ЗАДАНИЕ: Решение задачи классификации методом kNN
реклама

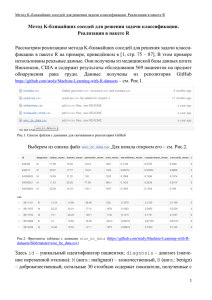
ЗАДАНИЕ: Решение задачи классификации методом kNN Выполнила Мустафина Элина, гр. 09-505 Была рассмотрена реализация метода K-ближайших соседей для решения задачи классификации в пакете R. Набор данных содержит случаи из исследования, проведенного между 1958 и 1970 годами в больнице Чикаго, на выживание пациентов, которые подверглись операции на грудь (у пациенток был рак). Данные получены из репозитория UCI. http://archive.ics.uci.edu/ml/datasets/Haberman%27s+Survival Здесь age – возраст пациентки в момент проведения операции, year – год, когда была сделана операция (с 1958 по 1970), nodes - Number of positive axillary nodes detected, т.е. это – количество обнаруженных подмышечных узлов в груди, class – значение переменной отклика, 1 – пациентка прожила 5 лет и более, 2 – пациентка скончалась в течение 5 лет. Цель исследования – предложить врачам инструментарий, позволяющий по данным обследования пациентки (значениям показателей в столбцах с номерами 1 – 3) спрогнозировать продолжительность жизни пациенток, перенесших операцию. Таким образом, мы имеем задачу бинарной классификации, поскольку классов всего 2 («1» и «2»). Прочтем данные в переменную mydata: mydata <- read.csv("haberman1.txt", stringsAsFactors = FALSE) Подсчитаем количество обоих исходов: table(mydata$class) Перекодируем значения переменной отклика (class), выделив 2 уровня («1» и «2») и заменив эти значения на «Survived» и «Died», соответственно: mydata$class<- factor(mydata$class, levels = c("1", "2"), labels = c("Survived", "Died")) Подсчитаем проценты каждого из исходов, округлив результаты до десятых: round(prop.table(table(mydata$class))*100, digits = 1) К сожалению, у нас нет данных, «непомеченных» цифрами «1» и «2» (а есть только данные, для которых уже известен исход). Поэтому для тестирования метода kNN разобьём выборку на 2 части – одну из них будем использовать как обучающую, а другую будем использовать для прогноза значения переменной отклика. Потом мы сможем сравнить полученные результаты с истинным значением переменной отклика. Пусть в обучающую выборку войдут первые 157 записей (берем столбцы с 1го по 3-ий): data_train <- mydata[1:157,1:3 ] В тестовую группу войдут остальные записи, т.е. те от 158 до 305 (столбцы 13): data_test<- mydata[158:305,1:3 ] Значение переменной отклика из обучающей выборки: data_train_labels <- mydata[1:157, 4] Значение переменной отклика для тестовой выборки (это нужно для того чтобы проверить точность метода KNN): data_test_labels <- mydata[158:305, 4] Данные для анализа готовы. Теперь нам нужна функция knn(). Она находится в пакете class, который необходимо подключить. install.packages("class") Вызываем функцию library: library("class") Вызовем функцию knn(): data_test_pred <- knn(train = data_train, test = data_test,cl = data_train_labels, k=12) Насколько точен прогноз, сделанный методом kNN, можно проверить с помощью функция CrossTable из пакета gmodels: install.packages("gmodels") – установили пакет library("gmodels") – вызвали функцию library CrossTable(x = data_test_labels, y = data_test_pred, prop.chisq=FALSE) Проанализируем точность полученных решений: (Survived, Survived) - содержит прогнозы, т.е. те случаи, когда пациентка относится к классу Survived (т.е. проживших после операции 5 и более лет), и метод KNN правильно решил. (Survived, Died) – количество пациенток, которых KNN метод ошибочно отнес к умершим в течение 5 лет. Всего в тестовой выборке пациенток, относящихся к классу Survived, было 118. Метод KNN в 12 случаях ошибся. Иными словами, метод KNN определил 12 пациенток как умерших в течение 5 лет (т.е. отнес их к классу «Died»), хотя, на самом деле, пациентки прожили 5 и более лет. (Died, Survived) – количество пациенток, которых KNN метод отнес к прожившим 5 и более лет ошибочно, т.е. на самом деле пациентки скончались в течение 5 лет. (Died, Died) – содержит количество пациенток, которых KNN метод верно отнес к классу «Died», т.е. эти пациентки действительно скончались в течение 5 лет после проведения операции. Таким образом, общее число ошибок метода kNN равно 27 , что составляет 18% от общего числа прогнозов. Теперь зададим нескольких новых данных и определим, к какому классу они относятся. Пусть у нас есть текстовый файл, в котором хранятся данные о 10 пациентках: test <- read.csv("new.txt", stringsAsFactors = FALSE) data_test_pred <- knn(train = data_train, test ,cl =data_train_labels, k=12) Мы видим, что KNN метод 3 из 10 пациенток отнес к классу «Died» (Выделены желтым). Это пациентки с самым большим количеством подмышечных узлов, так же важен возраст (например, пациентка 3 как и пациентка 4 имеет 16 подмышечных узлов, но ее возраст значительно меньше). Таким образом, можем сказать, что KNN метод классифицировал новых пациенток корректно. К сожалению, визуализировать данные мы не сможем, так как число признаков = 3.