Причины самоподобия телетрафика и методы оценки показателя Херста
УДК 621.396.67
Причины самоподобия телетрафика и методы оценки
показателя Херста
О.И. Шелухин
Рассмотрены причины возникновения самоподобия телекоммуникационного трафика; проанализированы методы оценки показателя самоподобия трафика.
Telecommunication traffic self-similarity origins are considered; Hurst exponent evaluation techniques are analyzed.
Введение
Современные исследования показывают, что
причиной самоподобия телекоммуникационного
трафика является объединение множества отдельных (хотя и сильно изменчивых) ON/OFFисточников, т.е. ON- и OFF-периоды описываются
распределениями с «тяжелыми хвостами» (РТХ) и
бесконечными дисперсиями (например, распределениями Парето) [1 – 4]. Другими словами, наложение
множества ON/OFF-источников, проявляющих синдром бесконечной дисперсии, в результате дает самоподобный объединенный сетевой трафик, стремящийся к фрактальному броуновскому движению
(ФБД). Кроме того, исследование различных трафиковых источников показывает, что высокоизменчивое поведение ON/OFF – это свойство, присущее архитектуре клиент/сервер [4 – 6].
Сложность понимания причин, которые могут
привести к самоподобности в сетевом трафике,
объясняются тем, что не существует какого-то одного фактора, вызывающего самоподобность. Различные корреляции, присутствующие в самоподобном сетевом трафике, которые воздействуют на
разных временных масштабах, могут возникать по
разнообразным причинам, проявляя себя в характеристиках на конкретных временных масштабах.
Возникновение долговременной зависимости
Перечислим некоторые из основных факторов, которые могут продуцировать в сетевом трафике ДВЗ различных видов: поведение пользователя; генерация, структура и поиск данных; объединение трафика; средства управления сетью; механизмы управления, основанные на обратной
связи; развитие сети.
Поведение пользователя. Одним из важных
факторов, воздействующих на характер трафика (на
сессию/уровень вызовов, а также во время сессии)
является поведение пользователя (человека). Было
показано, например, что распределение пользовательских запросов (время обдумывания) и предпочтения для документов в Интернете (WWW –
World Wide Web) обладает чрезвычайной степенью флюктуаций в широком диапазоне временных
масштабов [5]. Кроме того, существуют различные
механизмы управления потоками для различных
источников трафика, например, VBR-видео (Variable Bite Rate), MPEG-кодированные источники
(Motion Pictures Experts Group), ABR (Available
BitRate), TCP, которые регулируют интенсивность
выходного трафика в зависимости от состояния
сети, что также усиливает пульсирующую структуру сетевого трафика [6].
Генерация, структура и поиск данных. Появление трафика с самоподобной структурой тесно
связано со способом возникновения данных. Проведенные измерения показывают, что самоподобность в сетевом трафике, а также в трафике на
уровне приложений, является двухмерным свойством, которое относится частично к распределениям
времен
между
поступлениями
файла/пакета/ячейки и частично к распределениям
размеров файла/пакета. Эти результаты говорят о
том, что для трафика на уровне приложений, самоподобность может не быть состоянием, которое
вводится искусственным образом (механически).
Различные приложения/источники могут снабжать
трафик на самом верхнем уровне статистически
различными характеристиками, но основное статистическое поведение (например, корреляционная структура), как правило, инвариантно от одной машины/сети к другой. Например, показано,
что распределение размеров информационных
объектов, обычно передаваемых на уровне приложений (принцип клиент/сервер), лучше описывается распределением с тяжелыми хвостами.
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.
5
О. И. Шелухин
Объединение трафика. Одним из самых серьезных препятствий, которое не допускает сохранения
трафика, сгенерированного отдельными источниками в изолированном состоянии друг от друга (по
крайней мере источников в сети, удаленных насколько это возможно), является объединение трафика
(статистического мультиплексирования), используемого в сетях с коммутацией пакетов или ячеек. Как
указано выше, наложение множества ON/OFFисточников, проявляющих синдром бесконечной
дисперсии, приводит к объединенному самоподобному сетевому трафику, который стремится к ФБД.
Характеристики персистентности в трафике также
оказываются крайне устойчивыми к операциям сети,
таким как разделение, объединение, построение очередей, организация управления и формирование [7].
Самоподобность сохраняется при наложении однородных и разнородных (т.е. независимых) источников трафика, и это свойство присутствует в широком
диапазоне таких условий, как в случаях изменений
предельной пропускной способности и емкости буфера, так и при смешивании с перекрестным трафиком, обладающим другими (корреляционными) характеристиками [8, 9]. Если конкретный источник
генерирует ДВЗ-трафик, то и объединенный сетевой
трафик становится ДВЗ, независимо от характеристик (КВЗ или ДВЗ) других трафиков в смеси. Процесс объединения очень сложен, и весь диапазон
свойств при смешивании должен измениться, т.е.
кроме показателя Херста также должны существенно
измениться среднее значение и дисперсия [10, 11].
Средства управления сетью. Одной из главных причин, лежащих в основе ДВЗ, предположительно является ограниченность ресурсов, которая
присутствует в реальных сетевых окружениях, например, ограниченность сетевых и коммутирующих
ресурсов, таких как пропускная способность, незначительный размер буфера, лимитированные возможности обработки данных.
При использовании механизмов управления
могут возникать нелинейные зависимости, так как
из-за ограниченности ресурсов различные конфликтные ситуации не могут разрешаться простыми
способами. Эта проблема может проявляться в разных формах: от простых моделей построения очередей до очень сложных механизмов управления.
Подобные проблемы обсуждаются в [9], где показано, что в случае использования механизмов управления потоками типа TCP степень, с которой размеры файлов (WWW-документы) описываются распределениями с тяжелыми хвостами (ПРВ Парето с
параметром формы α), может напрямую определять
степень самоподобности H трафика.
6
В случае когда используются механизмы без
управления потоками, такие как UDP, возникающий
сетевой трафик в меньшей степени проявляет фрактальные свойства. Другими словами, ДВЗ в сетевом
трафике может возникать из-за передаваемых по сети РТХ-файлов и ограниченной (канальной) пропускной способности. Проблема управления ДВЗтрафиком может дополнительно усложниться в обстановке «борьбы» большого количества пользователей за ограниченные ресурсы. В результате проблема корректного распределения ресурсов приобретает первостепенную важность. Она еще более
усложняется из-за многомерной структуры, например, в результате конкуренции за пользование аппаратным обеспечением: CPU (Central Processing
Unit), память, пропускную способность, программные средства (стратегии планировщика OS, приоритеты процессов) и др.
Механизмы управления, основанные на обратной связи. Дальнейшее усложнение возникает
из-за большого количества механизмов управления,
которые основаны на обратной связи, например,
механизмов управления потоком и перегрузкой
(TCP, механизмы управления, основанные на интенсивности и т.д.). Это означает, что в случае перегрузки может проявляться дополнительная нелинейность, вызванная широким диапазоном динамического поведения системы. Важно отметить, что в
подобных ситуациях могут возникать очень сложные взаимосвязи между флюктуациями рабочей нагрузки и различными (сетевыми) механизмами
управления.
В результате возникают два класса специфических проблем: влияние реального трафика на эффективность конкретных механизмов управления
трафиком и степень изменения характеристик трафика посредством механизмов управления.
Развитие сети. Важная причина возрастания
пульсирующей структуры сетевого трафика – развитие сети, которое неизбежно с непрерывным появлением новых сервисов и приложений. Примером
может служить приход WWW-сервисов, повлекших
за собой усложнение структуры трафика [12].
При количественной оценке характеристики
канального уровня (например, Ethernet) определяют параметры сетевого трафика в миллисекундных масштабах [13]. Поведение человека влияет
на генерацию данных и поиск, что определяют характер трафика на интервалах в десятки секунд и
выше (минуты и даже часы) [14]. На промежуточных интервалах (на секундных временных масштабах), вероятно, будут преобладать процессы
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.
Причины самоподобия телетрафика и методы оценки показателя Херста
влияния различных механизмов управления потоками, таких как TCP. Характеристики построения
очередей могут доминировать на десятках и сотнях миллисекунд [10].
Проблемы оценки показателя Херста. На
практике при использовании измеренных наборов
данных оцененные значения H, получаемые при
использовании различных методик анализа, находятся под влиянием многих факторов и могут зависеть от методики оценки, размера выборки, масштабов времени, структуры данных и т.п [15, 16].
Обсудим эти факторы и то, как они затрагивают вычисление показателя самоподобности, а также оценим устойчивость H к этим воздействиям.
Проблемы тестирования. Известны различные статистические методы тестирования и оценки
степени самоподобности случайных процессов [18].
Популярны и широко используются на практике так
называемые «визуальные тесты». Однако они не надежны для опытных данных при небольших размерах выборки.
Широко применяется R/S-анализ, основанный на
эвристическом графическом подходе. С точки зрения
эффективности, R/S-анализ зависит от размера выборки. В случае, когда требуется более «тонкий» анализ
данных, отсутствие каких-либо результатов для предельных закономерностей статистических характеристик делает перечисленные тесты непригодными. Более «тонкий» анализ данных возможен с использованием периодограммных тестов в частотной области.
Некоторые периодограммные оценки, такие как оценки максимального правдоподобия и связанные с ними
методы, могут быть найдены в литературе. В частности, для гауссовских процессов широко исследована
оценка Виттла [18]. Используя эти подходы, можно
получить больше информации относительно оценок
H, например, доверительные интервалы.
На практике, когда требуемые предварительные
условия для проведения статистических тестов выполнены не полностью, различные методы могут давать слегка различающиеся оценки H. Так, использование индекса дисперсии для отсчетов (IDC), наряду с простотой и эффективностью, требует небольшой вычислительной мощности и наглядно показывает изменения при вариации анализируемого
набора данных.
Преимущества и недостатки существующих методов оценки показателя Херста. Преимущества и недостатки некоторых, наиболее распространенных методов оценки показателя самоподобия, подытожены в таблице.
Таблица. Эффективность методов оценки
Метод
Преимущества
Изменения
дисперсии
Может быть использован как диагностический тест
R/Sстатистика
Не зависит от маргинального распределения данных
Периодограммный
Устойчивая оценка
Метод
Виттла
Точные оценки получаются, если порядок модели известен
априорно.
Оценки имеют приемлемую точность
для небольших наборов данных
Недостатки
Оценки
смещены.
Смещение возрастает
с ростом показателя
самоподобия
Оценки
смещены.
Присутствие медленно
изменяющегося
тренда влияет на эффективность
Необходим большой
объем данных. Сходимость
дисперсии
( )
~ O U −1
Получаются смещенные оценки, если
данные не соответствуют заданной модели
Недостатком метода изменения дисперсии
является то, что для него требуется большой объем выборки, а значение уровня агрегирования
произвольно.
При использовании R/S-статистики наименьшие значения d не следует учитывать, так как в
этих точках преобладает кратковременная зависимость ряда. Напомним, что d:= ⎣n/K⎦, где n – длина
эмпирического ряда; K – число блоков разбиения.
Также не используются и верхние значения
графика, поскольку всего несколько значений в
этой области могут сделать оценку неустойчивой.
Оценки Виттла являются асимптотически
эффективными, однако требуют знания параметров модели спектральной плотности исследуемого
времеменного ряда. Данный метод более вычислительно требовательный..
Периодограмма является более устойчивой,
но асимптотическая сходимость дисперсии оценок
очень медленная.
Все методы оценки показали себя сравнительно устойчивыми.
Проблема нестационарности. Исследования
обнаружили, что оценка показателя Херста может
зависеть от многих характеристик и требуется, чтобы при его оценке удовлетворялось предположение
стационарности [17, 18].
Наиболее простой способ проверки стационарности случайных процессов заключается в
оценке их статистических характеристик. Если основные статистические характеристики, опреде-
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.
7
О. И. Шелухин
ляющие процесс x(t) – плотность распределения вероятностей (ПРВ) w(x), математическое ожидание
m, дисперсия σ 2 – не зависят от времени, то можно
полагать процесс стационарным в широком смысле. На практике такие простые соображения, позволяющие проверить справедливость гипотезы о стационарности, обычно не выполняются, поскольку
наблюдению доступны реализации конечной длительности. В подобных случаях гипотеза о стационарности должна быть проверена путем анализа
имеющихся реализаций конечной длительности.
Способы проверки могут быть различными – от визуального просмотра реализаций опытным специалистом до детального статистического оценивания
различных параметров процесса. Длина реализации
должна быть настолько большой, чтобы можно было разделить нестационарный тренд и низкочастотные случайные колебания.
Окончательная проверка реализаций на наличие трендов может быть выполнена различными
способами.
Особую проблему представляет тестирование
случайных процессов на самоподобность. Проблема заключается в конечном наборе данных, когда невозможно проверить, является трасса трафика самоподобной по определению или нет. Поэтому в реальном измеренном трафике исследуются
различные свойства самоподобности и долговременной зависимости. Однако установление самоподобности только путем обнаружения ее свойств
может быть ошибочным.
К подобным свойствам могут приводить некоторые нестационарные процессы. Это означает,
что, например, пульсирующий трафик может быть
вызван как долговременной зависимостью, так и
нестационарностью наблюдаемого процесса. Без
какого-либо обоснования, при помощи строгих статистических тестов на стационарность, во многих
случаях можно корректно говорить только о пульсирующей структуре трафика на заданном масштабе времени для определенного набора данных.
Наибольшее распространение при оценке
стационарности самоподобных процессов получил
метод с использованием коэффициента стационарности (WSS). Однако, как отмечается в работе
[19], его использование в ряде случаев дает неверные результаты.
Если известно выборочное распределение
оценок основных статистических параметров распределения, то можно использовать для решения
данной задачи критерий серий или критерий инверсий [20].
8
Коэффициент стационарности в широком
смысле. Известно, что для стационарных в широком смысле процессов их среднее значение m и
дисперсия σ 2 неизменны на всей области существования. Однако в действительности проверка этого положения на конечной выборке (например, видео данные) затруднена. Поэтому статистические
характеристики, такие как выборочные среднее
значение и дисперсия, обычно определяются в виде
M (X ) =
1
H
H
∑x
k
,
k =1
H
2
1
D( X ) =
xk − M ( X ) ) .
(
H − 1 k =1
∑
Рассмотрим набор данных
{ xk , k = 1, 2,..., H } ,
разделенных на S независимых сегментов, каждый из которых имеет длину N , так, что H=NS.
Если выборочное среднее значение каждого сегмента обозначить как mˆ i , а дисперсию как
σˆ i2 , i = 1, 2, L , S , то можно проверить равенство
средних значений и дисперсий между любыми
двумя блоками i и j .
Статистический тест на равенство средних
значений, называемый также Т-тестом, имеет вид
1
⎛ N −1 ⎞2
⎟ ,
(1)
T = mˆ i − mˆ j ⎜ 2
⎜ σˆ i + σˆ 2j ⎟
⎝
⎠
где Т имеет t-распределение Стьюдента с υ = 2N – 2
степенями свободы.
Статистический тест на равенство дисперсий
называется F-тестом и записывается так:
σˆ 2
F = i2 ,
(2)
σˆ j
(
)
где F имеет F -распределение с υ1 =N –1 и υ2 =N –1
степенями свободы.
Введем в рассмотрение индикаторную функцию
⎧⎪1, если T ≤ tυ ,α и F υ1 ,υ2 ,1− α ≤ F ≤ F υ1 ,υ2 , α ,
2
2
2
pij = ⎨
(3)
⎪⎩0, если иначе,
где T и F – тесты, которые выполняются на блоках
i и j; tυ , α – процентные точки ДФР для t-рас2
пределения; Fυ ,υ
α
1 2 ,1− 2
и Fυ ,υ
α
1 2, 2
– процентные точки
ДФР для F-распределения.
Тогда коэффициент стационарности в широком смысле (Wide Sense Stationary -WSS) [21] может быть определен как
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.
Причины самоподобия телетрафика и методы оценки показателя Херста
WN =
2
S N ( S N − 1)
S N −1 S N
∑∑
pij .
(4)
i =1 j =i +1
Если общее число сегментов в наборе данных
– D , то
D
SN = .
(5)
N
В результате, например, для теста равенств
средних значений (1) и теста равенств дисперсий
(2) можно выбрать доверительный интервал 95%.
Таким образом, даже для стационарных данных
можно ожидать 5% ошибок тестов для среднего
значения (дисперсии). Так как эти тесты независимы, в худшем случае 10% из всех тестов на стационарность будут ошибочными для стационарных данных, поэтому можно ожидать, что коэффициент WN для стационарных данных будет как
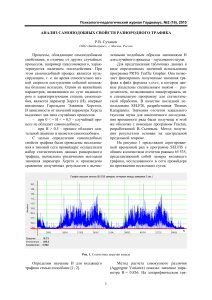
минимум равен 0,9. Пример использования критерия WSS для случая ФГШ с различными показателями Херста Н показан на рис. 1.
Рис. 1. Зависимость коэффициента нестационарности WSS от
размера блока усреднения для ФГШ при различных показателях Херста Н
Видно, что, хотя все анализируемые последовательности априорно являлись стационарными и
отличались только показателем Херста Н, лишь в
случае Н = 0,5 метод WSS дает верные результаты.
В этом случае значение WSS колеблется вблизи 1.
Случай Н = 0,5 соответствует случаю гауссовской
последовательности с независимыми значениями.
При Н > 0,5 значение WSS не превышает 0,4, что
свидетельствует о нестационарности исследуемой
последовательности. Очевидно, это вызвано долговременной зависимостью исследуемой последовательности.
Таким образом, метод WSS при анализе стационарности самоподобных процессов может давать неверные результаты.
Исследования, проведенные в [23], показывают, что коэффициент WN может определить различие между независимыми и одинаково распределенными данными с КВЗ или ДВЗ, однако с помощью него нельзя уловить различие между нестационарными и самоподобными данными.
Критерии серий и инверсий. Рассмотрим другую последовательность действий для проверки
стационарности случайного процесса по отдельной его реализации { xk , k = 1, 2,.., H } .
1. Реализации разделяется на N равных интервалов, причем наблюдения в различных интервалах полагаются независимыми.
2. Вычисляются оценки среднего квадрата
(или отдельно средних значений и дисперсий) для
каждого интервала, и эти оценки располагаются в
порядке возрастания номера интервала: x12 , x22 ,
x32 ,…, xN2 .
3. Эта последовательность оценок среднего
квадрата проверяется на наличие тренда или других изменений во времени, которые не могут быть
объяснены только выборочной изменчивостью
оценок.
Окончательная проверка реализаций на наличие трендов может быть выполнена различными
способами. Если известно выборочное распределение оценок, то можно воспользоваться статистическими критериями. Однако знание выборочного распределения оценок среднего квадрата требует знания частотной структуры процесса. Обычно при проверке стационарности эти сведения отсутствуют. Поэтому более желательно применение
непараметрических критериев, при использовании
которых не требуется знать выборочные распределения оценок. Два таких непараметрических критерия, которыми можно воспользоваться для решения данной задачи, − это критерий серий и критерий инверсий. Последний представляет собой
более мощное средство для обнаружения монотонных трендов в данных наблюдений. Критерий
инверсий может быть непосредственно использован для проверки гипотезы о стационарности.
Рассмотрим последовательность из N наблюдений значений случайной величины x, причем
каждое наблюдение отнесено к одному из двух
взаимно исключающих классов, которые можно
обозначить как (+) или (−). Ниже в виде последовательности плюсов или минусов приведена последовательность одновременных измерений двух
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.
9
О. И. Шелухин
случайных величин xi и yi (i = 1,2, …, N). Если xi ≥
yi то это соответствует (+), если xi < yi – то (−).
Число серий, появившихся в последовательности наблюдений, позволяет выяснить, являются
ли отдельные результаты независимыми наблюдениями одной и той же случайной величины. Если
последовательность N наблюдений состоит из независимых исходов одной и той же случайной величины, т.е. если вероятность отдельных исходов
((+) или (−)) не меняется от наблюдения к наблюдению, то выборочное распределение числа серий
в последовательности является случайной величиной r со средним значением μr и дисперсией σ r 2 :
2N N
μ r = 1 2 + 1,
(6)
N
2N N ( 2N N − N )
(7)
σ r2 = 1 2 2 1 2
.
N ( N − 1)
Здесь N1 и N2, − число исходов (+) и (−) соответственно.
В частном случае N1 = N2 = N/2 выражение (6)
принимает вид
N
μr = + 1.
2
В [20] приводятся 100α-процентные точки
функции распределения числа серий, по которым
можно с заданной достоверностью оценить стационарность анализируемых последовательностей.
С этой целью для проверки гипотезы с любым
требуемым уровнем значимости α надо сравнить
наблюдаемое число серий с границами области
принятия гипотезы, равными rn;1−α/2 и rn;α/2, где N =
N/2. Если это число серий окажется вне данной области, то гипотеза отвергается с уровнем значимости α. В противном случае гипотеза принимается.
Результаты использования критерия серий
для анализа ФГШ с различными значениями показателя Херста Н иллюстрируются на рис.2. Видно,
что в отличие от критерия WSS метод серий правильно идентифицирует стационарность самоподобного процесса.
Рассмотрим последовательность {xk,k = 1, 2,
…, N}. Подсчитаем, сколько раз в последовательности имеют место неравенства xi > xj при i < j.
Каждое такое неравенство называется инверсией.
Обозначим через А общее число инверсий. Формально А вычисляется следующим образом. Опре-
10
делим для множества наблюдений x1, x2, …, xN величины hij:
⎪⎧1, xi > x j ,
hij = ⎨
⎪⎩0, xi ≤ x j .
N −1
Тогда
A=
∑
N
Ai ,
Ai =
N
A1 =
∑
j =2
N
h1 j , A2 =
∑
j =3
∑h
ij
например:
j =i +1
i =1
N
h2 j , A3 =
∑h
3 j ,... .
j =4
Если последовательность из N наблюдений
состоит из независимых исходов одной и той же
случайной величины, то число инверсий является
случайной величиной A со средним значением μ А
и дисперсией σ А2 :
N ( N − 1)
,
μA =
(8)
4
2 N 3 + 3 N 2 − 5 N N ( 2 N + 5 )( N − 1)
σ A2 =
=
. (9)
72
72
В [20] приводятся 100α-процентные точки
функции распределения для А.
Критерий инверсий является более мощным
по сравнению с критерием серий при обнаружении
монотонного тренда в последовательности наблюдений. Однако он не столь эффективен при выявлении тренда типа флюктуаций. Результаты применения критерия инверсий для случая ФГШ с различными показателями Херста показаны на рис. 3.
Из представленных результатов видно, что
метод инверсий правильно идентифицирует стационарность тестовой самоподобной последовательности в виде ФГШ с различными значениями
показателя Херста H.
Могут быть предложены и другие тесты по
оценке стационарности, но все они не могут объективно показать, являются ли, например, видеоданные стационарными или самоподобными, однако, подтверждают, что самоподобные модели
могут быть использованы для генерирования данных, которые ведут себя подобно VBRвидеотрафику.
Вычислительные проблемы
Известно, что оценка показателя Херста для
идеального самоподобного процесса будет постоянной величиной независимо от того, как много
данных рассматривается. На практике, используя
наборы данных, измеренные при различных методах анализа, находят оценки показателя Херста
H , которые зависят от методики оценки, от раз-
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.
Причины самоподобия телетрафика и методы оценки показателя Херста
Оценка дисперсий Н = 0,5
Оценка дисперсий Н = 0,7
Оценка дисперсий Н = 0,9
Оценка средних Н = 0,5
Оценка средних Н = 0,7
Оценка средних Н = 0,9
Рис. 2. Результаты использования критерия серий для анализа ФГШ с различными значениями показателя Херста Н
мера выборки, от масштабов времени и от структуры данных.
В реальности показатель Херста существенно
изменяется во времени. Рассмотрим эту проблему
на примере трафика VoIP, полученного путем
мультиплексирования 100 речевых потоков, создаваемых абонентами в системе VoIP с включенным механизмом обнаружения активности речи
VAD (рис. 4).
Представленные данные характеризовались
временным разрешением 1с и охватывали более
трех часов работы системы VoIP. Показатель Хер-
ста вычислялся с использованием графика нормированного размаха и графика изменения дисперсии, а также с применением оценки на основе
свойств графика ковариационной функции. Динамика значений показателя Херста для рассматриваемого трафика приведена на рис. 5.
Оценка Н проводилась для «окна» заданной
длины, после чего окно смещалось и оценка выполнялась снова. В результате вычислений было
отмечено, что показатель Херста существенно изменялся во времени, несмотря на предполагаемую
схожесть обстановки.
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.
11
О. И. Шелухин
Оценка дисперсий Н = 0,5
Оценка дисперсий Н = 0,7
Оценка дисперсий Н = 0,9
Оценка средних Н = 0,5
Оценка средних Н = 0,7
Оценка средних Н = 0,9
Рис. 3. Инверсия средних и дисперсий для ФГШ для различных значений H и α = 0,05
Зависимость показателя Херста от N.
Оценивая показатель Херста для блоков данных D,
можно исследовать его корреляционную структуру.
Рассмотрим K сегментов ряда, каждый длиной N.
Показатель Херста H может быть оценен в каждом
сегменте Si , i = 1, 2, K ND с использованием, например, R/S-анализа. Если оценки, проводимые в
i-м блоке, обозначены как Hˆ i , то для соответст-
12
вующего N оценку показателя Херста можно найти в виде
N
Hˆ N =
D
D N
∑ Hˆ ,
i
(10)
i =1
Исследования показывают, что если выбрать
N достаточно большим, то можно обеспечить приемлемую сходимость оценки так, чтобы для стационарного процесса оценка Hˆ N не зависела от N.
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.
Причины самоподобия телетрафика и методы оценки показателя Херста
H
log-log КФ
R/S-статистика
Изменение
дисперсии
n
Рис. 4. Мультиплексированный трафик для 100 речевых
источников
Рис. 5. График изменения показателя Херста для скользящего
окна при различных методиках тестирования
В результате мера Hˆ N может отличить данные с
КВЗ от данных с ДВЗ.
015, Computer Science Department, Boston University,
1995.
7. Erramilli A., Willinger W., Wang J.L., Modeling and
Management of Self-Similar Traffic Flows in HighSpeed Networks, Network Systems Design, Gordon and
Breach Science Publishers, 1999.
8. Erramilli A., Narayan O., Willinger W., Experimental
queueing analysis with long-range dependent packet
traffic, IEEE/ACM Transactions on Networking,
4:209-223, 1996.
9. Li G. L., Dowd W.D., An Analysis of Network Performance Degradation Induced by Workload Fluctuations,
IEEЕЕ/АСМ Transactions on Networking, Vol.3, No.4,
August 1995.
10. Erramilli A., Willinger W., Wang J.L., Modeling and
Management of Self-Similar Traffic Flows in HighSpeed Networks, Network Systems Design, Gordon and
Breach Science Publishers, 1999.
11. Park К., Kim G.T., Crovella M.E., On the Relationship
Between File Sizes, Transport Protocols, and SelfSimilar Network Traffic, preprint, Boston University,
1996.
12. Popescu A., Traffic self-similarity, in Proc. of IEEE Intl.
Conf. on Telecommunications (ICT2001).
13. Leland W. E., Taqqu M. S., Willinger W., Wilson D. V.,
On the self-similar nature of Ethernet traffic (Extended
version), IEEE/ACM Transactions on Networking,
2:1-15, 1994.
14. Jena A.K., Pruthi P., Popescu A., Modeling and Evaluation of Network Applications and Services, Proceedings
of the RVK'99 Conference, Ronneby, Sweden, June
1999.
15. Molnar S., Vidacs A., Nilsson A., Bottlenecks on the
way towards fractal characterization of network traffic:
Estimation and interpretation of the Hurst parameter,
In International Conference of the Performance and
Management of Complex Communication Networks
(PMCCN'97), Tsukuba, Japan, November 1997.
16. Molnar S., Vidacs A., How to characterize Hursty traffic?
In COST 257 TD(98)003, Rome, Italy, January 1998.
Таким образом, проведенные исследования показали что основной причиной самоподобия тедекоммуникационного трафика является объединение
множества отдельных, хотя и сильно изменчивых
ON/OFF - источников.
Одной из главных причин, лежащих в основе
ДВЗ, является ограниченность ресурсов, которая
присутствует в реальных сетевых окружениях.
Метод серий правильно идентифицирует стационарность тестовой самоподобной последовательности в виде ФГШ с различными значениями показателя Херста H.
ЛИТЕРАТУРА
1. Beran J., Sherman R., Taqqu M. S., Willinger W., Longrange dependence in variable-bit-rate video traffic,
IEEE Transactions on Communications, 43:1566-1579,
1995.
2. Leland W. E.,. Taqqu M. S, Willinger W., Wilson D. V,
On the self-similar nature of Ethernet traffic (Extended
version), IEEE/ACM Transactions on Networking,
2:1-15, 1994.
3. Paxson V., Floyd S., Wide area traffic: The failure of
poisson modelling, IEEE/ACM Transactions on Networking, 3:226-244, 1995.
4. Arlitt M.F., Williamson C.L., Web Server Workload
Characterization: The Search for Invariants (Extended
Version), EEEE/ACM Transactions on Networking,
Vol. 5, No. 5, October 1997.
5. . Jena A.K, Pruthi P., Popescu A., Resource Engineering for Internet Applications, Proceedings of the 7th
IFIP ATM Workshop, Antwerp, Belgium, June 1999.
6. Crovella M.E., Bestavros A., Explaining World Wide
Web Traffic Self-Similarity, Technical Report: TR-95-
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.
13
О. И. Шелухин
17. Molnar S., Vidacs A., Fractal characterization of network traffic from parameter estimation to application,
Ph.D. dissertation, Budapest university of technology
and economics dept. of telecommunications and
telematics, Budapest, Hungary, 2000.
18. Bates S., Traffic Characterization and Modelling for
Call Admission Control Schemes on Asynchronous
Transfer Mode Networks, A thesis submitted for the degree of Doctor of Philosophy. The University of Edinburgh. 1997.
19. Shiavi R., Introduction to Applied Statistical Signal
Analysis, Aksen Associates, 1991.
20. Bendat J., Piersol A., Random Data: Analysis and Measurement Procedures, John Wiley & Sons, 1986.
21. Adas A., Traffic Models in Broadband Networks, IEEE
Communications Magazine, July 1997.
14
22. Crovella М. Е., Bestavros A., Self-similarity in world
wide web traffic: evidence and possible causes, In Proceedings of the 1996 ACM SIGMET-RICS. International Conference on Measurement and Modeling of
Computer Systems, May 1996.
23. Шелухин О.И., Осин А.В., Невструев И.А., Урьев
Г.А. Сравнительный анализ методов оценки стационарности самоподобных процессов. – Электротехнические комплексы и информационные системы,
2006. т.2, №1, с.55-60.
Поступила 22. 09. 2006 г.
Электротехнические и информационные комплексы и системы № 1, т. 3, 2007 г.