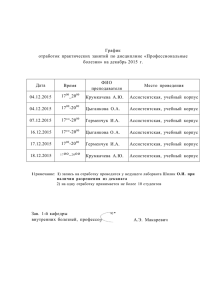
На сегодняшний день многие языки мира имеют собственные лингвистические корпусы, различающиеся по объему, типу языковых данных, полноте, целевому назначению и уровню научной обработки текстов. Но, тем не менее, общепризнанным эталоном остаются лингвистические корпусы английского языка. Британский национальный корпус. Объем корпуса Сбалансированность составляет корпуса 100 млн. достигается словоупотреблений. пропорциональным представлением разнообразных по стилю, жанру и тематике текстов, 90 % которых относятся к письменной речи и 10 % — к устной. Корпус характеризуется использованием как полных текстов, если их объем не превышает 45 000 слов, так и текстовых фрагментов. Британский национальный корпус — это синхронный корпус, что означает, что он отражает состояние британского английского конца ХХ — начала ХХI веков. Следовательно, используя ресурсы только данного корпуса, не представляется возможным проследить за неологизмами, проникающими в английский язык, или за уже существующими словами, меняющими свое значение, не представляется возможным. Корпус снабжен метатекстовой и морфологической разметками. Благодаря морфологической разметке можно осуществлять поиск как конкретной словоформы, так и всех форм одной лексемы. Также в Британском национальном корпусе можно искать и словосочетания, включая разрывные, получать информацию об относительной частоте встречаемости искомых объектов, информацию о частоте коллокаций для отдельных лексем. С использованием специального конструктора запросов возможен поиск сложных конструкций. Наличие метатекстовой разметки позволяет получить информацию об источниках примеров: авторе, жанре, времени создания. Одним из главных недостатков Британского национального корпуса для обычного пользователя, преподавателя или студента, является тот факт, что этот корпус с ограниченным доступом. Корпус современного американского английского Ещё одним из больших представительных и авторитетных корпусов является корпус современного американского варианта английского. Он был создан М.Дэвисом в 2008 году. На данный момент это единственный большой, сбалансированный корпус американского варианта английского языка объемом 445 миллионов словоупотреблений. Корпус находится в свободном доступе, но необходима регистрация. Этот корпус является корпусом смешанного типа, поскольку в нем представлены и письменные тексты (художественная проза, популярные журналы, газеты, научная литература и пр.), и устная речь. Корпус содержит в одинаковых пропорциях устную речь, художественную литературу, журнальные статьи, газеты, научные тексты. Как современного и Британский национальный американского варианта английского корпус, корпус языка является полнотекстовым и снабжен метатекстовой и морфологической разметками. Поисковый интерфейс предоставляет широкие возможности: поиск слов, словосочетаний, лемм, грамматических форм. Можно получить как все контексты, в которых встречается интересующее пользователя слово или словосочетание, так и информацию о распределении частоты их употребления по жанрам и по годам. В отличие от своего британского аналога, работая с корпусом современного американского варианта английского языка, можно также осуществлять поиск синонимических рядов и поиск по спискам пользователя. Корпус обновляется два раза в год и удобен для отслеживания динамики лингвальных изменений. Каждый год периода с 1990 по 2009 г. представлен текстами объемом по 20 миллионов словоупотреблений. Таким образом, в отличие от Британского национального корпуса, корпус современного американского динамическим корпусом. варианта английского языка является Банк английского языка Банк английского языка – это подкорпус крупнейшей языковой базы английского языка Collins Corpus. Банк английского языка представляет уникальный в своем роде мониторный корпус английского языка. Регулярное пополнение корпуса новыми текстами дает возможность отслеживать все изменения, касающиеся английской лексической системы, например, появление новых слов, изменение значений уже существующих лексем, изменение частоты употребления слов и грамматических конструкций в речи. Отличительной чертой данного корпуса является всеобъемлющее отражение состояния английского языка современного охватывает английского английский языка, язык в т. е. Банк целом, в пропорциональном соотношении всех его вариантов. Данный корпус содержит свыше 650 млн. словоупотреблений, 65–70 % из которых представляют британский вариант английского языка, 25–30 % — американский, 5 % — другие варианты: канадский, австралийский и др. В состав корпуса входят различные типы письменных текстов и устной речи. Данный корпус включает метатекстовую разметку, а также частеречную с элементами морфологической разметки. Можно искать слова по словоформе, лемме, задавать поиск разрывных словосочетаний. Для пользователей предусмотрена возможность ограничивать поиск определенным жанром, тематикой, временным периодом. Можно также получить полную информацию о частотных характеристиках лексем и их сочетаемости. Как и у большинства западных лингвистических корпусов, доступ к полной версии Банка английского языка платный. Однако возможна пробная бесплатная подписка на один месяц для получения доступа в Collins Wordbanks Online, открытой пробной версии этого корпуса. На основе корпусных данных Банка английского языка в 1991 г. был составлен первый словарь Collins COBUILD, считающийся одним из лучших словарей современного английского языка. И по сегодняшний день данные Банка английского языка используются в создании как новых словарей этой серии, так и в усовершенствовании ранее изданных. Оксфордский корпус английского языка Оксфордский корпус английского языка является самым большим из когда-либо созданных. Он содержит свыше 2 млрд. словоупотреблений и отражает состояние современного английского языка на всей территории его распространения. В корпусе представлены тексты, созданные с 2000 года, основную часть составляют материалы, размещенные во Всемирной Паутине. Также в Оксфордский корпус английского языка вошел ряд текстов на бумажных носителях, в частности, технические инструкции, статьи из газет и журналов, произведения художественной литературы и т.п. Данный корпус используется сотрудниками Oxford University Press, в частности, для составления словарей. Национальный корпус американского английского Национальный корпус американского английского создан по образцу Британского Национального корпуса и призван отразить американский вариант современного английского языка. В корпусе представлены тексты, созданные начиная с 1990 г. На сегодняшний день объем корпуса составляет 22 млн. словоупотреблений, фрагмент объемом 15 млн. словоупотреблений доступен для свободного скачивания. В состав корпуса входят различные типы письменных текстов и устной речи. Корпус включает метатекстовую разметку, а также частеречную разметку. В общедоступной версии корпуса, размещенной на сайте solutions/wordbanksсуществует http://www.collinslanguage.com/contentвозможность выбора подкорпуса: британские книги, газеты, журналы, радиопередачи и др [5]. Кембриджский международный корпус (CambridgeInternationalCorpus)cоздавался как база для составления учебных материалов и словарей английского языка. В корпус вошли британские и американские тексты разных типов, записи устной речи носителей британского и американского вариантов английского языкаобщим объемом свыше 700 млн. словоупотреблений. Отдельный подкорпус образуют тексты экзаменационных работ студентов из разных стран, изучающих Международный английский корпус English,ICE)является английского в в качестве языка совокупностью отражающихсловоупотребление языка язык иностранного[3]. (International национальных различных Corpus of подкорпусов, вариантах английского (Австралия, Великобритания, Гонконг, Индия, Ирландия, Канада, Кения, Малайзия, Новая Зеландия, Филиппины, включает Шри-Ланка, письменные Сингапур, США, Танзания, Южная Африка, Ямайка). Каждый подкорпус и устные тексты иимеет объем1 млн. словоупотреблений. В настоящее времяInternational Corpus of English находится на этапе разработки. Полностью компонент корпуса (ICE-GB), его тексты синтаксической разметкой. На подготовлен Британский снабжены морфологической и сайте IІ Всеукраїнська науково-практична конференція "Інтелектуальні системи та прикладна лінгвістика",28березня 2013р., м. Харків53http://www.ucl.ac.uk/english-usage/projects/ice.htmпредоставляется свободный доступ к фрагменту корпусаобъемом20 тыс. словоупотреблений[4].Благодаря репрезентативности, большому объему, разнообразию жанров, наличию как устных, так и письменных текстов созданные корпусы английского языка предоставляют филологам богатое поле для исследования языка. Систематическийанализкорпусныхданныхпозволяетэффективноотслеживать изменениявязыке, создавать точные лексикографические описания, верифицировать лингвистические гипотезы. Национальный корпус албанского языка Национальный корпус албанского языка, насчитывающий в настоящее время около художественной 16700000 словоупотреблений. литературе и Тексты публицистике) (относящиеся снабжены к доступной пользователю морфологической (словоизменительной) разметкой, которая представляет собой набор помет, приписываемых отдельным словоупотреблениям. В перспективе планируется внедрение в Корпус других типов разметки. Корпус предназначен для тех, кто интересуется самыми разными вопросами, связанными с албанским языком, и способен предоставить справочную информацию как профессиональным лингвистам, так и всем, кто в силу профессии или простой любознательности проявляет интерес к албанскому языку и его истории. Глубоко аннотированный и представительный Корпус позволяет быстро обрабатывать большие массивы языкового материала, снабженного переводом и иной лингвистической информацией. Собранный материал может быть использован для научных исследований лексики и грамматики, а также для изучения процессов языковых изменений, происходивших в албанском языке на протяжении предшествующих столетий. В настоящее время Национальный корпус албанского языка находится в процессе разработки. Расширяется текстовая база, осуществляется пополнение грамматического словаря и морфологическая разметка текстов. В ближайшей перспективе будет выполняться работа по снятию омонимии в Корпусе. Создателям Корпуса предстоит решить еще ряд важных вопросов, связанных с дальнейшим расширением базы Корпуса: создание подкорпуса устных текстов, добавление текстов, созданных в разные периоды истории албанского языка, а также текстов на диалектах албанского языка. В разработке корпуса принимают участие лингвисты из СанктПетербурга: М. С. Морозова, М. В. Домосилецкая, А. Ю. Русаков, Е. Д. Бернацкая, А. Г. Сидько, А. В. Коноваленко. В подборе и обработке текстов участвовали М. М. Макарцев (Москва), Д. А. Алексеева (Санкт-Петербург), В. А. Дивеева (Санкт-Петербург), Керим Ондози (Приштина). Система автоматического морфологического анализа UniParser разработана Т. А. Архангельским (Москва). Постоянную консультативную помощь и всестороннюю поддержку оказывает участник различных проектов по разработке языковых корпусов М. А. Даниэль (Москва). Корпус новогреческого языка Корпус новогреческого языка представляет собой коллекцию текстов, дополненных разметкой разного вида и поисковым механизмом. Интерфейс корпуса позволяет задавать запросы вида «найти все примеры употребления словоформы или лексемы X», «найти все предложения, в которых слово X следует за словом Y на расстоянии от 2 до 5», «найти все примеры употребления родительного падежа после предлогов» и многие другие. Объём корпуса в настоящий момент составляет 35,7 млн словоупотреблений. Большинство текстов составляют выпуски греческих газет начала XXI века, но имеются также художественная литература, поэзия, официальная, научная и религиозная литература и переводные тексты, созданные в XX и XIX веках. Все тексты обладают морфологической разметкой, т. е. при каждом слове указана его лемма (начальная форма) и набор выраженных в слове грамматических значений (падеж, число и т. п.); все эти параметры можно использовать в поисковых запросах. Морфологическая разметка проводилась с помощью электронного грамматического словаря, составленного М. Л. Кисилиером и Т. А. Архангельским, и морфологического анализатора UniParser. Поскольку разметка и отчасти составление грамматического словаря были выполнены автоматически, в грамматической информации могут встречаться ошибки; в настоящий момент создатели корпуса работают над повышением качества морфологической разметки. Снятие омонимии в корпусе не проводилось — это значит, что каждой словоформе приписывались все возможные разборы без учёта контекста. Корпус языка идиш Корпус языка идиш – это информационно-справочная система, основанная на собрании текстов в электронной форме общим объемом около 4000000 словоупотреблений. Корпус предназначен для всех, кто интересуется самыми разными вопросами, связанными с языком идиш: профессиональных лингвистов, преподавателей языка, школьников и студентов, иностранцев, изучающих идиш. В Корпус языка идиш входят: мощная поисковая система для запросов, связанных с идишем; обучающая система, где для частотных лексем можно сразу видеть перевод на английский язык; система, охватывающая тексты от конца XIX века до начала XXI корпус письменных текстов века; Корпус языка идиш - размеченный корпус с морфологической и метатекстовой разметкой. Этот корпус находится в свободном доступе. В будущем планируется разместить также корпус языка устного дискурса — не только аудио-, но и видеозаписи и большое количество произведений классиков литературы на идише. Проект по созданию и развитию корпуса языка идиш — это совместный проект РАН и университета Регенсбурга, развивающийся преимущественно благодаря программе «Корпусная лингвистика» РАН. С российской стороны участниками проекта являются сотрудники различных институтов РАН, а также студенты МГУ и СПбГУ. Алматинский корпус казахского языка В настоящий момент размер корпуса составляет более 40 миллионов словоупотреблений. Тексты корпуса размечены с помощью автоматического морфологического анализатора, 86% словоформ корпуса имеют грамматический разбор. Омонимия в корпусе не снималась, т. е. каждой словоформе приписаны все возможные варианты разбора без учёта контекста. Алматинский корпус казахского языка – один из возможных вариантов Национального корпуса казахского языка как справочно-информационной системы на основе обширного фонда размеченных текстов литературного казахского языка, государственного языка Республики Казахстан. Корпус постоянно дополняется, обновляется как количественно, так и качественно, кроме того существенно улучшается поисковая функциональность корпуса. Основные характеристики Алматинского корпуса казахского языка: удобный инструмент для самостоятельного изучения казахского языка, дающий для большинства словоформ лексико-морфологические разборы и русские/английские переводные эквиваленты; аннотированный корпус, снабженный грамматической и библиографической разметкой; лингвистически репрезентативный корпус; корпус, находящийся в открытом доступе; сбалансированность корпуса, который включает художественные, научные, публицистические тексты. В перспективе намечаются следующие характеристики Алматинского корпуса казахского языка: мощный поисковый аппарат для осуществления сложных лексико-морфологических запросов; лингвистически мощный репрезентативный корпус; диахронически ориентированный корпус, покрывающий различные периоды истории современного казахского языка; диверсифицированный корпус, включающий разножанровые письменные и устные тексты разных типов; максимально сбалансированный корпус; наличие электронной библиотеки, включающей более 100 классических произведений казахской литературы.