Карпенко М.Н.
реклама

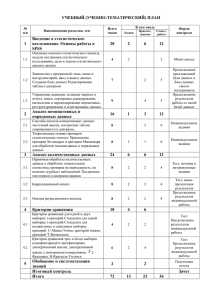
НАИБОЛЕЕ РАСПРОСТРАНЕННЫЕ ОШИБКИ СТАТИСТИЧЕСКОГО АНАЛИЗА ДАННЫХ В КВАЛИФИКАЦИОННЫХ РАБОТАХ БИОЛОГИЧЕСКОГО ПРОФИЛЯ Карпенко М.Н. 2013г. «Как блестящие идеи, так и научные нелепости одинаковым образом можно облечь во впечатляющий мундир формул и теорем». В.В. Налимов Большинство ошибок возникает при использовании простейших статистических методов! Специфика научного исследования заключается в том, что использование автором неадекватного метода даже на одном из этапов работы лишает его выводы достоверности. Выход: соблюдать несколько простейших правил! George S.L. Statistics in medical journals: a survey of current policies and proposal for editors. Med Pediat Oncol. 1985;13:109— 12. Lang T., Secic M. How to report statistics in medicine: annotated guideline for authors, editors, and reviewers. Philadelphia (PA): American Colleje of Physicians;1997. ОШИБКИ СТАТИСТИЧЕСКОГО АНАЛИЗА ДАННЫХ Ошибки в представлении данных Ошибки в описании результатов Ошибки в выборе статистического критерия ДАННЫЕ Количественные Качественные (их нельзя выстроить в последовательность) Дискретные Ранговые (качественные, но могут быть упорядочены; размер интервалов на шкале неодинаковый) Потеря информации и точности Непрерывные ШКАЛЫ ИЗМЕРЕНИЙ Шкала наименований Шкала отношений Шкала порядка Шкала интервалов Мощность шкалы ОШИБКА ПЕРВАЯ: ПОДМЕНА ТИПОВ ДАННЫХ - Замена количественных данных качественными; - Качественные данные анализируются как количественные. РАЗБИЕНИЕ ДАННЫХ НА ПОДГРУППЫ НА ОСНОВАНИИ МОДАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ мультимодальное унимодальное бимодальное обычно возникают, если популяция имеет естественные обособленные подгруппы ОСНОВНЫЕ ТИПЫ ЗАДАЧ, РЕШАЕМЫХ С ПОМОЩЬЮ МЕТОДА СТАТИСТИЧЕСКОЙ ГРУППИРОВКИ: Задачи Принцип группировки выделение типов явлений; типологический – по атрибутивным признакам; изучение структуры явления и структурных сдвигов, происходящих в явлении; структурный -разделение совокупности по какому-либо одному признаку ; выявление взаимосвязей и взаимозависимостей между явлениями и признаками, характеризующими эти явления. аналитический - характеризует взаимосвязь между признаками один из которых является факторным другой результативным. ОШИБКА ВТОРАЯ: ОКРУГЛЕНИЕ Количественные данные представляются с излишней точностью. ПРАВИЛО: числовое значение результата измерений представляется так, чтобы оно оканчивалось десятичным знаком того же разряда, какой имеет погрешность этого результата. Погрешности измерения погрешностью. сами определяются с некоторой «Погрешность погрешности» обычно такова, что в окончательном результате погрешность приводят с одной-двумя значащими цифрами. ОКРУГЛЕНИЕ: АЛГОРИТМ ДЕЙСТВИЙ 1. Задаем n и доверительную вероятность, например, α=0,95; проводим эксперимент; 2. Вычисляем среднее выборочное; 3. Вычисляем ошибку среднего; 4. Для заданных n и α находим tnα, 5. По паспорту прибора определяем инструментальную погрешность Δин. В паспорте, если не указано иное, приведена погрешность для α=0,997, поэтому при заданной α=0,95 Δин учитываем с коэффициентом 2/3. 6. Находим абсолютную погрешность по формуле: 7. Находим относительную погрешность по формуле: 8. Округляем абсолютную и относительную погрешность до двух значащих цифр (если первая из них меньше или равна 3) и до одной (если первая из них больше 3). 9. Округляем результат измерения. Число значащих цифр результата измерений должно быть ограничено поом величины абсолютной. 10. Записываем результат. ОШИБКА ТРЕТЬЯ: НЕПРАВИЛЬНОЕ ИСПОЛЬЗОВАНИЕ СТАТИСТИЧЕСКИХ ОЦЕНОК Средняя температура по больнице с учетом гнойного отделения и морга составила 36,60С. Качественный номинальный признак – мода; Ранговый признак – мода и медиана; Количественный признак – мода, медиана, среднее. СРЕДНЕЕ ИЛИ ВСЕ ЖЕ МЕДИАНА? Пример. Средняя зарплата: мода показывает какова зарплата «среднего» работника, а среднее – отражает среднюю зарплату на предприятии. Среднее выборочное вычисляется только для признаков, измеряемых в шкале отношений и исключительно для выборки, подчиняющейся нормальному закону распределения! ОШИБКА ЧЕТВЕРТАЯ: СТАНДАРТНАЯ ОШИБКА СРЕДНЕГО • Среднее – описывает центральную тенденцию; • СКО - вариабельность данных; • СОС – показатель точности оценки среднего. Пример: измеряем массу тела у N=100 мужчин, среднее м=72 кг, СКО=8кг, тогда СОС=0,8. Вывод 1: примерно в 68% случаев результат измерений будет лежать в диапазоне (64; 80)кг. Вывод 2: примерно в 68% случаев средняя масса тела составит (71,2;72,8)кг. ОШИБКА ПЯТАЯ: АНАЛИЗИРУЕМЫЕ ДАННЫЕ НЕ СООТВЕТСТВУЮТ УСЛОВИЯМ КРИТЕРИЯ • использование параметрических критериев для анализа данных, не подчиняющихся нормальному распределению; • использование критериев для независимых выборок при анализе парных данных. • использование t-критерия (критерия Манна-Уитни) для сравнения трех и более групп, а также для сравнения долей. ОБЩАЯ СХЕМА ПРОЦЕДУРЫ ПРОВЕРКИ ГИПОТЕЗЫ: 1. Формулируем Н0 и Н1. Строим распределения такие, как будто Н0 верна: • распределение исследуемой переменной; • распределение параметра выборки; • распределение статистики критерия. ЭТО ДЕЛАЕТ ЧЕЛОВЕК, А НЕ КОМПЬЮТЕР 2. Устанавливаем условия, при которых мы отвергнем Н0 – Определяем: • уровень значимости; • односторонний или двусторонний будет тест; • критическое значение статистики критерия. 3. Считаем параметр выборки и статистику критерия для реальной выборки, сравниваем их с критическими значениями. 4. Интерпретируем результаты: • Можем ли мы отвергнуть Н0? Т.е., достоверны ли результаты статистически? • Если да, достоверны ли они ПРАКТИЧЕСКИ? ВОЗМОЖНЫЕ ОШИБКИ Истинное (но неизвестное нам) положение дел Верна H0 Мы «приняли» H0 Мы отвергли H0 ПРАВИЛЬНО! (чувствительность критерия) ОШИБКА 1-го рода (уровень значимости) Верна H1 ОШИБКА 2-го рода ПРАВИЛЬНО! (мощность критерия) Заметим: ошибку 1-го рода можно сделать только отвергая Н0, а ошибку 2-го рода – только «принимая» Н0 (нельзя сделать одновременно обе ошибки). ДВУХВЫБОРОЧНЫЕ КРИТЕРИИ Различаются ли по массе тигры-самцы и тигры-самки в зоопарке? Сравниваем средние массы наших зверьков. Мы анализируем влияние пола на массу тигров. Зависимая переменная – масса. Независимая (группирующая) – пол (группы: 1. самцы; 2. самки) самец самка ДВУХВЫБОРОЧНЫЕ КРИТЕРИИ. КРИТЕРИЙ СТЬЮДЕНТА ДЛЯ НЕЗАВИСИМЫХ ВЫБОРОК Общий вопрос: получены ли выборки из одной популяции? Частный вопрос: равны ли средние значения между собой? H 0 : 1 2 H1 : 1 2 1. Размеры выборок могут отличаться 2. Выборки должны иметь нормальное распределение и их дисперсии должны быть равны. 3. Критерий может быть односторонним и двусторонним ДВУХВЫБОРОЧНЫЕ КРИТЕРИИ Статистика = H 0 : 1 2 H1 : 1 2 параметр выборки – параметр популяции стандартная ошибка параметра выборки H 0 : 1 2 0 разность выборочных средних ( X 1 X 2 ) ( 1 2 ) X 1 X 2 t s X1 X 2 s X1 X 2 df n1 n2 2 ошибка Ошибка считается из средних квадратов стандартных отклонений в выборках Основное распределение - t-распределение (Стьюдента) * Это статистика для двустороннего критерия ДВУХВЫБОРОЧНЫЕ КРИТЕРИИ. ПРОВЕРКА ГИПОТЕЗЫ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ Соответствует ли распределение мотыльков на дереве НОРМАЛЬНОМУ РАСПРЕДЕЛЕНИЮ? Переменная – высота от земли в метрах Тест Колмогорова-Смирнова (Kolmogorov-Smirnov test) (если известны дисперсия и среднее в популяции) Dстатистика. Lilliefors test – если НЕизвестны дисперсия и среднее в популяции – «улучшенный К-С тест» Shapiro-Wilk’s W test (самый мощный, размер выборки до 5000) – наиболее предпочтительный. ДВУХВЫБОРОЧНЫЕ КРИТЕРИИ. КРИТЕРИЙ СТЪЮДЕНТА ДЛЯ СВЯЗАННЫХ ВЫБОРОК К тиграм-самцам пришёл новый служитель, и возможно, они стали по-другому питаться. Мы хотим узнать, не изменилась ли их масса. Мы анализируем влияние служителя на массу тигров-самцов. Зависимая переменная – масса. Независимая – группы: 1. до нового служителя; 2. после) ДВУХВЫБОРОЧНЫЕ КРИТЕРИИ. КРИТЕРИЙ СТЪЮДЕНТА ДЛЯ СВЯЗАННЫХ ВЫБОРОК Каждый тигр два раза участвует в наблюдениях: он входит в обе группы. 1 тигр 2 тигр 3 тигр 4 тигр 5 тигр 6 тигр Статистика: ДО 356 351 353 355 354 355 ПОСЛЕ 363 361 358 356 359 355 Di X i1 X i 2 Таких D столько, сколько пар. У них есть среднее. H 0 : D 0 H1 : D 0 D D t sD Идентично одновыборочному tкритерию! D t sD Тест может быть односторонним и двусторонним df n 1 ФОРМИРОВАНИЕ ВЫБОРОК ДЛЯ ПАРАМЕТРИЧЕСКИХ КРИТЕРИЕВ В случае t-критериев Стьюдента: выборки случайные из популяций с нормальным распределением, равными дисперсиями, N≥10, лучше всего – от 30. НО: 1. небольшие отклонения от нормального распределения допустимы, если: распределение симметрично; тест двусторонний (односторонний НЕ рекомендуется) размеры выборок одинаковы 2. Для двухвыборочных тестов несоблюдение требования равенства дисперсий (приводит к увеличению ошибки 1-го рода) допустимо, если: распределения соответствуют нормальному; выборки отличаются по размеру не больше, чем на 10% 3. Двухвыборочные тесты Стьюдента и пр. не просто так названы двухвыборочными – они не подходят для 3-х и более выборок!!. ПРОВЕРКА РАВЕНСТВА ДИСПЕРСИЙ: вставлена в Статистике в блоки с соответствующими параметрическими тестами (t-тест, ANOVA) Проверка равенства дисперсий F-test – для двух групп; Levene’s test – более надёжный, подходит для двух и более групп; Brown & Forsythe's test – подходит для выборок разного размера Barlett’s test – для трёх и более групп /Если выборки гетерогенны, есть способы сделать их гомогенными./ МНОЖЕСТВЕННЫЕ СРАВНЕНИЯ ИЛИ КОШМАР БОНФЕРРОНИ Предположим, у нас 4 группы тигров, которых кормят по-разному. Различается ли средняя масса тигра в этих группах? 27 ANOVA Одна зависимая переменная (variable): масса; Одна независимая (группирующая, factor) – тип еды. One-way ANOVA Формулируем гипотезу Н0: Тигров кормили: 1. 2. 3. 4. овощами; фруктами; рыбой; мясом. H 01 : 1 2 H 02 : 1 4 H 03 : 1 3 H 04 : 2 3 H 05 : 2 4 H 06 : 3 4 H 0 : 1 2 3 4 Это сложная гипотеза (omnibus hypothesis). Она включает в себя много маленьких гипотез (для 3-х групп – 3, для 4-х – 12 …): H 07 : Парные (pairwise) нулевые гипотезы 1 2 2 3 4 2 3 4 H 08 : 1 2 3 ... Комплексные (complex) нулевые гипотезы 28 ANOVA POST HOC TESTS Если у нас 3 и более групп: 1. Сначала сравнить ВСЕ группы между собой с помощью ANOVA 2. Если различия есть, использовать методы множественного сравнения (группы сравнивают попарно, но вводят поправки) 3. Если различий нет, мы НЕ ИМЕЕМ ПРАВА ПРЕДПРИНИМАТЬ ДАЛЬНЕЙШИЙ АНАЛИЗ! Двухвыборочный t-критерий для сравнения групп попарно после проведения ANOVA тоже не годится! Например, если мы сравним две крайние группы, это уже будут не случайные выборки из генеральной совокупности, и уже будет не 0.05! 29 НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ Свойства распределения неизвестны, и параметры распределения (среднее, дисперсию и т. п.) мы использовать не можем Основной подход – ранжирование (ranking) наблюдений (выстраиваем их по порядку от самого маленького значения к наибольшему). подразумевается, что сравниваемые распределения имеют одинаковую форму и дисперсию. АНАЛИЗ ЧАСТОТ Родились: 84 розовых мыши и 16 зелёных. H0: выборка получена из популяции, где соотношение розовых и зелёных – 3:1. H1: выборка получена из популяции, где соотношение розовых и зелёных не равно 3:1 1:3 ?? Заметим, что речь идёт только о частотах, но не о параметрах распределения. Oi розовые зелёные всего 100 84 16 Ei k 2 i 1 75 25 Oi Ei 2 84 752 16 252 Ei 75 25 1.080 3.240 4.320 df = k-1=1 χ2cv = 3.841<4.320 p=0.038 Чем больше значение χ2,тем хуже наши данные соответствуют теоретическому распределению – тем меньше р H0 отвергаем – соотношение мышей не соответствует ожидаемому АНАЛИЗ ЧАСТОТ Сравниваем независимые выборки, причём все переменные (≥2) категориальные. Tests of independence – проверяют, зависит ли форма распределения одной переменной от значений другой переменной (переменных). Критерий χ2 (χ2 analysis of contingency tables = χ2 test of independence) ♂ ♂ ♂ ♂ Связаны ли пол и цвет у коз? ♀ ♀ ♀ ♀ пол белые красные жёлтые серые Всего самцы самки 32 55 43 65 16 64 9 16 100 200 всего 87 108 80 25 300 Таблицы вида a × b. Общая Н0 гипотеза: частоты в строчках не зависят от частот в столбцах. H0: цвет меха не зависит от пола в популяции коз; H1: цвет меха зависит от пола в популяции коз. Мы для каждой ячейки рассчитываем ожидаемую частоту (на основе общих частот для столбцов и строк). k Oi Ei 2 i 1 Ei 2 ОШИБКИ ПРИ ОПИСАНИИ РЕЗУЛЬТАТОВ «Смутно пишут о том, о чем смутно представляют» М.В. Ломоносов ПРИМЕР1 1. Что такое «граница нормального распределения»? Зачем ее находили? 2. С помощью какого критерия проверялась гипотеза о виде распределения? 3. Что такое «неправильное распределение»? 4. Данные описаны с помощью среднего и стандартного отклонения. 5. ANOVA – параметрический критерий. ПРИМЕР 2 1. Гипотеза о виде распределения не проверялась. 2. Что такое «достоверность параметров»? 3. Гипотеза о равенстве дисперсий не проверяется. 4. Уровень значимости не указан. ПРИМЕР 3 Статья "Влияние гиперлипидемии на чувствительность тимоцитов к апоптозу у мышей линии CBA и C57BI/C." Киселева Е.П., Пузырева В.П., Огурцова Р.П., Ковалева И.Г. Институт экспериментальной медицины РАМН, Санкт-Петербург. Бюллетень экспериментальной биологии и медицины, вып. 8, 2000, стр. 200-202. Цитаты из статьи Наш комментарий "Полученные данные обработаны статистически с использованием t критерия Стьюдента." В работе не сообщается о проверке условий необходимых и достаточных для использования tкритерия Стьюдента - нормальности распределения и равенства генеральных дисперсий (для всех признаков и во всех группах). Используя данные таблицы, проведем проверку гипотез о равенстве дисперсийдля нескольких случайно выбранных пар. Поскольку для каждой конкретной группы Далее в тексте приведены выражения вида (M±m)" и сравнения в статье не указан объем выборки, то используем минимально возможное в данное случае результаты сравнения отдельных значение, равное 8. групп между собой. Для конкретных сравниваемых пар гурпп не сообщается объем выборок, однако в тексте статьи сказано, что объем выборок изменялся в интервале от 8 до 16. Для пары 2,4±0,1 и 6,0±0,3 значение критерия Фишера F = 9,719 (р=0,0048). Для пары 2,3±0,1 и 3,8±0,2 значение критерия Фишера F = 4 (р=0,044). Для пары 1,6±0,1 и 3,0±0,2 значение критерия Фишера F = 4 (р=0,044). Для пары 17,6±0,1 и 26,0±0,2 значение критерия Фишера F = 4 (р=0,044). Для пары 17,2±0,1 и 22,7±0,4 значение критерия Фишера F = 16 (р=0,0008). Для пары 8,6±0,2 и 13,1±0,4 значение критерия Фишера F = 4 (р=0,044). Итак, поскольку достигнутый уровень значимости гораздо меньше 5%, то гипотеза о равенстве дисперсий для этих случаев отвергается! Вывод: если даже предположить, что во всех сравниваемых группах наблюдалось нормальное распределение, что само по себе весьма маловероятно, тем не менее, критерий Стьюдента не может быть использован в данных условиях вследствие неравенства генеральных дисперсий (см. проблему Беренса-Фишера). . Из чего следует, что выводы авторов не могут быть признаны корректно обоснованными методами статистики, а стало быть надежность их весьма сомнительна. ЗАКЛЮЧЕНИЕ ПРИЗНАК Количественный (нормальное распределение*) Качественный Порядковый ИССЛЕДОВАНИЕ Две группы Более двух групп Группа до и после лечения Одна группа несколько видов лечения Связь признаков Критерий Стьюдента ANOVA Парный критерий Стьюдента Дисперсионный анализ повторных измерений Линейная регрессия, корреляция, или метод БлэндаАлтмана Критерий 2 Z-критерий Критерий 2 Критерий МакНимара Критерий Кокрена Коэффициет сопряженности Критерий Манна Уитни Критерий Крускала Уоллиса Критерий Уилкоксона Критерий Фридмана Коэффициент ранговой корреляции Спирмена http://www.biometrica.tomsk.ru/