только тогда, когда
удовлетворяются два независимых от времени условия:
-уникальность: в произвольный заданный момент времени никакие два
различных кортежа r не имеют одного и того же значения для Aj, A1, …, Акі
-минимальность: ни один из атрибутов A1, А, …, Ак не может быть
исключен из К без нарушения уникальности.
Отношение может иметь несколько потенциальных ключей. Ключ,
содержащий два и более атрибута, называется составным ключом. Каждое
отношение обладает хотя бы одним возможным ключом, поскольку в
отношении не может быть одинаковых кортежей, а это значит, что, по
меньшей мере, комбинация всех его атрибутов удовлетворяет условию
уникальности. Потенциальные ключи, позволяя гарантированно выделить
точно один кортеж, обеспечивают основной механизм адресации на уровне
кортежей реляционной модели.
Один из возможных ключей (выбранный произвольным образом)
принимается за его первичный ключ. Обычно первичным ключом
назначается тот возможный ключ, которым проще всего пользоваться при
повседневной работе. Остальные возможные ключи, если они есть,
называются альтернативными ключами.
Для индикации связи между отношениями используются внешние
ключи.
Внешний ключ - это набор атрибутов одного отношения, являющийся
потенциальным ключом другого отношения.
Благодаря наличию связок между потенциальными и внешними
ключами обеспечивается взаимосвязь кортежей определенных отношений.
Отношение, содержащее внешний ключ, называется дочерним или
ссылающимся отношением. А отношение, содержащее связанный с
внешним ключом потенциальный ключ, - родительским или целевым
отношением.
Отношения не могут рассматриваться как статические объекты, так как
они предназначены для отражения некоторой части реального мира, а эта
часть реального мира может изменяться во времени. Поэтому и отношения
изменяются во времени: кортежи могут добавляться, удаляться или
модифицироваться. Тем не менее, предполагается, что сама схема отношения
инвариантна во времени.
НЕ из лекции, простыми словами:
Первичный ключ – это одно поле, которое используется для
обеспечения уникальности данных в таблице. Это означает, что значение
(информация) в поле первичного ключа в каждой строке (записи) таблицы
может быть уникальным.
Внешний ключ – это одно или несколько полей (атрибутов), которые
являются первичными в другой таблице и значение которых заменяется
значениями первичного ключа другой таблицы.
Рекурсивный внешний ключ – это внешний ключ, который ссылается
на одну и ту же таблицу, к которой он принадлежит. В этом случае поле
(атрибут), которое соответствует внешнему ключу, есть ключом одного и того
же отношения (связи).
Первичный, вторичный и внешний ключи могут быть как простыми, так
и составными (сложными). Простые ключи – это ключи, которые содержат
только одно поле (один атрибут). Составные ключи (сложные) – это ключи,
которые содержат несколько полей (атрибутов).
Примеры:
17. Модели данных. Реляционная модель. Целостность БД.
Модель данных - это совокупность правил порождения структур
данных в базе данных, операций над ними, а также ограничений целостности,
определяющих допустимые связи и значения данных, последовательность их
изменения.
Модель данных - это некоторая абстракция, в которой отражаются
самые важные аспекты функционирования выделенной предметной области, а
второстепенные - игнорируются. Модель данных включает в себя набор
понятий для описания данных, связей между ними и ограничений,
накладываемых на данные.
Реляционная модель - совокупность данных, состоящая из набора
двумерных таблиц. В теории множеств таблице соответствует термин
отношение (relation), физическим представлением которого является таблица,
отсюда и название модели – реляционная. Соответственно теория построения
баз данных, которая является приложением к задачам обработки данных таких
разделов математики, как теория множеств и логика первого порядка.
Поддержка целостности базы данных реализуется посредством ряда
ограничений, накладываемых на данные.
Первый тип ограничений проистекает из того факта, что каждый атрибут
определяется на своем домене, или наоборот: домен атрибута задает
множество значений, которые может принимать атрибут. Указанное
ограничение называется ограничением атрибута.
Важными понятиями в теории реляционных баз данных являются
категорная целостность и целостность на уровне ссылок.
Категорная целостность ограничивает набор значений первичных
ключей базовых отношений. Такого рода целостность заключается в
следующем: кортеж не может записываться в БД до тех пор, пока значения его
ключевых атрибутов не будут полностью определены.
Иными словами: никакой ключевой атрибут любого кортежа отношения
не может содержать отсутствующего значения, обозначаемого определителем
NULL.
Целостность на уровне ссылок. При построении отношений для
связывания строк одной таблицы со строками другой таблицы используются
внешние ключи. База данных, в которой все непустые внешние ключи
ссылаются на текущие значения ключей другого отношения, обладает
целостностью на уровне ссылок.
Определение условия целостности данных обычно осуществляется при
установлении взаимосвязи между родительским и дочерним отношениями;
при этом пользователю часто предоставляется возможность самому решить,
каким путем сохранять целостность базы данных и насколько жестко должно
соблюдаться условие целостности при различных операциях изменения
данных.
Так, например, при изменении значения первичного ключа в
родительском отношении обычно на выбор разрешены следующие варианты
действий, из которых два первых - обеспечивают нахождение базы данных в
целостном непротиворечивом состоянии.
1) При изменении значений полей первичного ключа в родительском
отношении автоматически осуществляется каскадное изменение всех
соответствующих значений в дочернем отношении.
2) Не позволяется изменять значения полей первичного ключа в
родительском отношении, если в дочернем отношении имеется хотя бы одна
запись, содержащая ссылку на изменяемую запись.
3) Позволяется изменять значения полей первичного ключа в
родительском отношении, независимо от существования связанных записей в
дочернем отношении. Целостность данных при этом не поддерживается.
При удалении записи в родительском отношении также возможны
несколько вариантов действий.
1) При удалении записи в родительском отношении автоматически
осуществляется каскадное удаление всех записей из дочернего отношения,
связанных с удаляемой записью.
2) Не позволяется удалять записи в родительском отношении, если в
дочернем отношении имеется хотя бы одна запись, содержащая ссылку на
удаляемую запись. При попытке удаления записи возникает ошибка, которую
можно обработать программно.
3) Позволяется удалять записи в родительском отношении независимо
от существования связанных записей в дочернем отношении. (Очевидно, что
целостность данных при этом че поддерживается.)
При добавлении новой записи в дочернее отношение или
редактировании в нем существующей записи возможно выбрать один из
вариантов:
1) Не позволяется вводить запись, если значение индексного выражения
дочернего отношения не соответствует одной из записей в родительском
отношении.
2) При вводе данных в дочернее отношение не анализируется значение
индексного выражения. Аналогично, целостность данных при этом не
поддерживается.
Еще один вид ограничений, накладываемый на информацию,
содержащуюся в отношениях, связан с теми бизнес-правилами, которые
существуют в данной организации или в моделируемой предметной области.
Это так называемые дополнительные правила поддержки целостности
данных, определяемые пользователем или администратором данных, которые
называются корпоративными ограничениями целостности.
Например:
-студентам нельзя планировать занятия продолжительностью более восьми
часов в день;
-студенты весь день должны заниматься в одном корпусе вуза, чтобы не
требовалось дополнительное время на переходы из одного здания в другое
или должно быть учтено время на этот переход/переезд.
18. Проектирование БД. Аномалии.
Аномалиями будем называть такую ситуацию в таблицах БД, которая
приводит к противоречиям в БД, либо существенно усложняет обработку
данных.
Избыточность данных в БД относится к нежелательным явлениям,
поскольку ведет к увеличению объема памяти, необходимого для
физического хранения отношений. Избыточность вызывается, прежде всего,
дублированием данных.
В данном отношении с первичным ключом «шифр студ» в каждом
кортеже о каждом студенте из одной и той же группы повторяются сведения
о коде группы, старосте и кураторе.
При работе с отношениями, содержащими избыточные данные, могут
возникнуть проблемы, которые называются аномалиями обновления.
Различают три вида аномалий в базе данных:
-аномалии включения;
-аномалии удаления;
-аномалии модификации.
Аномалия включения
В приведенном ранее примере отношения, аномалии включения
возникают при попытке создать новую группу и ввести ее в отношение при
том условии, что в нее еще не зачислен ни один студент. Ввод такой
информации в подобной ситуации требует присвоения значения NULL всем
атрибутам описания студента, в том числе и атрибуту «шифр_студ», который
является первичным ключом данного отношения. Но реализация такой
попытки приведет к нарушению категорной целостности, а значит, система
ее обязана отклонить.
Аномалии добавления возникают в случаях, когда информацию в таблицу
нельзя поместить до тех пор, пока она неполная, либо вставка новой записи
требует дополнительного просмотра таблицы.
Результатом анализа является вывод о том, что в отношении
присутствуют аномалии включения, а, следовательно, это отношение должно
быть преобразовано таким образом, чтобы от них избавиться.
Особенностью аномалий включения является то, что есть методы борьбы с
ними: первый – принудительно не включать неполную информацию об
объекте, возвращая ошибку, это делается при помощи принудительного
правила об ограничении целостности в доменах, второй способ включать
информацию, не накладывая ограничения целостности, но при этом,
ситуация с информационной целостность БД нарушается, нарушая
структуру. Так, например, в случае, если у товара в интернет-магазине не
будет указан тип, но в магазине будет поиск по типу, этот товар из поиска
пропадет. Так работать не должно!
Структура отношений, содержащая ту же информацию, что и
отношение СТУДЕНТ, но лишенная аномалий включения, представлена в
табл. 6.2 и 6.3.
Аномалия удаления
Аномалии удаления состоят в том, что при удалении какого-либо данного из
таблицы может пропасть и другая информация, которая не связана напрямую
с удаляемым данным.
Решение ситуации с аномалией удаления является более сложной, чем две
другие аномалии, но в нормализованных БД – эта проблема решаема.
Аномалия модификации
Аномалии модификации (или редактирования) проявляются в том,
что изменение значения одного данного может повлечь за собой просмотр
всей таблицы и соответствующее изменение некоторых других записей
таблицы.
Есть некоторые методы борьбы с ними, например, написание триггеров на
редактирование на таблиц, принудительно ставя доп.проверки на данные,
этот метод хорош в том случае, если администраторы БД не знакомы с ее
внутренней логикой, в случае, с магазином, хотят изменить количество
товаров заказанных и полученных в поставке, допустим, связанные с браком
товара, в таком случае СУБД должна выдать дополнительную проверку на
то, почему количество товара хотят изменить.
Такая аномалия возникает при попытке изменить что-либо касающееся
сведений о группе обучения студента. Допустим, что в группе РХБО-01-20
решили назначить нового старосту, например, Сенову А.Л.
B такой ситуации необходимо просмотреть все кортежи отношения и в
каждом кортеже значение атрибута «Староста» заменить Лебедь К.А. на
Сенова А.Л.
Появлении аномалии модификации можно заблокировать, если опять
же прибегнуть к преобразованию исходного отношения.
Эти преобразования точно такие же, которые были использованы для
исключения аномалий включения и удаления. Тогда смена старосты группы
требует изменения значения атрибута «Староста» только в одном кортеже
отношения ГРУППА.
Декомпозиция
Важно помнить, что в случае, если при проверке БД возникают
различного рода аномалии – это свидетельствует о неправильной схеме БД,
следует вернуться к процессу нормализации и решить его снова. Чтобы
исключить различного рода аномалии из отношения, его подвергают
процессу декомпозиции. При решении задачи декомпозиции возникают две
проблемы.
Первая проблема - это проблема обратимости, заключающаяся в
возможности восстановления исходной схемы, а именно - восстановления
любого кортежа исходного отношения, используя кортежи полученных в
результате декомпозиции отношений. Декомпозиция, удовлетворяющая
этому требованию, называется декомпозицией, гарантирующей отсутствие
потерь.
Вторая проблема связана с сохранением зависимостей. Следует
помнить, что проектирование базы данных включает в себя и определение
ограничений, накладываемых на ее отношения. В процессе декомпозиции
получаются новые отношения и ограничения, которые приписываются им,
должны быть такими, чтобы были сохранены исходные ограничения.
Все сказанное означает, что проводимая декомпозиция должна
сохранять эквивалентность схем при замене одной схемы на другую, т.е.
нужна декомпозиция, гарантирующая отсутствие потерь и сохранение
зависимостей.
19. Проектирование БД. Нормализация. Виды НФ.
Процесс нормализации отношений - это формальный метод анализа
отношений на основе их первичных или потенциальных ключей и
существующих функциональных зависимостей. Он включает ряд
формальных правил, используемых для проверки всех отношений базы
данных. Различают:
1НФ -- первую нормальную форму;
2НФ - вторую нормальную форму;
ЗНФ - третью нормальную форму;
НФБК - нормальную форму Бойса - Кодда;
4НФ - четвертую нормальную форму;
5НФ - пятую нормальную форму.
Каждая нормальная форма налагает определенные ограничения на
данные. Эти ограничения вводятся в каждом конкретном отношении, и
соблюдение этих ограничений в отношении связано уже с наличием
нормальной формы.
1НФ, 2НФ, ЗНФ - ограничивают зависимость непервичных атрибутов
от ключей.
НФБК - ограничивает зависимость первичных атрибутов.
4НФ - формулирует ограничения на виды многозначных зависимостей.
5НФ - вводит другие типы зависимостей: зависимости соединений.
Процесс перехода от нормальной формы более низкого уровня к
нормальной форме более высокого уровня и называется нормализацией
отношений (НО).
Для реляционных баз данных необходимо, чтобы все отношения базы
данных обязательно находились в 1НФ. Нормальные формы более высокого
порядка могут использоваться разработчиками по своему усмотрению.
Однако следует стремиться к тому, чтобы довести уровень нормализации
базы данных хотя бы до ЗНФ, тем самым, исключив из базы данных
избыточность данных и аномалии обновления.
Аксиома вывода - это правило, устанавливающее, что если отношение
удовлетворяет определенным F-зависимостям, то оно должно удовлетворять
к некоторым другим F-зависимостям. (Прим. Скорее всего не нужно, но было
в лекции)
Ниже приведены шесть аксиом вывода для F-зависимостей. В их
формулировках используется обозначение r для отношения на R, и W, X, У, Z
для подмножеств R. Запишем кратко все аксиомы.
F1. Рефлексивность: XY -> X.
F2. Пополнение: X -> Y влечет за собой XZ -> Y.
F3. Аддитивность: X -> Y и X -> Z влечет за собой X -> YZ.
F4. Проективность: X -> YZ влечет за собой X -> Y.
F5. Транзитивность: X -> Y и Y -> Z влечет за собой X -> Z.
F6. Псевдотранзитивность: X -> Y и YZ -> W влечет за собой XZ -> W.
20. Проектирование БД. Нормализация. 1НФ. 2НФ.
Первая нормальная форма
Отношение находится в первой нормальной форме, если все его
атрибуты имеют простые (атомарные) значения. Другими словами, значения
в домене каждого атрибута отношения не являются ни списками, ни
множествами простых или сложных значений.
Определить понятия атомарности трудно. Значение, атомарное в одном
приложении, может быть неатомарным в другом. Можно руководствоваться
общим принципом, что значение не атомарно, если в приложении оно
используется по частям.
Если значение атрибута Дата рождения предполагается использовать
целиком, то в этом случае данное отношение «РОЖДЕНИЕ 1» находится в
1НФ. Если бы потребовалось выделить и отдельно использовать, скажем,
год, число, месяц, то это отношение не находилось бы в 1НФ, так как
требуемые данные являются только частями значения атрибута Дата
рождения. Чтобы перевести такое отношение в 1НФ, атрибут Дата рождения
должен быть разбит на части так, как показано в отношении «РОЖДЕНИЕ
2».
НЕ из лекции, простыми словами:
Требование первой нормальной формы очень простое и оно
заключается в том, чтобы таблицы соответствовали реляционной модели
данных и соблюдали определённые реляционные принципы.
Таким образом, чтобы база данных находилась в 1 нормальной форме,
необходимо чтобы ее таблицы соблюдали следующие реляционные
принципы:
В таблице не должно быть дублирующих строк
В каждой ячейке таблицы хранится атомарное значение (одно не
составное значение)
В столбце хранятся данные одного типа
Отсутствуют массивы и списки в любом виде
Вторая нормальная форма
Вторая и третья нормальные формы возникли в результате стремления
избежать аномапий обновления данных при работе с БД и избавиться от
информационной избыточности в отношениях.
Вторая нормальная форма применяется к отношениям с составными
ключами, т. е. к таким отношениям, первичный ключ которых состоит из
двух или более атрибутов. Отношение, у которого первичный ключ включает
только один атрибут, всегда находится во 2НФ.
Определение 1. Атрибут называется посторонним для
функциональной зависимости X -> Y, если он может быть удален из правой
или левой части функциональной зависимости Гез изменений транзитивного
замыкания F+ множества F.
Определение 2. Функциональная зависимость X -> Y называется
редуцированной слева, если Х не содержит атрибута Z, постороннего для
функциональной зависимости X -> Y. Если функциональная зависимость X > Y редуцирована слева, то Y является полностью зависящим от X. В
противном случае Y частично зависит от Х.
Определение 3. Для данной схемы отношения R атрибут А в R и
множество функциональных зависимостей F на R атрибут A называется
первичным в R относительно F, если А содержится в каком-нибудь ключе
схемы R. В противном случае А называется непервичным в R.
Схема отношения R находится во 2НФ относительно F, если она
находится в 1НФ, и каждый непервичный атрибут функционально полно
зависит от первичного ключа.
Схема всей БД имеет 2НФ относительно F, если каждая ее схема
отношения находится относительно F во 2НФ.
Рассмотрим отношение КОНСУЛЬТАЦИИ ДИПЛОМНИКОВ со
схемой:
(Таб_Ном_преп, Ном_зач_кн, Дата, ФИО_преп, Должность, ФИО_студ,
Тема_диплома, Время, Аудитория, Вместимость).
Это отношение содержит информацию о том, какой преподаватель
консультирует определенного дипломника, а также дату, время консультации
и аудиторию с ее вместимостью, где она должна проводиться. Обозначим
основные зависимости этого отношения.
(Таб_Ном преп, Ном зач кн, Дата) -> (ФИО_преп, Должность, ФИО_студ,
Тема_липлома, Время, Аудитория, Вместимость).
Описательные атрибуты преподавателя ФИО_преп, Должность зависят
только от части первичного ключа. Данную ситуацию определяет
зависимость:
Таб-Ном преп -> (ФИО_преп, Должность).
Описательные атрибуты студента ФИО_студ, Тема_диплома также
зависят только от части первичного ключа и не зависят от остальных
атрибутов ключа, то есть имеется зависимость вида: Ном_зач_кн ->
(ФИО_студ. Тема__диплома).
Отсутствие полной функциональной зависимости каждого
непервичного атрибута отношения от первичного ключа, как и в других
рассмотренных здесь примерах, является источником аномалий обновления и
вносит свою долю избыточности в базу данных. Устранение данных
отрицательных явлений осуществляется путем декомпозиции исходного
отношения на три со следующими схемами:
ПРЕПОДАВАТЕЛЬ (Таб_Ном_преп, ФИО_преп, Должность); СТУДЕНТ
(Ном_зач_кн, ФИО_студ, Тема_диплома); КОНСУЛЬТАЦИИ
(Таб_Ном_преп, Ном_зач_кн, Дата, Время, Аудитория, Вместимость).
НЕ из лекции, простыми словами:
Чтобы база данных находилась во второй нормальной форме (2NF),
необходимо чтобы ее таблицы удовлетворяли следующим требованиям:
Таблица должна находиться в первой нормальной форме
Таблица должна иметь ключ
Все неключевые столбцы таблицы должны зависеть от полного ключа (в
случае если он составной)
Главное правило: таблица должна иметь правильный ключ, по
которому можно идентифицировать каждую строку.
21.Проектирование БД. Нормализация. 3НФ. НФБК.
Третья нормальная форма
Рассмотрим транзитивную зависимость следующего типа: если A -> В,
В /> А (В не является ключом), В -> С, то А -> С.
В этом случае считается, что С транзитивно зависит от А.
Транзитивная зависимость вызвана наличием в отношении двух
семантических зависимостей различных типов.
Схема отношения находится в третьей нормальной форме
относительно множества функциональных зависимостей F, если она
находится в 1НФ и ни один из непервичных атрибутов в R не является
транзитивно зависимым от ключа для R.
Схема всей БД находится в ЗНФ относительно F, если каждая схема
отношения находится в ЗНФ относительно F.
Вернемся, к примеру схемы отношения КОНСУЛЬТАЦИИ
ДИПЛОМНИКОВ.
ПРЕПОДАВАТЕЛЬ (Таб_Ном_преп, ФИО_преп, Должность);
СТУДЕНТ (Ном зач_кн, ФИО_студ, Тема_диплома);
КОНСУЛЬТАЦИИ (Таб_Ном_преп, Ном_зач_кн, Дата, Время,
Аудитория, Вместимость).
Последнее отношение содержит транзитивную зависимость:
(Таб_Ном_преп, Ном_зач_кн, Дата) -> Аудитория -> Вместимость.
Исходя из транзитивной зависимости можно сделать вывод, что это
отношение не находится в ЗНФ со всеми вытекающими из этого
последствиями, и прежде всего следующими:
-если аудитория исключается из расписания консультаций, то о ней
вообще теряются сведения;
-если аудитория перестроена и в результате изменилась ее
вместимость, то придется просмотреть все кортежи и провести модификацию
значений атрибута.
Для устранения транзитивной зависимости необходимо провести
декомпозицию последнего отношения, удалив из него транзитивнозависимый атрибут и поместив его в новое отношение вместе с копией того
атрибута, от которого он зависит.
Таким образом, база данных этого примера, лишенная транзитивных
зависимостей, в ЗНФ будет выглядеть так:
ПРЕПОДАВАТЕЛЬ (Таб_Ном_преп, ФИО_преп, Должность);
СТУДЕНТ Ном зач кн, ФИО студ, Тема диплома);
КОНСУЛЬТАЦИИ (Таб_Ном_преп, Ном_зач_кн, Дата, Время,
Аудитория);
АУДИТОРИЯ (Аудитория, Вместимость).
При проектировании структуры реляционной базы данных считается
корректной установка, что любая БД должна находиться как минимум ЗНФ.
На практике третья нормальная форма схем отношений достаточнг
большинстве случаев, и приведением к третьей нормальной ферме процесс
проектирования реляционной базы данных обычно заканчивается.
НЕ из лекции, простыми словами:
Требование третьей нормальной формы (3NF) заключается в том,
чтобы в таблицах отсутствовала транзитивная зависимость. Для приведения
третей нормальной формы нужно привести таблицы во вторую нормальную
форму.
Транзитивная зависимость – это когда неключевые столбцы зависят
от значений других неключевых столбцов.
Иными словами, неключевые столбцы не должны пытаться играть роль
ключа в таблице, т.е. они действительно должны быть неключевыми
столбцами, такие столбцы не дают возможности получить данные из других
столбцов, они дают возможность посмотреть на информацию, которая в них
содержится, так как в этом их назначение.
Таблица во второй нормальной форме.
Мы должны эту таблицу разбить на две: в первой хранить сотрудников
а во второй подразделения. А для реализации связи в таблице сотрудников
создать ссылку на таблицу подразделений, т.е. добавить внешний ключ.
Нормальная форма Бойса-Кодда
Определение для ЗНФ имеет упрощающее допущение, что отношение
имеет только один потенциальный ключ, который, естественно, и является
первичным ключом. Однако не все отношения могут быть уложены в данные
довольно жесткие рамки.
Более обобщающими являются случаи, когда в наличии имеются
следующие условия:
-отношение имеет два (или более) потенциальных ключа;
-два потенциальных ключа являются составными;
-два потенциальных ключа перекрываются, т. е. имеют, по крайней
мере, один общий атрибут.
Схема отношения R находится в НФБК относительно множества Fзависимостей тогда и только тогда, когда детерминанты являются
потенциальными ключами.
Допустим, что при проектировании базы данных
ПОСТАВКИ_ТОВАРОВ рассматривается отношение:
ПОСТАВКА (Индекс_поставщ, Имя_поставщ, Индекс_товара,
Колич_товара).
Допустим также, что значения атрибута Имя_поставщ уникальны и
могут быть использованы наряду с атрибутом Индекс_поставщ для
идентификации поставщика. В такой ситуации можно выделить два
составных потенциальных ключа:
(Индекс поставщ, Индекс_товара);
(Имя_поставщ, Иидекс_товара).
B рассматриваемом отношении есть два атрибута Индекс_поставщ и
Имя_поставщ, которые идентифицируют один и тот же экземпляр отношение
содержит два детерминанта, но эти детерминанты не являются
потенциальными ключами отношения.
Сложившаяся картина противоречит данному выше определению
НФБК, и следовательно, данное отношение не находится в НФБК.
Для схемы отношения, не находящейся в НФБК, можно провести
декомпозицию в схему БД в НФБК. Из исходного отношения убирается и
переносится в новое отношение зависимая часть вместе с копией
детерминанта.
Для рассматриваемого примера решение проблемы можно
осуществить, разбив исходное отношение на два. Причем поскольку два
детерминанта Индекс_поставщ и Имя_поставщ определяют друг друга, то
возможны два равносильных варианта декомпозиции, приводящей к НФБК.
Первый вариант получается, если учитывается зависимость
Индекс_поставщ - Имя_поставщ, в результате чего имеем следующих два
отношения:
ПОСТАВКА (Индекс_поставщ, Индекс_товара, Колич_товара);
ПОСТАВЩИК (Индекс_поставщ, Имя_поставщ).
Второй вариант исходит из зависимости Имя_поставщ ->
Индекс_поставщ, в результате чего получаем альтернативную группу
отношений;
ПОСТАВКА (Имя_поставщ, Индекс_товара, Колич_товара);
ПОСТАВЩИК (Индекс_поставщ, Имя_поставщ).
НЕ из лекции, простыми словами:
Требования нормальной формы Бойса-Кодда, следующие:
● Таблица должна находиться в третьей нормальной форме. Здесь все как
обычно, т.е. как и у всех остальных нормальных форм, первое
требование заключается в том, чтобы таблица находилась в предыдущей
нормальной форме, в данном случае в третьей нормальной форме;
● Ключевые атрибуты составного ключа не должны зависеть от
неключевых атрибутов.
Отсюда следует, что требования нормальной формы Бойса-Кодда
предъявляются только к таблицам, у которых первичный ключ составной.
Таблицы, у которых первичный ключ простой, и они находятся в третьей
нормальной форме, автоматически находятся и в нормальной форме БойсаКодда!
Наша таблица находится в третьей нормальной форме, так как у нас
есть первичный ключ, а неключевой столбец зависит от всего ключа, а не от
какой-то его части.
Но в данном случае таблица не находится в нормальной форме БойсаКодда, дело в том, что, зная куратора, мы можем четко определить, какое
направление он курирует, иными словами, часть составного ключа, т.е.
«Направление», зависит от неключевого атрибута, т.е. «Куратора».
Таким образом, в таблице кураторов у нас хранится список кураторов и
их специализация, т.е. направление, которое они могут курировать, а в
таблице связи кураторов и проектов отражается связь проектов и кураторов.
22. Проектирование БД. Нормализация. 4НФ. 5НФ.
Четвертая нормальная форма
Использование НФБК позволяет устранить любые аномалии
обновления, вызванные функциональными зависимостями.
Рассмотрим, как пример следующую схему отношения:
НИР (Номер_НИР, Сотр, Задан_НИР).
Отношение НИР содержит номера тем научно- исследовательских
работ, для каждой темы - список сотрудников, которые могут выполнять
работы по теме, и список заданий темы. Сотрудники могут участвовать в
нескольких темах, и разные темы могут включать одинаковые задания. В
такой ситуации единственно возможным ключом отношения является
составной атрибут:
(Номер_НИР, Сотр, Задан_НИР)
Отношение характеризуется значительной избыточностью и приводит
к возникновению аномалий обновления. Все рассмотренные до сих пор
приемы нормализации, опирающиеся на функциональные зависимости,
оказываются неприменимыми, поскольку этих зависимостей в отношении
вовсе нет.
Четвертая нормальная форма строго теоретически B 1971 году Фейгин
предложил обоснованный выход из этой ситуации с помощью понятия
многозначной зависимости (МЗ).
Формальное условие существования многозначной зависимости:
многозначная зависимость имеет место в том отношении, в котором
содержится две независимые связи типа 1 : M. И все проблемы данной
ситуации вызваны именно этой независимостью связей.
В отношении R(A, В, С) существует многозначная зависимость А > В в
том и только в том случае, если множество значений В, соответствующее
паре значений А и С, зависит только от А и не зависит от С.
В приведенном отношении НИР существуют спедующие две
многозначные зависимости:
Номер_НИР ->> Сотр;
Номер_НИР ->> Задан_НИР.
Многозначные зависимости всегда образуют связанные пары и поэтому
их обычно представляют вместе в символьном виде так:
A->> B | С.
Дальнейшая нормализация таких отношений должна проходить по
пути разделения двух независимых повторяющихся групп. Это разделение
основывается на следующей теореме Фейгина.
Отношение R (А, В, C) можно спроецировать без потерь в отношения
R1 (А, B) и R2 (А, C) тогда и только тогда, когда для отношения R
выполняется многозначная зависимость: A->> В | С.
Такая зависимость называется нетривиальной многозначной
зависимостью.
Отношение находится в четвертой нормальной форме (4НФ) тогда и
только тогда, когда существуют такие подмножества А и В атрибутов
отношения R, что выполняется нетривиальная многозначная зависимость А >> В. Тогда все атрибуты отношения R также функционально зависят от
атрибута А.
Так как проблема многозначных зависимостей возникает в связи c
многозначными атрибутами, то решить проблему можно, поместив каждый
многозначный атрибут в свою собственную таблицу вместе с ключом, от
которого атрибут зависит.
В рассматриваемом примере можно произвести декомпозицию
отношения НИР в два отношения
НИР-СОТРУДНИКИ и НИР-ЗАДАНИЯ:
НИР-СОТРУДНИКИ (Номер_НИР, Сотр);
НИР-ЗАДАНИЯ (Номер_НИР, Задан_НИР).
НЕ из лекции, простыми словами:
Перед тем как переходить к процессу приведения таблиц базы данных
до четвертой нормальной формы, необходимо чтобы эти таблицы уже
находились в третьей нормальной форме или, если первичный ключ
составной, в нормальной форме Бойса-Кодда.
Требование четвертой нормальной формы (4NF) заключается в том,
чтобы в таблицах отсутствовали нетривиальные многозначные зависимости.
Начнем с того, что таблица должна иметь как минимум три столбца,
допустим A, B и C, при этом B и C между собой никак не связаны и не
зависят друг от друга, но по отдельности зависят от A, и для каждого
значения A есть множество значений B, а также множество значений C.
В данном случае многозначная зависимость обозначается вот так:
A —> B
A —> C
В данном случае первичный ключ здесь состоит из всех трех столбцов,
поэтому эта таблица автоматически находится в третьей нормальной форме и
нормальной форме Бойса-Кодда. Однако она не находится в четвертой
нормальной форме, так как здесь есть многозначная зависимость
Курс ->-> Преподаватель
Курс ->-> Аудитория
Два атрибута «Преподаватель» и «Аудитория» никак не зависят друг от
друга, но они оба по отдельности зависят от курса. Их нужно разделить.
Многозначные зависимости плохи как раз тем, что их нельзя
независимо друг от друга редактировать. Иными словами, чтобы внести
изменения в одну зависимость, мы неизбежно должны затронуть другую
зависимость.
Пятая нормальная форма
Пятая нормальная форма всех рассмотренных ранее ситуациях
нормализация отношений производилась декомпозицией одного отношения
на два.
Иногда нормализовать отношение путем декомпозиции на два
отношения без потерь не удается, но просматривается возможность
декомпозиции исходного отношения без потерь на большее число
отношений, каждое из которых обладает лучшими свойствами. Такое
отношение называется термином "п-декомпозитируемое отношение" для
некоторого n > 2.
Это значит, что для данного от ношения возможна декомпозиция без
потерь на n проекций, а на меньшее числог проекций декомпозиция без
потерь невозможна.
Если в процессе естественного соединения декомпозированных
отношений сравнении c первоначальным отношением генерируются ложные
кортежи, то такая декомпозиция характеризуется зависимостью соединения.
В отношении R (X, У, …, Z) отсутствует зависимость соединения *(X,
Y, …, Z), в том и только в том случае, когда R восстанавливается без потерь
путем соединения своих проекций на X, У, …, Z
Отношение находится в пятой нормальной форме, если оно не
содержит зависимостей соединения.
НЕ из лекции, простыми словами:
Требование пятой нормальной формы (5NF) заключается в том, чтобы
в таблице каждая нетривиальная зависимость соединения определялась
потенциальным ключом этой таблицы.
Переменная отношения находится в пятой нормальной форме (иначе –
в проекционно-соединительной нормальной форме) тогда и только тогда,
когда каждая нетривиальная зависимость соединения в ней определяется
потенциальным ключом (ключами) этого отношения.
Если Вас когда-то попросят определить, находится та или иная
таблица в 5 нормальной форме, то Вы смело можете отвечать
«неизвестно, так как все зависит от требований предметной области».
В случае нашей таблицы мы также не можем сказать, находится ли она
в 5NF или нет, так как нам сначала необходимо разобраться в предметной
области и определить ограничения.
Поработав с предметной областью, мы выясняем, что:
Иванов И.И. может работать только в направлении «Разработка»
Сергеев С.С. может работать в любом направлении, за исключением
«Разработка»
Иванов И.И. может участвовать в большом количестве проектов
John Smith может участвовать только в одном проекте
Если придерживаться этих требований, то в нашу таблицу можно очень
легко внести некорректные данные, и у нас точно так же, как и в случае с
четвертой нормальной формой, будут возникать аномалии при добавлении,
изменении и удалении данных.
Наша таблица находится в четвертой нормальной форме, так как у нас
отсутствует многозначная зависимость, ведь у нас нет таких атрибутов,
которые зависели бы от другого атрибута.
Однако принимая во внимание наши требования, мы понимаем, что часть
данных каждого из столбцов зависит от части данных другого столбца, т.е.
существуют некие зависимости, и эти зависимости определяются не целым
потенциальным ключом, а только его частью.
Поэтому, чтобы устранить возможность внесения некорректных данных,
мы можем попытаться выполнить декомпозицию без потерь, и тем самым
привести таблицу к пятой нормальной форме.
Чтобы выполнить декомпозицию без потерь, нам нужно разбить данную
таблицу на три проекции
{Сотрудник, Проект}, {Сотрудник, Направление}, {Проект, Направление}
С условием, что в случае обратного соединения, мы получим те же
самые данные, что у нас были и до декомпозиции.
Если это нам удастся сделать, то мы устраним нетривиальные
зависимости соединения и нормализуем наши таблицы до пятой нормальной
формы.
Таблицы созданы, теперь если мы выполним следующий запрос,
который соединяет эти три таблицы, и он вернет нам точно такие же данные,
что и в исходной таблице, то зависимости соединения у нас нет, и наши
таблицы находятся в пятой нормальной форме.
23. Проектирование БД. Нормализация. Преобразование связей для
5НФ.
Общий подход к преобразованию сущностей концептуальной модели
предметной области в отношения реляционной базы данных состоит в
следующем:
- построить набор предварительных отношений и указать первичные
ключи для каждого отношения;
- подготовить список всех представляющих интерес атрибутов (тех из
них, которые не были перечислены в диаграмме в качестве первичных
ключей сущностей) и назначить каждый из этих атрибутов одному из
предварительных отношений с тем условием, чтобы эти отношения
находились в НФБК.
На этом шаге для каждого отношения должны быть определены
межатрибутные функциональные зависимости, с помощью которых
проверяется соответствие отношений НФБК. Если полученные отношения в
итоге не находятся в НФБК или если некоторым атрибутам не находится
логически обоснованных мест в предварительных отношениях, то в этих
случаях диаграммы необходимо пересмотреть.
Как уже упоминалось, связи между отношениями в реляционной
модели данных реализуются посредством механизма первичных и внешних
ключей. Чтобы этот механизм действовал, необходимо в первую очередь
определиться с тем, которое из двух отношений является родительским, а
какое дочерним. Родительским считается такое отношение, которое передает
копию набора значений своего первичного ключа другому отношению, где
этот набор значений будет представлять внешний ключ. Последнее
отношение в этом случае будет являться дочерним отношением.
Преобразование бинарных связей
Рассмотрим бинарную связь ЧИТАЕТ между сущностями
ПРЕПОДАВАТЕЛЬ и КУРС. ПРЕПОДАВАТЕЛЬ КУРС
Эта связь может быть изображена с помощью диаграммы, которая
содержит всю информацию, необходимую для генерации соответствующих
отношений РБД.
Сущности ПРЕПОДАВАТЕЛЬ и идентифицируются с помощью ТН…
преподавателя и НК - номера курса. КУРС однозначно табельного номера
Если все элементы данной сущности должны участвовать в связи, то
такое участие называется обязательным. Например, если каждый
преподаватель должен читать один какой-либо курс, то класс
принадлежности такой сущности - обязательный. Класс принадлежности
сущностей, а также мощность связи между сущностями являются факторами,
определяющими структуру проектируемой БД.
Преобразование связей типа 1:1
Предварительные отношения для бинарных связей показателем
кардинальности, равным 1:1 могут быть получены вследствие просмотра
нескольких логических альтернатив и выбора из них наиболее подходящей.
Пусть в проектируемой БД должна храниться следующая информация:
TH - номер преподавателя;
Ф_И_О - фамилия, имя, отчество преподавателя;
Тел_П - телефон преподавателя;
НК - номер курса;
Назв К - название курса.
Считая, что класс принадлежности является обязательным для обеих
сущностей, получаем отношение:
ПРЕПОДАВАТЕЛЬ (ТН, Ф_И_О, Тел_П, НК, Назв_К).
Первичным ключом этого отношения может быть ключ любой из двух
сущностей.
Ситуация будет другая, если класс принадлежности одной из
сущностей (ПРЕПОДАВАТЕЛЬ) - обязательный, второго (КУРС) нет.
В такой ситуации требуется построение двух отношений: по одному
под каждую сущность. При этом ключ каждой сущности должен служить
первичным ключом для соответствующего отношения. Сущность, для
которой класс принадлежности является необязательным, преобразуется в
родительское отношение, а сущность, участвующая в связи с обязательным
классом принадлежности, преобразуется в дочернее отношение.
Для связи полученных отношений ключ родительского отношения
добавляется в качестве атрибута (внешнего ключа) в дочернее отношение.
В результате получаем следующую реляционную схему:
ПРЕПОДАВАТЕЛЬ (ТН, Ф_И_О, Тел_П, НК);
КУРС (НК, Назв_К).
Если класс принадлежности для обеих сущностей необязательный, то
лучшим решением является определение трех отношений -- по одному для
каждой сущности и одного для связи:
ПРЕПОДАВАТЕЛЬ (ТН, Ф_И_О, Тел_П);
КУРС (НК, Назв_К);
ЧИТАЕТ (ТН, НК)
Отношение ПРЕПОДАВАТЕЛЬ содержит сведения обо всех
преподавателях, а отношение КУРС - обо всех курсах.
Отношение для связи должно иметь среди своих атрибутов по одному
ключу от каждой сущности.
Преобразование связей типа 1:N
Изменим в рассмотренной концептуальной модели бинарную связь на
тип 1:N.
Для таких связей существует только два правила. Вариант.
определяется классом принадлежности N-связной сущности, класс
принадлежности 1-связной сущности не влияет на конечный результат в
обоих случаях.
Первый вариант. ПРЕПОДАВАТЕЛЬ - класс принадлежности
необязательный, КУРС - обязательный.
Решение задачи становится возможным, если использовать два
отношения, по одному на каждую сущность, при условии, что ключ каждой
сущности служит в качестве первичного ключа для соответствующего
отношения. B качестве родительского назначается отношение,
соответствующее «единичной» с стороне связи, a B качестве дочернего
назначается отношение, представляющее «множественную» сторону связи.
Для представления этой связи необходимо скопировать первичный ключ
родительского отношения в дочернее отношение, где данный ключ должен
быть описан как внешний.
Окончательно в БД войдут два отношения:
ПРЕПОДАВАТЕЛЬ (ТН, Ф_И_О, Тел_П);
КУРС (НК, Назв_К, ТН).
Второй вариант. Класс принадлежности для обеих сущностей
необязательный. Решение- - в формировании трех отношений: по одному на
каждую сущность (причем ключ каждой сущности служит первичным
ключом соответствующего отношения) и одного отношении для связи.
Отношение для связи должно иметь среди своих атрибутов ключ
каждой сущности:
КУРС (НК, Назв_К);
ПРЕПОДАВАТЕЛЬ (ТН, Ф_И_О, Тел_П);
ЧИТАЕТ (ТН, НК)
Преобразование связи типа «суперкласс/подкласс»
Для каждой присутствующей в логической модели данных связи типа
«супертип/подтип» сущность супертипа необходимо определить как
родительскую, а сущность портипа- как дочернюю. Существуют различные
варианты представления подобных связей в виде одного или нескольких
отношений. Выбор наиболее подходящего варианта зависит от ограничений
участия и пересечения, наложенных на участников связи
«суперкласс/подкласс».
Если суперкласс с его подклассами имеет тотальные и
непересекающиеся связи, где каждый экземпляр суперкласса обязательно
должен быть членом одного и только одного подкласса, то самым
целесообразным решением является представление каждого из подклассов в
виде отдельного отношения, содержащего копию первичного ключа
суперкласса.
Рассмотрим подклассы АССИСТЕНТ, ПРЕПОДАВАТЕЛЬ, ДОЦЕНТ,
ПРОФЕССОР, которые являются членами суперкласса ПРЕПОДАВАТЕЛЬ.
Это означает, что каждый экземпляр подкласса является в то же время и
экземпляром суперкласса. Причем каждый преподаватель обязательно
принадлежит одному и только одному подклассу. ДОЦЕНТ СТАРШИЙ
ПРЕПОДАВАТЕЛЬ АССИСТЕНТ ПРОФЕССОР
Подобная диаграмма преобразуется в схему отношений в следующую
реляционную схему:
ПРЕПОДАВАТЕЛЬ (Табельный номер. ФИО, Адрес,
ПРОФЕССОР (Табельный_номер, Номер Диплома профессора);
Педагог стаж).
ДОЦЕНТ (Табельный_номер, Номердиппома доцента);
СТАРШИЙ_ПРЕПОДАВАТЕЛЬ (Табельный_номер):
АССИСТЕНТ (Табельный_номер).
Табельный номер в данном кортеже является первичным ключом.
Преобразование связей типа N:N
При такой степени связи требуется три отношения вне зависимости от
класса принадлежности обеих сущностей, по одному для каждой сущности,
причем ключ каждой сущности используется в качестве первичного ключа
соответствующего отношения, и одного отношения для связи. Последнее
должно иметь в числе своих атрибутов ключ каждой сущности. Единственно
допустимый вариант в сложившейся ситуации - представить БД тремя
отношениями:
КУРС (НК, Назв_К);
ПРЕПОДАВАТЕЛЬ (ТН, Ф_И_О, Теп_П);
ЧИТАЕТ (ТН, НК).
Вся информация о курсе будет содержаться в отношении КУРС,
информация о преподавателе - в отношении ПРЕПОДОВАТЕЛЬ, а
отношение ЧИТАЕТ будет содержать только экземпляры связи, имеющиеся
в модели.
(не обязательно(?), но в лекции было)
Проверка модели с помощью концепций последовательной
нормализации
Созданный на предыдущем этапе предварительный набор отношений
логической модели данных должен обязательно быть подвергнут анализу на
корректность объединения атрибутов в каждом из отношений. Проверка
корректности состава каждого из отношений должна проводиться
посредством применения к ним процедуры последовательной нормализации.
Целью применения этой процедуры является получение гарантий того, что
каждое из отношений, полученных на основе концептуальной модели,
находится, по крайней мере, в НФБК.
Если в процессе анализа отношений модели будут найдены отношения
не отвечающие требованиям НФБК, то это будет означать, что где-то на
предыдущих этапах были допущены ошибки. Возможно, ошибки появились
при построении концептуальной модели, a возможно в процессе
преобразования B логическую модель. Для обеспечения корректности
логической модели в такой ситуации придется вернуться на ранние этапы
проектирования и перестроить ошибочно созданные фрагменты модели.
Проверка поддержки целостности данных
По время проведения процедуры проверки следует обратить внимание
на следующие моменты:
-возможность для атрибутов иметь пустые значения;
-ограничения для доменов атрибутов;
-категорная целостность;
-ссылочная целостность;
-бизнес-правила в данной предметной области.
Необходимо выполнить работу по проверке каждой составляющей
применительно к каждой сущности, к каждому атрибуту, к каждой связи
логической модели предметной области. В том случае, если и данная
проверка даст положительный результат, можно переходить к следующему
этапу проектирования базы данных - физическому проектированию.
24. Физическая организация данных. Требования. Этапы поиска и
предоставления данных.
Для функционирования СУБД во внешней памяти базы данных
необходимо хранить следующие объекты:
-строки отношений
-основная часть базы данных, большей частью непосредственно
видимая пользователям;
-управляющие структуры индексы, создаваемые по инициативе
пользователя (администратора) или верхнего уровня системы для повышения
эффективности выполнения запросов и обычно автоматически
поддерживаемые нижним уровнем системы;
-журнальную информацию, для обеспечения надежного хранения
данных;
-служебную информацию для внутренних потребностей нижнего
уровня системы.
Поиск и предоставление данных пользователю состоит из трех
основных этапов:
1. Определяется искомая запись, для извлечения которой
запрашивается диспетчер файлов.
2. Диспетчер файлов определяет страницу, на которой находится
искомая запись, и для извлечения этой страницы запрашивает диспетчер
дисков.
3. Диспетчер дисков определяет физическое положение искомой
страницы на диске и посылает соответствующий вопрос на ввод-вывод
данных.
25.Физическая организация данных. Страничная организация файлов.
Основными единицами осуществления операций обмена являются
страницы данных, управляемые диспетчером дисков. Все данные хранятся
постранично.
Так, с точки зрения СУБД, база данных выглядит как набор записей,
которые просматриваются с помощью диспетчера файлов. С точки зрения
диспетчера файлов база данных выглядит как набор страниц, которые могут
просматриваться с помощью диспетчера дисков.
На одной странице хранятся однородные данные, например, только
данные или только индексы. Все страницы данных имеют одинаковую
структуру.
Заголовок страницы
Содержание страницы
Слоты
Заголовок страницы содержит информацию о физическом дисковом
адресе страницы, которая логически следует за данной страницей (см.
правый верхний угол рисунка на слайде).
Заголовки страниц и указатели на следующие страницы
обрабатываются только диспетчером дисков и скрыты от диспетчера файлов.
Для выполнения своих функций распоряжении диспетчера дисков имеется
каталог (страница 0), содержащий информацию обо всех имеющихся на
данном диске наборах страниц вместе с указателями на первые страницы
этих наборов.
Заголовок
Запись 1
5
Запись 2
Свободное пространство
Размещение строк данных на странице характеризуется слотами.
Каждая запись обладает уникальным идентификатором, не
изменяемым во все время ee существования, он имеет определенную длину и
состоит из номера страницы, на которой данная запись находится, и байта
смещения слота от конца страницы, который в свою очередь содержит байт
смещения записи от начала страницы.
26.Физическая организация данных. Индексирование. Индексно-прямые
файлы.
Преимущества индексации
Важные плюсы / преимущества индексирования:
Это помогает сократить общее количество операций ввода-вывода,
необходимых для извлечения этих данных, поэтому вам не нужно
обращаться к строке в базе данных из структуры индекса.
Предлагает более быстрый поиск и поиск данных для пользователей.
Индексирование также помогает сократить табличное пространство,
поскольку вам не нужно ссылаться на строку в таблице, поскольку нет
необходимости хранить ROWID в индексе. Таким образом вы сможете
уменьшить табличное пространство.
Вы не можете сортировать данные в ведущих узлах, так как значение
первичного ключа классифицирует их.
Недостатки индексации
Важными недостатками / минусами индексации являются:
Для выполнения системы управления базами данных индексирования
вам необходим первичный ключ в таблице с уникальным значением.
Вы не можете выполнять какие-либо другие индексы для
проиндексированных данных.
Вам не разрешено разбивать организованную по индексу таблицу.
Индексирование SQL Снижение производительности в запросах
INSERT, DELETE и UPDATE.
Основное назначение индексов состоит в обеспечении эффективного
прямого доступа к записи таблицы по ключу. Различают индексированный
файл и индексный файл.
Индексированный файл — это основной файл, содержащий данные
отношения, для которого создан индексный файл.
Индексный файл — это файл особого типа, в котором каждая запись
состоит из двух значений: данных и указателя.
Данные представляют поле, по которому производится
индексирование, а указатель осуществляет связывание с соответствующим
кортежем индексированного файла. Если индексирование осуществляется по
ключевому полю, то индекс называется первичным. Такой индекс к тому же
обладает свойством уникальности, т. е. не содержит дубликатов ключа.
Основное преимущество использования индексов заключается в
значительном ускорении процесса выборки данных, а основной недостаток B
замедлении процесса обновления данных. Действительно, при каждом
добавлении новой записи индексированный файл потребуется также
добавить новый индекс в индексный файл.
Индексно-прямые файлы
B индексно-прямых файлах основная область содержит
последовательность записей одинаковой длины, расположенных в
произвольном порядке, а индексная запись содержит з значение первичного
ключа и порядковый номер записи в основной области. которая имеет данное
значение первичного ключа.
Так как индексные файлы строятся для первичных ключей, однозначно
определяющих запись, то в индексно-прямых файлах для каждой записи в
основной области существует только одна запись из индексной области.
Такой индекс называется плотным. Все записи в индексной области
упорядочены по значению ключа.
Наиболее эффективным алгоритмом поиска на упорядоченном массиве
является бинарный поиск. При этом все пространство поиска разбивается
пополам, и так как оно строго упорядочено, то сначала определяется, не
является ли срединный элемент искомым, а если нет, то дается оценка в
какой половине его надо искать. Далее установленная половина также
делится пополам и производятся аналогичные действия, и так до тех пор,
пока не будет обнаружен искомый элемент. обращение к
Потом путем прямой адресации происходит основной области уже по
конкретному номеру записи.
Операция добавления осуществляет запись в конец основной области.
В индексной области при этом производится занесение информации так,
чтобы не нарушать упорядоченности. Поэтому вся индексная область файла
разбивается на блоки и при начальном заполнении в каждом блоке остается
свободная область (процент расширения).
При проектировании физической базы данных так важно заранее как
можно точнее определить объемы информации, спрогнозировать ee
хранимой рост и предусмотреть соответствующее расширение области
хранения.
При удалении записи возникает следующая последовательность
действий: запись в основной области помечается как удаленная, в индексной
области соответствующий индекс уничтожается физически, то есть записи
индексного файла, следующие за удаленной записью, перемещаются на ее
место, и блок, в котором хранился данный индекс, заново записывается на
диск. При этом количество обращений к диску для этой операции такое же,
как и при добавлении новой записи.
27. Физическая организация данных. Индексирование. Индекснопоследовательные файлы.
Преимущества индексации
Важные плюсы / преимущества индексирования:
Это помогает сократить общее количество операций ввода-вывода,
необходимых для извлечения этих данных, поэтому вам не нужно
обращаться к строке в базе данных из структуры индекса.
Предлагает более быстрый поиск и поиск данных для пользователей.
Индексирование также помогает сократить табличное пространство,
поскольку вам не нужно ссылаться на строку в таблице, поскольку нет
необходимости хранить ROWID в индексе. Таким образом вы сможете
уменьшить табличное пространство.
Вы не можете сортировать данные в ведущих узлах, так как значение
первичного ключа классифицирует их.
Недостатки индексации
Важными недостатками / минусами индексации являются:
Для выполнения системы управления базами данных индексирования
вам необходим первичный ключ в таблице с уникальным значением.
Вы не можете выполнять какие-либо другие индексы для
проиндексированных данных.
Вам не разрешено разбивать организованную по индексу таблицу.
Индексирование SQL Снижение производительности в запросах
INSERT, DELETE и UPDATE.
Основное назначение индексов состоит в обеспечении эффективного
прямого доступа к записи таблицы по ключу. Различают индексированный
файл и индексный файл.
Индексированный файл — это основной файл, содержащий данные
отношения, для которого создан индексный файл.
Индексный файл — это файл особого типа, в котором каждая запись
состоит из двух значений: данных и указателя.
Основное преимущество использования индексов заключается в
значительном ускорении процесса выборки данных, а основной недостаток B
замедлении процесса обновления данных. Действительно, при каждом
добавлении новой записи индексированный файл потребуется также
добавить новый индекс в индексный файл.
Индексно-последовательные файлы
Если файлы поддерживаются в отсортированном состоянии с момента
их создания, то для работы с ними может быть использован другой подход.
Принципы внутреннего упорядочения и блочности построения таких файлов
позволяют уменьшить количество хранимых индексов за счет того, что в
индексном файле не содержатся указатели на все записи индексированного
файла. Таким образом, в этом случае индекс получается неплотным или
разреженным.
Индексная запись для таких файлов должна содержать: значение ключа
первой записи блока и номер блока с этой записью.
Теперь по заданному значению первичного ключа в индексной области
требуется отыскать уже нужный блок. Все остальные действия происходят в
основной области. При переходе неплотному индексу время доступа
уменьшается практически в полтора раза.
При таком подходе новая запись должна заноситься сразу в требуемый
блок на требуемое место. Естественно, что для добавления записей уже блок
основной области должен иметь свободное место. При внесении новой
записи индексная область не корректируется.
Уничтожение записи происходит путем ее физического удаления из
основной области, при этом индексная область обычно не корректируется.
При этом следует помнить:
- с помощью одного неплотного индекса нельзя выполнить проверку
наличия некоторого значения;
- в данном хранимом файле может быть, по крайней мере, один
неплотный индекс, который организуется по полю, по которому этот файл
отсортирован, а остальные индексы обязательно должны быть плотными.
28. Физическая организация данных. Индексирование.
Организация индексов в виде Б-деревьев.
Преимущества индексации
Важные плюсы / преимущества индексирования:
Это помогает сократить общее количество операций ввода-вывода,
необходимых для извлечения этих данных, поэтому вам не нужно
обращаться к строке в базе данных из структуры индекса.
Предлагает более быстрый поиск и поиск данных для пользователей.
Индексирование также помогает сократить табличное пространство,
поскольку вам не нужно ссылаться на строку в таблице, поскольку нет
необходимости хранить ROWID в индексе. Таким образом вы сможете
уменьшить табличное пространство.
Вы не можете сортировать данные в ведущих узлах, так как значение
первичного ключа классифицирует их.
Недостатки индексации
Важными недостатками / минусами индексации являются:
Для выполнения системы управления базами данных индексирования
вам необходим первичный ключ в таблице с уникальным значением.
Вы не можете выполнять какие-либо другие индексы для
проиндексированных данных.
Вам не разрешено разбивать организованную по индексу таблицу.
Индексирование SQL Снижение производительности в запросах
INSERT, DELETE и UPDATE.
Основное назначение индексов состоит в обеспечении эффективного
прямого доступа к записи таблицы по ключу. Различают индексированный
файл и индексный файл.
Индексированный файл — это основной файл, содержащий данные
отношения, для которого создан индексный файл.
Индексный файл — это файл особого типа, в котором каждая запись
состоит из двух значений: данных и указателя.
Основное преимущество использования индексов заключается в
значительном ускорении процесса выборки данных, а основной недостаток B
замедлении процесса обновления данных. Действительно, при каждом
добавлении новой записи индексированный файл потребуется также
добавить новый индекс в индексный файл.
Построение Б-деревьев связано с простой идеей построения
индекса над уже построенным индексом. Действительно, если уже
построен плотный (но может быть и неплотный, если в индексированном
файле проведена кластеризация на основе индекса) индекс для реальных
данных, то сама индексная область может рассматриваться как основной
файл, над которым надо снова построить неплотный индекс.
Записи внутри индекса сгруппированы по страницам, а страницы
связаны в цепочку таким образом, чтобы логическое упорядочение на основе
индекса осуществлялось внутри первой страницы, затем с помощью
физической последовательности записей внутри второй страницы этой
последовательной цепочки и т. д. Таким образом, с помощью набора
последовательностей можно организовать быстрый последовательный
доступ индексированным данным.
Потом снова над новым индексом строится следующий неплотный
индекс и так до того момента, пока не останется всего один индексный блок.
Эта операция обычно применяется трижды, поскольку создание большого
количества иерархических уровней индексирования требуется для очень
больших файлов. При этом индекс на каждом из уровней будет неплотным
по отношению к нижнему индексируемому уровню. Таким образом, на
самом верхнем уровне такого индекса находится только один элемент
структуры (страница, содержащая множество записей), который называется
корневым.
Набор индексов обеспечивает быстрый непосредственный доступ к
набору последовательностей (а значит, и к данным).
В результате такого построения получится некоторое дерево, каждый
родительский блок которого связан с одинаковым количеством подчиненных
блоков, число которых равно числу индексных записей, размещаемых в
одном блоке. Количество обращений к диску при этом для поиска любой
записи одинаково и равно количеству уровней в построенном дереве. Такие
деревья называются сбалансированными потому, что путь от корня до
любого листа в этом древе одинаков.
Структуры типа Б-дерева позволяют, используя специальные,
алгоритмы, осуществлять сбалансированную вставку или удаление
значений.
K. Дж. Дейт приводит краткий алгоритм вставки нового значения V в
структуру типа Б-дерева порядка. Он рассчитан на вставку значения только
лишь в набор индексов, но может быть достаточно просто расширен для
вставки записи с данными в набор последовательностей.
Порядок добавления элементов:
1. На самом низком уровне набора индексов следует найти элемент
(допустим, что это элемент N), с которым логически связано вставляемое
значение V. Если элемент N содержит свободное пространство, то значение
V вставляется в него, и на этом процесс завершается.
2. В противном случае (если свободного пространства нет, т.е.
придется создать еще один уровень) элемент N (допустим, что он содержит
2n индексных записей) разделяется на два элемента N1 и N2. Обозначим
символом S множество из 2n + 1 значений, в котором 2n исходных значений
и одно новое значение V. Тогда п первых значений этой логической (уже
упорядоченной) последовательности необходимо поместить в элемент N1, п
последних -- в элемент N2, а среднее между ними значение W- в
родительский элемент Р на более высоком структурном уровне.
Впоследствии, при осуществлении поиска значения U и достижении
элемента Р, поиск будет перенаправлен в сторону элемента N1, если U s W,
либо в сторону элемента N2, если U > W.
3. Далее этот процесс следует повторить для вставки среднего значения
W в родительский элемент Р на более высоком структурном уровне.
В худшем случае процесс разделения элементов структуры может
продлиться вплоть до корневого элемента всей структуры с образованием
нового иерархического уровня.
Для удаления некоторого значения следует применить аналогичный
алгоритм, но только в обратном порядке. А для изменения значения его
можно удалить, а затем вставить новое.
29.Физическая организация данных. Индексирование.
Инвертированные списки.
Основное назначение индексов состоит в обеспечении эффективного
прямого доступа к записи таблицы по ключу. Различают индексированный
файл и индексный файл.
Индексированный файл — это основной файл, содержащий данные
отношения, для которого создан индексный файл.
Индексный файл — это файл особого типа, в котором каждая запись
состоит из двух значений: данных и указателя.
Основное преимущество использования индексов заключается в
значительном ускорении процесса выборки данных, а основной недостаток B
замедлении процесса обновления данных. Действительно, при каждом
добавлении новой записи индексированный файл потребуется также
добавить новый индекс в индексный файл.
Инвертированные списки
Базы данных должны предоставлять возможность проводить операции
доступа к данным не только по первичным, но и по вторичным индексам.
Для обеспечения ускорения доступа по вторичным индексам используются
структуры, называемые инвертированными списками. При организации
инвертированного списка можно выделить три уровня.
Самый нижний уровень (нулевой) представлен собственно основным
файлом.
Над этим уровнем строится еще два уровня, которые и представляют
собой непосредственно инвертированный список.
На первом уровне этой структуры находится файл, в который
помещаются значения вторичных индексов основного файла, причем в
упорядоченном состоянии. В этом файле предусмотрено поле, куда
помещается ссылка на второй уровень.
На втором уровне для каждого значения вторичного индекса строится
цепочка блоков, содержащих номера записей основного файла с этим
значением вторичного индекса. Адрес первого блока такой цепочки и
помещается в поле ссылки первого уровня. При этом блоки второго уровня
также упорядочены по значениям вторичного индекса.
Первый уровень ссылается на второй, а второй ссылается на нулевой
уровень.
Механизм доступа к записям по вторичному индексу при подобной
организации записей состоит в следующем:
- найти в области первого уровня заданное значение вторичного
индекса;
- по ссылке считать блоки второго уровня, содержащие номера записей
с заданным значением вторичного индекса;
- прямым доступом загрузить в рабочую область пользователя
содержимое всех записей, содержащих заданное значение вторичного
индекса.
Для одного основного файла может быть создано несколько
инвертированных списков по разным вторичным индексам.
Если же база данных постоянно изменяется, дополняется,
модифицируется содержимое записей, то наличие большого количества
инвертированных списков или индексных файлов по вторичным индексам
может резко замедлить процесс обработки информации.
Модификация основного файла в такой ситуации требует:
- изменить запись основного файла;
- исключить старую ссылку на предыдущее значение вторичного
индекса;
- добавить новую ссылку на новое значение вторичного индекса.
30. Языки БД. Языки определения данных.
Языки баз данных можно поделить на две категории:
-языки определения данных БД - ЯОД (DDL Data Definition Language);
-языки манипулирования данными - ЯМД (DML - Data Manipulation
Language).
Язык определения данных - описательный язык, с помощью которого
описывается предметная область: именуются объекты, определяются их
свойства и связи между объектами. Язык создания базы данных.
Он используется главным образом для определения логической
структуры БД.
Схема базы данных, выраженная в терминах специального языка
определения данных, состоит из набора определений. Язык ЯОД
используется как для определения новой схемы, так и для модификации уже
существующей.
Результатом компиляции ЯОД - операторов является набор таблиц,
хранимый в системном каталоге, в котором содержатся метаданные - т.е.
данные, которые включают определения записей, элементов данных, a также
другие объекты, представляющие интерес для пользователей или
необходимые для работы СУБД. Перед доступом к реальным данным СУБД
обычно обращается к системному каталогу.
31. Языки БД. Языки манипулирования данными.
Языки баз данных можно поделить на две категории:
-языки определения данных БД - ЯОД (DDL Data Definition Language);
-языки манипулирования данными - ЯМД (DML - Data Manipulation
Language).
Язык манипулирования данными содержит набор операторов
манипулирования данными, T. e. операторов, позволяющих заносить данные
в БД, удалять, модифицировать или выбирать существующие данные.
Множество операций над данными можно классифицировать
следующим образом:
1. операции селекции (выборки);
2. действия над данными:
- включение - ввод экземпляра записи в БД с установкой его связей;
- удаление
- исключение экземпляра записи из БД с установкой новых связей;
- модификация - изменение содержимого экземпляра записи и
коррекция связей при необходимости.
Языки манипулирования данными делятся на два типа. Это разделение
обусловлено коренным различием в подходах к работе с данными, а
следовательно, различием в базовых конструкциях в работе с данными.
Первый тип — это процедурный ЯМД.
Второй тип — это декларативный (непроцедурный) ЯМД.
К процедурным языкам манипулирования данными относятся и языки,
поддерживающие операции реляционной алгебры, которую основоположник
теории реляционных баз данных Э. Ф. Кодд ввел для управления
реляционной базой данных. Реляционная алгебра — это процедурный язык
обработки реляционных таблиц, где в качестве операндов выступают
таблицы в целом.
Декларативные языки предоставляют пользователю средства,
позволяющие указать лишь то, какие данные требуются. Решение вопроса о
том, как их следует извлекать, берет на себя процессор данного языка,
работающий с целыми наборами записей.
Реляционные СУБД обычно включают поддержку непроцедурных
языков манипулирования данными - чаще всего это бывает язык
структурированных запросов SQL или язык запросов по образцу QBE.
В настоящее время нормой является поддержка декларативного языка
SQL, в основе которого лежит реляционное исчисление, также введенное Э.
Коддом. Этот язык стал стандартом для языков реляционных баз данных, что
позволяет использовать один и тот же синтаксис и структуру команд при
переходе от одной СУБД к другой.
Следует отметить, что язык SQL имеет сразу два компонента: язык
DDL (ЯОД) для описания структуры базы данных, и язык DML (ЯМД) для
выборки и обновления данных.
Другим широко используемым языком обработки данных является
язык QBE, который заслужил репутацию одного из самых простых способов
извлечения информации из базы данных. Особенно это ценно для
пользователей, не являющихся профессионалами B этой области. Язык
предоставляет графические средства создания запросов на выборку данных с
использованием шаблонов. Ответ на запрос также представляет собой
графическую информацию.
Часть непроцедурного языка ЯМД, которая отвечает за извлечение
данных, называется языком запросов. Язык запросов можно определить как
высокоуровневый узкоспециализированный язык, предназначенный для
удовлетворения различных требований по выборке информации из базы
данных.
32. Языки БД.SQL. Достоинства и недостатки.
SQL (structured query language - «язык структурированных запросов»)
декларативный язык программирования, применяемый для создания,
модификации и управления данными в реляционной базе данных,
управляемой соответствующей системой управления базами данных.
Хотя изначально SQL был основным способом работы пользователя с
базой данных и позволял выполнять ограниченный набор операций по
созданию и удалению таблиц, изменению их структуры, добавления,
удаления и изменения данных, со временем он усложнился и обогатился
новыми конструкциями, возможностью описания и управления новыми
хранимыми объектами (индексы, представления, триггеры и хранимые
процедуры).
SQL является самым распространённым лингвистическим средством
для взаимодействия прикладного программного обеспечения с базами
данных
Преимущества SQL:
Независимость от конкретной СУБД - несмотря на наличие диалектов и
различий в синтаксисе, в большинстве своём тексты SQL-запросов,
содержащие DDL и DML, могут быть достаточно легко перенесены из одной
СУБД в другую.
Наличие стандартов - наличие стандартов и набора тестов для
выявления совместимости и соответствия конкретной реализации SQL
общепринятому стандарту способствует «стабилизации» языка.
Декларативность - с помощью SQL программист описывает какие
данные нужно извлечь или модифицировать. Как именно это сделать,
определяет СУБД при обработке SQL-запроса.
Недостатки SQL:
Несоответствие реляционной модели данных - создатели реляционной
модели данных Эдгар Кодд, Кристофер Дейт и их сторонники указывают на
то, что SQL не является истинно реляционным языком, так как имеет
следующие особенности (дефекты):
- допущение строк-дубликатов в таблицах и результатах выборок, что в
рамках реляционной модели данных невозможно и недопустимо;
- поддержку неопределённых значений (NULL), создающая фактически
многозначную логику;
- значимость порядка столбцов, возможность ссылок на столбцы по
номерам (в реляционной модели столбцы должны быть равноправны);
- допущение столбцов без имени, дублирующийся имён столбцов.
Сложность - язык SQL, который задумывался как средство работы
конечного пользователя с базой данных, усложнился и стал инструментом
программиста.
Отступления от стандартов - несмотря на наличие международных
стандартов, многие разработчики СУБД вносят свои изменения в язык SQL,
применяемый в разрабатываемой СУБД, отступая от стандарта. Что приводит
к появлению специфичных для каждой конкретной СУБД диалектов языка
SQL.
33. Восстановление при отказах. Транзакции.
Восстановление в системе управления базами данных означает
восстановление самой базы данных, т.е. возвращение БД в правильное
состояние.
Основной принцип, на котором строится такое восстановление это
избыточность, которая организуется на физическом уровне.
(Из следующих слайдов лекции)
Транзакция — это не только логическая единица работы, но также
единица восстановления при неудачном выполнении операций.
Таким образом, транзакции обладают четырьмя важными свойствами:
атомарность, долговечность, согласованность, изоляция
Атомарность. Транзакции атомарны (выполняется все или ничего).
Согласованность. Транзакции защищают БД согласованно, т.е.
транзакции переводят одно согласованное состояние БД в другое без
обязательной поддержки согласованности в промежуточных точках.
Изоляция. Транзакции отделены друг от друга. Это означает, что при
запуске множества конкурирующих друг с другом транзакций, любое
обновление определенной транзакции будет скрыто от остальных до тех пор,
пока эта транзакция выполняется.
Долговечность. Когда транзакция выполнена, ее обновления
сохраняются, даже если в следующий момент произойдет сбой системы.
Транзакция
Транзакция — это логическая единица работы.
Рассмотрим пример. Предположим, что отношение P (отношение
деталей) включает атрибут TOTQTY, представляющий собой общий объем
поставок для каждой детали. Значение TOTQTY для любой определенной
детали предполагается равным сумме всех значений QTY для всех поставок
данной детали.
Посмотрим код добавления в базу данных новой поставки со значением
1000 для поставщика S5 и детали Р1.
В приведенном примере предполагается, что речь идет об атомарной
операции. На самом деле добавление новой поставки — это выполнение двух
обновлений в базе данных (INSERT добавляет новую поставку к отношению
SP, a UPDATE обновляет значение TOTQTY для детали Р1).
Кроме того, в базе данных между двумя обновлениями временно
нарушается требование, что значение ТОТОТУ для детали Р1 равно сумме
всех значений QTY для этой детали. Таким образом, транзакция - не просто
одиночная операция системы баз данных, а скорее согласование нескольких
таких операций.
Это преобразование одного согласованного состояния базы данных в
другое, причем в промежуточных точках база данных находится в
несогласованном состоянии.
Системный компонент, обеспечивающий называется администратором
транзакций, а ключами к его выполнению служат COMMIT TRANSACTION
и ROLLBACK TRANSACTION.
- Оператор COMMIT TRANSACTION сигнализирует об успешном
окончании транзакции и что база данных находится вновь в согласованном
состоянии, а все обновления могут быть зафиксированы, т.е. стать
постоянными.
- Оператор ROLLBACK TRANSACTION сигнализирует о неудачном
окончании транзакции и что база данных находится в несогласованном
состоянии, a все обновления могут быть отменены.
Система поддерживает файл регистрации (журнал регистрации), где
записываются детали всех операций обновления, в частности новое и старое
значения модифицируемого объекта.
Таким образом, при необходимости отмены некоторого обновления система
использует соответствующий файл регистрации для возвращения объекта в
первоначальное состояние.
34. Восстановление при отказах. Восстановление транзакций.
Восстановление в системе управления базами данных означает
восстановление самой базы данных, т.е. возвращение БД в правильное
состояние.
Основной принцип, на котором строится такое восстановление это
избыточность, которая организуется на физическом уровне.
Транзакция — это логическая единица работы.
Восстановление транзакции
Транзакция начинается с успешного выполнения оператора BEGIN
TRANSACTION и заканчивается успешным выполнение либо оператора
COMMIT, либо оператора ROLLBACK.
Оператор COMMIT устанавливает так называемую точку фиксации,
которая соответствует концу логической единице работы И, следовательно,
точке, в которой база данных находится в согласованном состоянии.
Выполнение же оператора Rollback возвращает базу данных в
состоянии, в котором она находилась во время выполнения оператора BEGIN
TRANSACTION, т.е. в предыдущую точку фиксации.
Из этого следует, что транзакция — это не только логическая единица
работы, но также единица восстановления при неудачном выполнении
операций.
Таким образом, транзакции обладают четырьмя важными свойствами:
атомарность, долговечность, согласованность, изоляция
Атомарность. Транзакции атомарны (выполняется все или ничего).
Согласованность. Транзакции защищают БД согласованно, т.е.
транзакции переводят одно согласованное состояние БД в другое без
обязательной поддержки согласованности в промежуточных точках.
Изоляция. Транзакции отделены друг от друга. Это означает, что при
запуске множества конкурирующих друг с другом транзакций, любое
обновление определенной транзакции будет скрыто от остальных до тех пор,
пока эта транзакция выполняется.
Долговечность. Когда транзакция выполнена, ее обновления
сохраняются, даже если в следующий момент произойдет сбой системы.
35. Восстановление при отказах. Восстановление системы.
Система должна быть готова к восстановлению не только после
небольших локальных нарушений, таких как невыполнение операции в
пределах определенной транзакции, но также и после глобальных нарушений
типа сбоев питания серверов. Местное нарушение по определению поражает
только транзакцию, в которой оно произошло. Глобальное нарушение
поражает сразу все транзакции, что приводит к значительным для системы
последствиям.
Существует два вида глобальных нарушений:
Отказы системы (например, сбои в питании), поражающие все
выполняющиеся в данный момент транзакции, но физически не
разрушающие базу данных в целом. Такие нарушения в системе также
называют аварийным отказом программного обеспечения.
Отказы носителей (например, поломка головок дискового
накопителя), которые могут представлять угрозу для БД или для какой-либо
ее части и поражать, по крайней мере, те транзакции, которые используют
эту часть БД. Отказы носителей называют также аварийным отказом
аппаратуры.
Критической точкой в отказе системы является потеря содержимого
оперативной памяти (рабочих буферов БД). Поскольку точное состояние
какой-либо выполняющейся в момент нарушения транзакции не известно,
транзакция может не завершиться успешно и, таким образом, будет отменена
при перезагрузке системы.
Также, возможно, потребуется повторно выполнить определенную
успешно завершившуюся до аварийного отказа транзакцию при перезагрузке
системы, если не были физически выполнены обновления этой транзакции.
Решение вопроса о том, какую транзакцию следует отменить, а какую
выполнить повторно, при перезагрузке системы заключается в следующем. В
некотором предписанном интервале (когда в журнале накапливается
определенное число записей) система автоматически принимает
контрольную точку. Принятие контрольной точки включает физическую
запись содержимого рабочих буферов БД непосредственно в БД и
специальную физическую запись контрольной точки, которая предоставляет
список всех осуществляемых в данный момент транзакций.
Рассмотрим пример. На рисунке видно пять возможных вариантов
выполнения транзакций до аварийного сбоя системы.
При перезагрузке системы транзакции Т3 и Т5 должны быть отменены,
а транзакции Т2 и Т4 - выполнены повторно, а транзакция Т1 вообще не
включаются в процесс перезагрузки, так как обновления попали в БД еще до
момента времени Тс, т.е. зафиксированы еще до принятия контрольной
точки. Все это работает только тогда, когда есть журнал транзакций.
Следовательно, во время перезагрузки система вначале проходит через
процедуру идентификации всех транзакций типа T2-T5. при этом
выполняются перечисленные ниже шаги.
1. Создаются два списка транзакций: будем их называть UNDO
(отменить) и REDO (повторить). В список UNDO заносятся все транзакции,
предоставленные из записи контрольной точки (т.е. все транзакции,
выполняющиеся в момент времени Tс), а список REDO остается пустым.
2. Осуществляется поиск в файле регистрации (журнале), начиная с
записи контрольной точки.
3. Если в файле регистрации обнаружена запись BEGIN
TRANSACTION о начале транзакции T, то эта транзакция также добавляется
в список UNDO.
4. Если в файле регистрации обнаружена запись COMMIT об
окончании транзакции Т, то эта транзакция добавляется в список REDO.
5. Когда достигается конец файла регистрации, списки и REDO
анализируются для идентификации транзакций типа Т2 и Т4, появившихся в
списке REDO и транзакций типа Т3 и Т5, оставшихся в списке UNDO.
После этого система просматривает файл регистрации, отменяя
транзакции из списка UNDO, а затем просматривает снова вперед. повторно
выполняя транзакции из списка REDO.
Восстановление носителей
При отказе носителей некоторая часть БД разрушается физически.
Восстановление после такого нарушения включает перезапись (или
восстановление) БД с резервной копии (или дампа) и последующее
использование файла регистрации - как его активной, так и архивной части.
Такое восстановление — это повторное выполнение всех транзакций,
вызванное применением резервной копии. При этом нет необходимости
отмены транзакций, которые выполнялись в момент отказа носителей,
поскольку по определению все обновления таких транзакций полностью
утеряны.
Это восстановление подразумевает наличие утилиты
дамп/восстановление. Дамп-часть этой утилиты используется для сохранения
резервной копии. Такие копии должны сохранятся на другом носителе или
носителях. После отказа носителей восстановительная часть утилиты
используется для создания БД со специализированной резервной копии.
36. Транзакции. Параллелизм. Проблемы восстановления.
Транзакция — это не только логическая единица работы, но также
единица восстановления при неудачном выполнении операций.
Параллелизм означает возможность одновременной обработки в
СУБД многих транзакций с доступом к одним и тем же данным, причем в
одно и то же время. В такой системе для корректной обработки
параллельных транзакций без возникновения конфликтных ситуаций
необходимо использовать некоторый метод управления параллелизмом.
Прежде всего следует уточнить, что каждый метод управления
параллелизмом предназначен для решения некоторой конкретной задачи.
Тем не менее, при обработке правильно составленных транзакций возникают
ситуации, которые могут привести получению неправильного результата изза взаимных помех среди некоторых транзакций.
Основные проблемы, возникающие при параллельной обработке
транзакций следующие:
-потеря результатов обновления;
-незафиксированная зависимость;
-несовместимый анализ.
Проблема потери результатов обновления
Результат операции обновления, выполненной транзакцией А, будет
утерян, поскольку в момент времени t4 она не будет учтена и потому будет
«отменена» операцией обновления, выполненной транзакцией В.
Проблема незафиксированной зависимости
Проблема незафиксированной зависимости появляется, если с
помощью некоторой транзакции осуществляется извлечение (или, что еще
хуже, обновление) некоторого кортежа, который в данный момент
обновляется другой транзакцией, но это обновление еще не закончено.
Таким образом, если обновление не завершено, существует некоторая
вероятность того, что оно не будет завершено никогда. В таком случае в
первой транзакции будут принимать участие данные, которых больше не
существует (в том смысле, что они «никогда» не существовали).
Проблема незафиксированной зависимости
Транзакция А становится зависимой от невыполненного изменения в
момент времени t2:
Транзакция А обновляет невыполненное изменение в момент времени
t2, и результаты этого обновления утрачиваются в момент времени t3:
Проблема несовместимого анализа
В примере показаны транзакции А и В, которые выполняются для
кортежей со счетами. При этом транзакция А суммирует балансы, транзакция
В производит перевод суммы 10 со счета 3 на счет 1, полученный в итоге
транзакции А результат 110, очевидно, неверен, и если он будет записан в
базе данных, то в ней может возникнуть проблема несовместимость. В таком
случае говорят, что транзакция А встретилась с несовместимым состоянием и
на его основе был выполнен несовместимый анализ.
37. Транзакции. Блокировки. Проблемы взаимных блокировок и
их решение.
Транзакция — это не только логическая единица работы, но также
единица восстановления при неудачном выполнении операций.
Проблемы, возникающие при параллельной обработке транзакций,
могут быть разрешены с помощью методики управления параллельным
выполнением процессов под названием блокировка. Ее основная идея
проста: в случае, когда для выполнения некоторой транзакции необходимо
чтобы некоторый объект (обычно это кортеж базы данных) не изменялся
непредсказуемо и без ведома этой транзакции, такой объект блокируется.
Алгоритм функционирование блокировки заключается следующем:
1. Прежде всего, предположим, что в системе поддерживается два типа
блокировок: блокировка без взаимного доступа (монопольная блокировка),
называемая Х-блокировкой, блокировка с взаимным доступом, называемая Sблокировкой.
2. Если транзакция А блокирует кортеж р без возможности взаимного
доступа (Х-блокировка), то запрос другой транзакции В с отменен. будет
блокировкой этого кортежа р
3. Если транзакция А блокирует кортеж р с возможностью взаимного
доступа (S-блокировка), то запрос со стороны некоторой транзакции В на Хблокировку кортежа будет отвергнут; 00 запрос со стороны некоторой
транзакции В на S-блокировку кортежа будет принят (т.е. транзакция В
также будет блокировать кортеж р с помощью S-блокировки).
Алгоритм
Теперь следует ввести протокол доступа к данным, который на основе
Х и S-блокировок позволяет избежать возникновения проблем параллелизма,
описанных выше (билет №36).
1. Транзакция, предназначенная для извлечения кортежа, прежде всего
должна наложить S-блокировку на этот кортеж.
2. Транзакция, предназначенная для обновления кортежа, прежде всего
должна наложить Х-блокировку на этот кортеж. Иначе говоря, если,
например, для последовательности действий типа извлечение/обновление для
кортежа уже задана S-блокировка, то ее необходимо заменить Хблокировкой.
3. Если запрашиваемая блокировка со стороны транзакции В
отвергается из-за конфликта с некоторой другой блокировкой со стороны
транзакции А, то транзакция В переходит в состояние ожидания. Причем
транзакция В будет находится в состоянии ожидания до тех пор, пока не
будет снята блокировка, заданная транзакцией А.
4. X-блокировки сохраняются вплоть до конца выполнения транзакции
(до операции «завершение выполнения»). S-блокировки также обычно
сохраняются вплоть до этого момента.
Применение блокировок для решения проблем параллели:
Проблема потери результатов обновления
Хотя обновления не утрачиваются, но в момент времени t4 возникает
тупиковая ситуация.
Проблема незафиксированной зависимости
Транзакция А предохраняется от выполнения операций
незафиксированным изменением в момент времени t2.
Транзакция А предохраняется от выполнения операций с
незафиксированным изменением в момент времени 12.
Проблема несовместимого анализа
Проблема несовместимого анализа разрешается, но в момент времени
t7 возникает тупиковая ситуация.
Тупиковая ситуация
Хотя блокировку можно использовать для разрешения трех основных
проблем, возникающих при параллельной обработке кортежей,
использование, сожалению, приводит возникновению другой проблемы тупиковой ситуации. Два примера таких ситуаций были приведены выше.
Тупиковая ситуация возникает тогда, когда две или более транзакции
одновременно находятся в состоянии ожидания, причем для продолжения
работы каждая из транзакция ожидает прекращения выполнения другой
транзакции.
Желательно, чтобы при возникновении тупиковой ситуации система
могла обнаружить ее и найти из нее выход. Для обнаружения тупиковой
ситуации следует искать цикл в диаграмме состояний ожидания, т.е. в
перечне «транзакций, которые ожидают окончания выполнения других
транзакций». Поиск выхода из тупиковой ситуации состоит в выборе одной
из заблокированных транзакций в качестве жертвы и отмене ее выполнения.
Таким образом, с нее снимается блокировка, а выполнение другой
транзакции может быть возобновлено.
38. Триггеры БД.
Триггером (в контексте баз данных) называется хранимая в БД
процедура особого типа, которая автоматически вызывается при
возникновении заранее определенных событий в базе данных. Например,
добавлении и удалении строк, модификации столбцов.
Триггеры, в основном, используются для решения следующих задач:
- Проверка сложных ограничений целостности.
- Автоматизация обработки данных.
- Аудит действий пользователей. Установка начальных значений при
добавлении данных в таблицы.
- Проверка дифференцированных прав доступа.
Данные триггеры срабатывают на различные события, затрагивающие
работы СУБД и структуру БД.
К событиям уровня СУБД относятся запуск и останов сервера БД,
подключение и отключение клиента, возникновение ошибок.
К событиям уровня БД (схемы) относятся создание, удаление и
изменение таблиц.
Триггеры INSTEAD OF выполняются BMECТО тех команд, которые
являются событием триггера. Они обычно применяются для обновления
представлений, которые не являются обновляемыми.
Ограничения целостности для базовой таблицы представления
проверяются при выполнении команд изменения данных, которые
выполняются внутри триггера.
Ограничения триггеров INSTEAD OF:
- нельзя указывать тип BEFORE/AFTER;
- нельзя определять триггер уровня предложения;
- для команды UPDATE нельзя указывать список столбцов;
- нельзя указывать условие WHEN;
- в теле триггера обязательно должна быть команда DML.
Общий синтаксис создания триггера
trigger_definition ::= CREATE TRIGGER trigger_name
{ BEFORE | AFTER}
{INSERT | DELETE | UPDATE [OF column_commalist]}
ON table_name
[REFERENCING old_or_new_values_alias_list]
triggered_action
triggered_action ::= [ FOR EACH {ROW | STATEMENT}]
[WHEN left_paren conditional_expression right_paren]
triggered_SQL_statement
triggered_SQL_statement ::= SQL_procedure_statement
| BEGIN ATOMIC
SQL_procedure_statement_semicolonlist
END
old_or_new_values_alias ::= OLD [ ROW ][AS] correlation_name
| NEW [ ROW ] [AS ] correlation_name
| OLD TABLE [ AS ] identifier
| NEW TABLE [AS ] identifier
Основные параметры триггера
- INSERT | DELETE | UPDATE [of column] - событие триггера. Событием
триггера может быть одна команда или любая комбинация указанных
команд.
- BEFORE | AFTER - время срабатывания триггера: перед выполнением
события триггера или после него. Ограничения целостности проверяются во
время выполнения события триггера.
- ON <имя таблицы> таблица, к которой привязан триггер.
- FOR EACH {ROW | STATEMENT} - область действия триггера (для каждой
строки или для команды (предложения)).
- WHEN <условие> - условие срабатывания триггера. Если оно не
выполняется, триггер не будет запущен.
Триггер запускается автоматически при наступлении события триггера.
Триггер выполняется в рамках той транзакции, к которой относится
событие триггера, поэтому процедура триггера не может содержать команды
управления транзакциями и команды DDL.
Если команда инициирует выполнение более чем одного триггера, то, в
зависимости от типов, они выполняются в таком порядке:
1. «Перед началом выполнения команды» (Before-statement trigger)
2. «Перед обработкой записи» (Before-row trigger)
3. «После обработки записи» (After-row trigger)
4. «После окончания выполнения команды» (After-statement trigger)
Пример 1. Сложное ограничение целостности: Зарплата сотрудника
должна попадать в один из интервалов значений зарплаты, которые
установлены для разных категорий сотрудников в таблице sal_grade.
create or replace trigger check_salary
before INSERT or UPDATE of salary ON emp
for each row when :new.salary>=12000
declare cnt number(3);
begin
select count(*) into cnt from sal_grade
where :new.salary between low_value and high_value
if cnt=0 then raise_application_error(-20050, "Зарплата не попадает ни в
один из допустимых интервалов");
end if;
end;
:new. - обращение к полю новой записи (добавляемой или изменённой).
Пример 2. Аудит действий пользователей. Отслеживаем действия
пользователей над таблицей ТАВ и фиксируем данные о них в специальной
таблице TAB_LOG записывая туда имя пользователя, признак действия и
дату.
create or replace trigger audit_tab after INSERT or UPDATE or DELETE
ON tab
declare ch char:='U";
begin
if INSERTING then ch:= ‘I’
elsif DELETING then ch:= 'D';
end if;
insert into tab_log values (substr (user, 1, 30), ch, sysdate);
end;
INSERTING, DELETING и UPDATING - условные предикаты,
позволяющие определить, какая операция явилась событием триггера.
Пример 3. Автоматизация обработки данных. Автоматическое
добавление данных о предыдущей должности сотрудника в архив с
указанием даты, когда произошел перевод на другую должность.
Структура архивной таблицы:
create table emp_post(
id Триггер number(6) not null,
post varchar2(40) not null,
sdate date not null);
Триггер:
create or replace trigger cross_emp
before UPDATE of post ON emp
for each row
begin
insert into emp_post values(:old.id, :old.post, trunc(sysdate));
end;
:old. - обращение к полю старой записи (удалённой или изменяемой).
Пример 4. Установка значений по умолчанию. Если дата приема
сотрудника на работу не указана, то установить текущую дату. Перевести
ФИО сотрудника в верхний регистр.
create or replace trigger set_emp before
INSERT or UPDATE ON emp
for each row
begin
if :new.date_get IS NULL then :new.date_get:= trunc(sysdate);
else: new.date_get:= trunc(:new. date_get);
end if;
:new.name := upper(:new.name);
end;
39. Распределенные БД. Цели (правила).
Система распределенных баз данных состоит из набора узлов (site),
связанных коммуникационной сетью, в которой:
a) каждый узел - это полноценная СУБД сама по себе, но
б) узлы взаимодействуют между собой таким образом, что
пользователь любого из них может получить доступ к любым данным в сети
так, как будто они находятся на его собственном узле.
Из этого определения следует, что так распределенная база данных в
действительности представляет собой виртуальную базу данных,
компоненты которой физически хранятся в нескольких различных реальных
базах данных на нескольких различных узлах (в сущности, являясь
логическим объединением этих реальных баз данных).
На каждом узле есть собственные локальные реальные базы данных,
собственные локальные пользователи, собственные локальные СУБД и
программное обеспечение управления транзакциями (включая собственное
программное обеспечение блокировки, ведения журналов, восстановления и
т.д.) и собственный локальный диспетчер передачи данных.
В частности, любой пользователь может выполнять операции над
данными на своем локальном узле точно так же, как если бы этот узел вовсе
не входил в распределенную систему. Всю распределенную систему баз
данных можно рассматривать как некоторое партнерство между отдельными
локальными СУБД на отдельных локальных узлах. Новый программный
компонент на каждом узле - логическое расширение локальной СУБД предоставляет необходимые функциональные возможности для организации
подобного партнерства. Именно этот компонент вместе с существующими
СУБД составляет то, что обычно называется распределенной системой
управления базами данных (РСУБД).
Преимущества (?)
Так как обработка данных в крупных организациях чаще всего
распределена и логически разбита на подразделения, отделы, рабочие группы
и т.д., то часто есть распределение и физическое, т.е. разделены на отдельно
расположенные заводы, фабрики, лаборатории и т.д.
Из этого следует, что данные также обычно распределены, поскольку
каждая организационная единица на предприятии создает и обрабатывает
собственные данные, относящиеся к ее деятельности. Таким образом,
информация предприятия разбивается на отдельные автономные части,
которые иногда называют островами информации. А распределенная система
обеспечивает мосты для их соединения в единое целое. Иначе говоря,
распределенная система позволяет структуре базы данных отображать
структуру предприятия - локальные данные могут храниться локально, в
соответствии c логической принадлежностью, тогда как к удаленным данным
доступ может осуществляться по мере необходимости.
Двенадцать основных целей (ранее правил) необходимых для
обеспечения работы РСУБД:
1. Локальная независимость.
2. Отсутствие зависимости от центрального узла.
3. Непрерывное функционирование.
4. Независимость от расположения.
5. Независимость от фрагментации.
6. Независимость от репликации.
7. Обработка распределенных запросов.
8. Управление распределенными транзакциями.
9. Аппаратная независимость.
10. Независимость от операционной системы.
11. Независимость от сети.
12. Независимость от типа СУБД.
1. Локальная независимость
Узлы в распределенной системе должны быть независимы, или
автономны. Локальная независимость означает, что все операции на узле
контролируются этим узлом. Никакой узел Х не должен зависеть от
некоторого узла Y, чтобы успешно функционировать (иначе, если узел Y
будет отключен, узел X не сможет функционировать, даже если на самом
узле Х будет все в порядке).
Локальная независимость также означает, что локальные данные
имеют локальную принадлежность, управление и учет. Все данные реально
принадлежат одной и той же локальной базе данных, даже если доступ к ней
осуществляется с других, удаленных узлов.
Следовательно, такие вопросы, как безопасность, целостность, защита
и представление локальных данных на физическом устройстве хранения,
остаются под контролем и в пределах компетенции локального узла.
B действительности, локальная независимость не вполне достижима есть множество ситуаций, в которых узел X должен отказываться в
определенной степени от контроля в пользу узла Y. Поэтому цель
достижения локальной независимости точнее можно сформулировать так:
узлы должны быть независимыми в максимально возможной степени
2. Отсутствие зависимости от центрального узла
Локальная независимость предполагает, что все узлы в распределенной
системе должны рассматриваться как равные. Поэтому, в частности, не
должно быть никаких обращений к центральному, или главному, узлу для
получения некоторой централизованной услуги. Не должно быть, например,
централизованной обработки запросов, централизованного управления
транзакциями или централизованной службы присваивания имен, поскольку
в таких случаях система в целом будет зависимой от центрального узла.
Таким образом, вторая цель на самом деле является следствием первой цели если первая цель достигнута, то вторая цель также заведомо достигается.
Достижение цели "Отсутствие зависимости от центрального узла"
полезно само по себе, даже если полная локальная независимость узлов не
будет достигнута. Поэтому отдельная формулировка данной цели также
важна.
Зависимость от центрального узла может оказаться нежелательной по
крайней мере по двум следующим причинам. Во-первых, такой центральный
узел, скорее всего, станет узким местом системы, и, во-вторых (что еще
хуже), система станет уязвимой - если работа центрального узла будет
нарушена, то вся система выйдет из строя (проблема единственного
источника отказа).
3. Непрерывное функционирование
В общем случае преимущество распределенных систем состоит в том,
что они должны предоставлять более высокую степень надежности и
доступности.
Надежность - высокая степень вероятности того, что система будет
работоспособна и будет функционировать в любой заданный момент.
Надежность распределенных систем повышается за счет того, что они не
опираются на принцип «все или ничего»; распределенные системы могут
непрерывно функционировать (по меньшей мере, в сокращенном варианте)
даже в случаях отказов части их компонентов, таких как отдельный узел.
Доступность - высокая степень вероятности того, что система
окажется исправной и работоспособной и будет непрерывно
функционировать в течение определенного времени. Доступность, как и
надежность распределенных систем также повышается - частично по тем же
причинам, а также благодаря возможности дублирования данных.
4. Независимость от расположения
Основная идея независимости от расположения, или так называемой
прозрачности расположения, заключается в том, что пользователи не должны
знать, где именно данные хранятся физически и должны поступать так (по
крайней мере, с логической точки зрения), как если бы все данные хранились
на их собственном локальном узле.
Благодаря независимости от расположения упрощаются
пользовательские программы и терминальные операции. В частности, данные
могут быть перенесены с одного узла на другой, и это не должно требовать
внесения каких-либо изменений в использующие их программы или действия
пользователей. Эта переносимость позволяет перемещать данные в сети в
соответствии с изменяющимися требованиями к эффективности работы
системы.
5. Независимость от фрагментации
Система поддерживает независимость данных от фрагментации, если
некоторая переменная отношения может быть разделена на части, или
фрагменты, при организации ее физического хранения, а различные
фрагменты могут храниться на разных узлах. Фрагментация желательна для
повышения производительности системы. В этом случае данные могут
храниться в том месте, где они чаще всего используются, что позволяет
достичь локализации большинства операций и уменьшения сетевого
трафика.
6. Независимость от репликации
Система поддерживает репликацию данных, если данная хранимая
переменная отношения (или в общем случае данный фрагмент данной
хранимой переменной отношения) может быть представлена несколькими
отдельными копиями, или репликами, которые хранятся на нескольких
отдельных узлах.
Репликация желательна по крайней мере по двум причинам. Вопервых, она способна обеспечить более высокую производительность,
поскольку приложения смогут обрабатывать локальные копии вместо того,
чтобы устанавливать связь с удаленными узлами.
Во-вторых, наличие репликации может также обеспечивать более
высокую степень доступности, поскольку любой реплицируемый объект
остается доступным для обработки (по крайней мере, для выборки данных),
пока хотя бы одна реплика в системе остается доступной.
Главным недостатком репликации, безусловно, является то, что если
реплицируемый объект обновляется, то и все его копии должны быть
обновлены (проблема распространения обновлений).
7. Обработка распределенных запросов
Для распределенной БД возникают задачи, требующие сформировать
ответ на основе объединения информации из нескольких локальных аД.
Например, запрос для объединения отношения Rx, хранимого на узле X, и
отношения Ry, хранимого на узле Y, может быть выполнен посредством
пересылки отношения Rx на узел Y или отношения Ry на узел X, или обоих
отношений на какой-либо узел Z и т.п.
Что требует проработки и выбора наиболее подходящей для текущей
ситуации стратегии обработки информации.
8. Управление распределенными транзакциями
B распределенной системе отдельная транзакция может потребовать
выполнения кода на многих узлах, в частности, это могут быть операции
обновления, выполняемые на нескольких узлах. Поэтому говорят, что каждая
транзакция содержит несколько агентов, где под агентом подразумевается
процесс, который выполняется для данной транзакции на отдельном узле.
Система должна знать, что два агента являются элементами одной и той же
транзакции, например, два агента, которые являются частями одной и той же
транзакции, безусловно, не должны оказываться в состоянии взаимной
блокировки.
Чтобы обеспечить неразрывность транзакции (выполнение ее по
принципу «все или ничего») в распределенной среде, система должна
гарантировать, что все множество относящихся к данной транзакции агентов
или зафиксировало свои результаты, или выполнило откат.
9. Аппаратная независимость
Должна быть обеспечена возможность эксплуатировать одну и ту же
СУБД на различных аппаратных платформах.
10. Независимость от операционной системы
Необходимо обеспечить функционирование СУБД под управлением
различных операционных систем для многих платформ -- включая различные
операционные системы на одном и том же оборудовании.
11. Независимость от сети
Должна быть обеспечена коммуникационных поддержка различных
типов сетей.
12. Независимость от типа СУБД
Порой соединение нескольких отдельных БД в одну распределенную
происходит для уже готовых и функционирующих систем.
B этом случае необходимо чтобы экземпляры СУБД на различных
узлах все вместе поддерживали один и тот же интерфейс, и совсем не
обязательно, чтобы это были копии одной и той же версии СУБД.
40. Распределенные БД. Проблемы.
Ключевая проблема распределенных систем состоит в том, что
коммуникационные сети, по крайней мере, сети, которые охватывают
большую территорию, или глобальные сети, пока остаются медленными по
сравнению со скоростью передачи данных внутри самой ЭВМ.
Поэтому основная задача распределенных систем (по меньшей мере, в
случае глобальной сети, а также до некоторой степени и в случае локальной
сети) - минимизировать использование сетей, т.е. минимизировать
количество и объем передаваемых сообщений.
Решение этой задачи, в свою очередь, затрудняется из-за проблем в
нескольких дополнительных областях:
- Обработка запросов.
- Упра ление каталогом.
- Распространение обновлений.
- Управление восстановлением.
- Управление параллельностью.
1. Обработка запросов
Представляет собой задачу минимизации использования сети, процесс
оптимизации запросов должен быть распределенным, как и процесс
выполнения запросов. Иначе говоря, в общем случае процесс оптимизации
будет включать этап глобальной оптимизации, за которым последуют этапы
локальной оптимизации на каждом участвующем узле.
2. Управление каталогом
В распределенной системе системный каталог включает не только
обычные для каталога данные, касающиеся базовых переменных отношения,
представлений, ограничений целостности, полномочий и т.д., но также
содержит всю необходимую управляющую информацию, которая позволит
системе обеспечить независимость от размещения, фрагментации и
репликации.
Способы хранения системного каталога:
a). Централизованное хранение. Единственный общий каталог хранится на
отдельном центральном узле.
б). Полная репликация. Общий каталог целиком хранится на каждом узле.
в). Частичное секционирование. Каждый узел поддерживает собственный
каталог для объектов, которые на нем хранятся. Общий каталог представляет
собой объединение всех этих непересекающихся локальных каталогов.
г). Сочетание подходов 1 и 3. На каждом узле поддерживается свой
локальный каталог, ак предусмотрено в подходе 3. Кроме того, отдельный
центральный узел сопровождает объединенную копию всех этих локальных
каталогов, как предусмотрено в подходе 1.
Каждый подход имеет свои недостатки. При подходе a) очевидно
нарушается принцип «отсутствия зависимости от центрального узла». При
подходе б) в значительной мере утрачивается независимость узлов,
поскольку всякое обновление каталога должно распространяться на каждый
узел. При подходе в) нелокальные операции становятся слишком
дорогостоящими (для поиска удаленного объекта требуется доступ в среднем
к половине всех узлов). Подход г) более эффективен по сравнению с
подходом 3 (для поиска удаленного объекта требуется доступ лишь к одному
удаленному каталогу), но в этом случае вновь нарушается принцип
отсутствия зависимости от центрального узла. Поэтому на практике в
системах обычно не используется ни один из этих четырех подходов!
В реальности чаще всего используется следующий подход.
В системе различаются вводимые имена, с помощью которых
пользователи обычно обращаются к объектам (например, в конструкции
SELECT языка SQL), и общесистемные имена, которые представляют собой
глобально уникальные внутренние идентификаторы для этих же объектов.
Общесистемные имена имеют четыре описанных ниже компонента.
- Идентификатор создателя, т.е. идентификатор пользователя, который
впервые вызвал на выполнение операцию CREATE для создания
рассматриваемого объекта.
- Идентификатор узла создателя, т.е. идентификатор узла, на котором была
введена соответствующая операция CREATE.
- Локальное имя, т.е. неуточненное имя объекта.
- Идентификатор узла происхождения, т.е. идентификатор узла, на котором
объект хранился первоначально.
Далее или происходит подстановка компонентов общесистемного
имени к локальному имени из запроса пользователя, или используются
таблицы синонимов, по которым производится замена.
3. Распространение обновлений
Основная проблема репликации данных заключается в том, что
обновление любого заданного логического объекта должно распространяться
по всем хранимым копиям этого объекта. Сложности, которые возникают в
этом случае, состоят в том, что некоторый узел, содержащий копию данного
объекта, в момент обновления может оказаться недоступным, поскольку
произошел отказ узла или сети во время обновления. Таким образом,
очевидная стратегия немедленного распространения обновлений по всем
существующим копиям будет, вероятно, неприемлема, поскольку она
подразумевает, что любая операция обновления, а значит, и вся включающая
ее транзакция, закончится аварийно, если одна из требуемых копий в момент
обновления окажется недоступной. Получается, что при этой стратегии
данные будут менее доступными, чем при отсутствии репликации.
Общепринятая схема решения этой проблемы (но не единственное
возможное решение) состоит в использовании так называемой схемы
первичной копии:
Одна копия для каждого реплицируемого объекта устанавливается как
первичная копия, а все оставшиеся копии - как вторичные.
Первичные копии различных объектов находятся на различных узлах
(поэтому данная схема также является распределенной).
Операции обновления считаются логически завершенными, как только
обновлена первичная копия. Узел, содержащий такую копию, будет отвечать
за распространение обновления на вторичные копии в течение некоторого
последующего времени.
Однако эта схема тоже порождает проблемы и нарушает локальную
автономность.
4. Управление восстановлением
Управление восстановлением в распределенных системах обычно
базируется на протоколе двухфазной фиксации транзакций (или некоторых
его вариантах). Двухфазная фиксация транзакций требуется в любой среде,
где отдельная транзакция может взаимодействовать с несколькими
автономными диспетчерами ресурсов. Однако в распределенных системах ее
использование приобретает особую важность, поскольку рассматриваемые
диспетчеры ресурсов, т.е. локальные СУБД, функционируют на отдельных
узлах и поэтому в значительной мере автономны.
Рассмотрим некоторые особенности этого процесса:
1. Принцип «отсутствия зависимости от центрального узла»
предписывает, что функции координатора не должны назначаться одному
выделенному узлу в сети, а должны выполняться на различных узлах для
различных транзакций. Обычно управление транзакцией передается на тот
узел, на котором она была инициирована. Поэтому каждый узел (как
правило) должен быть способен выполнять функции координатора для
некоторых транзакций и выступать в качестве участника выполнения
остальных транзакций.
2. Для двухфазной фиксации транзакций координатор должен
взаимодействовать c каждым участвующим узлом, что подразумевает
увеличение количества сообщений, а значит, дополнительную нагрузку на
коммуникации.
3. Если узел Y является участником транзакции, выполняемой по
протоколу двух фазной фиксации и координируемой узлом X, узел Y должен
делать то, что предписывает ему узел X (фиксацию результатов транзакции
или ее откат в зависимости от того, что именно потребуется), а это означает
потерю (хотя и относительно незначительную) локальной автономности.
Отличие двухфазной фиксации транзакций от рассмотренной ними
ранее заключается в том, что координатор транзакции должен собрать
подтверждение или отказы от всех участников и выслать команду на
фиксацию или откат транзакции.
B реальности этот механизм значительно осложняется возможными
сбоями на любом участке информационного взаимодействия.
5. Управление параллельностью
Управление параллельным доступом в большинстве распределенных
систем строится на использовании механизма блокировки, т.е. точно так, как
и в большинстве нераспределенных систем. Однако в распределенных
системах запросы на проверку, установку и отмену блокировки становятся
сообщениями (если считать, что рассматриваемый объект расположен на
удаленном узле), a сообщения создают дополнительные издержки.
Рассмотрим, например, транзакцию обновления объекта, для которого
существуют дубликаты на n удаленных узлах. Если каждый узел отвечает за
блокировку объектов, которые на нем хранятся (как предполагается в
соответствии с принципом локальной независимости), то непосредственная
реализация будет требовать по крайней мере 5•n таких сообщений (n
запросов на блокировку; n разрешений на блокировку; n сообщений об
обновлении; n подтверждений; n запросов на снятие блокировки).
Для решения проблемы обычно выбирается стратегия первичной
копии, рассмотренная ранее в подразделе «Распространение обновлений».
Для данного объекта А все операции блокировки будет обрабатывать узел,
содержащий его первичную копию (в общем случае первичные копии
различных объектов будут размещаться на разных узлах). При
использовании этой стратегии набор всех копий объекта с точки зрения
блокировки можно рассматривать как единый объект, а общее количество
сообщений будет сокращено с 5•n до 2•n+3 (один запрос блокировки, одно
разрешение блокировки, n обновлений, n подтверждений и один запрос на
снятие блокировки). Но это решение влечет за собой серьезную потерю
независимости - транзакция может теперь не завершиться, если первичная
копия окажется недоступной, даже если в транзакции выполнялось лишь
чтение и локальная копия была доступна.
Таким образом, y стратегии первичной копии есть нежелательный
побочный эффект - снижение уровня производительности и доступности как
для выборки, так и для обновления.
Другая проблема, касающаяся блокировок в распределенных системах,
состоит в том, что блокировка может привести к состоянию глобальной
взаимоблокировки, охватывающей два или больше узлов.
В состоянии глобальной взаимоблокировки никакой узел не может
обнаружить ситуацию взаимоблокировки, используя лишь собственную
внутреннюю информацию. Так как в локальном графе ожиданий нет никаких
циклов, и подобный цикл возникает только при объединении лока ьных
графов в общий глобальный граф. Поэтому для обнаружения состояния
глобальной блокировки требуются дополнительные коммуникационные
расходы, поскольку необходимо, чтобы отдельные локальные графы
рассматривались вместе.
41.Большие данные. Определение. Признаки.
Big Data «Большие данные» — серия подходов, инструментов и
методов обработки структурированных и неструктурированных данных
огромных объёмов и значительного многообразия для получения
воспринимаемых человеком результатов, эффективных в условиях
непрерывного прироста, распределения по многочисленным узлам
вычислительной сети, сформировавшихся в конце 2000-х годов,
альтернативных традиционным системам управления базами данных и
решениям класса Business Intelligence.
Big Data — это не какой-то конкретный объем данных и даже не сами
данные, а методы их обработки, которые позволяют распределено
обрабатывать информацию. Эти методы можно применить как к огромным
массивам данных, так и к маленьким.
Признаки “Больших данных”
V — Volume — объем данных: от 150 Гб в сутки (число во многом
абстрактное и не является абсолютным и принятым мерилом);
V — Velocity — скорость накопления и обработки массивов данных.
Большие данные обновляются регулярно, поэтому необходимы
интеллектуальные технологии для их обработки в режиме онлайн;
V — Variety — разнообразие типов данных. Данные могут быть
структурированными, неструктурированными или структурированными
частично. Например, в соцсетях поток данных не структурирован: это могут
быть текстовые посты, фото или
видео.
V — Veracity — достоверность как самого набора данных, так и
результатов его анализа;
V — Variability — изменчивость. У потоков данных бывают свои пики
и спады под влиянием сезонов или социальных явлений. Чем нестабильнее и
изменчивее поток данных, тем сложнее его анализировать;
V — Value — ценность или значимость. Как и любая
информация, большие данные могут быть простыми или сложными для
восприятия и анализа.
Пример простых данных — это посты в соцсетях, сложных —
банковские транзакции.
Есть и седьмое V — Visualization — но это скорее тенденция подавать
результаты расчетов и исследований в упрощенной форме.
42.Большие данные. Основные источники данных. Основные принципы
работы.
Big Data «Большие данные» — серия подходов, инструментов
и методов обработки структурированных и неструктурированных данных
огромных объёмов и значительного многообразия для получения
воспринимаемых человеком результатов, эффективных в условиях
непрерывного прироста, распределения по многочисленным узлам
вычислительной сети, сформировавшихся в конце 2000-х годов,
альтернативных традиционным системам управления базами данных и
решениям класса Business Intelligence.
Big Data — это не какой-то конкретный объем данных и даже не сами
данные, а методы их обработки, которые позволяют распределено
обрабатывать информацию. Эти методы можно применить как к огромным
массивам данных, так и к маленьким
Основные источники данных:
— интернет вещей (loT) и подключенные к нему устройства;
— соцсети, блоги и СМИ;
— данные компаний: транзакции, заказы товаров и услуг, поездки на такси и
каршеринге, профили клиентов;
— показания приборов: метеорологические станции, измерители состава
воздуха и водоемов, данные со спутников;
— статистика городов и государств: данные о перемещениях, рождаемости и
смертности;
— медицинские данные: анализы, заболевания, диагностические снимки.
— PRISM - технология сбора данных пользователей посредством сбора
информации из их личных переписок. Существует мнение, что технология
собирает данные, по ключевым словам, на каждого пользователя.
Основные принципы работы.
1. Горизонтальная масштабируемость. Поскольку данных может быть
сколь угодно много — любая система, которая подразумевает обработку
больших данных, должна быть расширяемой. В 2 раза вырос объем данных - в
2 раза увеличили количество железа в кластере и всё продолжало работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости
подразумевает, что машин в кластере может быть много. Это означает, что
часть этих машин будет гарантированно выходить из строя. Методы работы с
большими данными должны учитывать возможность таких сбоев и
переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные
распределены по большому количеству машин. Если данные физически
находятся на одном сервере, а обрабатываются на другом — расходы на
передачу данных могут превысить расходы на саму обработку. Поэтому одним
из важнейших принципов проектирования-BIG DATA решений является
принцип локальности данных — по возможности обрабатываем данные на той
же машине, на которой их храним.
43.Большие данные. Методы анализа. Основные применяемые
технологии.
Big Data «Большие данные» — серия подходов, инструментов
и методов обработки структурированных и неструктурированных данных
огромных объёмов и значительного многообразия для получения
воспринимаемых человеком результатов, эффективных в условиях
непрерывного прироста, распределения по многочисленным узлам
вычислительной сети, сформировавшихся в конце 2000-х годов,
альтернативных традиционным системам управления базами данных и
решениям класса Business Intelligence.
Big Data — это не какой-то конкретный объем данных и даже не сами
данные, а методы их обработки, которые позволяют распределено
обрабатывать информацию. Эти методы можно применить как к огромным
массивам данных, так и к маленьким.
Методы анализа.
1. Описательная аналитика (descriptive analytics) — самая
распространенная. Она отвечает на вопрос «Что произошло?», анализирует
данные, поступающие в реальном времени, и исторические данные. Главная
цель — выяснить причины и закономерности успехов или неудач в той или
иной сфере, чтобы использовать эти данные для наиболее эффективных
моделей. Для описательной аналитики используют базовые математические
функции. Типичный пример — социологические исследования или данные
веб-статистики, которые компания получает через Google Analytics.
2. Прогнозная или предикативная аналитика (predictive analytics) —
помогает спрогнозировать наиболее вероятное развитие событий на основе
имеющихся данных. Для этого используют готовые шаблоны на основе какихлибо объектов или явлений с аналогичным набором характеристик. С
помощью предикативной (или предиктивной, прогнозной) аналитики можно,
например, просчитать обвал или изменение цен на фондовом рынке. Или
оценить возможности потенциального заемщика по выплатекредита.
3. Предписательная аналитика (prescriptive analytics) — следующий
уровень по сравнению с прогнозной. С помощью Big Data и современных
технологий можно выявить проблемные точки в бизнесе или любой другой
деятельности и рассчитать, при каком сценарии их можно избежать их в
будущем.
4. Диагностическая аналитика (diagnostic analytics) — использует —
данные, чтобы проанализировать причины произошедшего. Это помогает
выявлять аномалии и случайные связи между событиями и действиями.
Основные применяемые технологии.
1.NoSQL — обозначение широкого класса разнородных систем
управления базами данных, появившихся в конце 2000-х — ада 2010-х годов
и существенно отличающихся от традиционных реляционных СУБД с
доступом к данным средствами языка $О1. Относится к системам, в которых
делается попытка решить проблемы масштабируемости и доступности за счёт
полного или частичного отказа от требований атомарности и согласованности
данных.
2. MapReduce — модель распределенных вычислений, представленная
компанией Google, используемая для параллельных вычислений над очень
большими, вплоть до нескольких петабайт, наборами данных в компьютерных
кластерах.
3.Hadoop — свободно распространяемый набор утилит, библиотек и
фреймворк для разработки и выполнения распределённых программ,
работающих на кластерах из сотен и тысяч узлов. Используется для
реализации
поисковых
и
контекстных
механизмов
многих
высоконагруженных веб-сайтов. Разработан нa Java в рамках вычислительной
парадигмы MapReduce, согласно которой приложение разделяется на большое
количество одинаковых элементарных заданий, выполняемых на узлах
кластера и естественным образом сводимых в конечный результат.
4. R — язык программирования для статистической обработки данных и
работы с графикой, а также свободная программная среда вычислений с
открытым исходным кодом в рамках проекта GNU.
Также применяются и традиционные методы анализа данных и
классические реляционные БД, но с учетом специфики «больших данных».
44. Базы геоданных. Определение. Классификация представления
географических объектов.
Базы геоданных, они же Географические базы данных — подвид баз
данных, ориентированных на хранение геопространственных данных для
географических информационных систем (далее — ГИС).
Модель данных базы геоданных имеют близкую физическую и
логическую модели данных. Объекты данных в базе геоданных представляют
собой практически те же объекты, которые были заданы в логической модели
данных, например: владельцев, строения, земельные участки, дороги.
Базы геоданных имеют информационную модель для отображения и
управления географической информацией. Эта информационная модель
обычно реализуется серией простых таблиц с данными, содержащих классы
пространственных объектов, наборы растров и атрибуты. Кроме того,
расширенные объекты ГИС-данных добавляют ГИС-поведение, правила для
управления пространственной целостностью и инструменты для работы с
многочисленными
пространственными
отношениями
основных
пространственных объектов, растров и атрибутов.
Классификация представления географических объектов.
Географические объекты в географической базе данных (далее— ГБД)
представляются в виде:
— векторных данных;
Векторные данные представляю собой набор координат (географических или
линейных), соответствующих положению конкретного объекта в
пространстве.
Примерами векторных примитивов выступают:
●
●
●
●
●
●
точка;
линия;
ломанная линия;
замкнутый многоугольник;
дуга;
эллипс.
— растровых данных;
Растровые данные это изображение множества точек на местности или
в пространстве, каждая из которых имеет свои значения цвета или
описательные характеристики. Точки хранятся в памяти в виде таблицы
(двумерной или трехмерной). Часть точек имеет привязки к координатам на
местности.
Примером растровых данных выступают:
● спутниковый снимок;
● аэрофотоснимок;
● отсканированная карта.
— нерегулярной триангуляционной сети (TIN) для
представления поверхностей;
Триангуляционные сети позволяют связать набор точек в единое
трехмерное пространство. Треугольники выбраны в качестве опорных фигур
так как для них проще всего выполнять расчеты и трех точек достаточно для
формирования плоскости в пространстве.
TIN поддерживает изображения в перспективе. Можно наложить
фотографическое изображение поверх тм для фотореалистичного
отображения рельефа местности.
TIN являются особенно полезными для моделирования:
●
●
●
●
●
●
водосборов;
ЛИНИИ прямой видимости;
крутизны;
экспозиции;
хребтов и рек;
измерений объемов.
— адресов и локаторов для нахождения географического
положения.
Все геопространственные данные имеют:
— геометрию;
— атрибуты;
— «правила поведения».
По геометрии объекты бывают:
— точечные; х
— линейные;
— площадные.
Атрибуты несут всю описательную информацию об объекте: тип, цвет,
форма, высота, состояние, материал и т.д.
Правила поведения — условия отображения объекта, его обработки и
т.п.
Наборы объектов могут объединятся специальные группы по
темам данных — слои.
45.Базы геоданных. Слои. Особенности построения ГБД
Базы геоданных, они же Географические базы данных — подвид баз данных,
ориентированных на хранение геопространственных данных для
географических информационных систем (далее — ГИС).
Модель данных базы геоданных имеют близкую физическую и логическую
модели данных. Объекты данных в базе геоданных представляют собой
практически те же объекты, которые были заданы в логической модели
данных, например: владельцев, строения, земельные участки, дороги.
Базы геоданных имеют информационную модель для отображения и
управления географической информацией. Эта информационная модель
обычно реализуется серией простых таблиц с данными, содержащих классы
пространственных объектов, наборы растров и атрибуты. Кроме того,
расширенные объекты ГИС-данных добавляют ГИС-поведение, правила для
управления пространственной целостностью и инструменты для работы с
многочисленными пространственными отношениями основных
пространственных объектов, растров и атрибутов.
Слои
Все геопространственные данные имеют:
— геометрию;
— атрибуты;
— «правила поведения».
По геометрии объекты бывают:
— точечные; х
— линейные;
— площадные.
Наборы объектов могут объединятся специальные группы по темам данных —
слои.
Тема данных представляет собой набор связанных между собой
географических объектов, например дорожная сеть, набор границ земельных
участков, типы почв, поверхность рельефа, космический снимок
определенного участка земной поверхности (местоположение скважин).
Концепция тематических слоев появилась в начальный период развития ГИСтехнологий, когда специалисты изучали способы как представляемую на
картах географическую информацию можно было бы разбить на логические
информационные слои более эффективно, чем при помощи простого деление
на наборы отдельных объектов (дорога, мост, холм, полуостров). Таким
образом, эти ГИС-пользователи организовывали информацию в тематические
слои, которые могли бы описать распределение географического явления, а
также устанавливали правила их визуализации в различных географических
масштабах. Эти слои также имели определенный протокол (правила записи),
по которому происходило объединение представлений (в виде наборов
пространственных объектов, растровых слоев, атрибутивных таблиц).
Набор тем выступает в роли слоев в группе. С каждой темой
можно работать как с набором информации, независимо от других
тем.
Каждая тема обладает собственными средствами представления (точки,
линии, полигоны, поверхности, растры и так далее). Поскольку различные
несвязанные между собой темы являются пространственно
координированными (привязанными), то они будут накладываться друг на
друга и могут быть объединен при отображении общей карты. Помимо этого,
при выполнении операций ГИС-анализа, например наложения, может
осуществляться объединение информации между темами. Отдельные наборы
данных ГИС нередко собираются вместе с другими слоями данных. Хотя
любой набор данных ГИС можно использовать отдельно ото всех остальных
ГИС-данных, очень часто бывает важно, чтобы собранные данные
согласовывались с другими информационными слоями, для поддержки
пространственных взаимоотношений и поеду связанными ГИС-слоями
данных.
Например:
1.Гидрологическую информацию о водоразделах и водосборных бассейнах
следует собирать вместе с информацией о дренажной сети. Линии
водосборов должны попадать внутрь бассейнов. Все остальные слои должны
совпадать с поверхностью рельефа.
2.Различные слои данных в материалах по земельным участкам должны быть
собраны в соответствии с информацией из кадастровых слоев и
геодезической информацией, чтобы пространственные объекты земельных
участков совпадали с опорной сетью геодезических данных. Множество
прочих наборов пространственных объектов (зоны отчуждения, межевые
границы, коммуникации, классы зон) должны соответствовать набору
данных участков.
3.Пространственные отношения между рельефом, ландшафтами, типами
почв, уклонами, растительностью, геологией обычно также собирают вместе,
характеризуя тем самым природные ресурсы. Научное понимание этих
пространственных отношений помогает построить логически согласованную
базу данных, где пространственные объекты одного слоя данных
соответствуют объектам остальных слоев.
4.Гидрографию, транспортные сети, администрАтивные границы и прочие
слои топографической карты следует компилировать вместе. Эти
картографические представления на отображении карты должны быть
интегрированы, чтобы с такой картой было удобно работать и можно было
обращать внимание на ее ключевые позиции.
В каждом из этих случаев существует модель данных, которая определяет
набор связанных тематических данных, соответствующих общей
информационной рабочей среде. Каждая рабочая среда по существу, является
коллекцией связанных тематических данных, которые собирают вместе.
Общие правила
сбора данных соответствуют научным принципам их пространственного
поведения и взаимосвязей. Каждая тема играет важную роль в целостной
характеристике определенного ландшафта.
Особенности построения ГБД
1.Часть географических объектов могут иметь одинаковые координаты. Как
точечные, так и линейные или площадные.
Это позволяет с одной стороны, выделить наборы координат в отдельные
таблицы, сократить объем хранящихся данных и упростить их
корректировку, а с другой — требуется формировать набор координат для
конкретного объекта дополнительным запросом или запросами к БД, что
замедляет время работы
системы в целом.
2.Сведение в единую базу информации из разных источников и/или с
разными датами формирования может привести к формированию дубликатов
объектов. Причем в общем случае нет способа определить являются они
одним объектом или дублем с измененными координатами и/или
характеристиками.
3.Для географических объектов важно — направление перечисления
координат, так как существует понятие внешней и внутренней границы,
которое характеризует правила отображения геообъектов.
4.Диапазон масштабирования изображения оказывает существенное влияние
на количество хранимых координат линейных и площадных объектов. Чем
крупнее масштаб, тем больше надо формировать и хранить координат. Но
при переходе к
мелкомасштабным режимам отображения приходится передавать множество
координат множества объектов, причем точность этих координат будет
избыточна, так как множество географических точек будут сливаться в одну
точку изображения. Для уменьшения нагрузки можно использовать
следующие и аналогичные методы:
— отключать отображение некоторых объектов;
— пересчитывать координаты для текущего масштаба, сокращая количество
отображаемых точек;
— хранить наборы координат разной точности для разных масштабов
отображения;
— ограничить диапазон масштабов;
— использовать разные наборы данных (карты, слои) для разных масштабов.
5.Должен быть предусмотрен слой или слои пользовательских объектов с
возможностью их хранения в ГБД и привязки к существующим объектам.
При этом должно быть предусмотрено решение проблемы сохранения
данных пользователя при изменении или удалении объекта, с котором они
были связаны.