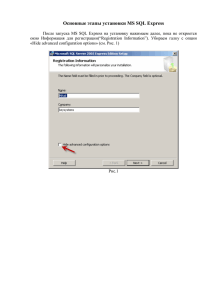
базы данных - Кузнецкий институт информационных и
реклама

Министерство образования и науки Российской Федерации
Кузнецкий институт информационных и управленческих технологий
БАЗЫ ДАННЫХ
Методические указания
к лабораторным работам
Кузнецк 2011
Лабораторная работа N 1
Тема: Выборка данных из базы данных с использованием языка SQL
Цель работы: изучить принципы работы с базой данных в архитектуре клиент-сервер, изучить
спецификации запроса языка баз данных SQL, получить практические навыки составления и
содержательной интерпретации запросов выборки данных (операторов SELECT), а также их
выполнения на SQL-сервере с использованием клиентских утилит.
Порядок выполнения работы
1. Запустить MS SQL Server 7.0 : Пуск – Программы - MS SQL Server – Enterprice Manager.
2. Изучить структуру учебной БД PUBS (изучить состав книготорговой компании ,
структуру и семантику ее таблиц ).
3. Запустить утилиту Query Analyzer, входящую в набор клиентских утилит для СУБД SQL
Server : меню Tools - Query Analyzer.
4. Изучить структуру и элементы SQL-запроса выборки, в том числе разделы FROM,
WHERE, GROUP BY, HAVING, ORDER BY, а также предикаты условия поиска и
агрегатные функции.
5. Изучить операции реляционной алгебры (соединение, пересечение, объединение,
разность и др.).
6. Получить у преподавателя номер варианта задания.
7. В соответствии с вариантом задания типа А произвести содержательную интерпретацию
заданных SQL-запросов, выполнить их на SQL-сервере с использованием клиентских
утилит, проинтерпретировать результаты выполнения запросов.
8. В соответствии с вариантом задания В составить SQL-запросы по их заданному
содержательному описанию, выполнить SQL-запросы на SQL-сервере с использованием
клиентских утилит, проинтерпретировать результаты выполнения запросов.
9. Оформить отчет.
Содержание отчета
1) Титульный лист; 2) цель работы; 3) тексты SQL-запросов и их содержательная
интерпретация; 4) результаты выполнения запросов по заданиям типа А и В и их
интерпретация; 5) выводы.
Теоретические сведения
Язык SQL
Первый международный стандарт языка SQL был принят в 1989 г. (SQL/89). В конце 1992 г.
Был принят новый международный стандарт SQL/92. “Родным” языком Microsoft SQL Server
является язык Transact-SQL (T-SQL), являющийся диалектом стандартного языка SQL. T-SQL
поддерживает большинство возможностей языков SQL/89 и SQL/92, а также ряд расширений,
увеличивающих возможность программирования и гибкость языка. В частности, в язык T-SQL
добавлены конструкции для задания последовательности операций управления в программе
(например, if и while), локальных переменных и других конструкций, позволяющих писать
более сложные запросы и строить программные объекты, хранящиеся на сервере, в том числе
процедуры и триггеры.
Язык SQL включает следующие языки:
o
o
язык определения данных (Data Definition Language или DDL), предназначенный
для добавления, модификации и удаления данных в таблицах;
язык модификации данных (Data Modification Language или DML),
предназначенный для добавления, модификации и удаления данных в таблицах.
В синтаксических конструкциях при описании языка будут использоваться следующие
соглашения. Нетерминальные элементы заключаются в угловые скобки <>. Необязательная
конструкция заключается в квадратные скобки []. Запись вида {A}… означает повторение
конструкции А произвольное число раз (включая нулевое). Вертикальные разделители |
читаются как “ИЛИ” и служат для выбора одной из конструкций, заключенных в скобки.
Оператор SELECT
Оператор SELECT используется для запросов к базе данных и выборки результатов. Синтаксис
оператора SELECT следующий:
<оператор SELECT>::=
SELECT [ALL | DISTINCT] <список выборки>
<табличное выражение>
ORDER BY <спецификация сортировки>]
<табличное выражение>::=
FROM <имя таблицы>[{,<имя таблицы>}…]
[WHERE <условие поиска>]
[GROUP BY <имя столбца> [{,<имя столбца>}…]
[HAVING <условие поиска>]
Если задано ключевое слово DISTINCT, то из результирующей таблицы удаляются
повторяющиеся строки. Список выборки определяет, какие столбцы должны быть возвращены
в результирующую таблицу. Данный список представляет список арифметических выражений
над значениями столбцов таблиц из раздела FROM и констант. В простейшем случае он может
быть, например, списком имен некоторых столбцов таблиц из раздела FROM. В случае, если
вместо списка выборки стоит звездочка (*), то выбираются все столбцы таблиц из раздела
FROM.
В разделе FROM определяются таблицы, из которых будут извлекаться данные. Следует
отметить, что рядом с именем таблицы можно указывать еще одно имя - синоним имени
таблицы, который можно использовать в других разделах табличного выражения.
Раздел WHERE служит своего рода фильтром при отборе данных.
Выполнение раздела GROUP BY оператора выборки сводится к разбиению результирующей
таблицы на множество групп строк, которое состоит из минимального числа таких групп, в
которых для каждого столбца из списка столбцов раздела GROUP BY во всех строках каждой
группы, включающей более одной строки, значения этого столбца совпадают.
Результатом выполнения раздела HAVING является сгруппированная таблица, содержащая
только те группы строк, для которых результат вычисления условия поиска является истинным.
Условие поиска раздела HAVING задает условие на целую группу, а не на индивидуальные
строки, поэтому в данном случае прямо можно использовать только столбцы, указанные в
качестве столбцов группирования в разделе GROUP BY.
Раздел ORDER BY позволяет установить желаемый порядок просмотра результирующей
таблицы. Спецификация сортировки имеет следующий синтаксис:
<спецификация сортировки>::= {<целое без знака> | <имя столбца>} [ASC | DESC]
Как видно, фактически задается список столбцов, и для каждого столбца указывается порядок
просмотра строк результирующей таблицы в зависимости от значений этого столбца (ASC - по
возрастанию (умолчание), DESC - по убыванию). Указывать сортируемый столбец можно по
имени или по порядковому номеру в результирующей таблице.
Предикаты условия поиска
В условии поиска могут использоваться следующие предикаты: предикат сравнения, предикат
BETWEEN , предикат IN, предикат LIKE, предикат NULL, предикат с квантором и предикат
EXISTS.
Предикат IN определяется следующим образом:
<предикат IN>::= <выражение> [NOT] IN (<значение> [,<значение>...] | .<подзапрос>)
Значение предиката является истинным, когда значение левого операнда совпадает хотя бы с
одним значением списка правого операнда. Использование ключевого слова NOT осуществляет
отрицание результата.
Подзапрос- это запрос, используемый в предикате условия поиска. Результатом выполнения
подзапроса является единственный столбец.
Предикат BETWEEN определяется следующим образом:
<предикат BETWEEN>::= <выражение> [NOT] BETWEEN <выражение> AND <выражение>
По определению результат x BETWEEN y AND z тот же самый, что результат логического
выражения x>=y AND x<=z.
Предикат LIKE имеет следующий синтаксис:
<предикат LIKE>::= <имя столбца> [NOT] LIKE <шаблон>[ESCAPE <escape-символ>]
Значение предиката LIKE является истинным, если шаблон является подстрокой заданного
столбца. При этом, если раздел ESCAPE отсутствует, то при составлении шаблона со строкой
производится специальная интерпретация символов-заместителей шаблона: символ
подчеркивания ("_") обозначает любой одиночный символ, символ процента ("%") обозначает
последовательность произвольных символов произвольной длины (может быть нулевой),
парные квадратные скобки представляют любой символ, записанный в скобках. Если же раздел
ESCAPE присутствует и специфицирует некоторый одиночный символ x, то пары символов
"x_" и "x%" представляют одиночные символы "_" и "%" соответственно.
Предикат NULL описывается синтаксическим правилом:
<предикат NULL>::= <имя столбца> IS [NOT] NULL
Значение "x IS NULL" является истинным, когда значение x неопределено.
Предикат EXISTS имеет следующий синтаксис:
<предикат EXISTS>::= EXISTS <подзапрос>
Значение предиката является истинным, когда результат вычисления подзапроса не пуст.
Агрегатные функции
Агрегатные функции (функции множества) в запросе предназначены для вычисления
некоторого значения для заданного множества строк. Таким множеством строк может быть
группа строк, если агрегатная функция применяется к сгруппированной таблице, или вся
таблица. В языке SQL определены следующие агрегатные функции:
o
o
o
o
o
AVG - функция определения среднего значения;
MAX - функция определения максимального значения;
MIN - функция определения минимального значения;
SUM - функция суммирования значений;
COUNT - функция для подсчета числа строк или значений.
Грамматика агрегатных функций следующая:
<агрегатная функция>::= COUNT(*) | <distinct-функция> | <all-функция>
<distinct-функция>::= {AVG | COUNT | MAX | MIN | SUM} (DISTINCT <имя столбца>)
<all-функция>::= {AVG | MAX | MIN | SUM} ([ALL]<выражение>)
Вычисление функции COUNT(*) производится путем подсчета числа строк в заданном
множестве. Функция типа distinct выполняет вычисления только над одним столбцом, а в
вычислениях используются только уникальные значения столбца. При использовании функции
типа all список значений формируется из значений арифметического выражения, вычисляемого
для каждой строки заданного множества.
Операции реляционной алгебры
Большинство SQL-запросов требует одновременного обращения к нескольким таблицам. Часто
такого рода запросы основываются на операциях реляционной алгебры, в частности,
соединения, декартова произведения, объединения, пересечения и разности.
При соединении двух таблиц по некоторому условию образуется результирующая таблица,
строки которой являются конкатенацией (сцеплением) строк первой и второй таблиц и
удовлетворяют этому условию. Операцию соединения можно реализовать с использованием
обычного SQL-запроса типа SELECT-FROM-WHERE. По стандарту ANSI операция соединения
таблиц может указываться явно в разделе FROM. Синтаксис раздела FROM в этом случае
следующий:
<раздел FROM>::= FROM <имя таблицы> [JOIN <имя таблицы> ON <условие соединения>
...]
При выполнении декартова произведения двух таблиц производится таблица, строки которой
являются конкатенацией строк первой и второй таблиц. Операцию декартова произведения
можно реализовать с использованием SQL-запроса типа SELECT-FROM. По стандарту ANSI
операция декартова произведения может указываться явно в разделе FROM с использованием
ключевой фразы CROSS JOIN.
При выполнении операции объединения двух таблиц производится таблица, включающая все
строки, входящие хотя бы в одну из таблиц-операндов. При этом число столбцов и типы
данных этих столбцов должны быть одинаковыми для всех операндов. Для объединения
результирующих таблиц операторов SELECT используется ключевое слово UNION.
Операция пересечения двух таблиц производит таблицу, включающую все строки, входящие в
обе исходные таблицы.
Таблица, являющаяся разностью двух таблиц, включает все строки, входящие в таблицу первый операнд, такие, что ни одна из них не входит в таблицу, являющуюся вторым
операндом.
Основные операции реляционной алгебры
1. Проекция (projection).
Это унарная операция (выполняемая над одним отношением), служащая для выбора
подмножества атрибутов из отношения R. Она уменьшает арность отношения и может
уменьшить мощность отношения за счёт исключения одинаковых кортежей.
Пример 1. Пусть имеется отношение R(A,B,C) (рис.2,а).
Тогда проекция A,C(R) будет такой, как показано на рис.2,б.
а) Отношение R
A
B
C
a
b
c
c
a
d
c
b
d
б) Проекция A,C(R)
A
C
a
c
c
d
Рис.2. Пример проекции отношения
2. Селекция (selection).
Это унарная операция, результатом которой является подмножество кортежей исходного
отношения, соответствующих условиям, которые накладываются на значения
определённых атрибутов.
Пример 2. Для отношения R(A,B,C) (рис. 3,а) селекция C=d(R) (при условии "значение
атрибута C равно d") будет такой (рис. 3,б):
а) Отношение R
A
B
C
a
b
c
c
a
d
c
b
d
б) Селекция C=d(R)
A
B
C
c
a
d
c
b
d
Рис.3. Пример селекции отношения
3. Декартово произведение (Cartesian product).
Это бинарная операция над разносхемными отношениями, соответствующая
определению декартова произведения для РМД.
Пример 3. Пусть имеются отношение R(A,B) и отношение S(C,D,E) (рис.4,а). Тогда
декартово произведение R S будет таким (рис.4,б):
а) Исходные отношения
A
B
a
B
c
A
b
D
C
D
E
g
h
a
a
b
c
б) Декартово произведение
A
B
C
D
E
a
b
g
h
a
a
b
a
b
c
c
a
g
h
a
c
a
a
b
c
b
d
g
h
a
b
d
a
b
c
Рис.4. Пример декартова произведения отношений
4. Объединение (union).
Объединением двух односхемных отношений R и S называется отношение T = R U S,
которое включает в себя все кортежи обоих отношений без повторов.
5. Разность (set difference).
Разностью односхемных отношений R и S называется множество кортежей R, не
входящих в S.
Пример 4. Пусть имеются отношение R(A,B,C) и отношение S(A,B,C) (рис.5,а). Тогда
разность R–S будет такой (рис.5,б):
а) Исходные отношения
A
B
C
a
b
c
c
a
d
c
h
c
A
B
C
g
h
a
a
b
c
h
d
d
б)
A
B
C
c
a
d
c
h
c
Рис.5. Пример разности отношений
1.3.2. Вспомогательные операции реляционной алгебры
6. Пересечение (intersection).
Пересечение двух односхемных отношений R и S есть подмножество кортежей,
принадлежащих обоим отношениям. Это можно выразить через разность:
R ∩ S = R – (R – S).
7. Соединение (join).
Эта операция определяет подмножество декартова произведения двух разносхемных
отношений. Кортеж декартова произведения входит в результирующее отношение, если
для атрибутов разных исходных отношений выполняется некоторое условие. Если
условием является равенство атрибутов исходных отношений, такая операция
называется эквисоединением. Естественным называется эквисоединение по
одинаковым атрибутам исходных отношений.
Пример 5. Пусть имеются отношения R(A,B,C) и S(A,D,E) (рис.6,а). Тогда естественное
соединение
R S будет таким, как показано на рис.6,б.
а) Исходные отношения
A
B
C
a
b
c
c
a
d
c
h
c
g
b
d
A
D
E
g
h
a
c
b
c
h
d
d
б) Соединение отношений
A
B
C
D
E
c
a
d
b
c
c
h
c
b
c
g
b
d
h
a
Рис.6. Пример естественного соединения отношений
8. Деление (division).
Пусть отношение R содержит атрибуты {r1,r2,...,ri,...,rn}, а отношение S – атрибуты {r1,r2,...,ri}.
Результирующее отношение содержит атрибуты {ri+1,...,rn}. Кортеж включается в
результирующее отношение, если его декартово произведение с каким-либо кортежем
отношения S входит в R.
Пример 6. Пусть имеются отношения R(A,B,C) и S(A,B) (рис. 7,а). Тогда частное
R/S будет таким как показано на рис. 7,б.
а) Исходные отношения
A
B
C
D
a
b
c
f
c
b
a
b
g
h
d
c
c
b
b
c
A
B
g
h
c
b
b
a
б) Частное
C
D
d
c
a
b
b
c
Рис.7. Пример операции деления
Описание задания
База данных книготорговой компании
Рассмотрим простую предметную область жизнедеятельности, связанную с книгоизданием и
маркетингом. В рамках данной предметной области существуют издатели, которые публикуют
книги, авторы, которые книги пишут, и издания (сами книги). Разработана база данных pubs,
определяющая описанную выше предметную область. Инфологическая модель предметной
области с использованием диаграмм “сущность-связь” (ER-диаграмм) [1]), разработанных
Ченом, представлена на рис. 1.
На данном рисунке прямоугольниками обозначены типы сущностей (объектов), а ромбами типы связей между сущностями. Атрибуты сущностей указаны мелким шрифтом в том же
прямоугольнике, который отображает типы сущностей. Имя типа сущности отмечено в верхней
части прямоугольника жирным шрифтом. Атрибуты связей в данном случае обозначены
овалами. Как видно из рис. 1 у связи “Написана” имеется два атрибута: первый атрибут
определяет порядок автора в названии книги, второй атрибут - гонорар автора книги.
Рис. 1
База данных книготорговой компании (база данных pubs) включает три таблицы,
определяющие сущности: таблица authors определяет авторов, таблица publishers - издателей, а
таблица titles - сами книги. Четвертая таблица titleauthor задает отношение между таблицами
titles и authors. Она показывает, какие авторы написали какие книги. Связь между таблицами
titiles и publishers определяется столбцом pub_id в данных таблицах.
Ниже представлены структуры используемых таблиц.
Структура таблицы authors
Имя столбца
Тип данных
Размерность
Возможность значений null
Содержательное описание
au_id
varchar
11
Нет
Идентификатор автора
au_lname
varchar
40
Нет
Фамилия автора
au_fname
varchar
20
Нет
Имя автора
phone
char
12
Нет
Номер телефона
address
varchar
40
Да
Адрес (улица, дом, квартира)
city
varchar
20
Да
Город проживания
state
char
2
Да
Штат проживания
zip
char
5
Да
Энергичность
contract
bit
1
Нет
Наличие контракта
Структура таблицы publishers
Имя
столбца
Тип
данных
Размерность
Возможность значений
null
Содержательное описание
pub_id
char
4
Нет
Идентификатор издательства
(издателя)
pub_name
varchar
40
Да
Название издательства (имя издателя)
city
varchar
20
Да
Город
state
char
2
Да
Штат
country
varchar
30
Да
Страна
Структура таблицы titles
Имя
столбца
Тип
данных
Размерность
Возможность значений
null
Содержательное описание
title_id
varchar
6
Нет
Идентификатор книги
title
varchar
80
Нет
Название книги
type
char
12
Нет
Тип книги
pub_id
char
4
Да
Идентификатор издательства
price
money
8
Да
Цена
advance
money
8
Да
Аванс (стоимость предварительной
продажи)
royalty
int
4
Да
Гонорар
ytd_sales
int
4
Да
Число книг, проданных в текущем году
notes
varchar
200
Да
Замечания
pubdate
datetime
8
Нет
Дата опубликования
Структура таблицы titleauthor
Имя столбца
Тип данных
Размерность
Возможность значений null
Содержательное описание
au_id
varchar
11
Нет
Идентификатор автора книги
title_id
varchar
6
Нет
Идентификатор книги
au_ord
tinyint
1
Да
Порядок автора в названии книги
royaltyper
int
4
Да
Авторский гонорар
В столбце type таблицы titles используются следующие типы книг: business - книги по бизнесу,
mod_cook - книги по современной кулинарии, popular_comp - книги по компьютерной тематике,
psychology - книги по психологии, trad_cook - книги по традиционной кулинарии, UNDECIDED
- неопределенный тип книги.
В столбцах state таблиц authors и publishers используются следующие обозначения
административных единиц США: CA - штат Калифорния, DC - округ Колумбия, IL - штат
Иллинойс, IN - штат Индиана, KS -штат Канзас, MD - штат Мэриленд, MA - штат Массачусетс,
MI - штат Мичиган, NY - штат Нью-Йорк, OR - штат Орегон, TN - штат Теннесси, TX штатТехас, UT - штат Юта.
В столбце country таблицы publishers используются следующие обозначения стран: France Франция, Germany - Германия, USA - США.
Домен городов, используемый в таблицах authors и publishers, включает города Ann Arbor,
Berkeley, Boston, Chicago, Corvallis, Colevo, Dallas, Gary, Lawrence, Menlo Park, Munchen,
Nashville, New York, Oakland, Palo Alto, Paris, Rockville, Salt Lake City, San Francisco, San Jose,
Vacaville, Walnul Creek, Washington.
В приложении 1 приведен полный пример базы данных pubs.
Лабораторные задания типа А
Дать содержательную интерпретацию SQL-запросам, выполнить их на SQL-сервере с
использованием клиентских утилит ISQL/w или SQL-EM, дать содержательную интерпретацию
результатам выполнения SQL-запросов.
1) SELECT au_lname, au_fname
FROM authors
2) SELECT au_lname, au_fname
FROM authors
ORDER BY au_lname
3) SELECT au_lname, au_fname
FROM authors
ORDER BY au_lname, au_fname
4) SELECT title_id, price, ytd_sales,
price*ytd_sales "ytd dollar sales"
FROM titles
ORDER BY price*ytd_sales
5) SELECT title_id, price, ytd_sales,
price*ytd_sales "ytd dollar sales"
FROM titles
ORDER BY price*ytd_sales DESC
6) SELECT title_id, type, ytd_sales
FROM titles
ORDER BY type ASC, ytd_sales DESC
7) SELECT AVG(price)
FROM titles
8) SELECT DISTINCT type
FROM titles
ORDER BY type ACS
9) SELECT DISTINCT city
FROM authors
ORDER BY city DESC
10) SELECT DISTINCT state
FROM authors
ORDER BY state
11) SELECT DISTINCT country
FROM publishers
ORDER BY country DESC
12) SELECT AVG(price), AVG(DISTINCT price)
FROM titles
13) SELECT *
FROM titles
14) SELECT au_lname, au_fname
FROM authors
WHERE state= "CA"
15) SELECT type, title_id, price
FROM titles
WHERE price*ytd_sales < advance
16) SELECT au_id, city, state
FROM authors
WHERE state= "CA" OR city= "Palo Alto"
17) SELECT title_id, price
FROM titles
WHERE price between $5 AND $15
18) SELECT title_id, price
FROM titles
WHERE type IN ("mod_cook", "trad_cook", "business")
19) SELECT au_lname, au_fname, city, state
FROM authors
WHERE city like "San%"
20) SELECT type, title_id, price
FROM titles
WHERE title_id like "B_2075"
21) SELECT type, title_id, price
FROM titles
WHERE title_id like "B[AUN]7832"
22) SELECT AVG(price) "AVG"
FROM titles
WHERE type= "business"
23) SELECT AVG(price) "avg" SUM(price) "sum"
FROM titles
WHERE type IN ("business", "mod_cook")
24) SELECT COUNT(*)
FROM authors
WHERE state= "CA"
25) SELECT COUNT(*)
FROM titles
WHERE LIKE "Co%s"
26) SELECT title
FROM titles
WHERE ytd_sales IS NULL
27) SELECT au_lname "Фамилия”, au_fname "Имя”
FROM authors
WHERE contract=1 AND phone LIKE "408____-__2_"
28) SELECT phone
FROM authors
WHERE address LIKE "%Broadway Av.%"
29) SELECT title, pubdate
FROM titles
WHERE pubdate>= "Jun 9 1991 12:00AM"
AND pubdate< "6/16/91"
30) SELECT type, AVG(price) "avg", SUM(price) "sum"
FROM titles
WHERE type IN ("business", "psychology")
GROUP BY type
31) SELECT type, pub_id, AVG(price) "avg", SUM(price) "sum"
FROM titles
WHERE type IN ("business", "mod_cook")
GROUP BY type, pub_id
32) SELECT type, AVG(price)
FROM titles
WHERE price>$11
GROUP BY type
HAVING AVG(price)>$19.7
33) SELECT au_id, COUNT(*)
FROM authors
GROUP BY au_id
HAVING COUNT(*)>1
34) SELECT type, MIN(price), MAX(price)
FROM titles
GROP BY type
ORDER BY type
35) SELECT type, MIN(price), MAX(price)
FROM titles
GROUP BY type
HAVING MAX(price)-MIN(price)>=3
36) SELECT state, COUNT(DISTINCT pub_id)
FROM publishers
GROUP BY state
37) SELECT pub_name, AVG(price) "avg",
COUNT(DISTINCT title_id) "count"
FROM titles t JOIN publishers p ON t.pub_id=p.pub_id
GROUP BY pub_name
38) SELECT type, (MIN(price)+MIN(price))/2, AVG(price)
FROM titles
GROUP BY type
HAVING type<> "UNDECIDED"
ORDER BY 2 DESC
39) SELECT type, MIN(pubdate), MAX(pubdate)
FROM titles
GROUP BY type
40) SELECT title, pub_name
FROM titles CROSS JOIN publishers
41) SELECT *
FROM titles, publishers
42) SELECT title, pub_name
FROM titles, publishers
WHERE titles.pub_id=publishers.pub_id
43) SELECT title, pub_name
FROM titles JOIN publishers
ON titles.pub_id=publishers.pub_id
44) SELECT *
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
45) SELECT t.*, pub_name
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
46) SELECT a.city, a.state
FROM authors a, publishers p
WHERE a.city=p.city AND a.state=p.state
47) SELECT au_lname, au_fname
FROM authors a JOIN titleauthor ON a.au_id=ta.au_id
JOIN titles t ON ta.title_id=t.title_id
WHERE au_lname LIKE "R%"
AND state IN ("CA", "TX", "NY", "OR", "UT")
AND (title LIKE "_h_ %" OR title LIKE "% _h_ %"
OR title LIKE "% _h_")
48) SELECT title, type
FROM authors a, titles t, titleauthor ta, publishers p
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND t.pub_id=p.pub_id AND p.city=a.city
49) SELECT au_lname, au_fname, title
FROM authors a, titles t, titleauthor ta, publishers p
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND t.pub_id=p.pub_id
AND ((p.country= ‘USA’ AND t.type=’popular_comp’)
OR (p.country=’France’ AND t.type=’psychology’))
50) SELECT au_lname, au_fname, city
FROM authors a, titles t, titleauthor ta
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND (city LIKE "[CPR]%" OR city LIKE "%San%")
AND (title LIKE "% the %" OR title LIKE "The %"
OR title LIKE "% a %" OR title LIKE "A %")
51) SELECT DISTINCT au_lname, au_fname
FROM authors a JOIN titleauthor ta ON a.au_id=ta.au_id
JOIN titles t ON ta.title_id=t.title_id
JOIN publishers p ON p.pub_id=t.pub_id
WHERE p.state= "CA"
ORDER BY au_lname, au_fname
52) SELECT pub_name
FROM publishers p JOIN titles t ON p.pub_id=t.pub_id WHERE $15>price AND type= "psychology"
ORDER BY pub_name
53) SELECT pub_name, AVG(price)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY pub_name
54) SELECT pub_name, AVG(price)
FROM titles t JOIN publishers p ON t.pub_id=p.pub_id
GROUP BY pub_name
55) SELECT au_lname, au_fname, title
FROM authors a, titles t, titleauthor ta
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND type= "popular_comp"
56) SELECT au_lname, au_fname, title
FROM authors a JOIN titleauthor ta ON a.au_id=ta.au_id
JOIN titles t ON ta.title_id=t.title_id
WHERE type= "psychology"
57) SELECT au_lname, au_fname, pub_name, COUNT(*)
FROM authors a, titles t, titleauthor ta, publishers p
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND t.pub_id=p.pub_id
GROUP BY au_lname, au_fname, pub_name
58) SELECT MIN(price)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY country
HAVING country=’USA’
59) SELECT pub_name, COUNT(*)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
AND (type= ‘mod_cook’ OR type=’trad_cook’)
GROUP BY pub_name
60) SELECT pub_name, COUNT(*)
FROM publishers p, titles t
WHERE p.pub_id=t.pub_id AND price>$15
GROUP BY pub_name
ORDER BY pub_name DESC
61) SELECT title, COUNT(DISTINCT a.au_id)
FROM titles t JOIN titleauthor ta ON t.title_id=ta.title_id
JOIN authors a ON ta.au_id=a.au_id
JOIN publishers p ON p.pub_id=t.pub_id
GROUP BY title
62) SELECT state, COUNT(DISTINCT p.pub_id)
FROM publishers p JOIN titles t ON p.pub_id=t.pub_id
GROUP BY state
63) SELECT title
FROM titles
WHERE pub_id=
(SELECT pub_id
FROM publishers
WHERE pub_name= "Binnet & Hardley")
64) SELECT pub_name
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type= "business")
65) SELECT pub_name
FROM publishers p
WHERE EXISTS
(SELECT *
FROM titles t
WHERE p.pub_id=t.pub_id
AND type="popular_comp")
66) SELECT pub_name
FROM publishers p
WHERE NOT EXISTS
(SELECT *
FROM titles t
WHERE p.pub_id=t.pub_id
AND type="mod_cook")
67) SELECT pub_name
FROM publishers
WHERE pub_id NOT IN
(SELECT pub_id
FROM titles
WHERE type="psychology")
68) SELECT type, price
FROM titles
WHERE price < (SELECT AVG(price) FROM titles)
69) SELECT type, AVG(price)
FROM titles
GROUP BY type
HAVING AVG(price) < (SELECT AVG(price) FROM titles)
70) SELECT DISTINCT a.city, a.state
FROM authors a
WHERE NOT EXISTS
(SELECT *
FROM publishers p
WHERE a.city=p.city AND a.state=p.state)
71) SELECT DISTINCT p.city, p.state
FROM publishers p
WHERE NOT EXISTS
(SELECT *
FROM authors a
WHERE p.city=a.city AND p.state=a.state)
72) SELECT MIN(price)
FROM titles t
WHERE t.pub_id IN
(SELECT pub_id
FROM publishers
WHERE country=’USA’)
73) SELECT title, type, price
FROM titles
WHERE price>ALL
(SELECT price
FROM titles
WHERE type= "psychology")
74) SELECT COUNT(DISTINCT city)
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type= "psychology")
75) SELECT pub_name
FROM publishers p
WHERE 15>SOME
(SELECT price
FROM titles t
WHERE p.pub_id=t.pub_id
AND type= "trad_cook")
76) SELECT pub_name, state
FROM publishers
WHERE pub_id NOT IN
(SELECT pub_id
FROM titles)
77) SELECT title
FROM titles
WHERE pub_id NOT IN
(SELECT pub_id
FROM publishers)
78) SELECT title
FROM titles t
WHERE price>=
(SELECT AVG(price)
FROM titles tt, publishers pp
GROUP BY pub_id
HAVING t.pub_id=pp.pub_id)
79) SELECT au_lname, au_fname, price
FROM authors a, titles t, titleauthor ta, publishers p
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND t.pub_id=p.pub_id AND country=’USA’
AND price=
(SELECT MIN(price)
FROM titles tt, publishers pp
WHERE tt.pub_id=pp.pub_id
GROUP BY country
HAVING country=’USA’)
80) SELECT DISTINCT au_lname, au_fname
FROM authors a, titles t, titleauthor ta
WHERE a.au_id=ta.au_id AND ta.title_id IN
(SELECT title_id
FROM titles
WHERE ytd_sales=
(SELECT MAX(ytd_sales)
FROM titles))
81) SELECT DISTINCT a.city, a.state
FROM authors a
WHERE NOT EXISTS
(SELECT *
FROM publishers p
WHERE a.city=p.city AND a.state=p.state)
UNION SELECT DISTINCT p.city, p.state
FROM publishers p
WHERE NOT EXISTS
(SELECT *
FROM authors a
WHERE p.city=a.city AND p.state=a.state)
82) SELECT title, price
FROM titles t JOIN publishers p ON t.pub_id=p.pub_id
WHERE p.country= "USA" AND t.price=
(SELECT MAX(price)
FROM titles tt JOIN publishers pp
ON tt.pub_id=pp.pub_id
WHERE country= "USA")
83) SELECT pub_name, COUNT(*)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY pub_name
HAVING COUNT(*)>=ALL
(SELECT COUNT(*)
FROM titles tt, publishers pp
WHERE tt.pub.id=pp.pub_id
GROUP BY pub_name)
84) SELECT pub_name, city, state, country
FROM publishers p
WHERE EXISTS
(SELECT *
FROM titles t
WHERE t.pub_id=p.pub_id)
AND 20>ALL
(SELECT price
FROM titles t
WHERE t.pub_id=p.pub_id
AND price IS NOT NULL)
85) SELECT state, SUM(price)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY state
HAVING state NOT IN ("TN", "MA", "TX")
AND SUM(price)>
(SELECT SUM(price)
FROM titles tt, publishers pp
WHERE tt.pub.id=pp.pub_id
AND pp.city= "Boston")
86) SELECT pub_name, MIN(price)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY pub_name
HAVING MIN(price)>=ALL
(SELECT MIN(price)
FROM titles tt JOIN publishers pp
ON tt.pub_id=pp.pub_id
GROUP BY pub_name)
87) SELECT *
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type= "psychology" AND pub_id IN
(SELECT pub_id
FROM publishers
WHERE country= "USA"
AND state<> "CA")
88) SELECT au_lname, au_fname
FROM authors a
WHERE a.au_id IN
(SELECT au_id
FROM titleauthor ta
WHERE ta.title_id IN
(SELECT title_id
FROM titles t
WHERE "CA"=SOME
(SELECT state
FROM publishers p
WHERE p.pub_id=t.pub_id)))
ORDER BY au_lname, au_fname
89) SELECT state, COUNT(*)
FROM publishers p
WHERE EXISTS
(SELECT *
FROM titles t
WHERE p.pub_id=t.pub_id)
AND $22>ALL
(SELECT price
FROM titles t
WHERE p.pub_id=t.pub_id
AND price IS NOT NULL)
GROUP BY state
ORDER BY state ASC
90) SELECT state
FROM publishers p1
GROUP BY state
HAVING COUNT(DISTINCT pub_name)=
(SELECT COUNT(*)
FROM publishers p2
WHERE EXISTS
(SELECT *
FROM titles t
WHERE p2.pub_id=t.pub_id)
AND $22.5>ALL
(SELECT price
FROM titles t
WHERE p2.pub_id=t.pub_id
AND price IS NOT NULL)
GROUP BY state
HAVING p1.state=p2.state)
91) SELECT p1.pub_id
FROM titles t1, publishers p1
WHERE t1.pub_id=p1.pub_id
GROUP BY p1.pub_id
HAVING COUNT(DISTINCT title)=
(SELECT COUNT(*)
FROM titles t2
WHERE t2.pub_id=p1.pub_id
AND EXISTS
(SELECT *
FROM titleauthor ta3, authors a3
WHERE ta3.au_id=a3.au_id
AND ta3.title_id=t2.title_id
AND a3.state IN
(SELECT state
FROM publishers p4
WHERE "business"=SOME
(SELECT type
FROM titles t5
WHERE p4.pub_id=
t5.pub_id))))
92) SELECT city, state
FROM authors
UNION SELECT city, state
FROM publishers
ORDER BY state, sity
93) SELECT city
FROM authors
UNION SELECT city
FROM publishers
94) SELECT state
FROM authors
UNION SELECT state
FROM publishers
95) SELECT city, state
FROM authors
WHERE state IS NOT NULL
UNION SELECT city, state
FROM publishers
WHERE state IS NOT NULL
ORDER BY city DESC, state ASC
96) SELECT state, MIN(price), MAX(price), AVG(price)
FROM authors a, titles t, titleauthor ta
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
GROUP BY state
HAVING state<> "CA"
Лабораторные задания типа B
Составить SQL-запросы по их заданному содержательному описанию, выполнить SQL-запросы на SQLсервере с использованием клиентских утилит ISQL/w или SQL-EM, проинтерпретировать результаты
выполнения запросов.
1) Выбрать имена и фамилии авторов книг.
2) Выбрать имена и фамилии авторов, проживающих в Калифорнии.
3) Выбрать информацию о книгах, объеме (стоимость) продаж которых в текущем году меньше
стоимости предварительной продажи. Информация о книгах должна включать тип книги,
идентификатор и цену книги.
4) Выбрать информацию об авторах, проживающих в штате Калифорния или в городе Salt Lake City.
Информация об авторах должна включать идентификатор автора, город и штат проживания.
5) Выбрать все идентификаторы и цены книг, причем цена книги должна лежать в диапазоне от 5 до 10
долларов. В SQL запросе использовать предикат BETWEEN.
6) Выбрать все идентификаторы и цены книг по современной и традиционной кулинарии и по бизнесу.
В запросе использовать предикат IN.
7) Выбрать информацию об авторах, проживающих в городах, название которых начинается со строки
"Sa". Информация об авторах должна включать имя и фамилию автора, а также штат и город
проживания.
8) Выбрать информацию о книгах, идентификаторы которых начинаются буквой "B", а кончаются
строкой "1342". Информация о книгах должна включать тип, идентификатор и цену книги.
9) Выбрать информацию о книгах, идентификаторы которых начинаются буквой "B", заканчиваются
строкой "1342", а вторым символом идентификатора являются буквы "A", "U" или "N". Информация о
книгах должна включать тип, идентификатор и цену книги.
10) Выбрать имена и фамилии всех авторов, упорядоченные по возрастанию фамилий авторов.
11) Выбрать имена и фамилии всех авторов, упорядоченные в первую очередь по возрастанию фамилий
и, во вторую очередь, по возрастанию имен.
12) Выбрать информацию о книгах, упорядоченную по возрастанию объема продаж (по стоимости).
Информация о книгах должна включать идентификатор, цену, объем продаж (по количеству) и объем
продаж (по стоимости).
13) То же, что 12, но использовать упорядочение по убыванию.
14) Выбрать информацию о всех книгах, упорядоченную по убыванию типа книги и числа проданных
книг. Информация о книгах должна включать идентификатор и тип книги, а также число проданных
книг.
15) Определить среднюю цену книги.
16) Определить среднюю цену книг по бизнесу.
17) Определить среднюю цену и стоимость всех книг по бизнесу и современной кулинарии
18) Определить число авторов, проживающих в Калифорнии.
19) Определить среднюю цену и сумму цен на книги по бизнесу и современной кулинарии отдельно для
каждого типа книги.
20) Определить среднюю цену и сумму цен на книги по бизнесу и современной кулинарии для каждой
комбинации типа книги и идентификатора издателя.
21) Выбрать те типы книг, средняя цена дорогих экземпляров (стоимостью более 10 долларов) которых
превышает 20 долларов. В выбираемые данные помимо типа книги включить и среднюю цену дорогих
экземпляров.
22) Подсчитать число строк в таблице authors, включающих одинаковые идентификаторы авторов. В
выбираемые данные включить идентификатор автора и соответствующее ему число повторяющихся
строк.
23) Выбрать названия книг и имена выпустивших их издателей.
24) То же, что и 23, но в разделе FROM запроса использовать операцию соединения JOIN.
25) Произвести проекцию на столбцы title и pub_name декартова произведения таблиц titles и publishers.
26) Определить среднюю цену выпускаемых каждым издателем книг. В выбираемые данные включить
имя издателя и среднюю цену книги.
27) То же, что и 26, но в разделе FROM запроса использовать операцию соединения JOIN.
28) Определить, кто из авторов написал какую книгу по психологии. В выбираемые данные включить
имя и фамилию автора, а также название книги.
29) То же, что и 28, но в разделе FROM запроса использовать операцию соединению JOIN.
30) Выбрать все столбцы результата эквисоединения таблиц titles publishers по идентификатору
издателя.
31) Выбрать все столбцы таблицы titles и столбец pub_name таблицы publishers результата
эквисоединения данных таблиц по идентификатору издателя.
32) Выбрать все книги издательства Algodata Infosysytems. В запросе использовать подзапрос для
определения нужного идентификатора издателя. В условии поиска использовать предикат "=". В
выбираемые данные включить название книги.
33) Выбрать всех издателей литературы по бизнесу. В запросе использовать подзапрос для выборки
нужных идентификаторов издателей. В условии поиска использовать предикат IN. В выбираемые
данные включить имя издателя.
34) Выбрать всех издателей литературы по бизнесу. В запросе использовать подзапрос, формирующий
промежуточную таблицу, в которую включаются те строки из таблицы titles, которые могут “эквисоединиться” по идентификатору издателя со строками из таблицы publishers и которые представляют
тип книг по бизнесу. В условии поиска основного запроса использовать предикат EXISTS. В
выбираемые данные включить имя издателя.
35) Выбрать издателей, не выпускающих книг по бизнесу. Дополнительные условия формирования
запроса взять из варианта 34.
36) Выбрать издателей, не выпускающих книг по бизнесу. Дополнительные условия формирования
запроса взять из варианта 33.
37) Выбрать тип и цену для всех книг, цена которых не превышает средней. В запросе использовать
подзапрос, определяющий среднюю цену книг.
38) Выбрать тип и среднюю цену книг данного типа, причем эта средняя цена должна быть меньше
средней цены всех книг. В запросе использовать подзапрос, определяющий среднюю цену всех книг.
39) Определить города и штаты проживания каждого из авторов и издателей в виде одной
результирующей таблицы.
40) Определить все типы книг. Типы книг в результирующей таблице не должны повторяться. Вывести
типы книг в порядке возрастания.
41) Определить все города, в которых проживают авторы. Названия городов в результирующей таблице
не должны повторяться. Вывести названия городов в порядке убывания.
42) Определить все штаты, в которых проживают авторы. Названия штатов в результирующей таблице
не должны повторяться. Вывести названия штатов в порядке возрастания.
43) Определить страны, в которых расположены издательства книг. Названия стран в результирующей
таблице не должны повторяться. Вывести названия стран в порядке убывания.
44) Определить все города, в которых проживают авторы и находятся издательства. Названия городов в
результирующей таблице не должны повторяться. Вывести названия городов в порядке возрастания.
45) Определить все штаты, в которых проживают авторы и находятся издательства. Названия штатов в
результирующей таблице не должны повторяться. Вывести названия штатов в порядке убывания.
46) Определить города и штаты совместного проживания авторов и издателей. (В запросе неявно
реализуется операцию пересечения).
47) Определить города и штаты проживания авторов, в которых нет издательств. (В запросе неявно
реализуется операция разности).
48) Определить города и штаты нахождения издательств, в которых не проживают авторы. (В запросе
неявно реализуется операция разности).
49) Определить, какой город в каком штате находится. Вывести названия городов в порядке
возрастания.
50) Определить число книг, название которых начинается со строки "The" и заканчивается буквой "e".
51) Определить авторов на букву "G", проживающих в штатах Теннесси, Иллинойс, Канзас, Орегон или
Калифорния, которые опубликовали книги, в которых есть слово из трех букв, причем средней буквой
является буква "a".
52) Определить минимальную, максимальную и среднюю цену для каждого из типов книг. Выводимые
данные должны быть упорядочены по убыванию типа книг.
53) Определить минимальную и максимальную цену для каждого из типов книг. В результирующую
таблицу не включать те типы книг, для которых разность между максимальной и средней ценой меньше
7 долларов.
54) Вычислить среднюю цену всех книг и медиану цены. Под медианой понимается среднее значение
всех различных цен всех книг.
55) Определить, какие авторы в каких издательствах опубликовали сколько книг.
56) Определить книги, авторы и издатели которых живут в одном городе.
57) Определить для каждого штата минимальную, максимальную и среднюю цену книг авторов,
проживающих в одном штате (кроме штата Калифорния).
58) Определить, какие авторы опубликовали какие книги в США по традиционной кулинарии или в
Германии по компьютерам.
59) Найти цену самой дешевой книги (книг), вышедшей в США. В запросе использовать операцию
группирования.
60) Найти авторов самых дорогих книг, вышедших в США. В запросе использовать подзапрос и
операцию группирования.
61) Найти авторов, у которых вышли самые не распродаваемые книги.
62) Найти цену самой дорогой книги (книг), вышедшей в США. В запросе использовать подзапрос.
63) Определить число книг по компьютерам, выпущенных каждым издательством.
64) Определить авторов из городов, начинающихся с букв "A", "B" или "C" или имеющих в своем
составе слово "Salt", и написавших книги, в названии которых есть определенный или неопределенный
артикль английского языка.
65) Определить города и штаты проживания авторов и издателей, за исключением городов и штатов их
совместного проживания. (В запросе неявно реализуется операция симметрической разности).
66) Определить названия и цену самых дешевых книг, вышедших в США. (Самые дешевые книги имеют
минимальную цену).
67) Определить издательство, в котором опубликовано меньше всего книг.
68) Найти книги, цена которых меньше цены каждой из книг по традиционной кулинарии.
69) Определить местонахождение издательств, цена каждой книги которых меньше 22 долларов. В
запросе использовать подзапросы и предикат с квантором.
70) Определить штаты (кроме штатов Индиана, Канзас, Юта), в которых сумма цен выпущенных в них
книг больше суммы цен книг, выпущенных в городе Вашингтон.
71) Найти издательство, выпустившее свою самую дорогую книгу с наиболее низкой ценой среди всех
издательств. В запросе использовать подзапрос, определяющий максимальные цены книг, выпущенные
каждым издательством.
72) Определить полную информацию об издателях книг по компьютерам, авторы которых живут в США
(за исключением штата Юта). В запросе использовать подзапросы.
73) Определить книги, стоимости которых составляют не более средней стоимости по издательству, где
издавались эти книги.
74) Определить для каждого штата число находящихся в нем издательств.
75) Определить число городов, в которых выпускается литература по компьютерам. В запросе
использовать подзапрос.
76) Определить авторов, хотя бы одна книга которых была опубликована в штате Массачусетс. В
запросе использовать подзапросы и предикат с квантором.
77) Найти издательства, среди изданных книг которых найдется хоть одна книга по компьютерам
стоимостью более двух долларов. В запросе использовать подзапрос и предикат с квантором.
78) Определить штаты, во всех издательствах которых все изданные книги имеют цену более 10
долларов. В запросе использовать подзапросы и предикат с квантором.
79) Определить издательства, для каждой книги которых выполняется условие: “Если книга выпущена в
данном издательстве, то хотя бы один из авторов книги проживает в штате, в котором находится
издательство, некоторые выпущенные книги которого посвящены компьютерам”.
80) Выбрать все столбцы таблицы titles.
81) Выбрать все столбцы декартова произведения таблиц titles и publishers.
82) Определить книги, число продаж для которых неопределено.
83) Определить минимальную и максимальную цену книг, выпущенных издательствами.
84) Определить авторов, хотя бы одна книга которых была опубликована в штате Массачусетс. В
запросе не использовать предикаты с квантором.
85) Найти издательства, среди изданных книг которых найдется хоть одна книга по традиционной
кулинарии стоимостью от 12 до 16 долларов. В запросе не использовать предикаты с квантором.
86) Определить для каждого издательства число изданных им дешевых книг (ценой менее 13 долларов).
87) Определить для штатов число издательств, в которых выпускаются только книги ценой более 7
долларов. В запросе использовать подзапросы и предикат с квантором.
88) Определить, сколько авторов имеет каждая изданная книга.
89) Определить штаты и число находящихся в них издательств, выпустивших книги.
90) Определить издательства, не выпустившие книг.
91) Определить неопубликованные в издательствах книги.
92) Определить авторов, работающих по контракту и имеющих телефон с кодом города 415 (первые три
цифры номера телефона).
93) Определить номера телефонов авторов, проживающих на Седьмой Авеню (Seventh Av.)
94) Определить книги, выпущенные в период с 1 июля 1991 г. по 30 октября 1991 г. (По умолчанию
сервер работает с датами в формате xx/yy/zz как с последовательностями месяц/день/год).
95) Вычислить для каждого типа книг среднее арифметическое минимальной и максимальной цены.
Результат упорядочить по убыванию значений.
96) Определить временные интервалы, в рамках которых опубликованы книги разных типов.
Примечания: 1. При упорядочении фамилий и имен авторов, городов, штатов, типов книг используется
лексикографический порядок.2. “Издатель” и “издательство” являются в данном случае синонимами.
Соответственно этому синонимами являются “имя издателя” и “название издательства”.
Варианты лабораторных заданий
Номер варианта
Задание типа A
Задание типа B
1
1, 25, 49, 81
24, 48, 72, 96
2
2, 26, 50, 63
23, 47, 71, 95
3
3, 27, 51, 64
22, 46, 70, 94
4
4, 28, 46, 65
21, 45, 69, 93
5
5, 29, 57, 84
20, 44, 68, 92
6
6, 30, 58, 83
19, 43, 67, 91
7
7, 31, 55, 79
18, 42, 66, 90
8
8, 32, 56, 80
17, 41, 65, 89
9
9, 33, 57, 81
16, 40, 64, 88
10
10, 34, 58, 82
15, 39, 63, 87
11
11, 35, 59, 83
13, 37, 61, 85
12
12, 36, 60, 84
14, 38, 62, 86
13
13, 37, 61, 85
12, 36, 60, 84
14
14, 38, 62, 86
11, 35, 59, 83
15
15, 39, 63, 87
10, 34, 58, 82
16
16, 40, 64, 88
9, 33, 57, 81
17
17, 41, 65, 89
8, 32, 56, 80
18
18, 42, 66, 90
7, 31, 55, 79
19
19, 43, 67, 91
6, 30, 58, 83
20
20, 44, 68, 92
5, 29, 57, 84
21
21, 45, 69, 93
4, 28, 46, 65
22
22, 46, 70, 94
3, 27, 51, 64
23
23, 47, 71, 95
2, 26, 50, 63
24
24, 48, 72, 96
1, 25, 49, 81
Лабораторная работа N 2
Тема: Создание, модификация и удаление объектов базы данных с использованием SQL
Цель работы: изучить языки определения и манипулирования данными SQL, получить
практические навыки составления SQL-запросов для работы с таблицами, индексами,
представлениями и курсорами, а также их выполнения на SQL-сервере с использованием
клиентских утилит.
Порядок выполнения работы
Изучение языка баз данных
1. Изучить язык определения данных SQL, включая операторы создания таблиц (CREATE
TABLE), создания представлений (CREATE VIEW), модификации таблиц (ALTER TABLE),
удаления таблиц (DROP TABLE), удаления представлений (DROP VIEW), а также операторы
создания индексов (CREATE INDEX) и удаления индексов (DROP INDEX). Изучить типы
ограничений и способы их представления на языке SQL.
2. Изучить операторы манипулирования данными, связанные с курсором, включая оператор
объявления курсора (DECLARE CURSOR), оператор открытия курсора (OPEN), оператор
чтения очередной строки курсора (FETCH), оператор позиционного удаления (DELETE),
оператор позиционной модификации (UPDATE), оператор закрытия курсора (CLOSE).
3. Изучить одиночные операторы манипулирования данными, включая) операторы поискового
удаления (DELETE) и поисковой модификации (UPDATE), а также оператор включения
(INSERT).
4. Изучить интегрированную утилиту SQL Enterprise Manager, а также системные хранимые
процедуры с точки зрения их использования для просмотра объектов базы данных, создания и
удаления таблиц. В частности, изучить работу с системной хранимой процедурой sp_help,
используемой для получения информации о базе данных и объектах базы данных.
Работа непосредственно с таблицей
1. В соответствии с вариантом задания разработать точную структуру строк (записей) таблицы,
включая выбор типов данных для каждого поля строки.
2. Составить оператор создания таблицы с учетом приведенных в задании ограничений,
выполнить данный оператор на SQL-сервере с использованием клиентской утилиты.
Просмотреть результат выполнения данного оператора с помощью системной хранимой
процедуры sp_help или клиентской утилиты SQL-EM.
3. Заполнить созданную таблицу данными с использованием оператора включения.
Просмотреть заполненную таблицу.
4. Изменить одну или несколько строк таблицы с использованием оператора поисковой
модификации. Просмотреть измененную таблицу.
5. Удалить одну или несколько строк из таблицы с использованием оператора поискового
удаления. Просмотреть измененную таблицу.
6. Добавить столбец в таблицу с использованием оператора модификации таблицы.
Просмотреть измененную таблицу.
7. Удалить ограничение из таблицы с использованием оператора модификации таблицы.
Просмотреть результат выполнения оператора.
Работа с курсором
1. Объявить скроллируемый курсор в соответствии со спецификацией курсора из
лабораторного задания.
2. Открыть курсор.
3. Просмотреть первую, j-ю и последнюю строки результирующей таблицы, а также
последовательно всю результирующую таблицу от начала и до конца и от конца до начала
(число j задается преподавателем).
4. Удалить n-ю строку результирующей таблицы с использованием оператора позиционного
удаления (число n задается преподавателем). Просмотреть базовую таблицу и сравнить ее c
предыдущим вариантом.
5. Модифицировать k-ю строку результирующей таблицы, изменив значение одного или
нескольких полей, с использованием оператора позиционной модификации (число k задается
преподавателем). Просмотреть базовую таблицу и сравнить ее c предыдущим вариантом.
6. Закрыть курсор.
Работа с представлением
1. В соответствии с заданием составить оператор создания представления, выполнить данный
оператор на SQL-сервере с использованием клиентской утилиты. Просмотреть результат
выполнения данного оператора с помощью системной хранимой процедуры sp_help или
клиентской утилиты SQL-EM. Просмотреть представляемую таблицу.
2. Включить несколько записей в представляемую таблицу с использованием оператора
включения. Просмотреть представляемую и базовую таблицы и сравнить их с предыдущими
вариантами этих таблиц.
3. Изменить несколько строк представляемой таблицы с использованием оператора поисковой
модификации. Просмотреть представляемую и базовую таблицы и сравнить их с предыдущими
вариантами этих таблиц.
4. Удалить несколько строк из представляемой таблицы с использованием оператора
поискового удаления. Просмотреть представляемую и базовую таблицы и сравнить их с
предыдущими вариантами этих таблиц.
5. Удалить представление с использованием оператора удаления представления.
Работа с индексами
1. Создать индекс, который бы позволял быстрый поиск по первичному ключу, содержащему
столбцы уникальности.
2. Составить и выполнить какой-нибудь запрос к индексированной таблице.
3. Удалить индекс.
4. Удалить базовую таблицу с использованием оператора удаления таблицы.
Содержание отчета
1. Задание;
Операторы создания и удаления таблицы;
Операторы создания и удаления представления;
Операторы объявления и закрытия курсора;
Операторы создания и удаления индекса;
Операторы манипулирования данными, относящиеся к базовой, представляемой и
результирующей таблицам;
7. Исходная базовая таблица;
8. Исходная представляемая таблица;
9. Исходная результирующая таблица курсора;
10. Измененные таблицы (базовая, представляемая и результирующая) и ссылки на
соответствующие им операторы изменения таблиц (для каждого акта изменения).
2.
3.
4.
5.
6.
Типы данных Transact-SQL
Символьные типы данных
CHAR[(n)] - cтроки фиксированной длины, где n - число символов в строке;
VARCHAR[(n)] - строки переменной длины , где n - максимальное число символов в
строке;
TEXT - строки потенциально неограниченного размера (до 2 Гб текста в строке).
В данном случае 1? n? 255. Символьные столбцы, допускающие пустые значения (NULL),
хранятся как столбцы переменной длины.
Примеры определений столбцов и типов данных:
name VARCHAR(40)
state CHAR(2)
description CHAR(50) NULL
Двоичные типы данных
BINARY(n) - двоичные строки фиксированной длины, где n - число двоичных символов
в строке;
VARBINARY(n) - двоичные строки переменной длины, где n - максимальное число
двоичных символов в строке;
IMAGE - большие двоичные строки (изображения до 2 Гб в строке).
В данном случае 1? n? 255.
Пример задания двоичного столбца:
bin_column BINARY(4) NOT NULL
Типы данных даты
SQL Server поддерживает два типа обозначения даты и времени при хранении: DATETIME и
SMALLDATETIME. Последний менее точный и охватывает меньший диапазон дат, но зато
позволяет экономить место на диске.
SQL Server поддерживает различные форматы ввода даты. По умолчанию он работает с датами
в формате xx/yy/zz как с последовательностями месяц/день/год. Точность представления
времени при использовании DATETIME - 3 миллисекунды, а при использовании
SMALLDATETIME - 1 минута. Пример:
Формат ввода: 4/15/99
Значение DATETIME: Apr 15 1999 12:00:00:000 AM
Значение SMALLDATETIME: Apr 15 1999 12:00 AM
Логический тип данных
SQL Server поддерживает логический тип данных BIT для столбцов флагов, имеющих значение
1 или 0.
Числовые типы данных
Числовые типы данных разбиваются на четыре основные категории:
целые, включающие INT, SMALLINT и TINYINT.
данные с плавающей точкой, включающие FLOAT и REAL.
данные с фиксированной точкой - NUMERIC и DECIMAL
денежные типы данных - MONEY и SMALLMONEY.
Целые типы данных
Характеристика
INT
Минимальное значение
-2
SMALLINT
0
Максимальное значение
Объем памяти
TINYINT
255
4 байта
2 байта
1 байт
Типы данных с плавающей точкой
Характеристика
FLOAT
REAL
Минимальное значение
± 2.23E-308
± 1.18E-38
Максимальное значение
± 1.79E308
± 3.40E38
Точность
до 15 значащих цифр
до 7 значащих цифр
Объем памяти
8 байтов
4 байта
Спецификатор типа FLOAT имеет вид FLOAT[(p)], где p - точность.
Точные числовые типы данных
Эти типы данных вводится описателями DECIMAL[(p,s)] и NUMERIC[(p,s)], где p - точность, s
- масштаб. Они являются синонимами и взаимозаменяемы, но только NUMERIC может
использоваться в комбинации со столбцами IDENTITY. Точность - это число значащих цифр,
масштаб - число цифр после десятичной точки.
Пример: NUMERIC(7,2).
Если опущен масштаб, то он полагается равным нулю, а если опущена точность, то ее значение
по умолчанию определяется в реализации.
Денежные типы данных
Характеристика
MONEY
SMALLMONEY
Диапазон
922337203685477.5808
214748.3647
Размер памяти
8 байтов
4 байта
Создание таблицы
Оператор создания таблицы имеет следующий синтаксис:
<оператор создания таблицы>::= CREATE TABLE <имя таблицы> (<элемент
таблицы>[{,<элемент таблицы>}...])
<элемент таблицы>::=<определение столбца> | <определение ограничения целостности>
Каждая таблица БД имеет простое и квалифицированное (уточненное) имена. В качестве
квалификатора имени выступает “идентификатор полномочий”.
Квалифицированное имя таблицы имеет вид: <идентификатор полномочий>.<простое имя>
Определение столбца
<определение столбца>::= <имя столбца><тип данных>[<раздел умолчания>]
[{<ограничение целостности столбца>}...]
<раздел умолчания>::= DEFAULT {<литерал> | USER | NULL}
<ограничение целостности столбца>::= NOT NULL[<спецификация уникальности>] |
<спецификация ссылок> | CHECK (<условие поиска>)
В разделе умолчания указывается значение, которое должно быть помещено в строку,
заносимую в данную таблицу, если значение данного столбца явно не указано. Значение по
умолчанию может быть: 1) литеральная константа, соответствующая типу столбца; 2)
символьная строка, содержащая имя текущего пользователя (USER); 3) неопределенное
значение (NULL).
Если значение столбца по умолчанию не специфицировано, и в разделе ограничений
целостности столбца указано NOT NULL (т.е. наличие неопределенных значений запрещено),
то попытка занести в таблицу строку с неспецифицированным значением данного столбца
приведет к ошибке.
Если ограничение NOT NULL не указано, и раздел умолчаний отсутствует, то неявно
порождается раздел умолчаний DEFAULT NULL.
Ограничения целостности столбца в принципе сходны с ограничениями целостности таблицы и
рассмотрены ниже.
Определение ограничений целостности таблицы
Синтаксис для определения ограничений целостности таблицы представлен следующими
правилами:
<определение ограничений целостности таблицы>::= <определение ограничения
уникальности> | <определение ограничения по ссылкам> | <определение проверочного
ограничения>
<определение ограничения уникальности>::=<спецификация уникальности>(<список
столбцов>)
<спецификация уникальности>::= UNIQUE | PRIMARY KEY
<список столбцов>::= <имя столбца>[{,<имя столбца>}..]
<определение ограничения по ссылкам>::= FOREIGN KEY (<ссылающиеся
столбцы>)<спецификация ссылок>
<спецификация ссылок>::== REFERENCES <ссылаемая таблица и столбцы>
<ссылаемая таблица и столбцы>::=<имя таблицы>[(<список столбцов>)]
<определение проверочного ограничения>::= CHECK (<условие поиска>)
Действие ограничения уникальности состоит в том, что в таблице не допускается появление
двух или более строк, значения столбцов уникальности которых совпадают. Среди ограничений
уникальности таблицы не должно быть более одного определения первичного ключа
(ограничения уникальности с ключевым словом PRIMARY KEY).
Ограничения по ссылкам в данной работе не используются, и поэтому подробно не
рассматриваются.
Проверочное ограничение специфицирует условие, которому должен удовлетворять в
отдельности каждая строка таблицы. Это условие не должно содержать подзапросов,
спецификаций агрегатных функций, а также ссылок на внешние переменные или параметров. В
него могут входить только имена столбцов данной таблицы и литеральные константы.
Примеры создания таблиц с ограничениями:
CREATE TABLE employee
(emp_id INTEGER CONSRAINT p1 PRIMARY KEY,
fname CHAR(20) NOT NULL,
minitial CHAR(1) NULL,
lname VARCHAR(30) NOT NULL,
job_id SMALLINT NOT NULL DEFAULT 1
REFERENCES jobs(job_id)
CREATE TABLE inventory
(code CHAR(4) NOT NULL
CONSTRAINT c1 CHECK(code LIKE"[0-9][0-9][0-9][0-9]"),
high INT NOT NULL CHECK (high>0),
low INT NOT NULL CHECK (low>0),
CONSTRAIN c4 CHECK (hign>=low AND high-low<1000)
Изменение таблиц
Для изменения таблицы, а именно: для включения новых столбцов и ограничений, а также
удаления ограничений, используется оператор ALTER TABLE, имеющий следующий
синтаксис:
<оператор изменения таблицы>::= ALTER TABLE <имя таблицы> {ADD <элемент
таблицы>[{,<элемент таблицы>}...] | DROP CONSTRAINT <имя ограничения>[{,<имя
ограничения>}...]}
Пример включения нового столбца в таблицу:
ALTER TABLE names2 ADD middle_name VARCHAR(20) NULL, fax VARCHAR(15) NULL
Создание представлений
Представление — это виртуальная таблица, которая сама по себе не существует, но для
пользователя выглядит таким образом, как будто она существует. Представление не
поддерживаются его собственными физическими хранимыми данными. Вместо этого в каталоге
таблиц хранится определение, оговаривающее, из каких столбцов и строк других таблиц оно
должно быть сформировано при реализации SQL-предложения на получение данных из
представления или на модификацию таких данных.
Синтаксис предложения CREATE VIEW имеет вид:
CREATE VIEW имя_представления
[(столбец[,столбец] ...)]
AS подзапрос
[WITH CHECK OPTION];
где
■ подзапрос, следующий за AS и являющийся определением данного представления, не
исполняется, а просто сохраняется в каталоге;
■ необязательная фраза “WITH CHECK OPTION” (с проверкой) указывает, что для операций
INSERT и UPDATE над этим представлением должна осуществляться проверка,
обеспечивающая удовлетворение WHERE фразы подзапроса;
■ список имен столбцов должен быть обязательно определен лишь в тех случаях, когда:
■ хотя бы один из столбцов подзапроса не имеет имени (создается с помощью выражения, SQLфункции или константы);
■ два или более столбцов подзапроса имеют одно и то же имя;
■ если же список отсутствует, то представление наследует имена столбцов из подзапроса.
Например, создадим представление Мясные_блюда:
CREATE VIEW Мясные_блюда
AS SELECT БЛ, Блюдо, В, Выход
FROM Блюда
WHERE Основа = 'Мясо';
которое может рассматриваться пользователем как новая таблица в базе данных.
Уничтожение ненужных представлений выполняется с помощью предложения DROP VIEW
(уничтожить представление), имеющего следующий формат:
DROP VIEW представление;
Операции выборки из представлений
Создав представление Мясные_блюда пользователь может считать, что в базе данных реально
существует такая таблица и дать, например, запрос на получение из нее всех данных:
SELECT *
FROM Мясные_блюда;
результат которого имеет вид:
БЛ Блюдо В Выход
2 Салат мясной З 200
6 Мясо с гарниром З 250
9 Суп харчо С 500
13 Бастурма Г 300
14 Бефстроганов Г 210
Поскольку при определении представления может быть использован любой допустимый
подзапрос, то выборка данных может осуществляться как из базовых таблиц, так и из
представлений:
CREATE VIEW Горячие_мясные_блюда
AS SELECT Блюдо, Продукт, Вес
FROM Мясные_блюда, Состав, Продукты
WHERE Мясные_блюда.БЛ = Состав.БЛ
AND Продукты.ПР = Состав.ПР
AND В = 'Г';
Если теперь возникла необходимость получить сведения о горячих мясных блюдах, в состав
которых входят помидоры, то можно сформировать запрос:
SELECT Блюдо, Продукт, Вес
FROM Горячие_мясные_блюда
WHERE Блюдо IN
( SELECT Блюдо
FROM Горячие_мясные_блюда
WHERE Продукт = 'Помидоры')
и получить:
Блюдо Продукт Вес
Бастурма Говядина 180
Бастурма Помидоры 100
Бастурма Лук 40
Бастурма Зелень 20
Бастурма Масло 5
Легко заметить, что данный запрос, осуществляющий выбор данных через два представления,
выглядит для пользователя точно так же, как обычный SELECT, оперирующий обычной
базовой таблицей. Однако СУБД преобразует его при выполнении в эквивалентную операцию
над лежащими в основе базовыми таблицами (перед выполнением проводит слияние выданного
пользователем SELECT с предложениями SELECT из описаний представлений, хранящихся в
каталоге).
Обновление представлений
Рассмотренные ранее операции DELETE, INSERT и UPDATE могут оперировать не только
базовыми таблицами, но и представлениями. Однако, если из базовых таблиц можно удалять
любые строки, обновлять значения любых их столбцов и вводить в такие таблицы новые
строки, то этого нельзя сказать о представлениях, не все из которых являются обновляемыми.
Безусловно обновляемыми являются представления, полученные из единственной базовой
таблицы простым исключением некоторых ее строк и (или) столбцов, обычно называемые
“представление-подмножество строк и столбцов”. Таким является представление
Мясные_блюда, полученное из базовой таблицы Блюда исключением из нее столбца Труд и
строк, не содержащих значение 'Мясо' в столбце Основа. Работая с ним, можно:
■ вставить (операция INSERT) новую строку, например, строку (34, 'Шашлык', 'Г', 150),
фактически вставляя соответствующую строку (34, 'Шашлык', 'Г', 150, NULL) в лежащую в
основе базовую таблицу Блюда;
■ удалить (операция DELETE) существующую строку из представления, например строку (13,
'Бастурма', 'Г', 300), фактически удаляя соответствующую строку (13, 'Бастурма', 'Г', 300, 5) из
таблицы Блюда;
■ обновить (операция UPDATE) какое-либо поле в существующей строке, например увеличить
массу порции Бефстроганова с 210 до 250 граммов, фактически осуществляя то же самое
изменение в соответствующем поле таблицы Блюда.
Однако если бы представление Мясные_блюда имело вместо столбца Выход столбец
Вых_труд, полученный путем суммирования значений столбцов Выход и Труд таблицы Блюда,
то указанные выше операции INSERT и UPDATE были бы отвергнуты системой.
Действительно, как распределить вводимое значение столбца Вых_труд (153 или 254) между
значениями столбцов Выход и Труд базовой таблицы Блюда? Была бы отвергнута и операция
удаления масла из состава бастурмы, если бы ее попытались выполнить путем удаления строки
('Бастурма', 'Масло', 5) в представлении Горячие_мясные_блюда.
Встает множество вопросов:
■ надо ли удалять из базовой таблицы Блюда строку, содержащую значение 'Бастурма' в
столбце Блюдо?
■ надо ли удалять из базовой таблицы Продукты строку, содержащую значение 'Масло' в
столбце Продукт?
■ надо ли удалять из базовой таблицы Состав все строки, содержащие значение 5 в столбце
Вес?
Последний вопрос возник потому, что при конструировании представления
Горячие_мясные_блюда в него не была включена информация о связях между лежащими в его
основе базовыми таблицами Блюда, Состав и Продукты, и у системы нет прямых путей для
поиска той единственной строки таблицы Состав, которая должна быть удалена.
Таким образом, некоторые представления по своей природе обновляемы, в то время как другие
таковыми не являются. Здесь следует обратить внимание на слова “по своей природе”. Дело
заключается не просто в том, что некоторая СУБД не способна поддерживать определенные
обновления, в то время как другие СУБД могут это делать. Никакая СУБД не может
непротиворечивым образом поддерживать без дополнительной помощи обновление такого
представления как Горячие_мясные_блюда. “Без дополнительной помощи” означает здесь “без
помощи какого-либо человека — пользователя”. Как было указано выше, к теоретически
обновляемым представлениям относятся представления-подмножества строк и столбцов.
Однако существуют некоторые представления, которые не являются представлениямиподмножествами строк и столбцов, но также теоретически обновляемы. Хотя известно, что
такие есть и можно привести их примеры, но невозможно дать их формального определения.
Неверным является такое формальное определение некоторых авторов — “нельзя обновлять
соединение”.
Во-первых, в некоторых соединениях с успехом выполняется операция UPDATE, а, во-вторых,
как было показано выше, не обновляемы и некоторые представления, не являющиеся
соединениями. Кроме того, не все СУБД поддерживают обновление любых теоретически
обновляемых представлений. Поэтому пользователь должен сам оценивать возможность
использования операций DELETE, INSERT или UPDATE в созданном им представлении.
Для чего нужны представления
Одна из основных задач, которую позволяют решать представления, — обеспечение
независимости пользовательских программ от изменения логической структуры базы данных
при ее расширении и (или) изменении размещения столбцов, возникающего, например, при
расщеплении таблиц. В последнем случае можно создать представление-соединение с именем и
структурой расщепленной таблицы, позволяющее сохранить программы, существовавшие до
изменения структуры базы данных.
Кроме того, представления дают возможность различным пользователям по-разному видеть
одни и те же данные, возможно, даже в одно и то же время. Это особенно ценно при работе
различных категорий пользователей с единой интегрированной базой данных. Пользователям
предоставляют только интересующие их данные в наиболее удобной для них форме (окно в
таблицу или в любое соединение любых таблиц).
Наконец, от определенных пользователей могут быть скрыты некоторые данные, невидимые
через предложенное им представление. Таким образом, принуждение пользователя
осуществлять доступ к базе данных через представления является простым, но эффективным
механизмом для управления санкционированием доступа.
Механизм представлений является мощным средством языка SQL, позволяющим скрыть
реальную структуру БД от некоторых пользователей за счет определения представления БД.
Представление реально является некоторым хранимым в БД запросом с именованными
столбцами, а для пользователя ничем не отличается от базовой таблицы БД. Представляемая
таблица является виртуальной. Обычно вычисление представляемой таблицы производится
каждый раз при использовании представления.
Оператор определения представления имеет следующий синтаксис:
<оператор создания представления>::= CREATE VIEW <имя таблицы>[(список столбцов)]
AS <спецификация запроса> [WITH CHECK OPTION]
<спецификация запроса>::= SELECT [ALL | DISTINCT] <список выборки><табличное
выражение>
<список столбцов>::=<имя столбца>[{,<имя столбца>}...]
Требование WITH CHECK OPTION имеет смысл только в случае определения изменяемой
представляемой таблицы, которая определяется спецификацией запроса, содержащей раздел
WHERE. При наличии этого требования не допускаются изменения представляемой таблицы,
приводящие к появлению в базовых таблицах строк, не видимых в представляемой таблице.
Операторы, связанные с курсором
Курсор — это сущность, устанавливающая соответствие с результирующим набором
указывающая на одну из его строк. После позиционирования курсора на некоторой строке над
этой строкой или над блоком, который начинается с этой позиции, можно выполнять
различные действия.
Курсор - это механизм языка SQL, предназначенный для того, чтобы позволить прикладной
программе последовательно, строка за строкой, просмотреть результат связанного с курсором
запроса. Курсор можно представить как “буфер” с указателем на текущую строку.
В реляционных базах данных операции выполняются над наборами строк. Оператор
SELECT возвращает набор, который состоит из всех строк, соответствующих заданному
конструкции WHERE условию. Полный набор строк, который возвращает оператор,
называется результирующим набором. Приложения, особенно интерактивные, не всегда
могут эффективно работать с результирующим набором как с единым целым. Для эти
приложений необходим механизм, позволяющий им работать с небольшими блок ам строк.
Такой механизм реализован в виде курсоров.
Курсоры расширяют возможности обработки результатов, обеспечивая поддержку еле дующих
функций:
• позиционирование на определенных строках результирующего набора;
• извлечение одной строки или блока строк от текущей позиции курсора в
результирующем наборе;
• поддержку модификации данных в строке, на которой в текущий момент
позиционирован курсор в результирующем наборе;
• поддержку различных уровней видимости для изменений, которые вносят другие
пользователи в данные результирующего набора;
• предоставление доступа к данным результирующего набора операторам Transact-SQL
составе сценариев, хранимых процедур и триггеров.
SQL Server поддерживает три типа курсоров:
• серверные курсоры Transact-SQL
• серверные курсоры API
• клиентские курсоры.
Поскольку первые два вида курсоров реализованы на сервере, их в совокупности называют
серверными курсорами.
Не следует смешивать использование курсоров различных типов. При исполнении операторов
DECLARE CURSOR и OPEN из приложения сначала необходимо установит значения по
умолчанию для атрибутов курсора API. Если установить для атрибутов курсоpa API значения,
отличные от заданных по умолчанию, а затем исполнить оператор! DECLARE CURSOR и
OPEN, то SQL Server установит соответствие курсора API и курс» pa Transact-SQL. В
частности, не следует задавать значения атрибутов ODBC, которые (устанавливают
соответствие результирующего набора и курсора, управляемого набором ключей, а затем с
помощью описателя этого оператора исполнять операторы DECLARE CURSOR и OPEN,
вызывающие курсор INSENSITIVE.
Недостатком серверных курсоров можно считать, что они поддерживают не все операторы
Transact-SQL. Серверные курсоры не поддерживают операторы Transact-SQL, которые
генерируют несколько результирующих наборов; поэтому их нельзя использовать при
исполнении приложением хранимой процедуры или пакета, где имеется несколько операторов SELECT. Серверные курсоры также не поддерживают операторы SQL с ключевыми
словами COMPUTE, COMPUTE BY, FOR BROWSE или INTO.
Ниже приводится синтаксис операторов, связанных с курсором и их краткая характеристика.
<оператор объявления курсора>::= DECLARE <имя курсора> [SCROLL] CURSOR FOR
<спецификация курсора>
<спецификация курсора>::= SELECT [ALL | DISTINCT] <список выборки> <табличное
выражение>[ORDER BY <спецификация сортировки>]
Этот оператор не является выполняемым, он только связывает имя курсора со спецификацией
курсора. Если задан описатель SCROLL, то курсор является “скроллируемым”, то есть
допускает прокрутку результирующей таблицы как вниз, так и вверх на любое число строк.
<оператор открытия курсора>::= OPEN <имя курсора>
Оператор открытия курсора должен быть первым в серии выполняемых операторов, связанных
с данным курсором. Можно считать, что во время выполнения оператора открытия курсора
производится построение временной таблицы, содержащей результат запроса, который связан с
этим курсором.
<оператор чтения>::= FETCH <имя курсора> INTO <список спецификаций целей>
<список спецификаций целей>::= <спецификация цели>[{,<спецификация цели>}..]
Данный оператор устанавливает курсор на следующую строку таблицы и выбирает значения из
этой строки.
<оператор позиционного удаления>::= DELETE FROM <имя таблицы> WHERE CURRENT OF
<имя курсора>
Данный оператор удаляет строку таблицы. Изменяемая таблица, указанная в разделе FROM
оператора DELETE, должна быть таблицей, указанной в самом внешнем разделе FROM
спецификации курсора.
<оператор позиционной модификации>::= UPDATE <имя таблицы> SET <предложение
установки> [{,<предложение установки>}...] WHERE CURRENT OF <имя курсора>
<предложение установки>::= <имя столбца> = {<арифметическое выражение> | NULL}
Данный оператор изменяет значение полей строки таблицы, определенной курсором, в
соответствии с предложениями установки.
<оператор закрытия курсора>::= CLOSE <имя курсора>
Примеры работы с курсором:
DECLARE mycursor SCROLL CURSOR FOR
SELECT au_lname FROM authors
OPEN mycursor
FETCH FIRST FROM mycursor /* первая строка */
FETCH ABSOLUTE 10 FROM mycursor
FETCH NEXT FROM mycursor /* следующая строка */
FETCH RELATIVE 2 FROM mycursor
FETCH PRIOR FROM mycursor /* предыдущая строка */
FETCH LAST FROM mycursor /* последняя строка */
CLOSE mycursor
Одиночные операторы манипулирования данными
Каждый из операторов этой группы является абсолютно независимым от другого оператора.
<оператор выборки>::= SELECT [ALL | DISTINCT] <список выборки> [INTO <список
спецификаций целей>]<табличное выражение>
Результатом выполнения оператора выборки является таблица, состоящая не более чем из
одной строки. После выполнения оператора цели содержат соответствующие поля
результирующей строки.
<оператор поискового удаления>::= DELETE FROM <имя таблицы> [WHERE <условие
поиска>]
При выполнении оператора последовательно просматриваются все строки таблицы, и те строки,
для которых результатом вычисления условия поиска является “истина”, удаляются из таблицы.
При отсутствии раздела WHERE удаляются все строки таблицы.
Примеры:
DELETE authors
DELETE titles WHERE type= "business"
<оператор поисковой модификации>::= UPDATE <имя таблицы> SET <предложение
установки >[{,<предложение установки>}…] [WHERE <условие поиска>]
При выполнении оператора просматриваются все строки таблицы, и каждая строка, для которой
результатом вычисления условия поиска является “истина”, изменяется в соответствии с
разделом SET.
Пример:
UPDATE publishers SET pub_name= "Joe’s Press" WHERE pub_id= "1234"
<оператор включения>::= INSERT INTO <имя таблицы>[(<список столбцов>)] {VALUES
(<список значений >) | <подзапрос>}
Оператор включения добавляет строку в таблицу. При это строка формируется или из списка
значений раздела VALUES, или вычисляется с помощью подзапроса. Список столбцов
определяет те столбцы, для которых явно будет указано их значение. Причем i-му столбцу в
списке столбцов соответствует i-ое значение из списка значений или i-я строка результата
подзапроса. Если список столбцов опущен, то для каждого столбца таблицы должно быть точно
указаны (или вычислены) значения, в порядке, в котором они были определены.
При вставке символьных данных или поиске значения в конструкции WHERE значение
необходимо передавать в одиночных или двойных кавычках. Для вставки в столбец двоичных
данных их нужно указывать без кавычек, начиная с 0х и задавая два шестнадцатеричных
символа для каждого байта данных.
Примеры:
INSERT INTO publishers (pub_id, pub_name, cite, state) VALUES (‘1234’, ‘Stendahl Publishing’,
‘Paris’, ‘France’)
INSERT INTO binary_example(id, bin_column) VALUES(19, 0xa134e2ff)
Создание индекса
О индексах и производительности
Для ускорения поиска данных можно создавать индексы.
Индекс — это системная таблица, построенная по значениям заданного столбца заданной
таблицы. В нем размещается перечень уникальных значений указанного столбца таблицы со
ссылками на те ее строки, где встречаются эти значения (структура, похожая на предметный
указатель книги). Например, индекс, построенный для столбца Основа таблицы Блюда, будет
содержать следующие сведения:
Значения столбца Строки, в которых встречается такое значение
Кофе 32 33
Крупа 20 21
Молоко 7 8 12 18 22 24 28 31
Мясо 2 6 9 13 14
Овощи 1 3 17 23 15
Рыба 4 5 10 11
Фрукты 25 26 27 29 30
Яйца 16 19
Отметим, что такой индекс уже существовал (в несколько иной форме) в базе данных, хотя это
обстоятельство никак не повлияло на текст иллюстрационных предложений SELECT, DELETE,
INSERT и UPDATE. SQL намеренно не включает в свои конструкции ссылки на индексы.
Решение о том, использовать или не использовать какой-либо индекс при обработке некоторого
конкретного запроса принимается не пользователем, а оптимизатором СУБД, который
учитывает множество факторов — размер таблиц, тип используемых структур хранения
данных, статистическое распределение данных в таблицах и индексах. Однако чтобы
оптимизатор смог использовать индексы, их нужно построить (чтобы выиграть в лотерею
нужно, по крайней мере, иметь лотерейный билет).
Естественно, что поиск какого-либо значения путем последовательного перебора
неупорядоченных данных будет во много раз медленнее, чем поиск с использованием
упорядоченного списка (индекса). Ясно также, что таблицу можно упорядочить лишь по
данным одного столбца, тогда как поиск часто приходится осуществлять по данным нескольких
столбцов. По нескольким столбцам производится и соединение таблиц. Поэтому, несмотря на
то, что индексы увеличивают объем базы данных, их следует использовать как для отдельных
столбцов таблицы, так и для комбинации нескольких ее столбцов (например, для комбинации:
Фамилия, Имя, Отчество).
Для построения индекса в SQL существует предложение CREATE INDEX (создать индекс),
имеющее формат:
CREATE [UNIQUE] INDEX имя_индекса ON базовая_таблица
(столбец [[ASC] | DESC] [, столбец [[ASC] | DESC]] ...);
где UNIQUE (уникальный) указывает, что никаким двум строкам в индексируемой базовой
таблице не позволяется принимать одно и то же значение для индексируемого столбца (или
комбинации столбцов) в одно и то же время.
Например, индексы для столбцов БЛ и Основа таблицы Блюда создаются с помощью
предложений:
CREATE UNIQUE INDEX Блюда_БЛ ON Блюда (БЛ);
CREATE INDEX Блюда_Основа ON Блюда (Основа);
а индекс для первичного ключа (столбцы БЛ и ПР) таблицы Состав — с помощью
предложения:
CREATE UNIQUE INDEX Состав_БЛ_ПР ON Состав (БЛ, ПР);
В больших (более 1000 строк) таблицах поиск индексированных значений выполняется на
порядок быстрее, чем поиск неиндексированных, а в очень больших таблицах — на два-три
порядка.
Так может быть, если позволяет память, следует построить индексы для всех столбцов всех
таблиц базы данных?
Если база данных не должна модифицироваться, то на этот вопрос можно дать положительный
ответ. Однако при удалении или добавлении строки таблицы должны быть перестроены все
индексы, построенные для ее столбцов, а при изменении значения индексированного столбца
— индекс этого столбца. Когда модифицируется много — несколько сотен (тысяч) строк — и
после модификации каждой строки перестраиваются все ее индексы, время модификации
может быть на порядок (несколько порядков) больше времени модификации строк с
неиндексированными столбцами. Поэтому перед модификацией множества строк таблицы
целесообразно уничтожить индексы ее столбцов, что можно сделать с помощью предложения
DROP INDEX (уничтожить индекс), имеющего следующий формат:
DROP INDEX имя_индекса;
Так как индексы могут создаваться или уничтожаться в любое время, то перед выполнением
запросов целесообразно строить индексы лишь для тех столбцов, которые используются в
WHERE и ORDER BY фразах запроса, а перед модификацией большого числа строк таблиц с
индексированными столбцами эти индексы следует уничтожить.
Индекс представляет собой объект, ускоряюший выполнение запросов. Синтаксис оператора
создания индекса имеет вид:
<оператор создания индекса>::= CREATE [UNIQUE] INDEX <имя индекса> ON <имя
таблицы> (<имя столбца> [ASC | DESC] [{,<имя столбца>[ASC | DESC]}..])
Описатель уникальности UNIQUE указывает, что никаким двум строкам в индексируемой
базовой таблице не позволяется принимать одно и тоже значение для индексируемого столбца
(или комбинации столбцов) в одно и то же время. Описатели ASC и DESC определяют, что
столбец должен быть отсортирован в возрастающем или убывающем порядке в пределах
индекса. В Transact-SQL описатели ASC и DESC не используются.
Удаление объектов базы данных
Для удаления объектов базы данных используются соответствующие операторы, синтаксис
которых представлен ниже.
<оператор удаления таблицы>::= DROP TABLE <имя таблицы>
<оператор удаления представления>::= DROP VIEW <имя представления>
<оператор удаления представления>::= DROP INDEX <имя индекса>
Получение справочной информации об объектах базы данных
Информацию об объектах текущей базы данных можно получить, запустив хранимую
процедуру SP_HELP, выполнив оператор
SP_HELP <имя объекта>
Для объекта-таблицы отображаются: имя собственника таблицы; дата и время ее создания;
имена столбцов таблицы и их типы данных; имена, описания и ключи индексов, связанных с
таблицей; типы, имена и описания ограничений столбцов и таблицы в целом. Без входных
параметров эта процедура возвращает список всех объектов, их собственников и типов
объектов.
Для получения информации только об ограничениях таблицы можно воспользоваться хранимой
процедурой SP_HELPCONSTRAINT, выполнив оператор
SP_HELPCONSTRAINT <имя таблицы>
Для получения информации только об индексах таблицы можно воспользоваться хранимой
процедурой SP_HELPINDEX, выполнив оператор
SP_HELPINDEX <имя таблицы>
Для того, чтобы получить список и описания объектов класса X, определенных в базе данных,
можно выполнить оператор
SELECT * FROM sysobjects WHERE type= ‘X’
Возможные значения параметра X: U - таблица, V - представление, С - проверочное
ограничение, F - ограничение по ссылкам, K - ограничение уникальности, D - раздел
умолчаний.
Варианты заданий
1. Схема таблицы СТУДЕНТ:
идентификатор зачетки
фамилия и инициалы студента
специальность
группа
дата рождения
наличие стипендии (имеется/не имеется)
адрес проживания
средний балл зачетки
Ограничение уникальности: идентификатор зачетки.
Проверочные ограничения: а) Код группы должен иметь следующую структуру:
<цифра><цифра><буква><буква><цифра>; б) средний балл зачетки должен быть в интервале
[2,5].
Спецификация представления: представляемая таблица содержит идентификатор зачетки,
фамилию и инициалы студента, а также средний балл зачетки для студентов, получающих
стипендию.
Спецификация курсора: результирующая таблица включает фамилию и инициалы студента,
группу и адрес проживания для студентов, имеющих средний балл зачетки более 4.5.
2. Схема таблицы ЭКЗАМЕН:
название предмета
фамилия и инициалы студента
фамилия и инициалы преподавателя
должность преподавателя
дата сдачи экзамена
номер аудитории
оценка
сложность предмета
Ограничение уникальности: название предмета, фамилия и инициалы студента.
Проверочные ограничения: а) должность преподавателя должна быть одной из следующего
списка: ассистент, старший преподаватель, доцент, профессор; б) сложность предмета должна
быть в интервале [0,1].
Спецификация представления: представляемая таблица содержит название предмета, фамилию
и инициалы студента, а также экзаменационную оценку для тех экзаменов, которые принимают
профессора.
Спецификация курсора: результирующая таблица включает все сведения об экзаменах, сданных
на оценку “отлично”.
3. Схема таблицы ВОЕННОСЛУЖАЩИЕ:
номер военного билета
фамилия и инициалы
дата рождения
род войск
воинское звание
оклад
рост
вес
номер противогаза
наличие водительских прав (имеются/не имеются)
Ограничение уникальности: номер военного билета.
Проверочные ограничения: а) номер военного билета должен состоять из шести цифр; б) номер
противогаза должен быть цифрой 1,2 или 3.
Спецификация представления: представляемая таблица содержит номер военного билета,
фамилию и инициалы, род войск военнослужащих ростом более 180 см.
Спецификация курсора: результирующая содержит фамилию и инициалы, воинское звание,
номер противогаза военнослужащих, имеющих водительские права.
4. Схема таблицы КОМПЬЮТЕР:
марка компьютера
страна сборки
процессор
объем оперативной памяти
объем внешней памяти
быстродействие
наличие мыши (имеется/не имеется)
марка монитора
цена
дата выпуска
Ограничение уникальности: марка компьютера, страна сборки.
Проверочные ограничения: а) объем оперативной памяти должен быть в интервале [2,128]
Мбайт; б) Дата выпуска должна быть не больше текущей даты.
Спецификация представления: представляемая таблица содержит марку компьютера, страну
сборки и цену для компьютеров, имеющих объем оперативной памяти более 8 Мбайт.
Спецификация курсора: результирующая таблица совпадает с базовой.
5. Схема таблицы УЧЕБНЫЙ ПЛАН:
код специальности
название дисциплины
семестр
дата начала семестра
общее количество часов
наличие курсового проекта (имеется/не имеется)
формы отчетности (экзамены, зачеты и т.д.)
Ограничение уникальности: код специальности, название дисциплины, семестр.
Проверочные ограничения: а) код специальности должен иметь следующую структуру:
<цифра><цифра>.<цифра><цифра>; б) семестр должен быть или осенний или весенний.
Спецификация представления: представляемая таблица содержит код специальности, семестр и
название дисциплин, для которых предусмотрен курсовой проект.
Спецификация курсора: результирующая таблица содержит все сведения о дисциплинах
весеннего семестра.
6. Схема таблицы ПОСТАВКИ ТОВАРОВ:
название фирмы-поставщика
название фирмы-потребителя
товарный кредит (да/нет)
название товара
количество единиц товара
вес единицы товара
цена единицы товара
платежные реквизиты (адрес и номер расчетного счета)
дата отгрузки
Ограничение уникальности: название фирмы-поставщика, название фирмы-потребителя.
Проверочные ограничения: а) поставляемыми товарами являются холодильники, пылесосы и
утюги; б) количество поставляемых единиц товара не должно превышать 100 штук.
Спецификация представления: представляемая таблица содержит сведения о товарах.
Спецификация курсора: результирующая таблица содержит название фирмы-поставщика,
название фирмы-потребителя и название товара для поставок, в которых используется
товарный кредит.
7. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
8. Схема таблицы МАГАЗИН:
код товара
наименование
отдел
дата выпуска
себестоимость
цена
количество
срок годности
Ограничение уникальности: код товара.
Проверочные ограничения: а) код товара имеет следующую структуру:
<цифра><цифра><цифра><буква><буква>;
Спецификация представления: представляемая таблица содержит наименование товара,
количество, цена, дата выпуска.
Спецификация курсора: результирующая таблица содержит код товара, отдел, себестоимость,
срок годности
9. Схема таблицы БИБЛИОТЕКА:
Инвентарный номер книги
Название книги
Тип книги
год издания
автор издания
количество страниц
издательство
Ограничение уникальности: Инвентарный номер книги
Проверочные ограничения: а) Инвентарный номер книги имеет следующую структуру:
<буква><цифра><цифра><цифра><буква>; б) книга может быть следующих типов: научная ,
художественная, учебная.
Спецификация представления: представляемая таблица содержит Инвентарный номер книги,
название издания, автор.
Спецификация курсора: результирующая таблица содержит тип издания, количество страниц и
год издания, издательство.
10. Схема таблицы ФУТБОЛЬНЫЕ КЛУБЫ:
Идентификатор клуба
Название клуба
Тип клуба
Количество игроков
Ведущий тренер
Страна
Город
Год создания клуба
Ограничение уникальности: Идентификатор клуба.
Проверочные ограничения: а) Идентификатор клуба имеет следующую структуру:
<цифра><буква><буква>; б) футбольный клуб может быть следующих типов:
профессиональный, детский, юношеский.
Спецификация представления: представляемая таблица содержит Идентификатор клуба, тип
клуба, ведущего тренера.
Спецификация курсора: результирующая таблица содержит название клуба, количество
игроков, город.
11. Схема таблицы АВТОСАЛОН:
Идентификатор автомобиля
тип (микроавтобус, легковой, грузовой)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: Идентификатор автомобиля
Проверочные ограничения: а) Идентификатор автомобиля имеет следующую структуру:
буква><цифра><цифра><цифра><буква>;
Спецификация представления: представляемая таблица содержит Идентификатор
автомобиля, тип и марку автомобиля, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автомобиля, грузоподъемность
(вместимость) и дату проведения последнего техосмотра для автотранспорта, выпущенного за
последние пять лет.
12. Схема таблицы АПТЕКА
Идентификатор лекарства
тип (антибиотик, анаболик, спазмолитическое, отхаркивающие …)
изготовитель
дата изготовления
срок годности
заболевание
стоимость
цена продажи
Ограничение уникальности: Идентификатор лекарства.
Проверочные ограничения: Идентификатор лекарства имеет следующую структуру:
<буква><цифра><буква><буква>; б) лекарство может быть следующих типов:
антибиотик, анаболик, спазмолитическое, отхаркивающие.
Спецификация представления: представляемая таблица содержит Идентификатор лекарства,
тип и дату изготовления, не потерявшего срока годности.
Спецификация курсора: результирующая таблица содержит тип лекарства, заболевание при
котором его применяют и стоимость.
13. Схема таблицы САЛОН СОТОВОЙ СВЯЗИ:
Идентификатор телефона
марка
номер регистрационный
дата изготовления
часы работы (без подзарядки)
фирма изготовитель
цена
стоимость
Ограничение уникальности: Идентификатор телефона.
Проверочные ограничения: Идентификатор телефона имеет следующую структуру:
<буква><буква><буква>;
Спецификация представления: представляемая таблица содержит идентификатор телефона,
марку, фирма изготовитель.
Спецификация курсора: результирующая таблица содержит марку, регистрационный номер,
часы работы, стоимость.
14. Схема таблицы КОМПЬЮТЕРНЫЙ КЛУБ:
Идентификатор услуги
Наименование услуги
Стоимость (1 час)
Номер ПК
Оператор
дата проведения последнего техосмотра ПК
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: Идентификатор услуги.
Проверочные ограничения: идентификатор услуги имеет следующую структуру:
<буква><буква><буква>;
Спецификация представления: представляемая таблица содержит идентификатор услуги,
номер ПК, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит наименование услуги, стоимость и
номер ПК предоставляемого данную услугу.
15. Схема таблицы КАНЦТОВАРЫ:
номер товара
наименование товара
марку товара
дата изготовления
количество
цена
стоимость
наличие (есть/ нет)
Ограничение уникальности: номер товара.
Проверочные ограничения: номер товара имеет следующую структуру:
<буква><цифра><буква>;
Спецификация представления: представляемая таблица содержит номер товара,
наименование и марку товара, имеющегося в наличии.
Спецификация курсора: результирующая таблица содержит наименование товара, дату
изготовления, количество и стоимость товара.
16. Схема таблицы МЕБЕЛЬНЫЙ САЛОН
номер товара
тип (кухня, спальня, прихожая, детская)
марка
дата изготовления
количество предметов
цена
стоимость
наличие (да/нет)
дерево (дуб, сосна, красное дерево, ламинат)
цвет
Ограничение уникальности: номер товара.
Проверочные ограничения: номер товара имеет следующую структуру: <буква><цифра
><буква>; б) товар может быть следующих типов: кухня, спальня, прихожая, детская.
Спецификация представления: представляемая таблица содержит марку, дерево, цвет, цена.
Спецификация курсора: результирующая таблица содержит тип, дату изготовления,
стоимость(если имеется в наличии) .
17. Схема таблицы ЖЕЛЕЗНОДОРОЖНЫЙ ВОКЗАЛ:
номер поезда
тип (скорый, пассажирский, грузовой)
периодичность
время прибытия
время отправления
количество свободных мест
время в пути
средняя стоимость билета
Ограничение уникальности: номер поезда.
Проверочные ограничения: а) номер поезда имеет следующую структуру:
<цифра><цифра><цифра>; б) поезд может быть следующих типов: скорый,
пассажирский, грузовой.
Спецификация представления: представляемая таблица содержит номер поезда, тип и
периодичность, среднюю стоимость билета.
Спецификация курсора: результирующая таблица содержит номер поезда, время прибытия,
время отправления, количество свободных мест.
18. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
19. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
20. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
21. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
22. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
23. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
24. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
25. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
26. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
27. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
28. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
29. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
30. Схема таблицы АВТОТРАНСПОРТ:
государственный номер
тип (автобус, самосвал, тягач, джип)
марка
год изготовления
грузоподъемность или вместимость
расход горючего на 100 км
пробег к текущему техосмотру
дата проведения последнего техосмотра
успешность техосмотра (положительная/отрицательная)
Ограничение уникальности: государственный номер.
Проверочные ограничения: а) государственный номер имеет следующую структуру:
<буква><цифра><цифра><цифра><буква><буква>; б) автотранспорт может быть следующих
типов: автобус, самосвал, тягач, джип.
Спецификация представления: представляемая таблица содержит государственный номер, тип
и марку автотранспорта, успешно прошедшего техосмотр.
Спецификация курсора: результирующая таблица содержит тип автотранспорта,
грузоподъемность (вместимость) и дату проведения последнего техосмотра для автотранспорта,
выпущенного за последние пять лет.
Лабораторная работа N 3
Тема: Технология ADO
Цель работы: Изучить технологию ADO подключения к БД
В Delphi версий 5,6 и 7 поддерживается технология ADO (ActiveX Data Objects объекты данных, построенные как объекты ActiveX), которая усиленно развивается корпорацией Microsoft. На основе этой технологии созданы соответствующие
компоненты-наборы TADOTable, TADOQuery, TADOStoredProc, повторяющие в
функциональном отношении компоненты TTable, TQuery, TStoredProc, но не
требующие развертывания и настройки BDE на клиентской машине.
Основные особенности использования технологии ADO не зависят от архитектуры БД: эта технология характерна не только для файл-серверных БД, но также и
для клиент-серверных и трехзвенных БД. Однако в этом уроке (и в книге вообще)
мы не будем рассматривать особенности компонентов TADOStoredProc и
TRDSConnection, предназначенных для поддержки соответственно клиент-серверной и трехзвенной архитектур, — если вас интересуют эти вопросы,
обратитесь к документации и/или к встроенной справочной службе.
Основным достоинством технологии ADO является ее естественная ориентация
на создание «облегченного» клиента. В рамках этой технологии на машине разработчика БД устанавливаются базовые объекты MS ADO и соответствующие компоненты Delphi (рис. 9.1), обеспечивающие использование технологии ADO (эти
установки осуществляются автоматически при развертывании Delphi). На машине
сервера данных (это может быть файловый сервер в рамках файл-серверной
технологии или машина с сервером данных — в технологии клиент-сервер) устанавливается так называемый провайдер данных — некоторая надстройка над специальной технологией OLE DB, «понимающая» запросы объектов ADO и «умеющая» переводить эти запросы в нужные действия с данными. Взаимодействие
компонентов ADO и провайдера осуществляется на основе универсальной для
Windows технологии ActiveX, причем провайдер реализуется как СОМ-сервер, а
ADO-компоненты — как СОМ-клиенты.
На машине сервера создается и размещается источник данных. В случае файл-серверных систем отдельные таблицы типа dBASE, FoxPro, Paradox и т. п. должны
управляться соответствующим ODBC-драйвером, а в роли провайдера используется Microsoft OLE DB Provider for ODBC drivers. Если по каким-либо причинам
не найден нужный драйвер, файл-серверные таблицы можно перенести в формат
MS Access. На их основе создается единый файл, содержащий все необходимые
таблицы, индексы, хранимые процедуры и прочие элементы БД. Такой файл управляется машиной баз данных Microsoft Jet 4.0 Database Engine, а в роли провайдера используется Microsoft Jet 4.0 OLE DB Provider.
Рис. 9.1. Реализация технологии ADO в Delphi
Если используется промышленный сервер данных Oracle или MS SQL Server, данные не нуждаются в какой-либо предварительной подготовке, а в роли провайдера
используется соответственно Microsoft OLE DB Provider for Oracle или Microsoft
OLE DB Provider for SQL Server. Нетрудно обнаружить и явный недостаток такой
технологии: ADO не может использоваться, если для соответствующей структуры
данных (в частности, для БД многих популярных серверов — InterBase, Informix,
DB2 и пр.) не создан нужный провайдер или ODBC-драйвер.
На машине клиента располагаются связные компоненты TADOConnect ion и компоненты-наборы данных TADOTable, TADOQuery, TADOStoredProc, а также не
показанные на рисунке компоненты-наборы TADODataSet и командные компоненты TADOCommand. Каждый из этих компонентов может связываться с
провайдером данных либо с помощью связного компонента TADOConnection,
либо минуя его и используя собственное свойство ConnectionString. Таким
образом, компонент TADOConnection играет роль концентратора соединений с
источником данных компонентов-наборов, и в этом смысле он подобен
компоненту TDatabase в традиционной архитектуре с BDE.
Компоненты-наборы TADODataSet в функциональном плане повторяют свойства
Delphi компонентов TClientDataSet технологии MIDAS. Командные компоненты
TADOCommand предназначены для реализации запросов на языке определения
данных (Data Definition Language, DDL), то есть для реализации SQL-запросов,
которые не возвращают данные (запросы типа CREATE, DROP, UPDATE и т. п.).
Специальный компонент RDSConnection (не показан на рисунке) создан для упрощения связи с MS Internet Explorer и при разработке интранет-приложений.
Компоненты-наборы с помощью компонентов-источников TDataSource и визуализирующих компонентов TDBGrid, TDBMemo, TDBEdit и т. п. обеспечивают необходимый интерфейс с пользователем программы.
® ПРИМЕЧАНИЕ Ничто не дается бесплатно— эта старая истина во многом
относится и к АОО. Ско-рость доступа к данным с помощью средств СОМ (а
технология ActiveX, являющаяся краеугольным камнем ADO, целиком базируется
на СОМ) в общем случае оказывается заметно ниже традиционного для Delphi
механизма на основе ВОЕ (как будет показано дальше, для некоторых типичных
случаев скорость уменьшается в десятки и сотни раз).
Тестовая программа
В этом разделе рассматриваются основные особенности использования технологии ADO. Описанный далее пример (Chap_09\ADO\ADOTest.dpr) в
функциональном плане повторяет пример, рассмотренный в разделе «Пример
простой программы» урока 1: в нем иллюстрируется реляционная связь главныйдетальный между таблицами NAKLS и MOVEBOOK. Однако технология ADO
значительно медленнее BDE, поэтому во избежание раздражающих задержек при
установлении связей и открытии таблиц следует предварительно существенно
сократить объем данных, хранящихся в БД «Книголюб». Вызовите SQL Explorer,
откройте БД BiblData и выполните следующие четыре запроса1:
DELETE FROM Nakls WHERE NaklID>10 DELETE FROM MoveBook WHERE
MNakl>lU DELETE FROM Firms WHERE NOT FirmID IN
(SELECT NFirm FROM Nakls) DELETE FROM*Books WHERE NOT BookID IN
(SELECT MBook FROM MoveBook)
После этого объем основных таблиц уменьшится в несколько десятков раз, но
зато и временные задержки сократятся с 15 минут до примерно одной минуты
(для системы 400 МГц, 192 Мбайт, Windows 2000). Если учесть, что открытие
таблиц в примере из урока 1 происходит примерно за две секунды, следует
признать, что замена BDE на ADO уменьшила «реактивность» СУБД в 15 х 60/2 =
450 раз!
Порядок выполнения работы
1.Итак, начните новый проект и добавьте к нему модуль данных. Поместите на
него компонент ADOConnetion, ADOTable (вкладка ADO палитры компонентов) и
компоненты DataSource (вкладка Data Access). Назовите таблицы именами и
свяжите источник данных DataSource с таблицами. Поскольку предполагается
использовать файл-серверные таблицы, то в рамках ADO такие таблицы должны
управляться драйвером ODBC. Этот драйвер следует предварительно настроить
на работу с нужным каталогом. Для этого в главном меню выберите команду
Пуск > Настройка > Панель управления (для Windows 2000/XP еще и
Администрирование) и щелкните на значке Источники данных (ODBC).
2. На вкладке Пользовательский DSN открывшегося окна (рис. 1) выберите в
списке Источники данных пользователя кнопку Добавить.
Рис. Выбор драйвера ODBC
3. В открывшемся диалоговом окне Создание нового источника данных
выберите драйвер : SQL Server и нажмите кнопку Готово
4. В открывшемся диалоговом окне Создание источника данных введите любое
Имя (например Андрей); Сервер – выберите тот компьютер где установлен SQL
Server (например local – если он установлен локально на вашем компьютере).
5.Далее в диалоговом окне Создание источника данных надо настроить как
показано на рис.
6. Выбрать вашу БД созданную в MS SQL Server.
8. Поскольку ранее мы уже настроили драйвер OBDC, можно щелкнуть на кнопке
Проверить подключение, чтобы убедиться в нормальном функционировании
связи. Закройте окно щелчком на кнопке О К и щелкните на кнопке О К еще раз
— связь готова!
Хранимые процедуры.
Хранимая процедура – это набор операторов T-SQL, который компилируется системой SQL
Server в единый "план исполнения". Этот план сохраняется в кэш-области памяти для процедур
при первом выполнении хранимой процедуры, что позволяет использовать этот план повторно;
системе SQL Server не требуется снова компилировать эту процедуру при каждом ее запуске.
Хранимые процедуры T-SQL аналогичны процедурам в других языках программирования в том
смысле, что они допускают входные параметры и возвращают выходные значения в виде
параметров или сообщения о состоянии (успешное или неуспешное завершение). Все
операторы процедуры обрабатываются при вызове процедуры. Хранимые процедуры
используются для группирования операторов T-SQL и любых логических конструкций,
необходимых для выполнения задачи. Поскольку хранимые процедуры сохраняются в виде
процедурных блоков, они могут использоваться различными пользователями для
согласованного повторяемого выполнения одинаковых задач и даже в различных приложениях.
Хранимые процедуры также позволяют поддерживать единый подход к управлению задачей,
что помогает обеспечивать согласованное и корректное внедрение любых деловых правил.
Ваше приложение может взаимодействовать с SQL Server двумя способами: вы можете
программировать в приложении отправку операторов T-SQL от клиента на SQL Server или
можете создавать хранимые процедуры, которые хранятся и выполняются на сервере. Если вы
отправляете ваши операторы T-SQL на сервер, то эти операторы передаются через сеть и
рекомпилируются SQL Server каждый раз, когда происходит их запуск. Используя хранимые
процедуры, вы можете выполнять их путем вызова из вашего приложения с помощью одного
оператора. Как уже говорилось, при первом запуске хранимой процедуры происходит ее
компиляция и создание плана ее исполнения, который сохраняется в памяти. Затем при
последующих вызовах этой процедуры SQL Server использует этот план исполнения без
необходимости повторного компилирования. Поэтому в тех случаях, когда для выполнения
задачи требуется выполнить несколько операторов T-SQL или когда требуется частая обработка
какого-либо оператора, использование хранимой процедуры способствует снижению сетевого
трафика и может оказаться эффективнее и быстрее, чем отправка каждого оператора через сеть
от клиента на сервер.
Использование хранимых процедур может повысить производительность и в других
отношениях. Например, использование хранимых процедур для проверки условий сервера
может повысить производительность за счет снижения количества данных, которые должны
передаваться между клиентом и сервером, и снижения объема обработки, выполняемой на
клиентской машине. Для проверки какого-либо условия из хранимой процедуры можно
включить в хранимую процедуру условные операторы (например, конструкции IF и WHILE.
Логика этой проверки будет обрабатываться на сервере с помощью хранимой процедуры,
поэтому вам не потребуется программировать эту логику в самом приложении а серверу не
нужно будет возвращать промежуточные результаты клиенту для проверки данного условия.
Вы можете также вызывать хранимые процедуры из сценариев, пакетных заданий и
интерактивных командных строк с помощью операторов T-SQL, показанных в примерах далее.
Хранимые процедуры также обеспечивают простой доступ к базе данных для пользователей.
Пользователи могут осуществлять доступ к базе данных, не зная деталей архитектуры таблиц и
без непосредственного доступа к данным таблиц, – они просто запускают процедуры, которые
выполняют требуемые задачи. Тем самым хранимые процедуры помогают обеспечивать
соблюдение деловых правил.
Хранимые процедуры могут принимать входные параметры, использовать локальные
переменные и возвращать данные. Хранимые процедуры могут возвращать данные с помощью
выходных параметров, а также могут возвращать коды завершения, результирующие наборы из
операторов SELECT или глобальные курсоры. Вы увидите примеры этих методов (кроме
использования глобальных курсоров) в последующих разделах.
Имеется три типа хранимых процедур: системные хранимые процедуры, расширенные
хранимые процедуры и простые определяемые пользователем хранимые процедуры.
Системные хранимые процедуры предоставляет SQL Server, и они имеют префикс sp_. Они
используются для управления SQL Server и вывода на экран информации о базах данных и
пользователях. Расширенные хранимые процедуры являются динамически подключаемыми
библиотеками (DLL), которые может динамически загружать и выполнять SQL Server. Обычно
их пишут на C или C++, и они исполняют процедуры, внешние относительно SQL Server.
Расширенные хранимые процедуры имеют префикс xp_. Простые определяемые пользователем
хранимые процедуры создаются пользователем и настраиваются для выполнения тех задач,
которые требуются данному пользователю.
Примечание. Вы не должны использовать префикс sp_ при создании простых определяемых
пользователем хранимых процедур. Если SQL Server обнаруживает хранимую процедуру,
имеющую префикс sp_, то он сначала ищет эту хранимую процедуру в главной базе данных
(master). И если вы создадите, например, хранимую процедуру с именем sp_myproc в базе
данных MyDB, то SQL Server сначала будет искать эту процедуру в главной базе данных, а уж
затем в пользовательских базах данных. Разумнее назвать процедуру просто myproc.
Но прежде чем перейти к изучению этих процедур, мы кратко изложим некоторые базовые
сведения о расширенных хранимых процедурах. Расширенные хранимые процедуры придают
высокую степень гибкости и расширяемости среде SQL Server. Они позволяют создавать ваши
собственные внешние процедуры на C, C++ или других языках программирования.
Расширенные внешние процедуры выполняются в том же стиле, что и два других типа
хранимых процедур. Вы можете передавать параметры в расширенные хранимые процедуры,
как и в другие типы хранимых процедур, и они могут возвращать результирующие наборы
и/или сообщения о состоянии.
Как уже говорилось, расширенные хранимые процедуры – это библиотеки DLL, которые
динамически загружает и выполняет SQL Server. Они выполняются непосредственно в
адресном пространстве SQL Server, и вы можете программировать их, используя интерфейс
прикладного программирования (API) SQL Server Open Data Services.
Расширенные хранимые процедуры пишут вне SQL Server. Закончив разработку расширенной
хранимой процедуры, вы регистрируете ее в SQL Server с помощью операторов T-SQL или
через Enterprise Manager.
Создание хранимых процедур
Мы рассмотрим три метода создания хранимой процедуры:
1. использование оператора T-SQL CREATE PROCEDURE,
2. использование Enterprise Manager
3. использование мастера Create Stored Procedure Wizard.
Независимо от выбранного метода не забывайте тестировать каждую процедуру, выполняя при
необходимости последующее редактирование, пока она не будет работать должным образом.
Использование оператора CREATE PROCEDURE
Оператор CREATE PROCEDURE имеет следующий синтаксис:
CREATE PROC[EDURE]
имя_процедуры
[ {@имя_параметра тип_данных} ] [= по_умолчанию][OUTPUT]
[,...,n]
AS оператор(ы)_t-sql
Создадим какую-либо простую хранимую процедуру. Эта процедура будет выбирать (и
возвращать) три колонки данных для каждой строки таблицы Orders, в которой дата колонки
ShippedDate больше даты колонки RequiredDate. Отметим, что хранимая процедура может быть
создана только в текущей базе данных, к которой осуществляется доступ, поэтому сначала
следует указать эту базу данных с помощью оператора USE. Прежде чем создать эту процедуру,
мы выясним также, существует ли хранимая процедура с именем, которое мы хотим
использовать. Если она существует, то мы удалим ее, и затем создадим новую процедуру с этим
именем. Ниже показан набор T-SQL, используемый для создания этой процедуры:
USE Northwind
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "LateShipments" AND
type = "P")
DROP PROCEDURE LateShipments
GO
CREATE PROCEDURE LateShipments
AS
SELECT
FROM
WHERE
RequiredDate,
ShippedDate,
Shippers.CompanyName
Orders, Shippers
ShippedDate
> RequiredDate AND
Orders.ShipVia = Shippers.ShipperID
GO
Если запустить данный набор, то будет создана хранимая процедура. Для запуска хранимой
процедуры просто обратитесь к ней по имени, как это показано ниже:
LateShipments
GO
Процедура LateShipments возвратит 37 строк данных.
Если оператор, вызывающий данную процедуру, входит в пакет операторов и не является
первым оператором этого пакета, то вы должны использовать вместе с вызовом процедуры
ключевое слово EXECUTE (сокращается до "EXEC"), как это показано в следующем примере:
SELECT getdate()
EXECUTE LateShipments
GO
Вы можете использовать ключевое слово EXECUTE, даже если процедура выполняется как
первый оператор в пакете или является единственным оператором, который у вас выполняется.
Использование параметров
Теперь добавим к нашей хранимой процедуре входной параметр, чтобы мы могли передавать
данные в эту процедуру. Чтобы задать входные параметры в хранимой процедуре, укажите
список этих параметров с символом @ перед именем каждого параметра, т.е. @имя_параметра.
Вы можете задать в хранимой процедуре до 1024 параметров. В нашем примере мы создадим
параметр с именем @shipperName. При запуске хранимой процедуры мы укажем имя
компании-грузоотправителя (shipperName), и результатом запроса будут строки только для
этого грузоотправителя. Ниже приводится T-SQL-программа, используемая для создания новой
хранимой процедуры:
USE Northwind
GO
IF EXISTS
(SELECT
name
FROM
sysobjects
WHERE
name = "LateShipments" AND
type = "P")
DROP PROCEDURE LateShipments
GO
CREATE PROCEDURE LateShipments @shipperName char(40)
AS
SELECT
RequiredDate,
ShippedDate,
Shippers.CompanyName
FROM
Orders, Shippers
WHERE
ShippedDate
> RequiredDate AND
Orders.ShipVia
= Shippers.ShipperID AND
Shippers.CompanyName
= @shipperName
GO
Для запуска этой хранимой процедуры вы должны указать входной параметр. Если параметр не
указан, SQL Server выведет сообщение об ошибке, например, в следующей форме:
Procedure LateShipments, Line 0 Procedure 'LateShipments'
expects parameter '@shipperName', which was not supplied.
(Процедура LateShipments, Строка 0 процедуры 'LateShipments',
предполагается параметр '@shipperName', который не был указан)
Чтобы получить строки для грузоотправителя Speedy Express, выполните следующие
операторы:
USE Northwind
GO
EXECUTE LateShipments "Speedy Express"
GO
Вы увидите 12 строк, возвращенные в результате вызова этой хранимой процедуры.
Вы можете также задать для параметра значение по умолчанию, которое будет использоваться,
когда этот параметр не указан в обращении к процедуре. Например, чтобы использовать для
вашей хранимой процедуры значение по умолчанию United Package, измените текст
создаваемой процедуры следующим образом: (изменена только строка CREATE PROCEDURE)
USE Northwind
GO
IF EXISTS
(SELECT
name
FROM
sysobjects
WHERE
name = "LateShipments" AND
type = "P")
DROP PROCEDURE LateShipments
GO
CREATE PROCEDURE LateShipments @shipperName char(40) = "United Package"
AS
SELECT
RequiredDate,
ShippedDate,
Shippers.CompanyName
FROM
Orders, Shippers
WHERE
ShippedDate
Orders.ShipVia
Shippers.CompanyName
GO
> RequiredDate AND
= Shippers.ShipperID AND
= @shipperName
Теперь при запуске процедуры LateShipments без входного параметра (@shipperName) по
умолчанию для этого параметра будет использоваться значение United Package; процедура
возвратит 16 строк. Но если вы укажете входной параметр, то его значение заместит значение,
определенное по умолчанию.
Для возврата значения параметра хранимой процедуры в вызывающую программу используйте
ключевое слово OUTPUT после имени этого параметра. Чтобы сохранить значение в
переменной, которую можно использовать в вызывающей программе, используйте при вызове
хранимой процедуры ключевое слово OUTPUT. Чтобы увидеть, как это происходит, мы
создадим новую хранимую процедуру, которая выбирает цену единицы указанного продукта.
Входной параметр @prod_id – это идентификатор продукта, а выходной параметр @unit_price –
это возвращаемое значение цены единицы продукта. В вызывающей программе будет
объявлена локальная переменная с именем @price, которая будет использоваться для
сохранения возвращаемого значения. Ниже приводится набор операторов, используемый для
создания хранимой процедуры GetUnitPrice:
USE Northwind
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "GetUnitPrice" AND
type = "P")
DROP PROCEDURE GetUnitPrice
GO
CREATE PROCEDURE GetUnitPrice @prod_id int, @unit_price money OUTPUT
AS
SELECT @unit_price = UnitPrice
FROM
Products
WHERE ProductID = @prod_id
GO
Прежде чем использовать переменную в вызове хранимой процедуры, вы должны объявить эту
переменную в вызывающей программе. Например, в следующей программе мы сначала
объявим переменную @price и присвоим ей тип данных money (который должен быть
совместим с типом данных выходного параметра), а затем выполним хранимую процедуру:
DECLARE @price money
EXECUTE GetUnitPrice 77, @unit_price = @price OUTPUT
PRINT CONVERT(varchar(6), @price)
GO
Оператор PRINT возвращает значение 13.00 в переменной @price. Отметим, что мы
использовали оператор CONVERT для преобразования значения @price в данные типа varchar,
чтобы их можно было напечатать как строку, как символьный тип данных или как тип данных,
которые могут быть неявно преобразованы в символьный тип, что требуется для оператора
PRINT.
Кроме того, отметим, что в хранимой процедуре и в вызывающей программе для выходных
переменных использовались различные имена, чтобы вам было легче следить за положением
этих переменных в примере и чтобы показать, что можно использовать различные имена.
При обращении к хранимой процедуре вы можете также задать входное значение в выходном
параметре. Это означает, что это значение будет введено в хранимую процедуру, где это
значение может быть изменено или использовано для операций; затем новое значение
возвращается в вызывающую программу. Чтобы поместить входное значение в выходной
параметр, нужно просто присвоить это значение соответствующей переменной в вызывающей
программе перед выполнением процедуры или выполнить запрос, который считывает значение
в переменную и затем передает эту переменную в хранимую процедуру. А теперь рассмотрим
использование локальных переменных внутри хранимой процедуры.
Использование локальных переменных внутри хранимой процедуры
Как показано в предыдущем разделе, для создания локальных переменных используется
ключевое слово DECLARE. При создании локальной переменной вы должны задать для нее имя
и тип данных, а также поставить перед именем переменной символ @. При объявлении
переменной ей первоначально присваивается значение NULL.
Локальные переменные можно объявлять в пакете, в сценарии (или вызывающей программе)
или в хранимой процедуре. Переменные часто используются в хранимых процедурах для
хранения значений, которые будут проверяться в условном операторе или возвращаться
оператором RETURN хранимой процедуры. Переменные в хранимых процедурах часто
используются как счетчики. Область действия локальной переменной в хранимой процедуре
начинается с точки объявления этой переменной и заканчивается выходом из данной
процедуры. После выхода из хранимой процедуры эта переменная уже недоступна для
использования.
Рассмотрим пример хранимой процедуры, содержащей локальные переменные. Эта процедура
вставляет пять строк в таблицу с помощью циклической конструкции WHILE. Сначала мы
создадим таблицу с именем mytable для этого примера и затем создадим хранимую процедуру
InsertRows. В этой процедуре мы будем использовать локальные переменные @loop_counter и
@start_val, которые объявим вместе и разделим запятой. В следующей T-SQL-программе
создается таблица и хранимая процедура:
USE MyDB
GO
CREATE TABLE mytable
(
column1 int,
column2 char(10)
)
GO
CREATE PROCEDURE InsertRows @start_value int
AS
DECLARE
@loop_counter int, @start_val int
SET
@start_val = @start_value – 1
SET
@loop_counter = 0
WHILE (@loop_counter < 5)
BEGIN
INSERT INTO mytable VALUES (@start_val + 1, "new row")
PRINT (@start_val)
SET @start_val = @start_val + 1
SET @loop_counter = @loop_counter + 1
END
GO
А теперь выполним эту хранимую процедуру с начальным значением 1, как это показано ниже:
EXECUTE InsertRows 1
GO
Вы увидите пять значений, выведенных для @start_val: 0, 1, 2, 3 и 4.
Выберите все строки из таблицы mytable с помощью следующего оператора:
SELECT *
FROM
mytable
GO
После выполнения этого оператора SELECT мы получим следующие выходные результаты:
column1
column2
----------------------1
new row
2
new row
3
new row
4
new row
5
new row
После завершения хранимой процедуры переменные @loop_counter и @start_val уже
недоступны. Вы получите сообщение об ошибке, если попытаетесь вывести их с помощью
следующего оператора T-SQL:
PRINT (@loop_counter)
PRINT (@start_val)
GO
Сообщение об ошибке будет иметь следующую форму:
Msg 137, Level 15, State 2, Server JAMIERE3, Line 1
Must declare the variable '@loop_counter'.
(Должна быть объявлена переменная '@loop_counter')
Msg 137, Level 15, State 2, Server JAMIERE3, Line 2
Must declare the variable '@start_value'.
(Должна быть объявлена переменная '@start_value')
Те же правила, связанные с областью действия переменной, применимы к выполнению
пакетного набора операторов. Как только появляется ключевое слово GO (являющееся
признаком конца пакета), локальные переменные, объявленные внутри пакета, становятся
недоступны. Область действия локальной переменной находится только в пределах пакета.
Чтобы лучше понять эти правила, рассмотрим вызов хранимой процедуры в одном из
приведенных выше примеров:
USE Northwind
GO
DECLARE @price money
EXECUTE GetUnitPrice 77, @unit_price = @price OUTPUT
PRINT CONVERT(varchar(6), @price)
GO
PRINT CONVERT(varchar(6), @price)
GO
В первом операторе PRINT выводится значение локальной переменной @price из данного
пакета. Во втором операторе сделана попытка вывести его снова вне пакета, но в результате
появится сообщение об ошибке в следующей форме:
13.00
Msg 137, Level 15, State 2, Server JAMIERE3, Line 2
Must declare the variable '@price'.
(Должна быть объявлена переменная '@price')
Отметим, что первый оператор PRINT выполнен успешно. (Он вывел значение 13.00.)
Возможно, вам потребуется использовать операторы BEGIN TRANSACTION, COMMIT и
ROLLBACK в хранимой процедуре, которая содержит более одного оператора T-SQL. Это
позволяет указывать, какие операторы должны быть сгруппированы как одна транзакция.
Использование RETURN
Вы можете возвращаться из любой точки хранимой процедуры в вызывающую программу с
помощью ключевого слова RETURN, обеспечивающего безусловный выход из процедуры.
RETURN можно также использовать для выхода из пакета или блока операторов. При
выполнении оператора RETURN в хранимой процедуре работа процедуры прекращается в этой
точке, и происходит переход к следующему оператору вызывающей программы. Операторы,
следующие после RETURN в хранимой процедуре, не выполняются. С помощью RETURN вы
можете также возвращать целое значение.
Сначала рассмотрим пример использования RETURN просто для выхода из хранимой
процедуры. Мы создадим модифицированную версию процедуры GetUnitPrice, которая
проверяет, было ли задано входное значение, и если нет, то выводит сообщение для
пользователя и возвращается в вызывающую программу. Для этого мы определим входной
параметр со значением по умолчанию NULL и затем будем проверять это значение в
процедуре; если входной параметр имеет значение NULL, это означает, что входное значение
не задано. Ниже приводится пример удаления и повторного создания этой процедуры:
USE Northwind
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "GetUnitPrice" AND
type = "P")
DROP PROCEDURE GetUnitPrice
GO
CREATE PROCEDURE GetUnitPrice @prod_id int = NULL
AS
IF @prod_id IS NULL
BEGIN
PRINT "Please enter a product ID number"
RETURN
END
ELSE
BEGIN
SELECT
FROM
WHERE
UnitPrice
Products
ProductID = @prod_id
END
GO
А теперь запустим GetUnitPrice без ввода входного значения и посмотрим результаты. Для
запуска этой хранимой процедуры вы должны указать оператор EXECUTE, поскольку вызов
процедуры не является первым оператором этого пакета. Используйте следующую
последовательность:
PRINT "Before procedure"
EXECUTE GetUnitPrice
PRINT "After procedure returns from stored procedure"
GO
Результаты будут выведены в следующей форме:
Before procedure (До процедуры)
Please enter a product ID number (Введите идентификационный номер продукта)
After procedure returns from stored procedure (После возврата из хранимой
процедуры)
Второй оператор PRINT включен для того, чтобы показать, что после оператора RETURN
хранимой процедуры выполнение данного пакета продолжается с оператора PRINT.
Теперь рассмотрим использование RETURN для возврата значения в вызывающую программу.
Возвращаемое значение должно быть целым. Это может быть константа или переменная. Вы
должны объявить в вызывающей программе переменную, в которой будет храниться
возвращаемое значение для дальнейшего использования в этой программе. Например,
следующая процедура возвратит значение 1, если цена единицы продукции для продукта,
указанного во входном параметре, меньше $100; иначе она возвратит значение 99.
CREATE PROCEDURE CheckUnitPrice @prod_id int
AS
IF
(SELECT UnitPrice
FROM
Products
WHERE ProductID = @prod_id) < 100
RETURN 1
ELSE
RETURN 99
GO
Для вызова этой хранимой процедуры и использования возвращаемого значения объявите в
вызывающей программе переменную и приравняйте ее возвращаемому значению хранимой
процедуры (указав значение 66 в ProductID для входного параметра):
DECLARE @return_val int
EXECUTE @return_val = CheckUnitPrice 66
IF (@return_val = 1) PRINT "Unit price is less than $100"
GO
В результате будет выведен текст "Unit price is less than $100" (Цена единицы продукции
меньше $100), поскольку цена единицы продукции для указанного продукта равна $17 и, тем
самым, возвращаемое значение равно 1. Убедитесь в том, что вы задали целый тип данных,
когда объявляете переменную, которая используется для хранения значения, возвращаемого
оператором RETURN, поскольку этот оператор возвращает целое значение.
Использование SELECT для возвращаемых значений
Вы можете также возвращать данные из хранимой процедуры с помощью оператора SELECT,
находящегося внутри этой процедуры. Вы можете возвращать результирующий набор из
запроса SELECT или возвращать значение переменной.
Рассмотрим пару примеров. Сначала мы создадим новую хранимую процедуру с именем
PrintUnitPrice, которая возвращает цену единицы продукции для продукта, указанного во
входном параметре (с помощью идентификатора этого продукта). Используется следующая
последовательность:
CREATE PROCEDURE PrintUnitPrice @prod_id int
AS
SELECT
ProductID,
UnitPrice
FROM
Products
WHERE
ProductID = @prod_id
GO
Вызовите эту процедуру со значением входного параметра 66, как это показано ниже:
PrintUnitPrice 66
GO
Результаты будут выведены в следующей форме:
ProductID
UnitPrice
-----------------------------------------66
17.00
(1 row(s) affected)
Для возврата значений переменных с помощью оператора SELECT, укажите после SELECT имя
соответствующей переменной. В следующем примере мы снова создадим хранимую процедуру
CheckUnitPrice, которая возвращает значение переменной, а также зададим заголовок
выводимой колонки:
USE Northwind
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "CheckUnitPrice" AND
type = "P")
DROP PROCEDURE CheckUnitPrice
GO
CREATE PROCEDURE CheckUnitPrice @prod_id INT
AS
DECLARE @var1 int
IF
(SELECT
UnitPrice
FROM
Products
WHERE
ProductID = @prod_id) > 100
SET
@var1 = 1
ELSE
SET
@var1 = 99
SELECT "Variable 1" = @var1
PRINT "Can add more T-SQL statements here"
GO
Вызовите эту процедуру со значением входного параметра 66, как это показано ниже:
CheckUnitPrice 66
GO
Результаты выполнения этой хранимой процедуры будут выведены в следующей форме:
Variable
1
-------------99
(1 row(s) affected)
Can add more T-SQL statements here
Мы вывели текст оператора PRINT "Can add more T-SQL statements here" (Здесь можно
добавить другие операторы T-SQL), чтобы показать отличие между возвратом значения с
помощью SELECT и возвратом значения с помощью RETURN. Оператор RETURN прекращает
работу хранимой процедуры в том месте, где он находится, а оператор SELECT возвращает
свой результирующий набор, после чего продолжается выполнение хранимой процедуры.
Если бы в этом примере мы не задали заголовок колонки (просто указали бы SELECT @var1),
то получили бы результат без заголовка, как это показано ниже:
-------------99
(1 row(s) affected)
Использование Enterprise Manager
Теперь, когда вы знаете, как использовать T-SQL для создания хранимых процедур,
рассмотрим, как использовать для их создания Enterprise Manager. Чтобы создать хранимую
процедуру с помощью Enterprise Manager, вам по-прежнему нужно знать, как записываются
операторы T-SQL. Enterprise Manager просто снабжает вас графическим интерфейсом, в
котором можно создавать вашу процедуру. Мы опробуем этот метод, повторно создав
хранимую процедуру InsertRows, как это описано ниже.
1. Чтобы удалить хранимую процедуру, сначала раскройте папку базы данных MyDB в
левой панели. Enterprise Manager и щелкните на папке Stored Procedures (Хранимые
Процедуры). В правой панели появятся все хранимые процедуры этой базы данных.
Щелкните правой кнопкой мыши на хранимой процедуре InsertRows (она должна
существовать – мы создали ее ранее в этой лекции) и выберите из контекстного меню
пункт Delete (Удалить). (Вы можете также переименовать или скопировать хранимую
процедуру через это контекстное меню.) Появится диалоговое окно Drop Objects
(Удаление объектов. Щелкните на кнопке Drop All (Удалить все), чтобы удалить
хранимую процедуру.
2. Щелкните правой кнопкой мыши на папке Stored Procedures и выберите из контекстного
меню пункт New Stored Procedure (Создать хранимую процедуру). Появится диалоговое
окно Stored Procedure Properties (Свойства хранимой процедуры).
Рис. 21.1. Диалоговое окно Drop Objects (Удаление объектов)
Рис. 21.2. Окно Stored Procedure Properties (Свойства хранимой процедуры)
3. В поле Text (Текст) вкладки General (Общие) замените [OWNER].[PROCEDURE NAME]
([Владелец].[Имя процедуры]) на имя хранимой процедуры – в данном случае, –
InsertRows. Затем введите текст T-SQL-программы для этой хранимой процедуры. На
рис. 21.3 показано окно Stored Procedure Properties после ввода текста T-SQL-программы
для процедуры InsertRows.
Рис. 21.3. Текст T-SQL-программы для новой хранимой процедуры
4. Щелкните на кнопке Check Syntax (Проверить синтаксис), чтобы SQL Server указал
ошибки синтаксиса T-SQL в хранимой процедуре. Исправьте найденные синтаксические
ошибки и снова щелкните на кнопке Check Syntax. После успешной проверки синтаксиса
вы увидите окно сообщения (рис. 21.4). Щелкните на кнопке OK
Рис. 21.4. Окно сообщения об успешной проверке синтаксиса хранимой процедуры
5. Щелкните на кнопке OK в окне Stored Procedure Properties, чтобы создать вашу
хранимую процедуру и вернуться в окно Enterprise Manager. Щелкните на папке Stored
Procedures в левой панели Enterprise Manager, чтобы показать новую хранимую
процедуру в правой панели (рис. 21.5).
Рис. 21.5. Новая хранимая процедура в окне Enterprise Manager
6. Чтобы присвоить пользователям полномочия выполнения новой хранимой процедуры,
щелкните правой кнопкой мыши на имени этой хранимой процедуры в правой панели
Enterprise Manager и выберите из контекстного меню пункт Properties (Свойства). В
появившемся окне Stored Procedure Properties щелкните на кнопке Permissions
(Полномочия). Появится окно Object Properties (Свойства объектов) (рис. 21.6).
Установите флажки в колонке EXEC для пользователей или ролей базы данных,
которым вы хотите разрешить выполнение этой хранимой процедуры. В данном примере
полномочия выполнения хранимой процедуры InsertRows предоставлены трем
пользователям.
Рис. 21.6. Вкладка Permissions окна Object Properties (Свойства объектов)
7. Щелкните на кнопке Apply (Применить) и затем щелкните на кнопке OK, чтобы
присвоить выбранные вами полномочия и вернуться в окно Stored Procedure Properties.
Для завершения щелкните на кнопке OK.
Вы можете также использовать Enterprise Manager для редактирования хранимой процедуры.
Для этого щелкните правой кнопкой мыши на имени этой процедуры и выберите из
контекстного меню пункт Properties. Выполните редактирование процедуры в окне Stored
Procedure Properties (рис. 21.3), проверьте синтаксис, щелкнув на кнопке Check Syntax,
щелкните на кнопке Apply и затем щелкните на кнопке OK.
Кроме того, вы можете использовать Enterprise Manager для управления полномочиями по
хранимой процедуре. Для этого щелкните правой кнопкой мыши на имени хранимой
процедуры в окне Enterprise Manager, укажите в контекстном меню пункт All Tasks (Все задачи)
и выберите пункт Manage Permissions (Управление полномочиями). Вы можете также создавать
публикацию для репликации, генерировать сценарии SQL и отображать зависимости
(dependencies) для хранимой процедуры из подменю All Tasks. Если вы решите генерировать
сценарии SQL, то SQL Server автоматически создаст файл сценария (с указанным вами
именем), который будет содержать определение хранимой процедуры. Затем вы сможете при
необходимости повторно создать процедуру, используя этот сценарий.
Использование мастера Create Stored Procedure Wizard
Третий метод создания хранимых процедур – использование мастера создания хранимых
процедур Create Stored Procedure Wizard – дает вам основу для написания ваших процедур из
шаблонных операторов T-SQL. Вы можете применить мастер для создания хранимой
процедуры, используемой для вставки, удаления или обновления строк таблиц. Этот мастер не
помогает создавать процедуры, которые считывают строки из таблицы.
Мастер позволяет вам создавать несколько хранимых процедур в одной базе данных без
необходимости выхода из мастера и его перезапуска. Однако для создания процедуры в другой
базе данных вы должны снова запустить мастер. Для запуска этого мастера выполните
следующие шаги.
1. В окне Enterprise Manager выберите из меню Tools (Сервис) пункт Wizards (Мастера),
чтобы появилось диалоговое окно Select Wizard (Выбор мастера). Раскройте папку
Database и щелкните на строке Create Stored Procedure Wizard (рис. 21.7).
Рис. 21.7. Диалоговое окно Select Wizard (Выбор мастера)
2. Щелкните на кнопке OK, чтобы появилось начальное окно мастера Create Stored
Procedure Wizard (рис. 21.8).
Рис. 21.8. Начальное окно мастера Create Stored Procedure Wizard (Создание хранимых
процедур)
3. Щелкните на кнопке Next (Далее), чтобы появилось окно Select Database (Выбор базы
данных). Введите имя базы данных, в которой вы хотите создать хранимую процедуру.
4. Щелкните на кнопке Next, чтобы появилось окно Select Stored Procedures (Выбор
хранимых процедур) (рис. 21.9). Здесь вы увидите список всех таблиц в выбранной базе
данных с тремя колонками флажков. Эти колонки представляют три типа хранимых
процедур, которые можно создать с помощью этого мастера: хранимые процедуры,
которые выполняют вставку (Insert), удаление (Delete) и обновление (Update) данных.
Установите нужные флажки в колонках рядом с именем каждой таблицы.
Рис. 21.9. Окно Select Stored Procedures (Выбор хранимых процедур)
В данном примере показаны две таблицы, которые использовались на протяжении всей
этой книги. Как видно из рисунка, таблице Bicycle_Inventory были присвоены две
процедуры: процедура вставки (insert)) и процедура обновления (update). Как показано в
последующих шагах, вы можете изменять эти процедуры до их реального создания.
Примечание. Одна хранимая процедура может выполнять несколько типов
модификаций данных, но мастер Create Stored Procedure Wizard создает каждый тип
модификаций в виде отдельной хранимой процедуры. Вы можете изменять любую из
создаваемых этим мастером процедур, добавляя другие операторы T-SQL.
5. Щелкните на кнопке Next, чтобы появилось окно мастера Create Stored Procedure Wizard
(рис. 21.10). В этом окне содержится список имен и описаний всех хранимых процедур,
которые будут созданы, когда вы завершите работу мастера.
6. Чтобы переименовать и отредактировать хранимую процедуру, начните с выбора ее
имени в окне Completing the Create Stored Procedure Wizard и затем щелкните на кнопке
Edit (Правка), чтобы появилось окно Edit Stored Procedure Properties (Редактирование
свойств хранимой процедуры) (рис. 21.11). Это окно содержит список колонок таблицы,
на которые повлияет данная процедура. Колонки, для которых установлен флажок в
колонке Select, будут использоваться в данной хранимой процедуре.
Рис. 21.10. Окно мастера Completing the Create Stored Procedure Wizard
Рис. 21.11. Окно Edit Stored Procedure Properties (Редактирование свойств хранимой
процедуры)
В этом примере показано шесть колонок таблицы Bicycle_Inventory, на которые может
повлиять процедура вставки с текущим именем insert_Bicycle_Inventory_1. Для каждой
колонки таблицы установлен флажок в колонке Select. Эти флажки указывают, что при
выполнении данной хранимой процедуры потребуется ввод значений во все шесть
колонок и что хранимая процедура вставит эти шесть значений в соответствующие
шесть колонок.
7. Для переименования хранимой процедуры удалите существующее имя в текстовом поле
Name и замените его новым именем.
8. Для редактирования хранимой процедуры щелкните на кнопке Edit SQL (Редактировать
SQL), чтобы появилось диалоговое окно Edit Stored Procedure SQL (Редактирование SQL
хранимой процедуры) (рис. 21.12). Здесь вы можете видеть T-SQL-программу для
хранимой процедуры. Как видно из рисунка, здесь используются довольно простые
операторы T-SQL. В данном примере пять параметров, которые вы указываете при
вызове этой хранимой процедуры, – это значения, которые вставляются в виде новой
строки в таблицу. Для редактирования этой процедуры просто введите ваши изменения в
текстовом окне. Закончив правку, щелкните на кнопке Parse (Синтаксический разбор),
чтобы проверить синтаксис, исправьте ошибки и затем щелкните на кнопке OK, чтобы
вернуться в окно мастера Completing the Create Stored Procedure Wizard.
Рис. 21.12. Диалоговое окно Edit Stored Procedure SQL
9. После внесения возможных изменений и проверки процедуры щелкните на кнопке Finish
(Готово), чтобы создать хранимые процедуры. Не забудьте задать полномочия по
каждой из хранимых процедур после создания этих процедур. (См. раздел
"Использование Enterprise Manager" выше.)
Как видите, этот мастер нельзя назвать очень полезным. Если вы знаете, как писать программы
на языке T-SQL, то вы можете также использовать сценарии или Enterprise Manager для
создания ваших собственных хранимых процедур.
Управление хранимыми процедурами с помощью T-SQL
Теперь, когда мы знаем, как создавать хранимые процедуры, рассмотрим, как использовать
операторы T-SQL для изменения, удаления и просмотра содержимого хранимой процедуры.
Оператор ALTER PROCEDURE
Оператор T-SQL ALTER PROCEDURE используется для изменения хранимой процедуры,
созданной с помощью оператора CREATE PROCEDURE. При использовании оператора ALTER
PROCEDURE сохраняются исходные полномочия, установленные для данной хранимой
процедуры, а изменения не влияют любые зависимые процедуры или триггеры. (Зависимая
процедура или триггер – это соответствующий объект, который вызывается процедурой.)
Синтаксис оператора ALTER PROCEDURE аналогичен синтаксису оператора CREATE
PROCEDURE:
ALTER PROC[EDURE]
имя_процедуры
[ {@имя_параметра тип_данных} ] [= по_умолчанию]
[OUTPUT]
[,...,n]
AS оператор(ы)_t-sql
В операторе ALTER PROCEDURE вы должны переписать всю хранимую процедуру, внося
нужные изменения. Например, изменим хранимую процедуру GetUnitPrice, которую мы
использовали в предыдущем примере, добавив условие проверки цен единицы продукции,
превышающих $100, как это показано ниже:
USE Northwind
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "GetUnitPrice" AND
type = "P")
DROP PROCEDURE GetUnitPrice
GO
CREATE PROCEDURE GetUnitPrice
@prod_id
int,
@unit_price money OUTPUT
AS
SELECT
@unit_price = UnitPrice
FROM
Products
WHERE
ProductID = @prod_id
GO
ALTER PROCEDURE GetUnitPrice
@prod_id
int,
@unit_price money OUTPUT
AS
SELECT
@unit_price = UnitPrice
FROM
Products
WHERE
ProductID = @prod_id AND
UnitPrice > 100
GO
Теперь предоставим полномочия выполнения по этой хранимой процедуре пользователю DickB
с помощью следующего оператора:
GRANT EXECUTE ON GetUnitPrice TO DickB
GO
Как уже говорилось выше, при изменении хранимой процедуры полномочия сохраняются.
Изменим данную процедуру, чтобы выбирать строки, у которых значение колонки UnitPrice
больше 200 (вместо 100), как это показано ниже:
ALTER PROCEDURE GetUnitPrice
@prod_id
int,
@unit_price money OUTPUT
AS
SELECT
@unit_price = UnitPrice
FROM
Products
WHERE
ProductID = @prod_id AND
UnitPrice > 200
GO
После выполнения этого оператора ALTER PROCEDURE пользователь DickB будет попрежнему иметь полномочия запуска данной хранимой процедуры.
Оператор DROP PROCEDURE
Оператор T-SQL DROP PROCEDURE действует просто – он удаляет хранимую процедуру. Вы
не сможете восстановить хранимую процедуру после ее удаления. Если вам нужно
использовать удаленную процедуру, вы должны полностью воссоздать ее с помощью оператора
CREATE PROCEDURE. Все полномочия по удаленной хранимой процедуре будут утрачены, и
они должны быть предоставлены снова. Ниже приводится пример использования DROP
PROCEDURE для удаления процедуры GetUnitPrice:
USE Northwind
GO
DROP PROCEDURE GetUnitPrice
GO
Примечание. Для удаления хранимой процедуры вы должны использовать базу данных, в
которой она находится. Напомним, что для использования какой-либо базы данных нужно
применить оператор USE, после которого указывается имя этой базы данных.
Хранимая процедура sp_helptext
Системная хранимая процедура sp_helptext позволяет вам просматривать определение любой
хранимой процедуры и оператора, который использовался для создания этой процедуры. (Ее
можно также использовать для просмотра определения триггера, представления, правила или
значения по умолчанию.) Это средство полезно, если вы хотите быстро воспроизвести
определение процедуры (или одного из только что упомянутых объектов), когда используете
ISQL, OSQL или анализатор запросов SQL Query Analyzer. Вы можете также направлять
выходные результаты в файл, чтобы создать из этого определения сценарий, который можно
использовать для редактирования или повторного создания процедуры. Чтобы использовать
sp_helptext, вы должны указать в качестве параметра имя вашей хранимой процедуры (или имя
другого объекта). Например, для просмотра операторов, которые использовались выше для
создания процедуры InsertRows, используйте следующую команду. (И здесь для выполнения
данной команды вы должны использовать базу данных, в которой находится процедура.)
USE MyDB GO sp_helptext InsertRows GO
Выводимые результаты выглядят следующим образом:
Text
---------------------------------------------------------------------
CREATE PROCEDURE InsertRows
@start_value int
AS
DECLARE
@loop_counter int,
@start_val
int
SET
@start_val = @start_value – 1
SET
@loop_counter = 0
WHILE (@loop_counter < 5)
BEGIN
INSERT INTO mytable VALUES (@start_val + 1, 'new row')
PRINT (@start_val)
SET
@start_val
= @start_val + 1
SET
@loop_counter
= @loop_counter + 1
END
Задания:
1. Разработать учебную БД по теме из лабораторной работы № 3.
2. Используя технологию ADO соединиться БД состоящую из связанных
таблиц.
3. Сформировать не менее 3-х различных запросов.
4. Создать хранимые процедуры.
5. Ответить на вопросы:
– Назначение компонент: TADOTable, TADOQuery, TADOStoredProc.
– Основные отличия технологий BDE, ADO.
Лабораторная работа N 4
Тема: Разработка триггеров и транзакций.
Цель работы: научится создавать триггеры
Теоретические сведения
Транзакция – это набор операций, который выполняется как один логический блок.
Использование транзакций позволяет SQL Server обеспечивать определенный уровень
целостности и восстанавливаемости данных. Журнал транзакций, который должна иметь
каждая база данных, поддерживает запись всех транзакций, которые осуществляют любой тип
модификации в базе данных (вставка, обновление или удаление). SQL Server использует этот
журнал транзакций для восстановления данных в случае ошибок или отказов системы.
Целостность транзакции зависит, в частности, от программиста SQL. Программист должен
знать, когда начинать и когда заканчивать транзакцию и в какой последовательности, чтобы
модификации данных обеспечивали логическую согласованность и содержательность данных.
Мы рассмотрим в последующих разделах, как начинать и заканчивать транзакции. А теперь,
когда вы знаете, что такое транзакция, рассмотрим свойства, которыми должна обладать
допустимая для использования транзакция.
ACID-свойства
Чтобы транзакцию можно было считать допустимой для использования, она должна отвечать
четырем требованиям. Эти требования называют ACID-свойствами. "ACID" – это сокращение
от "atomicity (атомарность), consistency (согласованность), isolation (изолированность) и
durability (устойчивость)". В SQL Server включены механизмы, помогающие обеспечивать
соответствие транзакций каждому из этих требований.
Уровни изолированности
SQL Server поддерживает четыре уровня изолированности. Уровень изолированности –
значение, определяющее уровень, при котором в транзакции допускаются несогласованные
данные, т.е. степень изолированности одной транзакции от другой. Более высокий уровень
изолированности повышает точность данных, но при этом может снижаться количество
параллельно выполняемых транзакций. С другой стороны, более низкий уровень
изолированности позволяет выполнять больше параллельных транзакций, но снижает точность
данных. Указываемый вами уровень изолированности для сеанса SQL Server определяет
блокирующее поведение всех операторов SELECT, выполняемых во время этого сеанса (если
только вы не задали другой уровень изолированности). Блокирующее поведение описано в
разделе "Блокировка транзакций" ниже в этой лекции. Ниже описано четыре уровня
изолированности – от низшего до высшего:
Read uncommitted (Чтение незафиксированных данных). Самый низкий уровень
изолированности. На этом уровне транзакции изолированы только в такой степени,
чтобы нельзя было читать физически поврежденные данные.
Read committed (Чтение фиксированных данных). Принятый по умолчанию уровень
для SQL Server. На этом уровне разрешается чтение только фиксированных данных.
(Фиксированные данные – это данные, которые стали постоянной частью базы данных.)
Repeatable read (Повторяемость чтения). Уровень, при котором чтение одной и той же
строки или строк в транзакции дает одинаковый результат. (Пока транзакция не
завершена, никакие другие транзакции не могут модифицировать эти данные.)
Serializable (Упорядочиваемость).Самый высокий уровень изолированности;
транзакции полностью изолируются друг от друга. На этом уровне результаты
параллельного выполнения транзакций для базы данных совпадают с последовательным
выполнением тех же транзакций (по очереди в каком-либо порядке).
Задание уровня изолированности
Вы можете задать уровень изолированности, который будет использоваться для всего сеанса
пользователя SQL Server, с помощью операторов Transact-SQL (T-SQL) или с помощью
функций в вашем приложении. Вы можете также задать в запросе подсказку блокировки, чтобы
переопределить уровень изолированности для данной транзакции. Подсказки блокировки
приводятся в секции "Подсказки блокировки" далее. Чтобы задать уровень изолированности с
помощью T-SQL или в приложении DB-LIB, используйте оператор SET TRANSACTION
ISOLATION LEVEL и задайте один из четырех уровней изолированности. Используется
следующий синтаксис:
SET TRA NSA CTI ON I SOLA TIO N L EVE L
REA D U NCO MM IT TED
| R EAD CO MM IT TED
| R EPE ATA BL E READ
| S ERI ALI ZA BL E
GO
Дополнительная информация. Для других типов приложений, использующих, например,
ODBC, ADO или OLE-DB, найдите "ACID properties" (ACID-свойства) в Books Online и
выберите "Adjusting Transaction Isolation Levels" (Изменение уровней изолированности
транзакций) в диалоговом окне Topics Found (Найденные темы).
После того как вы задали определенный уровень изолированности для сеанса, все последующие
транзакции в этом сеансе SQL Server будут осуществлять блокировку, обеспечивающую этот
уровень изолированности. Чтобы определить, какой уровень изолированности SQL Server
применяется в данный момент по умолчанию, используйте команду DBCC USEROPTIONS.
Нужно просто указать имя данной команды:
DBCC USEROPTIONS
Эта команда возвращает в результате только те параметры, которые задал пользователь или
которые являются активными. Если вы не задали уровень изолированности (оставив принятый
по умолчанию уровень SQL Server), то не увидите этот уровень, запустив оператор DBCC
USEROPTIONS. Но если вы все-таки задали уровень, отличный от принятого по умолчанию, то
увидите этот уровень изолированности. Например, если выполнить следующие операторы, то
уровень изолированности будет показан в результатах оператора DBCC USEROPTIONS:
USE pubs
GO
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
GO
DBCC USEROPTIONS
GO
Результаты оператора DBCC USEROPTIONS будут выведены в следующей форме:
Set Option
Value
--------------------------------------------textsize
64512
language
us_english
dateformat
mdy
datefirst
7
quoted_identifier
SET
arithabort
SET
ansi_null_dflt_on
SET
ansi_defaults
SET
ansi_warnings
SET
ansi_padding
SET
ansi_nulls
SET
concat_null_yields_null SET
isolation level
serializable
(13 row(s) affected)
Для замещения принятого по умолчанию уровня изолированности можно использовать
подсказки блокировки на уровне таблиц, но вам следует применять этот метод, только когда это
абсолютно необходимо и вы в полностью понимаете, как это повлияет на ваши транзакции.
Более подробные сведения о доступных подсказках блокировки см. в разделе "Подсказки
блокировки" далее.
Режимы транзакций
Транзакция может начинаться в одном из трех режимов: автофиксация (autocommit), явный
режим (explicit) или неявный режим (implicit). По умолчанию для SQL Server принят режим
автофиксации. Рассмотрим, что означает каждый из этих режимов.
Режим автофиксации
В режиме автофиксации каждый оператор T-SQL фиксируется по его завершении, и в этом
режиме не требуется никаких дополнительных операторов для управления транзакциями.
Иными словами, каждая транзакция состоит только из одного оператора T-SQL. Режим
автофиксации полезен при выполнении операторов с помощью интерактивной командной
строки, утилиты OSQL или анализатора очередей SQL Server Query Аnalyzer, поскольку вам не
нужно задавать в явном виде запуск и окончание каждой транзакции. Каждый оператор будет
рассматриваться системой SQL Server как отдельная транзакция и будет фиксироваться сразу
после его завершения. Режим автофиксации будет использоваться в каждом соединении с SQL
Server, пока вы не запустите транзакцию в явном режиме с помощью оператора BEGIN
TRANSACTION или пока не укажете неявный режим. По окончании явно заданной транзакции
или после отключения неявного режима SQL Server возвращается к режиму автофиксации.
Явный режим
Явный режим используется чаще всего для программных приложений, а также для хранимых
процедур, триггеров и сценариев. При запуске группы операторов для выполнения какой-либо
задачи вам может потребоваться указание начала и конца данной транзакции, чтобы затем
выполнить фиксацию всей группы операторов или отмену (откат) модификаций всей группы.
Если вы явно указываете начало и конец транзакции, это означает, что вы используете явный
режим, и такую транзакцию называют явной транзакцией. Явная транзакция задается с
помощью операторов T-SQL или с помощью функций API. В этом разделе рассматривается
только метод T-SQL; функции API выходят за рамки изложения этой книги.
Дополнительная информация. Для получения сведений о явных транзакциях,
использующих технологию ADO и OLE-DB, найдите "explicit transactions" (явные
транзакции) в Books Online и выберите "Explicit Transactions" в диалоговом окне Topics Found.
Отметим, что ODBC API не поддерживает явных транзакций, а только транзакции в неявном
режиме и режиме автофиксации.
Использование явной транзакции
Рассмотрим ситуацию, в которой вам потребовалось бы использование явной транзакции для
запуска и окончания задачи. Предположим, что у нас имеется хранимая процедура с именем
Place_Order (Поместить_Заказ), которая управляет в базе данных задачей размещения заказа
покупателя на какой-либо товар. Эта процедура включает в себя следующие шаги: выбор
информации о текущем счете покупателя, ввод идентификационного номера нового заказа и
наименования товара, расчет стоимости заказа с учетом налогов, обновление остатка на счете
покупателя с учетом общей стоимости и проверка наличия товара на складе.
Для согласованности информации в базе данных нам нужно, чтобы были завершены все эти
шаги или не был завершен ни один из этих шагов. Для этой цели мы сгруппируем все
операторы, управляющие данной задачей, в одну явную транзакцию. Если эти операторы не
будут объединены в одну группу, это может привести к несогласованному состоянию данных.
Например, при обрыве соединения клиента с сервером после завершения шага, где вводится
номер нового заказа, но до обновления остатка на счете покупателя, в базе данных появится
новый заказ для данного покупателя, но без снятия денег со счета покупателя. В этом случае
SQL Server фиксирует каждый оператор сразу после его окончания, что оставляет хранимую
процедуру незаконченной на момент разъединения сети. Но если все указанные шаги
определены в рамках одной явной транзакции, то в случае разъединения SQL Server
автоматически выполнит откат всей транзакции, а клиент может затем снова подсоединиться к
серверу и повторно выполнить данную процедуру. Более подробную информацию см. в разделе
"Откаты транзакций" далее.
Использование явных транзакций, когда ваша задача состоит из нескольких шагов, как в
предыдущем примере, также дает преимущества, поскольку SQL Server (независимо от
использования вами операторов ROLLBACK) автоматически выполнит откат ваших транзакций
в случае серьезных ошибок, таких как обрыв связи в сети, аварийный сбой (базы данных или
клиентской системы) или взаимоблокировка. (Взаимоблокировки рассматриваются в разделе
"Блокирование и взаимоблокировки" далее.) Для запуска транзакции используется оператор TSQL BEGIN TRANSACTION. Чтобы указать конец транзакции, используется COMMIT
TRANSACTION или ROLLBACK TRANSACTION. В операторе BEGIN TRANSACTION вы
можете дополнительно указать имя транзакции и затем ссылаться на эту транзакцию по имени в
операторе COMMIT TRANSACTION или ROLLBACK TRANSACTION. Ниже показан
синтаксис этих трех операторов:
BEGI N T RAN [SA CT IO N] [ имя _тр анз ак ци и | @пе рем енн ая _с _име нем _тр анз ак ци и]
COMM IT [TR AN[ SA CT ION] [ и мя _ тра нз ак ции |
@ пер еме нна я _с _и ме нем _ тра нза кци и ] ]
ROLL BAC K [ TRA N[ SA CTIO N] [ им я _т ра нз акци и |
@ пер еме нна я _с _и ме нем _ тра нза кци и
| и мя_ точ ки _с охра нен ия | @ пе ре менн ая_ с_и мен ем _т очки _со хра нен ия ]]
Фиксирование транзакций
Как уже говорилось, фиксированной называется транзакция, все модификации которой стали
постоянной частью базы данных. До фиксирования транзакции запись о ее модификациях и
запись ее фиксирования заносятся в журнал транзакций базы данных. Таким образом,
модификации, которые становятся постоянной частью базы данных, могут находиться в одном
из двух мест: либо они фактически записываются на диск и, тем самым, оказываются в базе
данных, либо они находятся в кэше данных, что позволяет в случае сбоя выполнить повтор
транзакции с помощью журнала транзакций, чтобы избежать потери данной транзакции.
Все ресурсы, используемые транзакцией, такие как блокировки, освобождаются после
фиксирования данной транзакции. Фиксирование транзакции считается успешным в случае
успешного завершения каждого из ее операторов. Ниже приводится небольшая транзакция с
именем update_state, которая изменяет в таблице publishers (издатели) значение колонки state на
XX для всех издателей, у которых в этой колонке содержится значение NULL:
USE pub s
GO
BEGI N T RAN up da te _sta te
UPDA TE pub lis he rs SET st ate = 'X X'
WHER E s tat e I S NU LL
COMM IT TRA N u pd at e_st ate
GO
Запустив эту транзакцию, вы увидите, что это повлияло на две строки. Чтобы вернуть таблицу к
ее исходному состоянию (как если бы вместо фиксирования произошел откат), выполните
следующую транзакцию:
USE pub s
GO
BEGI N T RAN un do _u pdat e_s tat e
UPDA TE pub lis he rs SET st ate = NU LL
WHER E s tat e = ' XX '
COMM IT TRA N u nd o_ upda te_ sta te
GO
И снова вы увидите, что это повлияло на две строки. Имена транзакций update_state
(модифицировать_состояние) и undo_update_state (отменить_модификацию_состояния),
используемые в операторе COMMIT TRAN, игнорируются в SQL Server: имена транзакций
используются просто для удобства программиста, чтобы можно было указать имя фиксируемой
транзакции. SQL Server автоматически фиксирует последнюю нефиксированную транзакцию,
запущенную перед фиксированием, независимо от указания имени транзакции.
Создание вложенных транзакций
В SQL Server разрешаются вложенные транзакции, т.е. транзакции внутри транзакции. В случае
вложенных транзакций вы должны явно фиксировать каждую внутреннюю транзакцию, чтобы
SQL Server получал информацию об окончании внутренней транзакции и мог освободить
ресурсы, используемые этой транзакцией, когда будет фиксирована внешняя транзакция. Если
ресурсы блокированы, другие пользователи не могут получать доступа к этим ресурсам. Хотя
вы должны явным образом включать оператор фиксации COMMIT для каждой транзакции,
SQL Server не выполняет фактического фиксирования внутренних транзакций, пока не
произойдет успешное фиксирование внешней транзакции; одновременно с этим SQL Server
освобождает все ресурсы, используемые внутренними и внешней транзакциями. При
неуспешном фиксировании внешней транзакции фиксирование внутренних транзакций не
выполняется и происходит откат внешней и всех внутренних транзакций. После фиксирования
внешней транзакции выполняется фиксирование внутренних тр анзакций. Иными словами, SQL
Server по сути игнорирует операторы COMMIT внутри внутренних вложенных транзакций – в
том смысле, что внутренние транзакции не фиксируются в ожидании окончательного
фиксирования или отката внешней транзакции, чтобы определить статус завершения всех
внутренних транзакций. (Это разъясняется в примерах на врезках "Практические советы"
далее.) Кроме того, в случае использования оператора отката ROLLBACK во внешней
транзакции или в любой из внутренних транзакций происходит откат всех этих транзакций. В
оператор ROLLBACK нельзя включать имя внутренней транзакции; в этом случае SQL Server
возвратит сообщение об ошибке. Можно включать имя внешней транзакции, имя точки
сохранения или не включать никакого имени. (Описание точек сохранения приводится в
разделе "Точки сохранения" далее.)
Рассмотрим пример вложенной транзакции, включающей в себя хранимую процедуру. Эта
хранимая процедура содержит явную транзакцию и вызывается из другой явной транзакции.
Поэтому транзакция в хранимой процедуре становится внутренней вложенной транзакцией. В
следующей последовательности SQL показаны операторы, используемые для создания
хранимой процедуры, и транзакция, которая вызывает эту хранимую процедуру. (Для
упрощения в этом примере используется оператор PRINT, а не реальные операторы
модифицирования данных.)
USE MyDB
GO
CREATE PROCEDURE Place_Order
--Создает хранимую процедуру
AS
BEGIN TRAN place_order_tran
PRINT 'Здесь должны быть SQL-операторы, выполняющие задачи по заказам'
COMMIT TRAN place_order_tran
GO
BEGIN TRAN Order_tran
PRINT 'Поместите заказ'
EXEC Place_Order
COMMIT TRAN Order_tran
--Начинает внешнюю транзакцию
--Вызывает хранимую процедуру, которая
--начинает внутреннюю транзакцию
--Фиксирует внутреннюю и внешнюю
--транзакции
GO
Выполнив эту программу, вы увидите результаты обоих операторов PRINT. Транзакция
place_order_tran должна содержать внутри хранимой процедуры оператор COMMIT,
отмечающий конец этой транзакции, но на самом деле это фиксирование не произойдет, пока
не будет выполнено фиксирование транзакции Order_tran. Фиксирование или откат
place_order_tran будет зависеть только от фиксирования Order_tran.
Хотя SQL Server не выполняет фактического фиксирования внутренних транзакций по
оператору COMMIT, но все же для каждого оператора COMMIT происходит изменение
системной переменной @@TRANCOUNT. Эта переменная следит за количеством активных
транзакций на одно соединение с пользователем. При отсутствии активных транзакций
значение @@TRANCOUNT равно 0. В начале каждой транзакции (с помощью BEGIN TRAN)
значение @@TRANCOUNT увеличивается на 1. После фиксирования каждой транзакции
значение @@TRANCOUNT уменьшается на 1. Когда значение @@TRANCOUNT становится
равным 0, фиксируется внешняя транзакция. Если во внешней транзакции или в любой из
внутренних транзакций выполняется оператор ROLLBACK, то значение @@TRANCOUNT
устанавливается равным 0. Помните, что для правильного уменьшения @@TRANCOUNT вы
должны указывать фиксирование (COMMIT) для каждой внутренней транзакции. Вы можете
проверять значение @@TRANCOUNT, чтобы определять наличие активных транзакций. Чтобы
увидеть значение @@TRANCOUNT, используйте оператор SELECT @@TRANCOUNT.
Использование @@TRANCOUNT
Рассмотрим пример того, как SQL Server использует переменную @@TRANCOUNT.
Предположим, что имеется вложенная транзакция, состоящая из двух транзакций: одной
внутренней и одной внешней, как в предыдущем примере. После запуска обеих транзакций, но
до того, как они фиксированы, значение @@TRANCOUNT равно 2. Внешняя транзакция не
может быть фиксирована, поскольку @@TRANCOUNT имеет ненулевое значение. После
оператора COMMIT внутренней транзакции SQL Server уменьшает @@TRANCOUNT до 1.
После оператора COMMIT внешней транзакции значение @@TRANCOUNT уменьшится до 0,
и будет выполнено фактическое фиксирование внешней и внутренней транзакций. Следующая
программа основана на предыдущем примере, но включает в себя считывание значений
@@TRANCOUNT:
USE MyDB
GO
DROP PROCEDURE Place_Order
GO
CREATE PROCEDURE Place_Order
--Создает хранимую процедуру.
AS
BEGIN TRAN place_order_tran
--Приращение TRANCOUNT
PRINT 'Здесь должны быть SQL-операторы, выполняющие задачи по заказам'
SELECT @@TRANCOUNT as TRANCOUNT_2
COMMIT TRAN place_order_tran
--Уменьшение TRANCOUNT.
GO
SELECT @@TRANCOUNT as TRANCOUNT_initial
BEGIN TRAN Order_tran
--Приращение TRANCOUNT.
PRINT 'Place an order'
SELECT @@TRANCOUNT as TRANCOUNT_1
EXEC Place_Order
--Вызывает хранимую процедуру, которая
--начинает внутреннюю транзакцию.
SELECT @@TRANCOUNT as TRANCOUNT_3
COMMIT TRAN Order_tran
--Уменьшение TRANCOUNT.
SELECT @@TRANCOUNT as TRANCOUNT_4
GO
При выполнении этой программы вы увидите на экране значения @@TRANCOUNT, которые
выводятся в следующем порядке: 0, 1, 2, 1, 0.
Примечание. Для явных транзакций, в которых используется BEGIN TRAN, вы должны
фиксировать каждую транзакцию явным образом. При использовании вложенных
транзакций SQL Server не сможет фиксировать внешние и внутренние транзакции, пока не
будет указано явное фиксирование всех внутренних транзакций с помощью оператора
COMMIT.
Неявный режим
В неявном режиме транзакция автоматически начинается при использовании определенных
операторов T-SQL и продолжается, пока не появится оператор явного окончания COMMIT или
ROLLBACK. Если оператор окончания не указан, то при отсоединении пользователя
происходит откат данной транзакции. Следующие операторы T-SQL являются началом новой
транзакции в неявном режиме:
ALTER TABLE
CREATE
DELETE
DROP
FETCH
GRANT
INSERT
OPEN
REVOKE
SELECT
TRUNCATE TABLE
UPDATE
Если один из этих операторов используется, чтобы начать неявную транзакцию, эта транзакция
продолжается, пока не будет явно указано ее окончание, даже если внутри транзакции снова
встретятся эти операторы. После явного фиксирования или отката данной транзакции
следующее появление этих операторов является началом новой транзакции. Этот процесс
продолжает действовать, пока не будет отключен неявный режим.
Чтобы задать неявный режим транзакций, вы можете использовать следующий оператор TSQL:
SET IMPLICIT_TRANSACTIONS {ON | OFF}
Значение ON активизирует неявный режим, и OFF отключает его. После отключения неявного
режима используется режим автофиксации.
Неявные транзакции полезно использовать, когда запускаются сценарии с модификациями
данных, которые требуется защитить внутри транзакции. Вы можете включить неявный режим
в начале сценария, выполнить необходимые модификации и отключить этот режим в конце
сценария. Во избежание конфликтов параллельных операций отключайте неявный режим после
модификации данных и перед просмотром данных. Если вслед за операцией фиксирования
следует оператор SELECT, то с него начинается новая транзакция в неявном режиме, и
соответствующие ресурсы не будут освобождены, пока не будет фиксирована эта транзакция.
Откаты транзакций
Откаты могут происходить в двух формах: автоматический откат, выполняемый SQL Server,
или программируемый вручную откат. В определенных случаях SQL Server выполнит для вас
откат. Но для обеспечения логической согласованности в ваших программах вы должны при
необходимости явным образом обращаться к оператору ROLLBACK. Рассмотрим более
подробно эти два метода.
Автоматические откаты
Как уже говорилось ранее в этой лекции, при сбое транзакции вследствие серьезной ошибки,
такой как потеря сетевого соединения при выполнении данной транзакции или отказ
клиентского приложения или компьютера, SQL Server выполняет автоматический откат
транзакции. Во время отката происходит отмена всех модификаций, выполненных в данной
транзакции, и освобождение всех ресурсов, использовавшихся этой транзакцией.
Если при исполнении какого-либо оператора возникает ошибка, такая как нарушение
ограничения или правила, то по умолчанию SQL Server автоматически выполняет откат только
этого определенного оператора, в котором возникла ошибка. Чтобы изменить это поведение, вы
можете использовать оператор SET XACT_ABORT. Если задать для XACT_ABORT значение
ON, то в случае ошибки исполнения SQL Server автоматически выполнит откат транзакции.
Этот метод полезно использовать, например, когда один оператор вашей транзакции не
выполняется из-за того, что он нарушает ограничение по внешнему ключу, и поэтому вы не
хотите, чтобы выполнялись последующие операторы. По умолчанию для XACT_ABORT задано
значение OFF.
SQL Server использует также автоматический откат при восстановлении сервера. Например,
если у вас отключился источник питания во время выполнения транзакций и произошла
перезагрузка системы, то при перезапуске SQL Server выполнит автоматическое
восстановление. При автоматическом восстановлении происходит чтение информации из
журнала транзакций для воспроизведения фиксированных транзакций, которые не были
записаны на диск, и отката транзакций, которые находились в процессе выполнения (еще не
были фиксированы) в момент отказа источника питания.
Программируемые откаты
С помощью оператора ROLLBACK вы можете указать точку в транзакции, где будет выполнен
откат. Оператор ROLLBACK прекращает данную транзакцию и выполняет откат (отмену) всех
выполненных изменений. Если вы запускаете откат в середине какой-либо транзакции, то
остальная часть этой транзакции игнорируется. Если, например, эта транзакция является
хранимой процедурой и оператор ROLLBACK выполняется в этой процедуре, то происходит
откат всей процедуры и переход к обработке оператора, следующего после вызова хранимой
процедуры.
Если вам нужно выполнить откат, исходя из количества строк, возвращенных оператором
SELECT, используйте системную переменную @@ROWCOUNT. Эта переменная содержит
количество строк, которое возвращается в результате запроса или на которое влияет
модификация или удаление. Если конкретное количество строк не имеет значения и вам просто
нужно определить наличие строки или строк для определенного условия, то вы можете
использовать совместно с оператором SELECT оператор IF EXISTS. Этот оператор не
возвращает количества строк данных, а только значениеTRUE или FALSE. Если результат
равен TRUE, то выполняется следующий оператор; если результат равен FALSE, то следующий
оператор не выполняется. В операторе IF EXISTS может также использоваться предложение
ELSE. Рассмотрим пример использования предложения IF EXISTS...ELSE. В следующей
транзакции происходит модификация значений ставки арендной платы (royalty) в таблице
roysched для двух ставок арендной платы (royalty rates) (16 процентов и 15 процентов), но если
ни одна из этих ставок не существует, то ни одна из команд UPDATE выполняться не будет.
Для обеспечения такого результата в этой транзакции используется оператор ROLLBACK.
BEGIN TRAN update_royalty
--Начать транзакцию.
USE pubs
IF EXISTS (SELECT titles.title, roysched.royalty FROM titles, roysched
WHERE titles.title_id = roysched.title_id
AND roysched.royalty = 16)
UPDATE roysched SET royalty = 17 WHERE royalty = 16
--Имеется 13 строк.
ELSE
ROLLBACK TRAN update_royalty
--ROLLBACK не выполняется.
IF EXISTS (SELECT titles.title, roysched.royalty FROM titles, roysched
WHERE titles.title_id = roysched.title_id
AND roysched.royalty = 15)
--Нет ни одной строки.
BEGIN
UPDATE roysched SET royalty = 20 WHERE royalty = 15
COMMIT TRAN update_royalty
END
ELSE
--Выполняется ROLLBACK.
ROLLBACK TRAN update_royalty
GO
В этой транзакции первый оператор IF EXISTS (SELECT...) определяет, что существует
несколько строк, и поэтому оператор UPDATE выполняется (показывая, что модификация
касается 13 строк). Второй оператор SELECT возвращает 0 строк, и поэтому второй оператор
UPDATE не выполняется, но выполняется оператор ROLLBACK TRAN update_royalty.
Поскольку ROLLBACK выполняет откат всех модификаций до самого начала данной
транзакции, то происходит откат первой модификации. Если снова выполнить первый оператор
SELECT, то вы по-прежнему увидите 13 строк со значением royalty, равным 16, как и было в
исходном состоянии базы данных, когда мы запускали данную транзакцию. И снова изменение
royalty на значение 17 будет отменено (будет выполнен откат) из-за оператора
ROLLBACK.
Примечание.В этой транзакции было использовано несколько новых ключевых слов: IF,
ELSE, BEGIN и END.
Откат транзакции нельзя выполнить после ее фиксирования. (Напомним, что внутренняя
транзакция на самом деле не фиксируется, пока не будет фиксирована внешняя транзакция.)
Чтобы можно было выполнить явный откат отдельной транзакции, оператор ROLLBACK
должен предшествовать оператору COMMIT. В случае вложенных транзакций после
фиксирования внешней транзакции (и, тем самым, внутренних транзакций) уже нельзя
выполнить откат ни одной из транзакций. Как уже отмечалось, вы не можете выполнить откат
только внутренних транзакций; должен быть выполнен откат всей транзакции (всех внутренних
транзакций и внешней транзакции). Поэтому, включив имя транзакции в оператор ROLLBACK,
проследите за тем, чтобы было указано имя внешней транзакции (во избежание путаницы и
сообщения об ошибке от SQL Server). Однако существует обходной путь, позволяющий
избежать отката всей транзакции и сохранить часть модификаций: вы можете использовать
точки сохранения.
Точки сохранения
Вы можете избежать отката всей транзакции; для этого нужно использовать точку сохранения,
которая позволяет выполнять откат только до определенной точки в транзакции, а не до самого
начала транзакции. Все модификации, выполненные до точки сохранения, остаются в силе и не
подвергаются откату; но для всех операторов, выполняемых после точки сохранения (которую
вы должны указать в транзакции) вплоть до оператора ROLLBACK, будет выполнен откат.
Затем начнут выполняться операторы, следующие за оператором ROLLBACK. Если вы затем
зададите откат транзакции без указания точки сохранения, то, как обычно, будет выполнен
откат всех модификаций вплоть до начала данной транзакции, т.е. будет отменена вся
транзакция. Отметим, что при откате транзакции до точки сохранения SQL Server не
освобождает блокированные ресурсы. Они будут освобождены после фиксирования транзакции
или после отката всей транзакции.
Чтобы указать точку сохранения в транзакции, используйте следующий оператор:
SAVE TRAN[SACTION] {имя_точки_сохранения | @переменная_с_именем_точки_сохранения}
Поместите точку сохранения в том месте транзакции, до которого вы хотите выполнять откат.
Чтобы выполнить откат до точки сохранения, используйте ROLLBACK TRAN вместе с именем
точки сохранения, как это показано ниже:
ROLLBACK TRAN имя_точки_сохранения
Вы можете использовать другие операторы T-SQL, чтобы продолжить транзакцию. Не забудьте
включить оператор COMMIT или другой оператор ROLLBACK после первого оператора
ROLLBACK, чтобы завершить всю транзакцию.
Дополнительная информация. Для получения более полной информации о точках
сохранения и примера их использования найдите "Save Transaction" (Сохранение
транзакций) в Books Online и выберите "Save Transaction (T-SQL)" в диалоговом окне Topics
Found.
Блокировка транзакций
В SQL Server используется объект, который называется блокировкой (lock); он препятствует
тому, чтобы несколько пользователей одновременно вносили изменения в базу данных и чтобы
один пользователь считывал данные, которые изменяет в этот момент другой пользователь.
Блокировка помогает обеспечивать логическую целостность транзакций и данных. Управление
блокировками осуществляется внутренним образом из программного обеспечения SQL Server и
захват блокировки осуществляется на уровне пользовательского соединения. Если пользователь
захватывает блокировку (становится ее владельцем) по какому-либо ресурсу, то эта блокировка
указывает, что данный пользователь имеет право на использование данного ресурса. К
ресурсам, которые может блокировать пользователь, относятся строка данных, страница
данных экстент (8 страниц), таблица или вся база данных. Например, если пользователь владеет
блокировкой по странице данных, то другой пользователь не может выполнять операции на
этой странице, которые повли яют на операции пользователя, владеющего данной блокировкой.
Поэтому любой пользователь не может модифицировать страницу данных, которая
блокирована и считывается в данный момент другим пользователем. Кроме того, ни один
пользователь не может владеть блокировкой, конфликтующей с блокировкой, которой уже
владеет другой пользователь. Например, два пользователя не могут одновременно владеть
блокировками на одновременную модификацию одной и той же страницы. Одна блокировка не
может одновременно использоваться более чем одним пользователем.
Система управления блокировками SQL Server автоматически захватывает и освобождает
блокировки в соответствии с действиями пользователей. Для управления блокировками не
требуется никаких действий со стороны DBA (администратора базы данных) или
программиста. Однако вы можете использовать программные подсказки (hint), чтобы задать для
SQL Server, какой тип блокировки нужно захватывать при выполнении определенного запроса
или модификации базы данных (см. раздел "Подсказки блокировки" далее).
В данном разделе мы рассмотрим уровни детализации блокировок, а также режимы
блокировки. Но сначала рассмотрим некоторые возможности управления блокировками,
которые повышают производительность SQL Server.
Возможности управления блокировками
SQL Server поддерживает блокировку на уровне строк, т.е. позволяет захватывать блокировку
по строке страницы данных или страницы индекса. Блокировка на уровне строк – самый
высокий уровень детализации, который можно получить в SQL Server. Этот нижний уровень
блокировки дает больше возможностей параллельной работы многим приложениям
оперативной обработки транзакций (OLTP). Блокировка на уровне строк особенно полезна,
когда выполняются вставки, обновления и удаления в таблицах и индексах.
В дополнение к возможности блокировки на уровне строк SQL Server обеспечивает простоту
администрирования для конфигурации блокировок. Вы не обязаны задавать вручную параметр
конфигурации блокировок, чтобы определить количество блокировок, доступное для
использования в SQL Server. По умолчанию при увеличении необходимого количества
блокировок SQL Server динамически выделяет дополнительное количество вплоть до предела,
определяемого памятью SQL Server. Если какое-то количество блокировок больше не
используется, SQL Server освобождает их. SQL Server также оптимизирован для динамического
выбора типа блокировки, который захватывается по какому-либо ресурсу – обычно это
блокировка на уровне строк для вставок, обновлений и удалений и блокировка страниц для
сканирования таблиц. В следующем разделе дается более подробное описание уровней
блокировок.
Уровни блокировок
Блокировки могут захватываться по целому ряду ресурсов; тип ресурса определяет уровень
детализации данной блокировки. В табл. 1-1 приводится список ресурсов, которые может
блокировать SQL Server, начиная с самого подробного и до самого крупного уровня
детализации.
Ресурс
Идентификатор
строки
Ключ
Страница
Экстент
Таблица
База данных
Таблица 1.1. Блокируемые ресурсы
Тип блокировки
Описание
Уровень строки
Блокирует отдельную строку в таблице
Уровень строки
Блокирует отдельную строку в индексе
Уровень страницы Блокирует
отдельную страницу размером 8 Кб
в таблице или индексе
Уровень экстента
Блокирует экстент – группу из 8
последовательных страниц данных или
страниц индекса
Уровень таблицы
Блокирует всю таблицу
Уровень базы данных
Блокирует всю базу данных
При снижении уровня детализации снижается степень параллельности. Например, блокировка
всей таблицы с помощью определенного типа блокировки может заблокировать доступ к этой
таблице другим пользователям. Но при этом снижается объем передачи дополнительной
служебной информации (непроизводительные затраты), поскольку используется меньшее
количество блокировок. По мере повышения уровня детализации, например, до уровня
блокировки страниц и строк, уровень параллельности возрастает, поскольку увеличивается
количество пользователей, одновременно получающих доступ к различным страницам и
строкам в таблице. В этом случае увеличиваются также непроизводительные затраты,
поскольку при отдельном доступе к большому числу строк или страниц требуется больше
блокировок.
SQL Server автоматически выбирает тип блокировки, подходящий для данной задачи,
минимизируя при этом непроизводительные затраты на блокировку. SQL Server также
автоматически определяет режим блокировки для каждой транзакции, касающейся
блокируемого ресурса; ниже приводится описание этих режимов.
Режимы блокировки
Режим блокировки указывает, каким образом одновременно работающие пользователи (или
транзакции) могут осуществлять доступ к какому-либо ресурсу. Захват каждого типа
блокировки происходит в одном из этих режимов. Имеется шесть режимов блокировки:
разделяемая блокировка (shared), блокировка изменений (update), монопольная блокировка
(exclusive), блокировка намерения (intent), блокировка схемы (schema) и блокировка массовых
изменений (bulk update).
Разделяемая блокировка
Режим разделяемой блокировки используется только для операций чтения, таких как операции
с помощью оператора SELECT. Этот режим позволяет одновременно выполняемым
транзакциям выполнять чтение одного и того же ресурса, но при этом ни одна из транзакций не
может модифицировать этот ресурс. Разделяемые блокировки освобождаются сразу после
окончания чтения, за исключением случаев, когда степень изолированности задана на уровне
повторяемого чтения или более высоком уровне или в транзакции задана подсказка
блокировки, подавляющая это поведение.
Блокировка изменений
Режим блокировки изменений используется для случаев, когда в данный ресурс могут быть
внесены изменения. Только одна транзакция может захватывать блокировку изменений по
определенному ресурсу. Если транзакция вносит изменения (например, когда по условию
поиска найдены строки для модификации), то блокировка изменений преобразуется в
монопольную блокировку (описана ниже); иначе она преобразуется в разделяемую блокировку.
Монопольная блокировка
Режим монопольной блокировки используется для операций, модифицирующих данные, таких
как обновления, вставки и удаления. При захвате транзакцией монопольной блокировки по
какому-либо ресурсу никакая другая транзакция не может выполнять чтение или модификацию
этого ресурса. Этот режим блокировки препятствует тому, чтобы одновременно работающие
пользователи изменяли одни и те же данные, что может приводить к ошибкам в данных.
Блокировка намерения
Режим блокировки намерения используется для создания иерархической структуры
блокировок. Например, блокировка намерения на уровне таблицы указывает, что SQL Server
предполагает захватывать блокировку по одной или нескольким страницами или строкам этой
таблицы. Обычно в случае, когда в транзакции требуется захватить блокировку по какому-либо
ресурсу, SQL Server сначала проверяет, существуют ли блокировки намерений для данного
ресурса. Если блокировка намерения захвачена транзакцией, которая находится в состоянии
ожидания этого ресурса, то вторая транзакция не может захватить монопольную блокировку.
Если не существует ни одной транзакции, владеющей блокировкой намерения и ожидающей
данный ресурс, то текущая транзакция может захватить монопольную блокировку по этому
ресурсу. Существует три следующих типа режимов блокировки намерения:
Разделяемое намерение (Intent shared). Указывает, что в транзакции предполагается
наложить на ресурс разделяемую блокировку.
Монопольное намерение (Intent exclusive). Указывает, что в транзакции
предполагается наложить на ресурс монопольную блокировку.
Разделяемо-монопольное намерение (Shared with intent exclusive). Указывает, что в
транзакции предполагается наложить разделяемую блокировку на некоторые ресурсы и
монопольную блокировку на другие ресурсы.
Для получения более подробной информации по этим типам режимов найдите "shared lock
mode" (режим разделяемой блокировки) в Books Online и выберите "Understanding Locking in
SQL Server" (Ознакомление с блокировкой в SQL Server) в диалоговом окне Topics Found.
Блокировка схемы
Режим блокировки схемы используется в тех случаях, когда выполняется операция изменения
схемы таблицы, такая как добавление колонки в таблицу, или когда компилируются запросы.
Для таких случаев существует два типа блокировок схемы: блокировка модификации схемы
(Sch-M) и блокировка стабильности схемы (Sch-S). Блокировка модификации схемы
используется при выполнении операции языка определения данных таблицы (DDL).
Блокировка стабильности схемы используется для компиляции запросов. Когда происходит
компиляция запроса, другие транзакции могут одновременно с этим запускать и захватывать
блокировки по данной таблице (даже монопольные блокировки), но операторы DDL не могут
применяться к таблице, если задана блокировка стабильности схемы.
Блокировка массовых изменений
Режим блокировки массовых изменений используется, когда вам нужно выполнить массовое
копирование данных в таблицу с подсказкой блокировки TABLOCK или когда вы задаете
параметр table lock on bulk load с помощью хранимой процедуры sp_tableoption. Целью
блокировки массовых изменений является предоставление процессам разрешения на
параллельное массовое копирование данных в одну таблицу, запрещая при этом доступ к этой
таблице любым процессам, которые не выполняют массового копирования.
Блокирование и взаимоблокировки
Блокирование (blocking) и взаимоблокировки (deadlock) – это две дополнительные
проблемы, которые могут возникать при одновременно выполняемых транзакциях. Они могут
приводить к серьезным проблемам системы, а также могут замедлять и даже останавливать
работу. Эти проблемы могут разрешаться в приложении, или SQL Server постарается сделать
все возможное для их разрешения; они будут описаны здесь только для того, чтобы вы
представляли их себе и понимали используемые концепции. Обход и разрешение проблем
блокирования и взаимоблокировки являются обязанностью программиста.
Блокирование возникает в том случае, когда одна транзакция владеет блокировкой по какомулибо ресурсу, а второй транзакции требуется конфликтный тип блокировки по этому ресурсу.
Вторая транзакция должна ждать, пока первая транзакция освободит свою блокировку; иными
словами, она блокирована первой транзакцией. Проблема блокирования обычно возникает,
когда какая-либо транзакция захватывает блокировку на длительный период времени, что
приводит к цепочке блокированных транзакций, ожидающих окончания других транзакций,
чтобы получить необходимые им блокировки; это состояние называют цепным блокированием.
На рис. 1 показан пример цепного блокирования.
Взаимоблокировка отличается от блокированной транзакции в том, что взаимоблокировка
возникает в случае двух блокированных транзакций, ожидающих друг друга. Например,
предположим, что одна транзакция владеет монопольной блокировкой по Таблице 1, а вторая
владеет монопольной блокировкой по Таблице 2. Прежде чем будет освобождена любая
монопольная блокировка, первой транзакции требуется блокировка по Таблице 2 и второй
транзакции – требуется блокировка по Таблице 1. Теперь каждая транзакция ждет, пока другая
транзакция освободит свою монопольную блокировку, но ни одна из транзакций не сделает
этого, пока не будет выполнено фиксирование или откат для завершения соответствующей
транзакции. Ни одна из транзакций не может завершиться, поскольку для продолжения работы
ей требуется блокировка, которой владеет другая транзакция, – ситуация взаимоблокировки!
Этот сценарий показан на рис. 2. При возникновении взаимоблокировки SQL Server прекращает
одну из транзакций, и ее требуется запустить заново.
Рис. 1. Цепное блокирование
Рис. 2. Взаимоблокировка
Дополнительная информация. Для получения информации о том, как избежать ситуации
блокирования и взаимоблокировки, найдите "Blocks" (Блокирование) в Books Online и
выберите "Understanding and Avoiding Blocking" (Как избежать блокирования) в диалоговом
окне Topics Found. Кроме того, найдите "Deadlocks" (Взаимоблокировки) в Books Online и
выберите "Avoiding Deadlocks and Handling Deadlocks" (Как избегать взаимоблокировок и
справляться с проблемой взаимоблокировок).
Подсказки блокировки
Подсказки блокировки – это ключевые слова T-SQL, которые можно использовать с
операторами SELECT, INSERT, UPDATE и DELETE, чтобы задать для SQL Server
использование предпочтительного типа блокировки на уровне таблицы для определенного
оператора. Вы можете использовать подсказки блокировки для переопределения принятого по
умолчанию уровня изолированности. Вам следует использовать этот метод только в случае
абсолютной необходимости, поскольку ваша неаккуратность может привести к блокированию
или взаимоблокировкам.
Рассмотрим ситуацию, где может оказаться полезным использование подсказок блокировки.
Предположим, что вы используете для всех транзакций принятый по умолчанию уровень
изолированности read uncommitted (чтение незафиксированных данных). При этом уровне
изолированности по данному ресурсу захватывается разделяемая блокировка только до
завершения чтения, и затем эта разделяемая блокировка освобождается. И если какая-либо
транзакция читает одни и те же данные дважды, то результаты чтения могут не совпасть,
поскольку другая транзакция могла захватить блокировку между первым и вторым чтениями и
модифицировать эти данные.
Чтобы избежать проблемы повторяемости чтения, вы можете задать уровень изолированности
serializable (упорядочиваемость), но это вынудит SQL Server захватить все разделяемые
блокировки, необходимые для операторов SELECT во всех транзакциях, пока не будет
завершена каждая транзакция. Иными словами, для целостности транзакций разделяемые
блокировки будут захвачены по таблице, указанной в операторе SELECT любой транзакции.
Если вы не хотите поддерживать упорядочиваемость для всех ваших транзакций, то можете
добавить какую-либо подсказку блокировки для определенного запроса. Подсказка блокировки
HOLDLOCK в операторе SELECT указывает SQL Server захват всех разделяемых блокировок
по таблице, заданной в операторе транзакции SELECT, вплоть до конца этой транзакции –
независимо от уровня изолированности. Тем самым при повторном чтении будет наблюдаться
согласованность данных (они не будут изменены другой транзакцией). Использование подсказ
ок блокировки не влияет на уровень изолированности для других транзакций.
Примечание. Оптимизатор запросов SQL Server автоматически определяет наиболее
эффективный план исполнения и типы блокировок для запроса. И поскольку оптимизатор
запросов автоматически выбирает подходящие тип или типы блокировок, подсказки
блокировки следует использовать, если только они хорошо изучены и когда это абсолютно
необходимо, иначе они могут отрицательным образом повлиять на параллельно выполняемые
задачи.
В следующем списке дается описание существующих подсказок блокировки на уровне таблиц.
HOLDLOCK. Захватывает разделяемую блокировку до завершения транзакции, а не
освобождает ее сразу после того, как уже не требуется соответствующая таблица,
страница или строка данных. Эквивалентно использованию подсказки блокировки
SERIALIZABLE.
NOLOCK. Применяется только к оператору SELECT. Не получает разделяемых
блокировок и не поддерживает монопольных блокировок; читает данные, которые
монопольно захвачены другой транзакцией. Эта подсказка позволяет читать
нефиксированные данные (dirty read).
PAGLOCK. Используется для блокировки на уровне страницы там, где обычно
используется блокировка на уровне таблицы.
READCOMMITTED. Выполняется сканирование с тем же поведением по блокировкам,
как у транзакций, использующих уровень изолированности read committed (принятый по
умолчанию уровень изолированности для SQL Server).
READPAST. Применяется только к оператору SELECT и только к строкам,
блокированным с помощью блокировки на уровне строк. Пропускаются строки,
блокированные другими транзакциями, которые обычно включаются в набор
результатов; возвращает результаты без этих блокированных строк. Может
использоваться только с транзакциями, выполняемыми на уровне изолированности read
committed.
READUNCOMMITTED. Эквивалентно NOLOCK.
REPEATABLEREAD. Выполняется сканирование с тем же поведением по
блокировкам, как у транзакций, использующих уровень изолированности repeatable read.
ROWLOCK. Используются блокировки на уровне строк вместо блокировки на уровне
страниц или на уровне таблиц.
SERIALIZABLE. Выполняется сканирование с тем же поведением по блокировкам, как
у транзакций, использующих уровень изолированности serializable. Эквивалентно
HOLDLOCK.
TABLOCK. Используется блокировка на уровне таблиц вместо блокировки на уровне
страниц или на уровне строк. SQL Server захватывает эту блокировку до завершения
оператора.
TABLOCKX. Используется монопольная блокировка по таблице. Внимание! Эта
подсказка препятствует доступу других транзакций к этой таблице.
UPDLOCK. Используются блокировки изменения вместо монопольных блокировок при
чтении таблицы. Эта подсказка позволяет другим пользователям только читать данные и
позволяет вам изменять эти данные; тем самым никакой другой пользователь не сможет
модифицировать эти данные после того, как вы в последний раз прочитали их.
Вы можете объединять совместимые подсказки блокировки, такие как TABLOCK и
REPEATABLEREAD, но вы не можете объединять конфликтующие подсказки, такие как
REPEATABLEREAD и SERIALIZABLE. Чтобы задать подсказку блокировки на уровне таблиц,
заключите эту подсказку в круглые скобки после имени таблицы в операторе T-SQL.
Следующая последовательность является примером использования подсказок TABLOCKX в
операторе SELECT:
USE pubs
SELECT COUNT(ord_num)
FROM sales (TABLOCKX)
WHERE ord_date > "Sep 13 1994"
GO
Подсказка TABLOCK сообщает SQL Server, что нужно захватить монопольную блокировку на
уровне таблиц по таблице продаж (sales), пока не будет выполнен данный оператор. Эта
подсказка обеспечивает, что никакая другая транзакция не сможет модифицировать данные в
таблице sales, пока данный запрос подсчитывает заказы из этой таблицы. Будьте осторожны,
используя этот вид подсказки, поскольку блокирование доступа других транзакций к этой
таблице может приводить к ожиданию других транзакций, снижению времени отклика и
цепному блокированию. И снова напомним: используйте подсказки блокировки на уровне
таблиц только в случае абсолютной необходимости.
Триггеры
Триггер – это специальный тип хранимой процедуры, которая запускается автоматически
системой SQL Server при модифицировании какой-либо таблицы одним из трех операторов:
UPDATE, INSERT или DELETE. Триггеры, как другие хранимые процедуры, могут содержать
простые или сложные операторы T-SQL. В отличие от других типов хранимых процедур
триггеры запускаются автоматически при указанных модификациях данных; их нельзя
запустить вручную по имени. Когда происходит запуск триггера, говорят, что он
активизируется (fire) . Триггер создается по одной таблице базы данных, но он может
осуществлять доступ и к другим таблицам и объектам других баз данных. Триггеры нельзя
создать по временным таблицам или системным таблицам, а только по определенным
пользователем таблицам или представлениям. Таблица, по которой определяется триггер,
называется таблицей триггера.
Существует пять типов триггеров: UPDATE, INSERT, DELETE, INSTEAD OF и AFTER. Как
следует из названий, триггер UPDATE активизируется, когда выполняются изменения
(обновления) в какой-либо таблице, триггер INSERT активизируется, когда происходит вставка
данных в таблицу и триггер DELETE активизируется, когда из таблицы удаляются данные.
Триггер INSTEAD OF выполняется вместо операции вставки, обновления или удаления.
Триггер AFTER активизируется после какой-либо запускающей операции и обеспечивает
механизм управления порядком выполнения нескольких триггеров.
Операции обновления, вставки и удаления называются событиями модификации данных. Вы
можете создать триггер, который активизируется при возникновении более чем одного события
модификации данных.
Например, вы можете создать триггер, который будет активизироваться, когда происходит
выполнение оператора UPDATE или INSERT, и такой триггер мы будем называть триггером
UPDATE/INSERT. Вы можете даже создать триггер, который будет активизироваться при
возникновении любого из трех событий модификации данных (триггер
UPDATE/INSERT/DELETE).
Вам следует знать некоторые из других общих правил, относящихся к триггерам. Это
следующие правила:
Триггеры запускаются только после завершения оператора, который вызвал их
активизацию. Например, UPDATE-триггер не будет активизироваться, пока не будет
выполнен оператор UPDATE.
Если какой-либо оператор пытается выполнить операцию, которая нарушает какое-либо
ограничение по таблице или является причиной какой-то другой ошибки, то связанный с
ним триггер не будет активизирован.
Триггер рассматривается как часть одной транзакции вместе с оператором, который
вызывает его. Поэтому из триггера можно вызвать оператор отката, и этот оператор
выполнит откат как триггера, так и соответствующего события модификации данных.
Кроме того, при возникновении серьезной ошибки, такой как разъединение с
пользователем, SQL Server автоматически выполнит откат всей транзакции.
Триггер активизируется только один раз для одного оператора, даже если этот оператор
влияет на несколько строк данных.
При активизации триггера результаты (если они есть) возвращаются вызывающей программе,
как и при использовании хранимых процедур. Обычно результаты не возвращаются из
оператора INSERT, UPDATE или DELETE (это операторы, вызывающие активизацию
триггера). Результаты обычно возвращаются из запросов SELECT. Поэтому, чтобы избежать
результатов, возвращаемых в приложение из триггера, откажитесь от использования операторов
SELECT и присваивания переменных в определении триггера. Если вам все-таки нужно, чтобы
триггер возвращал результаты, вы должны включить в приложение специальную обработку
там, где разрешены модификации в таблице, содержащей триггер, чтобы приложение получало
возвращаемые данные и обрабатывало их нужным образом.
Если вам нужно назначить переменную внутри триггера, используйте оператор SET NOCOUNT
ON в начале триггера, чтобы не было возвращаемых результирующих строк. Оператор SET
NOCOUNT указывает, нужно ли возвращать сообщение, указывающее, сколько строк было
затронуто запросом или оператором (например, "23 rows affected"). По умолчанию для SET
NOCOUNT задается значение OFF, а это означает выдачу сообщения о количестве затронутых
строк. Отметим, что этот параметр не влияет на реальные возвращаемые результаты из
оператора SELECT; он влияет только на возврат сообщений о количестве строк.
Расширение возможностей триггеров в SQL Server 2000
В SQL Server 2000 включены два новых триггера: триггер INSTEAD OF и триггер AFTER.
Триггер INSTEAD OF выполняется вместо запуска оператора SQL. Тем самым
переопределяется действие запускающего оператора. Вы можете задать по одному триггеру
INSTEAD OF на один оператор INSERT, UPDATE или DELETE. Триггер INSTEAD OF можно
задать для таблицы и/или представления Вы можете использовать каскады триггеров INSTEAD
OF, определяя представления поверх представлений, где каждое представление имеет
отдельный триггер INSTEAD OF. Триггеры INSTEAD OF не разрешается применять для
модифицируемых представлений, содержащих опцию WITH CHECK. Прежде чем задавать
триггер INSTEAD OF для одного из этих представлений, вы должны удалить опцию WITH
CHECK из модифицируемого представления с помощью команды ALTER VIEW. Триггер
AFTER активизируется после успешного выполнения всех операций, указанных в запускающем
операторе или операторах SQL. Сюда включается весь каскад действий по ссылкам и все
проверки ограничений. Если у вас имеется несколько триггеров AFTER, определенных по
таблице для определенного оператора или набора операторов, то вы можете задать, какой
триггер будет активизирован первым и какой триггер – последним. Если у вас определено
больше двух триггеров, то вы можете задать порядок активизации только первого и последнего
триггера. Все остальные триггеры активизируются случайным образом. Порядок активизации
задается с помощью оператора T-SQL sp_settriggerorder.
Кроме новых триггеров, SQL Server 2000 позволяет также задавать триггеры как по
представлениям, так и по таблицам. В предыдущих версиях SQL Server разрешалось задавать
триггеры только по таблицам. Триггеры по представлениям действуют точно так же, как и
триггеры по таблицам.
Когда использовать триггеры
Триггеры, как и ограничения, можно использовать для поддержки целостности данных и
деловых правил, но триггер не следует использовать как замену ограничения, когда достаточно
использовать только ограничение. Например, вам не нужно создавать триггер, который
проверяет наличие значения в колонке первичного ключа одной таблицы, чтобы определить,
можно ли вставить это значение в соответствующую колонку другой таблицы; в этой ситуации
прекрасно подойдет ограничение FOREIGN KEY. Однако вам может потребоваться триггер для
каскадирования изменений, вносимых в связанные таблицы базы данных. Например, вы можете
создать триггер DELETE по колонке title_id в таблице titles базы данных pubs, который удалит
строки в таблицах sales, roysched и titleauthor, если удаляется соответствующая строка в таблице
titles. (Мы увидим в следующем разделе, как создать этот триггер DELETE.)
Вы можете также использовать триггеры для проведения более сложных проверок по данным,
чем это допускается при использовании ограничения CHECK. Дело в том, что триггеры могут
обращаться к колонкам таблиц, отличных от таблицы, по которой они определены, в то время
как ограничения CHECK действуют в рамках только одной таблицы.
Триггеры также полезно использовать для выполнения нескольких операций в ответ на одно
событие модификации данных. Если вы создаете несколько триггеров для одного типа события
модификации данных, то все эти триггеры будут активизироваться, когда происходит это
событие. (Следует помнить, что если несколько триггеров определено по таблице или
представлению для какого-либо события, то каждый триггер должен иметь уникальное имя.)
Вы можете создать один триггер, который будет активизироваться для нескольких типов
событий модификации данных. Этот триггер будет активизироваться каждый раз, когда будет
возникать событие, для которого он определен. Поэтому триггер, определенный по
определенной таблице или представлению для вставок, изменений и удалений, будет
активизироваться при каждом возникновении любого из этих событий по данной таблице или
представлению.
Когда вы создаете какой-либо триггер, SQL Server создает две специальные временные
таблицы. Вы можете обращаться к этим таблицам при написании T-SQL-программы, которая
образует определение этого триггера. Эти таблицы всегда находятся в памяти и являются
локальными по отношению к данному триггеру, и каждый триггер имеет доступ только к своим
временным таблицам. Эти временные таблицы являются копиями таблицы базы данных, по
которой определяется данный триггер. Вы можете использовать эти временные таблицы, чтобы
увидеть влияние, оказанное каким-либо событием модификации данных на исходную таблицу.
Вы увидите примеры этих специальных таблиц (с именами deleted и inserted) в следующем
разделе.
Создание триггеров
Теперь, зная, что такое триггеры и когда они используются, перейдем к особенностям создания
триггеров. В этом разделе мы рассмотрим сначала метод создания триггеров с помощью T-SQL
и затем – метод с использованием Enterprise Manager. Чтобы использовать Enterprise Manager
для создания триггеров, вам нужно знать программирование с помощью T-SQL, как и в случае,
когда вы используете Enterprise Manager для создания других типов хранимых процедур.
Использование оператора CREATE TRIGGER
Чтобы использовать T-SQL для создания триггера, нужно применить оператор CREATE
TRIGGER. (В методе с Enterprise Manager также используется этот оператор.) Оператор
CREATE TRIGGER имеет следующий синтаксис:
CREA TE TRI GGE R им я_тр игг ера
ON { таб лиц а | п ре дста вле ние }
[WIT H E NCR YPT IO N]
{FOR | AFT ER | IN STEA D O F}
{[D ELE TE] [ ,] [IN SER T] [,] [ UP DATE ]}
[W ITH A PP END]
[N OT FO R REPL ICA TIO N]
AS
оп ера то р _ sql [.. .n]
Как видно из этого описания, вы можете создать триггер для оператора INSERT, UPDATE,
DELETE, INSTEAD OF или AFTER или для любой комбинации из этих пяти операторов. Вы
должны задать хотя бы одну опцию с предложением FOR. Это предложение указывает,
возникновение какого типа события модификации данных (или типов событий) по указанной
таблице приведет к активизации данного триггера.
При вызове триггера будут выполнены операторы SQL, указанные после ключевого слова AS.
Вы можете поместить сюда несколько операторов, включая программные конструкции, такие
как IF и WHILE. В определении триггера не допускаются следующие операторы:
ALTER DATABASE
CREATE DATABASE
DISK INIT
DISK RESIZE
DROP DATABASE
LOAD DATABASE
LOAD LOG
RECONFIGURE
RESTORE DATABASE
RESTORE LOG
Использование таблиц deleted и inserted
Как уже говорилось, при создании триггера вы имеете доступ к двум временным таблицам с
именами deleted и inserted. Их называют таблицами, но они отличаются от реальных таблиц баз
данных. Они хранятся в памяти, а не на диске.
Эти две таблицы имеют одинаковую структуру с таблицей (одинаковые колонки и типы
данных), по которой определяется данный триггер. Таблица deleted содержит копии строк, на
которые повлиял оператор DELETE или UPDATE. Строки, удаляемые из таблицы данного
триггера, перемещаются в таблицу deleted. После этого к данным таблицы deleted можно
осуществлять доступ из данного триггера. Таблица inserted содержит копии строк, добавленных
к таблице данного триггера при выполнении оператора INSERT или UPDATE. Эти строки
добавляются одновременно в таблицу триггера и в таблицу inserted. Поскольку оператор
UPDATE обрабатывается как DELETE, после которого следует INSERT, то при использовании
оператора UPDATE старые значения строк копируются в таблицу deleted, а новые значения
строк – в таблицу триггера и в таблицу inserted.
Если вы попытаетесь проверить содержимое таблицы deleted из триггера, который
активизирован в результате выполнения оператора INSERT, эта таблица окажется пустой, но
сообщение об ошибке не возникнет. Выполнение оператора INSERT не приводит к
копированию значений строк в таблицу deleted. Аналогичным образом, если вы попытаетесь
проверить содержимое таблицы inserted из триггера, который активизирован в результате
выполнения оператора DELETE, эта таблица окажется пустой. Выполнение оператора DELETE
не приводит к копированию значений строк в таблицу inserted. И здесь просмотр пустой
таблицы не приведет к сообщению об ошибке; поэтому для использования этих таблиц с целью
просмотра результатов модификаций убедитесь в том, что для доступа из триггера у вас
выбрана соответствующая таблица.
Примечание. Значения таблиц inserted и deleted доступны только из триггера. После
завершения работы триггера эти таблицы больше не доступны.
Создание вашего первого триггера
Чтобы увидеть, как работает триггер, создадим простую таблицу с определенным по ней
триггером, который печатает определенный текст при каждой модификации. Программа T-SQL
для создания этой таблицы имеет следующий вид:
USE MyDB
GO
CREATE
TABLE Bicycle_Inventory
(
make_name
char(10)
make_id
tinyint
model_name
char(12)
model_id
tinyint
in_stock
tinyint
on_order
tinyint
)
GO
NOT NULL,
NOT NULL,
NOT NULL,
NOT NULL,
NOT NULL,
NULL,
IF EXISTS (SELECT name
FROM
sysobjects
WHERE
name = "Print_Update" AND
type = "TR")
DROP TRIGGER Print_Update
GO
CREATE TRIGGER Print_Update
ON Bicycle_Inventory
FOR UPDATE
AS
PRINT "The Bicycle_Inventory table was updated"
GO
Чтобы проверить ваш триггер, выполним вставку строки в эту таблицу и затем модифицируем
ее:
INSERT
GO
INTO Bicycle_Inventory VALUES ("Trek",1,"5500",5,1,0)
UPDATE
SET
WHERE
GO
Bicycle_Inventory
make_id = 2
model_name = "5500"
Будет возвращено сообщение "The Bicycle_Inventory table was updated", так как в результате
выполнения оператора UPDATE был запущен триггер. В данном примере мы задали в нашем
триггере вывод сообщения, чтобы можно было увидеть работу этого триггера. Но обычно не
требуется, чтобы триггер возвращал выходные данные. Однако в определенных
обстоятельствах это может оказаться полезным. Например, предположим, что вы создаете
триггер типа UPDATE, который выполняет свои операторы, только когда в указанную колонку
заносится определенное значение, но эта модификация происходит неверно. Если добавить в
триггер оператор PRINT, который выводит значение этой колонки до выполнения других
операторов триггера, это, видимо, поможет определить, где лежит источник проблемы – в
логике самого триггера или в модифицируемых данных.
Создание триггера типа DELETE
Перейдем к более сложному примеру – триггер типа DELETE, который каскадирует изменения
в связанные таблицы. Мы создадим триггер, который будет удалять строки из таблиц sales,
roysched и titleauthor базы данных pubs, когда соответствующая строка удаляется из таблицы
titles. Мы будем использовать таблицу deleted, чтобы указывать, какие строки нужно удалить из
связанных таблиц. (Напомним, что при удалении какой-либо строки из таблицы триггера эта
строка копируется в таблицу deleted; затем вы можете проверить содержимое таблицы deleted и
удалить соответствующие записи в других таблицах.) Чтобы этот триггер мог работать, нам
нужно было бы удалить ограничения FOREIGN KEY из таблиц titleauthor, roysched и sales,
которые связаны с колонкой title_id таблицы titles. В данном примере мы создадим триггер так,
как будто этих ограничений FOREIGN KEY не существует. Если все же попытаться удалить
строку из таблицы titles, не удалив ограничений FOREIGN KEY, то вы получите сообщение об
ошибке от SQL Server и удаление не произойдет.
Примечание. Если вы не возражаете против изменения вашей базы данных pubs,
попытайтесь удалить ограничения FOREIGN KEY самостоятельно и затем создать данный
триггер. Проще всего удалить ограничения FOREIGN KEY с помощью схемы базы данных в
окне Enterprise Manager. Не забудьте удалить ограничения FOREIGN KEY, связанные с title_id.
Ниже показана программа T-SQL для этого триггера:
USE pubs
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "Delete_Title" AND
type = "TR")
DROP TRIGGER Delete_Title
GO
CREATE TRIGGER Delete_Title
ON titles
FOR DELETE
AS
DELETE
sales
FROM
sales, deleted
WHERE
sales.title_id = deleted.title_id
PRINT
"Deleted from sales"
DELETE
roysched
FROM
roysched, deleted
WHERE
roysched.title_id = deleted.title_id
PRINT
"Deleted from roysched"
DELETE
titleauthor
FROM
titleauthor, deleted
WHERE
titleauthor.title_id = deleted.title_id
PRINT
"Deleted from titleauthor"
GO
Чтобы проверить этот триггер, используйте оператор DELETE следующим образом:
DELETE
WHERE
GO
titles
title_id = "PC1035"
Если выполнить этот оператор DELETE, то произойдет активизация триггера (при условии, что
вы удалили отмеченные выше ссылки на внешние ключи [FOREIGN KEY]). Вы увидите
сообщение с количеством затронутых строк для события модификации данных по таблице
titles, после которого следуют сообщения, заданные в трех операторах PRINT из этого триггера,
и сообщения о количестве затронутых строк в трех других таблицах; эти выходные сообщения
показаны ниже:
(1 row(s) affected)
Deleted from sales
(5 row(s) affected)
Deleted from roysched
(1 row(s) affected)
Deleted from titleauthor
(1 row(s) affected)
Еще одно применение таблицы deleted – это сохранение всех строк, удаленных из таблицы, в
резервной таблице для последующего анализа данных. Например, чтобы сохранить строки,
удаленные из таблицы roysched, в новой таблице с именем roysched_backup, используйте
следующую программу:
USE pubs
GO
CREATE TABLE roysched_backup
(
title_id
tid
lorange
int
hirange
int
royalty
int
)
NOT NULL,
NULL,
NULL,
NULL
CREATE TRIGGER tr_roysched_backup
ON roysched
FOR DELETE
AS
INSERT INTO roysched_backup SELECT * FROM deleted
GO
SELECT * FROM roysched_backup
GO
Отметим, что мы присвоили резервной таблице те же имена колонок и те же типы данных, что
и в исходной таблице. Вы можете использовать другие имена колонок для таблицы
roysched_backup, но обязаны использовать одинаковые типы данных для обеих таблиц, чтобы
обеспечить совместимость.
Создание триггера типа INSERT
В этом примере мы создадим триггер типа INSERT (триггер, который активизируется при
выполнении оператора INSERT) по таблице sales. Этот триггер при вставке строки в таблицу
sales будет модифицировать колонку ytd_sales в таблице titles добавляя в нее значение, которое
было помещено в колонку qty таблицы sales. Этот триггер запрашивает таблицу inserted, чтобы
получить значение qty, которое было помещено в таблицу sales. Мы включим в этот запрос
оператор SELECT *, с помощью которого увидим, что содержит таблица inserted. Ниже
приводится T-SQL-текст для этого триггера:
USE pubs
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "Update_ytd_sales" AND
type = "TR")
DROP TRIGGER Update_ytd_sales
GO
CREATE TRIGGER Update_ytd_sales
ON sales
FOR INSERT
AS
SELECT
*
FROM
inserted
UPDATE
titles
SET
ytd_sales = ytd_sales + qty
FROM
inserted
WHERE
titles.title_id = inserted.title_id
GO
Отметим, что мы использовали в операторе UPDATE предложение FROM
источник_для_таблицы (FROM inserted), чтобы указать, что значение qty должно поступать из
таблицы inserted. Теперь выполним следующий оператор INSERT для просмотра результатов из
этого триггера:
INSERT INTO sales VALUES(7066, 1, "March 7, 2000", 100, "Net 30",
"BU1111")
GO
Вы увидите следующие результаты. В первом наборе результатов показана строка, выбранная
из таблицы inserted, и второе сообщение "1 row(s) affected" получено из оператора UPDATE.
stor_id
ord_num
ord_date
qty
payterms
title_id
--------------------------------------------------------------------------------------7066
1
2000-03-07 00:00:00.000
100
Net 30
BU1111
(1 row(s) affected)
(1 row(s) affected)
Создание триггера типа UPDATE
Теперь создадим UPDATE-триггер, который будет просматривать колонку price (цена) при
модификации таблицы titles, чтобы убедиться, что цена книги не возросла более чем на 10
процентов. В противном случае будет использован оператор ROLLBACK, который выполнит
откат данного триггера и оператора, вызвавшего триггер. Если триггер активизирован из
транзакции, то произойдет откат всей транзакции. Таблицы deleted и inserted используются в
данном примере для проверки изменения цены. Ниже приводится определение этого триггера:
USE pubs
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "Update_Price_Check" AND
type = "TR")
DROP TRIGGER Update_Price_Check
GO
CREATE TRIGGER Update_Price_Check
ON titles
FOR UPDATE
AS
DECLARE
@orig_price money, @new_price money
SELECT
@orig_price = price from deleted
PRINT
"orig price ="
PRINT
CONVERT(varchar(6),@orig_price)
SELECT
@new_price = price from inserted
PRINT
"new price ="
PRINT
CONVERT(varchar(6),@new_price)
IF (@new_price > (@orig_price * 1.10))
BEGIN
PRINT "Rollback occurred"
ROLLBACK
END
ELSE
PRINT "Price is OK"
GO
Чтобы проверить этот триггер, выполните сначала следующие операторы, чтобы проверить
текущую цену книги с идентификатором заголовка (title_id) BU1111:
SELECT
FROM
WHERE
GO
price
titles
title_id = "BU1111"
Цена составляет $11.95. Теперь попробуем увеличить цену на 15 процентов с помощью
следующих операторов:
UPDATE
SET
WHERE
GO
titles
price = price * 1.15
title_id = "BU1111"
Вы увидите следующие результаты:
orig price = (исходная цена)
11.95
new price = (новая цена)
13.74
Rollback occurred (Произошел откат)
Произошла активизация триггера, который вывел исходную цену и новую цену и выполнил
откат (поскольку цена возросла более чем на 10 процентов).
Теперь снова проверим цену, чтобы убедиться, что был выполнен откат этой модификации.
Используйте следующий T-SQL-набор:
SELECT
FROM
WHERE
GO
price
titles
title_id = "BU1111"
Цена снова стала равной $11.95, а это означает, что был выполнен откат модификации.
Теперь увеличим цену на 9 процентов и убедимся, что цена изменена. Для этой модификации
используется следующий T-SQL-набор:
UPDATE
SET
WHERE
GO
titles
price = price * 1.09
title_id = "BU1111"
SELECT
FROM
WHERE
GO
price
titles
title_id = "BU1111"
Цена стала равной $13.03, и поскольку изменение составило меньше 10 процентов, то триггер
не инициировал откат.
Создавая триггер UPDATE, вы можете задать, чтобы этот триггер выполнял определенные
операторы только в случае модификации определенной колонки или колонок. Например,
давайте снова создадим предыдущий триггер, но на этот раз будет использовать предложение
IF UPDATE, чтобы указать, что триггер проверяет колонку price, только если была обновлена
сама эта колонка:
USE pubs
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "Update_Price_Check" AND
type = "TR")
DROP TRIGGER Update_Price_Check
GO
CREATE TRIGGER Update_Price_Check
ON titles
FOR UPDATE
AS
IF UPDATE (price)
BEGIN
DECLARE
@orig_price money, @new_price money
SELECT
@orig_price = price
FROM
deleted
PRINT
"orig price ="
PRINT
CONVERT(varchar(6),@orig_price)
SELECT
@new_price = price
FROM
inserted
PRINT
"new price ="
PRINT CONVERT(varchar(6),@new_price)
IF (@new_price > (@orig_price * 1.10))
BEGIN
PRINT "Rollback occurred"
ROLLBACK
END
ELSE
PRINT "Price is OK"
END
GO
Теперь в случае модификации одной или нескольких колонок в таблице titles, за исключением
колонки price, триггер пропустит операторы между ключевыми словами BEGIN и END в
операторе IF, т.е. фактически будет пропущен весь триггер.
Чтобы проверить этот триггер, выполните следующие операторы T-SQL, модифицирующие
сумму продаж за год (значение в колонке ytd_sales) для книги со значением BU1111 в колонке
title_id.
UPDATE
SET
WHERE
GO
titles
ytd_sales = 123
title_id = "BU1111"
Отметим, что в выходные результаты не будут включены никакие сообщения, указанные в
операторах PRINT данного триггера. Сам триггер активизируется, так как мы модифицировали
таблицу titles. Но поскольку была модифицирована колонка ytd_sales, а не колонка price, то
результатом условия IF было значение FALSE. Поэтому операторы данного триггера не
выполнялись. Этот метод препятствует тому, чтобы SQL Server обрабатывал ненужные
операторы.
Создание триггера INSTEAD OF
Триггер INSTEAD OF позволяет вам управлять тем, что происходит, когда выполняются
функции INSERT, UPDATE или DELETE. Триггер INSTEAD OF используется в первую
очередь при модификации объединенного представления (union view). Обычно объединенные
представления недоступны для модификации, поскольку SQL Server "не знает", какую базовую
(underlying) таблицу или таблицы нужно модифицировать. Для обхода этой ситуации вы
определяете по данному представлению триггер INSTEAD OF, позволяющий модифицировать
базовые (underlying) таблицы. Рассмотрим один пример. Следующие операторы T-SQL создают
представление под именем TitlesByAuthor со ссылкой на таблицы authors, titles и titleauthor.
USE pubs
GO
CREATE
AS
SELECT
FROM
VIEW TitlesByAuthor
authors.au_id, authors.au_lname, titles.title
authors INNER JOIN
titleauthor ON authors.au_id = titleauthor.au_id INNER JOIN
titles ON titleauthor.title_id = titles.title_id
GO
Теперь после создания представления мы используем следующий набор T-SQL для вывода всех
строк (они также показаны здесь), отвечающих критериям данного представления:
USE pubs
GO
SELECT *
FROM
TitlesByAuthor
GO
au_id
au_lname
title
————— ——————— —————————————————————
238-95-7766
Carson
But Is It User Friendly?
724-80-9391
MacFeather
Computer Phobic AND Non-Phobic Individuals:
756-30-7391
Karsen
Computer Phobic AND Non-Phobic Individuals:
267-41-2394
O’Leary
Cooking with Computers:
724-80-9391
MacFeather
Cooking with Computers:
486-29-1786
Locksley
Emotional Security: A New Algorithm
648-92-1872
Blotchet-Halls
Fifty Years in Buckingham Palace Kitchens
899-46-2035
Ringer
Is Anger the Enemy?
998-72-3567
Ringer
Is Anger the Enemy?
998-72-3567
Ringer
Life Without Fear
486-29-1786
Locksley
Net Etiquette
807-91-6654
Panteley
Onions, Leeks, and Garlic:
172-32-1176
White
Prolonged Data Deprivation: Four Case Studies
427-17-2319
Dull
Secrets of Silicon Valley
846-92-7186
Hunter
Secrets of Silicon Valley
712-45-1867
del Castillo
Silicon Valley Gastronomic Treats
274-80-9391
Straight
Straight Talk About Computers
267-41-2394
O’Leary
Sushi, Anyone?
472-27-2349
Gringlesby
Sushi, Anyone?
672-71-3249
Yokomoto
Sushi, Anyone?
213-46-8915
Green
The Busy Executive’s Database Guide
409-56-7008
Bennet
The Busy Executive’s Database Guide
722-51-5454
DeFrance
The Gourmet Microwave
899-46-2035
Ringer
The Gourmet Microwave
213-46-8915
Green
You Can Combat Computer Stress!
(25 row(s) affected)
Если вы попытаетесь удалить из этого представления строку, в которой значение колонки
au_lname равно Carson, то появится следующее сообщение:
Server: Msg 4405, Level 16, State 1, Line 1 View or function 'TitlesByAuthor' is
not updatable
because the FROM clause names multiple tables. (Представление или
функция 'TitlesByAuthor' недоступна для модифицирования,
поскольку предложение FROM ссылается names на несколько таблиц)
Чтобы обойти эту ситуацию, мы создадим для операции удаления триггер INSTEAD OF.
Следующий набор операторов T-SQL создает триггер INSTEAD OF с именем Delete_It:
USE pubs
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = 'Delete_It' AND
type = 'TR')
DROP TRIGGER Delete_It
GO
CREATE TRIGGER Delete_It
ON TitlesByAuthor
INSTEAD OF DELETE
AS
PRINT
'Row from authors before deletion...'
SELECT
au_id, au_lname, city, state
FROM
authors
WHERE
au_lname = 'Carson'
PRINT
UPDATE
SET
WHERE
PRINT
SELECT
FROM
WHERE
GO
'Deleting row from authors...'
authors
au_lname = 'DELETED'
au_lname = 'Carson'
'Verifying deletion...'
au_id, au_lname, city, state
authors
au_lname = 'Carson'
И если теперь мы введем операторы для удаления строки Carson из этого представления, то
произойдет активизация триггера INSTEAD OF и мы получим следующие выходные
результаты:
Row from authors before deletion... (Строка из authors перед удалением)
au_id
au_name
city
state
---------------------------------------------------------------------------------238-95-7766
Carson
Berkeley
CA
(1 row(s) affected)
Deleting row from authors...
(Удаление строки из authors)
(1 row(s) affected)
Verifying deletion...:
(Проверка удаления)
au_id
au_name
city
state
---------------------------------------------------------------------------------(0 row(s) affected)
Использование триггеров AFTER
Как уже говорилось ранее в этой лекции, триггер AFTER – это просто триггер, который
активизируется после завершения указанного события модификации данных. Если у вас
определен по таблице более чем один триггер AFTER для определенного события или набора
событий, то вы можете задать, какой триггер будет активизироваться первым и какой –
последним. Любые другие триггеры, определенные по данной таблице для этого события или
набора событий, будут активизироваться в случайном порядке. Первый и последний триггеры
задаются с помощью оператора T-SQL sp_settriggerorder. Этот оператор имеет следующий
синтаксис:
sp_settriggerorder
[@triggername =] 'имя_триггера',
[@order=] {'first' | 'last' | 'none'}
Рассмотрим один пример. Предположим, что у нас четыре триггера, определенных по таблице:
MyTrigger, MyOtherTrigger, AnotherTrigger и YetAnotherTrigger. Мы хотим убедиться, что после
запускающего события AnotherTrigger активизируется первым и MyTrigger активизируется
последним. Мы вводим следующие операторы T-SQL:
sp_s ett rig ger or de r
go
sp_s ett rig ger or de r
go
sp_s ett rig ger or de r
go
sp_s ett rig ger or de r
go
@t rig ger nam e = 'Ano the rTr igg er ', @or der = 'fi rs t'
@t rig ger nam e = 'MyT rig ger ', @o rd er = 'l ast '
@t rig ger nam e = 'MyO the rTr igg er ', @or der = 'no ne '
@t rig ger nam e = 'Yet Ano the rTr ig ge r', @or der = 'n on e'
Обозначение "none" для MyOtherTrigger и YetAnotherTrigger указывает, что SQL Server должен
активизировать эти триггеры случайным образом после активизации AnotherTrigger и до
активизации MyTrigger. Поскольку этот случайный порядок активизации принят для триггеров
по умолчанию, то вы не обязаны явно запускать оператор sp_settriggerorder для триггеров,
которые запускаются случайным образом.
Использование вложенных триггеров
Вложенные триггеры – это триггеры, которые активизируются другими триггерами. Они
отличаются от рекурсивных триггеров, которые активизируют сами себя. Вложенный триггер
инициируется, когда событие модификации данных внутри другого триггера активизирует этот
вложенный триггер. Как и в SQL Server 7, SQL Server 2000 допускает до 32 уровней
вложенности триггеров. Один триггер активизирует второй триггер, который, в свою очередь,
активизирует третий триггер, и т.д. вплоть до 32-го триггера. Использование вложенных
триггеров разрешается в SQL Server 2000 по умолчанию. Вы можете указать, разрешается ли в
SQL Server использование вложенных триггеров, задав соответствующий параметр
конфигурации сервера для вложенных триггеров Например, чтобы блокировать использование
вложенных триггеров, выполните следующую команду:
sp_configure "nested triggers", 0
GO
Значение 0 блокирует использование вложенных триггеров; значение 1 разрешает их
использование. Рассмотрим пример использования вложенных триггеров. В этом примере мы
создадим вложенные триггеры, которые будут выполнять каскадные удаления при удалении
заголовка книги из таблицы titles. (См. раздел "Создание триггера типа DELETE" ранее.) Мы
создали отдельный триггер, который выполняет эту операцию. Сначала мы удалим этот
триггер, чтобы он не активизировался. Затем мы создадим три триггера. Второй и третий
триггеры будут вложенными триггерами. Первый триггер будет активизировать второй триггер,
который будет активизировать третий триггер. Вот эта программа:
USE pubs
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "Delete_Title" AND
type = "TR")
DROP TRIGGER Delete_Title
GO
CREATE TRIGGER TR_on_titles
ON titles
FOR DELETE
AS
DELETE
sales
FROM
sales, deleted
WHERE
sales.title_id = deleted.title_id
PRINT
"Deleted from sales"
GO
CREATE TRIGGER TR_on_sales
ON sales
DELETE
roysched
FROM
roysched, deleted
WHERE
roysched.title_id = deleted.title_id
PRINT
"Deleted from roysched"
GO
CREATE TRIGGER TR_on_roysched
ON roysched
DELETE
titleauthor
FROM
titleauthor, deleted
WHERE
titleauthor.title_id = deleted.title_id
PRINT
"Deleted from titleauthor"
GO
Для успешной работы этих триггеров вы должны удалить ограничения FOREIGN KEY по
таблицам, указанным в этих триггерах (см. раздел "Создание триггера типа DELETE" ранее).
Чтобы проверить, работают ли все эти триггеры, запустите следующий оператор DELETE:
DELETE
FROM
WHERE
GO
titles
title_id = "PS7777"
Вы увидите следующий набор результатов:
(2 row(s) affected)
(1 row(s) affected)
Deleted from titleauthor
(Удалено из titleauthor)
(2 row(s) affected)
Deleted from roysched
(Удалено из roysched)
(1 row(s) affected)
Deleted from sales
(Удалено из sales)
(1 row(s) affected)
При сбое на любом уровне набора вложенных триггеров происходит отмена всей транзакции и
откат модификаций всех данных до начала данной транзакции.
Использование Enterprise Manager
Чтобы создать триггер с помощью Enterprise Manager, вы просто вводите свои операторы TSQL в окне Trigger Properties (Свойства триггера). Для использования этого метода выполните
следующие шаги.
1. В окне Enterprise Manager щелкните правой кнопкой мыши на имени таблицы, по
которой вы хотите создать триггер. В появившемся контекстном меню укажите All Tasks
(Все задачи) и затем выберите из подменю All Tasks пункт Manage Triggers (Управление
триггерами). Появится окно Trigger Properties (рис. 3).
Рис. 3. Окно Trigger Properties (Свойства триггера)
2. Введите в окне Text предложения T-SQL для вашего триггера. На рис. 4 показано окно
Trigger Properties, содержащее T-SQL-текст триггера с именем Print_Update.
Рис. 3. Окно Trigger Properties с текстом триггера
3. Щелкните на кнопке Check Syntax (Проверить синтаксис) для проверки синтаксиса. При
отсутствии синтаксических ошибок появится диалоговое окно, показанное на рис. 4. В
противном случае внесите необходимые исправления. Щелкните на кнопке Apply
(Применить), чтобы создать данный триггер. Имя нового триггера теперь появится в
раскрывающемся списке Name (Имя). На рис. 5 показан список с включенным в него
именем вашего нового триггера.
Рис. 4. Диалоговое окно с сообщением об успешном завершении синтаксической
проверки
4. Окно Trigger Properties остается открытым, что позволяет вам создавать новые триггеры
по данной таблице. Если вам не нужно создавать новые триггеры, щелкните на кнопке
Close (Закрыть).
Рис. 5. Имя нового триггера в раскрывающемся списке Name
Управление триггерами
Теперь, когда вы знаете, как создавать триггер, вам надо научиться управлять триггерами. В
этом разделе мы рассмотрим сначала управления триггерами с помощью команд T-SQL, а затем
– управление с помощью Enterprise Manager.
Управление триггерами с помощью операторов T-SQL
Имеется несколько операторов, с помощью которых можно управлять триггерами. Вы можете
просматривать текст триггера, просматривать существующие триггеры по определенной
таблице, изменять текст триггера, удалять триггеры и разрешать или блокировать
использование триггеров. Все эти возможности описаны в данном разделе.
Просмотр текста триггера
Информацию о триггерах можно получить с помощью двух системных хранимых процедур:
sp_helptext и sp_helptrigger. Процедура sp_helptext, после которой указывается имя триггера,
используется для вывода на экран текста, который использовался для создания этого триггера.
Например, для просмотра определения созданного ранее триггера Print_Update используйте
следующий оператор:
USE MyDB
GO
sp_helptext Print_Update
GO
Результаты выглядят следующим образом:
Text
------------------------------------------------CREATE TRIGGER Print_Update
ON Bicycle_Inventory
FOR UPDATE
AS
PRINT "The Bicycle Inventory table was updated."
Просмотр триггеров, имеющихся по какой-либо таблице
Для просмотра триггеров, существующих по определенной таблице (или чтобы увидеть, что нет
ни одного триггера), используйте хранимую процедуру sp_helptrigger, после которой укажите
имя этой таблицы. Для просмотра триггеров по таблице MyTable используйте следующий
оператор:
USE MyDB
GO
sp_helptrigger MyTable
GO
Ниже приводятся результаты:
trigger_name
trigger_owner
isupdate
isdelete isinsert
isafter
isinsteadof
---------------------------------------------------------------------------------------------Print_Update
dbo
1
0
0
1
0
(1 row affected)
В результатах показано имя триггера, владелец триггера и тип события модификации данных
(или типы событий), активизирующего данный триггер.
Результирующие колонки isupdate, isdelete, isinsert, isafter и isinsteadof содержат значение 1,
если триггер активизируется событием модификации данных, которое указано именем колонки,
или 0 в противном случае. Если триггер активизируется более чем одним типом событий
модификации данных, то значение 1 может быть в нескольких колонках.
Использование оператора ALTER TRIGGER
Чтобы изменить определение триггера, вы можете удалить и заново создать соответствующий
триггер или использовать оператор ALTER TRIGGER. Для этого оператора используется тот же
синтаксис, что и для оператора CREATE TRIGGER. Если вы модифицируете триггер, то
должны переопределить весь этот триггер. Например, для изменения триггера Print_Update,
чтобы он активизировался при выполнении операторов INSERT или UPDATE, которые влияют
на таблицу Bicycle_Inventory, используйте следующий текст:
USE MyDB
GO
ALTER TRIGGER Print_Update
ON Bicycle_Inventory
FOR UPDATE, INSERT
AS
PRINT "Bicycle_Inventory was updated or a row was inserted"
GO
Теперь старая версия данного триггера не существует; она заменена новой версией. Теперь этот
триггер будет активизироваться при изменениях в Bicycle_Inventory и при вставке строк в эту
таблицу. Ниже показаны примеры операторов, используемых для выполнения этих операций:
INSERT
GO
INTO Bicycle_Inventory VALUES ("Trek",1,"Lance S.E.",1,0,1)
UPDATE
SET
WHERE
GO
Bicycle_Inventory
in_stock = 1
model_name = "Lance S.E."
Использование оператора DROP TRIGGER
Для удаления триггера из таблицы используйте оператор DROP TRIGGER. Вы можете удалить
триггер, который вам больше не нужен. Этот оператор имеет следующий синтаксис:
DROP TRIGGER имя_триггера
Чтобы удалить триггер Print_Update, используйте следующий оператор:
USE Bicycle_Inventory
GO
DROP TRIGGER Print_Update
GO
Теперь при попытке увидеть существующие триггеры по таблице MyTable (с помощью
следующих операторов T-SQL) вы увидите, что нет ни одного триггера:
USE MyDB
GO
sp_helptrigger MyTable
GO
Примечание. Если вы удаляете таблицу, то при этом автоматически удаляются все триггеры по
данной таблице.
Блокирование (disabling) и разблокирование (enabling) триггеров
Вы можете использовать оператор ALTER TABLE для разблокирования и блокирования
триггера без удаления определения этого триггера из таблицы. Поскольку каждый триггер
создается по определенной таблице, то мы используем оператор ALTER TABLE вместо
оператора ALTER TRIGGER. Создадим триггер из первого примера этой лекции, чтобы
использовать его в следующем примере:
USE MyDB
GO
IF EXISTS
(SELECT
FROM
WHERE
name
sysobjects
name = "Print_Update" AND
type = "TR")
DROP TRIGGER Print_Update
GO
CREATE TRIGGER Print_Update
ON Bicycle_Inventory
FOR UPDATE
AS
PRINT "Bicycle_Inventory table was updated"
GO
В момент создания этот триггер автоматически становится доступен для активизации (он
разблокирован). Чтобы блокировать активизацию этого триггера (до момента, когда будет
снова задано разблокирование) с сохранением определения этого триггера в соответствующей
таблице, используйте опцию DISABLE TRIGGER, как это показано ниже:
ALTER TABLE Bicycle_Inventory
DISABLE TRIGGER Print_Update
GO
Теперь после этого изменения в таблице Bicycle_Inventory триггер Print_Update не будет
активизироваться, пока не будет явно задано разблокирование с помощью опции ENABLE
TRIGGER, как это показано ниже:
ALTER TABLE Bicycle_Inventory
ENABLE TRIGGER Print_Update
GO
Предложения ENABLE TRIGGER и DISABLE TRIGGER полезно использовать, когда вы
хотите прекратить активизацию триггера, но сохранить его на тот случай, если он понадобится
в будущем. Определение триггера не изменяется, поэтому вам не придется создавать его снова
в будущем; вам нужно будет только разблокировать его.
Управление триггерами с помощью Enterprise Manager
Используя Enterprise Manager, вы можете управлять вашими триггерами с помощью
графического интерфейса. Но вам по-прежнему нужно знать, как создаются программы на
языке T-SQL.
Удаление триггера
Чтобы удалить триггер с помощью Enterprise Manager, выполните следующие шаги.
1. Откройте окно Trigger Properties, щелкнув правой кнопкой мыши на имени таблицы,
указав в контекстном меню All Tasks и выбрав пункт Manage Triggers из подменю All
Tasks.
2. В окне Trigger Properties выберите имя данного триггера из раскрывающегося списка
Name и щелкните на кнопке Delete (Удалить).
3. Появится диалоговое окно подтверждения (рис. 6). Щелкните на кнопке Yes (Да), чтобы
удалить выбранный вами триггер.
Рис. 6. Диалоговое окно, в котором вы подтверждаете удаление триггера
Модифицирование триггера
Чтобы модифицировать триггер с помощью Enterprise Manager, выполните следующие шаги.
1. Откройте окно Trigger Properties, щелкнув правой кнопкой мыши на имени таблицы,
указав в контекстном меню All Tasks и выбрав пункт Manage Triggers из подменю All
Tasks.
2. Выберите имя данного триггера из раскрывающегося списка Name.
3. Отредактируйте текст T-SQL в окне Text. Для отступов в тексте используйте клавиши
Ctrl+Tab. Вы можете использовать оператор CREATE TRIGGER или ALTER TRIGGER.
В обоих случаях SQL Server удалит существующий триггер и создаст его заново. Вы
можете даже использовать оператор CREATE TRIGGER, указав после него имя
существующего триггера. Вы не получите сообщения об ошибке, которое возникло бы
при использовании интерактивных OSQL или ISQL. Закончив редактирование, щелкните
на кнопке Apply. После SQL Server автоматически модифицирует определение данного
триггера.
Практическая часть
1. Изучить теоретическую часть.
2. Разработать для своего приложения из лабораторной № 4 триггеры, которые могут
позволить выполнять:
a. Расчет результатов или других вычисляемых значений полей.
b. Операции удаления, добавления, модификации записей
3. Разработать транзакции (не менее двух) для своего приложения.
4. Показать работу с блокировками в MS SQL Server:
a. Запрещать пользователям чтение или модификацию данных, находящихся в
процессе изменения другими пользователями
b. Запрещать модификацию данных, находящихся под влиянием незавершенных
транзакций.
Лабораторная работа 5
Тема: Система безопасности в MS SQL Server 2000.
Цель работы:
Теоретические сведения
В современных СУБД поддерживается один из двух наиболее общих подходов к вопросу
обеспечения безопасности данных: избирательный подход и обязательный подход. В обоих
подходах единицей данных или «объектом данных», для которых должна быть создана система
безопасности, может быть как вся база данных целиком, так и любой объект внутри базы
данных. Эти два подхода отличаются следующими свойствами:
□ В случае избирательного управления некоторый пользователь обладает
различными правами (привилегиями или полномочиями) при работе с данными
объектами. Разные пользователи могут обладать разными правами доступа к
одному и тому же объекту. Избирательные права характеризуются значительной
гибкостью.
□ В случае избирательного управления, наоборот, каждому объекту данных
присваивается некоторый классификационный уровень, а каждый пользователь
обладает некоторым уровнем допуска. При таком подходе доступом к
определенному объекту данных обладают только пользователи с
соответствующим уровнем допуска.
□ Для реализации избирательного принципа предусмотрены следующие методы. В
базу данных вводится новый тип объектов БД – это пользователи. Каждому
пользователю в БД присваивается уникальный идентификатор. Для
дополнительной
защиты
каждый
пользователь
кроме
уникального
идентификатора снабжается уникальным паролем, причем если идентификаторы
пользователей в системе доступны системному администратору, то пароли
пользователей хранятся чаще всего в специальном кодированном виде и
известны только самим пользователям.
□ Пользователи могут быть объединены в специальные группы пользователей.
Один пользователь может входить в несколько групп. В стандарте вводится
понятие группы PUBLIC, для которой должен быть определен минимальный
стандартный набор прав. По умолчанию предполагается, что каждый вновь
создаваемый пользователь, если специально не указано иное, относится к группе
PUBLIC.
□ Привилегии или полномочия пользователей или групп – это набор действий
(операций), которые они могут выполнять над объектами БД.
□ В последних версиях ряда коммерческих СУБД появилось понятие «роли». Роль
– это поименованный набор полномочий. Существует ряд стандартных ролей,
которые определены в момент установки сервера баз данных. И имеется
возможность создавать новые роли, группируя в них произвольные полномочия.
Введение ролей позволяет упростить управление привилегиями пользователей,
структурировать этот процесс. Кроме того, введение ролей не связано с
конкретными пользователями, поэтому роли могут быть определены и
сконфигурированы до того, как определены пользователи системы.
□ Пользователю может быть назначена одна или несколько ролей.
□ Объектами БД, которые подлежат защите, являются все объекты, хранимые в БД:
таблицы, представления, хранимые процедуры и триггеры. Для каждого типа
объектов есть свои действия, поэтому для каждого типа объектов могут быть
определены разные права доступа.
На самом элементарном уровне концепции обеспечения безопасности баз данных
исключительно просты. Необходимо поддерживать два фундаментальных принципа: проверку
полномочий и проверку подлинности (аутентификацию).
Проверка полномочий основана на том, что каждому пользователю или процессу
информационной системы соответствует набор действий, которые он может выполнять по
отношению к определенным объектам. Проверка подлинности означает достоверное
подтверждение того, что пользователь или процесс, пытающийся выполнить
санкционированное действие, действительно тот, за кого он себя выдает.
Система назначения полномочий имеет в некотором роде иерархический характер. Самыми
высокими правами и полномочиями обладает системный администратор или администратор
сервера БД. Традиционно только этот тип пользователей может создавать других пользователей
и наделять их определенными полномочиями.
СУБД в своих системных каталогах хранит как описание самих пользователей, так и
описание их привилегий по отношению ко всем объектам.
Далее схема предоставления полномочий строится по следующему принципу. Каждый
объект в БД имеет владельца – пользователя, который создал данный объект. Владелец объекта
обладает всеми правами-полномочиями на данный объект, в том числе он имеет право
предоставлять другим пользователям полномочия по работе с данным объектом или забирать у
пользователей ранее, предоставленные полномочия.
В ряде СУБД вводится следующий уровень иерархии пользователей – это администратор
БД. В этих СУБД один сервер может управлять множеством СУБД (например, MS SQL Server,
Sybase).
В СУБД Oracle применяется однобазовая архитектура, поэтому там вводится понятие
подсхемы – части общей схемы БД и вводится пользователь, имеющий доступ к подсхеме.
В стандарте SQL не определена команда создания пользователя, но практически во всех
коммерческих СУБД создать пользователя можно не только в интерактивном режиме, но и
программно с использованием специальных хранимых процедур. Однако для выполнения этой
операции пользователь должен иметь право на запуск соответствующей системной процедуры.
В стандарте SQL определены два оператора: GRANT и REVOKE соответственно
предоставления и отмены привилегий.
Оператор предоставления привилегий имеет следующий формат:
Здесь список действий определяет набор действий из общедопустимого перечня действий
над объектом данного типа.
Параметр ALL PRIVILEGES указывает, что разрешены все действия из допустимых для
объектов данного типа.
<имя_объекта> – задает имя конкретного объекта: таблицы, представления, хранимой
процедуры, триггера.
<имя_пользователя> или PUBLIC определяет, кому предоставляются данные привилегии.
Параметр WITH GRANT OPTION является необязательным и определяет режим, при
котором передаются не только права на указанные действия, но и право передавать эти права
другим пользователям. Передавать права в этом случае пользователь может только в рамках
разрешенных ему действий.
Рассмотрим пример, пусть у нас существуют три пользователя с абсолютно уникальными
именами user1, user2 и users. Все они являются пользователями одной БД.
User1 создал объект Таb1, он является владельцем этого объекта и может передать права на
работу с эти объектом другим пользователям. Допустим, что пользователь user2 является
оператором, который должен вводить данные в Таb1 (например, таблицу новых заказов), а
пользователь user3 является большим начальником (например, менеджером отдела), который
должен регулярно просматривать введенные данные.
Для объекта типа таблица полным допустимым перечнем действий является набор из
четырех операций: SELECT, INSERT, DELETE, UPDATE. При этом операция обновление
может быть ограничена несколькими столбцами.
Общий формат оператора назначения привилегий для объекта типа таблица будет иметь
следующий синтаксис:
Тогда резонно будет выполнить следующие назначения:
Эти назначения означают, что пользователь user2 имеет право только вводить новые строки
в отношение Таb1, а пользователь user2 имеет право просматривать все строки в таблице Таb1.
При назначении прав доступа на операцию модификации можно уточнить, значение каких
столбцов может изменять пользователь. Допустим, что менеджер отдела имеет право изменять
цену на предоставляемые услуги. Предположим, что цена задается в столбце COST таблицы
Таb1. Тогда операция назначения привилегий пользователю user2 может измениться и
выглядеть следующим образом:
Если наш пользователь user1 предполагает, что пользователь user4 может его замещать в
случае его отсутствия, то он может предоставить этому пользователю все права по работе с
созданной таблицей Таb1.
В этом случае пользователь user4 может сам назначать привилегии по работе с таблицей
Таb1 в отсутствие владельца объекта пользователя user1. Поэтому в случае появления нового
оператора пользователя users он может назначить ему права на ввод новых строк в таблицу
командой
Если при передаче полномочий набор операций над объектом ограничен, то пользователь,
которому переданы эти полномочия, может передать другому пользователю только те
полномочия, которые есть у него, или часть этих полномочий. Поэтому если пользователю
user4 были делегированы следующие полномочия:
то пользователь user4 не сможет передать полномочия на ввод данных пользователю user3,
потому что эта операция не входит в список разрешенных для него самого.
Кроме непосредственного назначения прав по работе с таблицами эффективным методом
защиты данных может быть создание представлений, которые будут содержать только
необходимые столбцы для работы конкретного пользователя и предоставление прав на работу с
данным представлением пользователю. Так как представления могут соответствовать итоговым
запросам, то для этих представлений недопустимы операции изменения, и, следовательно, для
таких представлений набор допустимых действий ограничивается операцией SELECT. Если же
представления соответствуют выборке из базовой таблицы, то для такого представления
допустимыми будут все 4 операции: SELECT, INSERT, UPDATE и DELETE.
Для отмены ранее назначенных привилегий в стандарте SQL определен оператор REVOKE.
Оператор отмены привилегий имеет следующий синтаксис:
Параметры CASCADE или RESTRICT определяют, каким образом должна производиться
отмена привилегий. Параметр CASCADE отменяет привилегии не только пользователя,
который непосредственно упоминался в операторе GRANT при предоставлении ему
привилегий, но и всем пользователям, которым этот пользователь присвоил привилегии,
воспользовавшись параметром WITH GRANT OPTION. Например, при использовании
операции:
будут отменены привилегии и пользователя user3, которому пользователь user4 успел
присвоить привилегии.
Параметр RESTRICKT ограничивает отмену привилегий только пользователю,
непосредственно упомянутому в операторе REVOKE. Но при наличии делегированных
привилегий этот оператор не будет выполнен. Так, например, операция:
не будет выполнена, потому что пользователь user4 передал часть своих полномочий
пользователю user5.
Посредством оператора REVOKE можно отобрать все или только некоторые из ранее
присвоенных привилегий по работе с конкретным объектом. При этом из описания синтаксиса
оператора отмены привилегий видно, что можно отобрать привилегии одним оператором сразу
у нескольких пользователей или у целой группы PUBLIC. Поэтому корректным будет
следующее использование оператора REVOKE:
При работе с другими объектами изменяется список операций, которые используются в
операторах GRANT и REVOKE.
По умолчанию действие, соответствующее запуску (исполнению) хранимой процедуры,
назначается всем членам группы PUBLIC.
Если вы хотите изменить это условие, то после создания хранимой процедуры необходимо
записать оператор REVOKE.
И теперь мы можем назначить новые права пользователю user4.
Системный администратор может разрешить некоторому пользователю создавать и изменять
таблицы в некоторой БД. Тогда он может записать оператор предоставления прав следующим
образом:
В этом случае пользователь user1 может создавать, изменять или удалять таблицы в БД
DB_LIB, однако он не может разрешить создавать или изменять таблицы в этой БД другим
пользователям, потому что ему дано разрешение без права делегирования своих возможностей.
В некоторых СУБД пользователь может получить права создавать БД. Например, в MS SQL
Server системный администратор может предоставить пользователю main_user право на
создание своей БД на данном сервере. Это может быть сделано следующей командой:
По принципу иерархии пользователь main_user, создав свою БД, теперь может предоставить
права на создание или изменение любых объектов в этой БД другим пользователям.
В СУБД, которые поддерживают однобазовую архитектуру, такие разрешения недопустимы.
Например, в СУБД Oracle на сервере создается только одна БД, но пользователи могут работать
на уровне подсхемы (части таблиц БД и связанных с ними объектов). Поэтому там вводится
понятие системных привилегий. Их очень много, 80 различных привилегий.
Для того чтобы разрешить пользователю создавать объекты внутри этой БД, используется
понятие системной привилегии, которая может быть назначена одному или нескольким
пользователям. Они выдаются только на действия и конкретный тип объекта. Поэтому, если вы,
как системный администратор, предоставили пользователю право создания таблиц (CREATE
TABLE), то для того чтобы он мог создать триггер для таблицы, ему необходимо предоставить
еще одну системную привилегию CREATE TRIGGER. Система защиты в Oracle считается
одной из самых мощных, но это имеет и обратную сторону – она весьма сложная. Поэтому
задача администрирования в Oracle требует хорошего знания как семантики принципов
поддержки прав доступа, так и физической реализации этих возможностей.
Реализация системы защиты в MS SQL Server
SQL server 6.5 поддерживает 3 режима проверки при определении прав пользователя:
1. Стандартный (standard).
2. Интегрированный (integrated security).
3. Смешанный (mixed).
Стандартный режим защиты предполагает, что каждый пользователь должен иметь учетную
запись как пользователь домена NT Server. Учетная запись пользователя домена включает имя
пользователя и его индивидуальный пароль. Пользователи доменов могут быть объединены в
группы. Как пользователь домена пользователь получает доступ к определенным ресурсам
домена. В качестве одного из ресурсов домена и рассматривается SQL Server. Но для доступа к
SQL Server пользователь должен иметь учетную запись пользователя MS SQL Server. Эта
учетная запись также должна включать уникальное имя пользователя сервера и его пароль. При
подключении к операционной среде пользователь задает свое имя и пароль пользователя
домена. При подключении к серверу баз данных пользователь задает свое уникальное имя
пользователя SQL Server и свой пароль. Интегрированный режим предполагает, что для
пользователя задается только одна учетная запись в операционной системе, как пользователя
домена, a SQL Server идентифицирует пользователя по его данным в этой учетной записи. В
этом случае пользователь задает только одно свое имя и один пароль.
В случае смешанного режима часть пользователей может быть подключена к серверу с
использованием стандартного режима, а часть с использованием интегрированного режима.
В MS SQL Server 7.0 оставлены только 2 режима: интегрированный, называемый Windows
NT Authentication Mode (Windows NT Authentication), и смешанный, Mixed Mode (Windows NT
Authentication and SQL Server Authentication). Алгоритм проверки аутентификации пользователя
в MS SQL Server 7.0 приведен на рис. 13.1.
Рис. 13.1. Алгоритм проверки аутентификации пользователя в MS SQL Server 7.0
При попытке подключения к серверу БД сначала проверяется, какой метод аутентификации
определен для данного пользователя. Если определен Windows NT Authentication Mode, то
далее проверяется, имеет ли данный пользователь домена доступ к ресурсу SQL Server, если он
имеет доступ, то выполняется попытка подключения с использованием имени пользователя и
пароля, определенных для пользователя домена; если данный пользователь имеет права
подключения к SQL Server, то подключение выполняется успешно, в противном случае
пользователь получает сообщение о том, что данному пользователю не разрешено подключение
к SQL Server. При использовании смешанного режима аутентификации средствами SQL Server
проводится последовательная проверка имени пользователя (login) и его пароля (password);
если эти параметры заданы корректно, то подключение завершается успешно, в противном
случае пользователь также получает сообщение о невозможности подключиться к SQL Server.
Для СУБД Oracle всегда используется в дополнение к имени пользователя и пароля в
операционной среде его имя и пароль для работы с сервером БД.
Проверка полномочий
Второй задачей при работе с БД, как указывалось ранее, является проверка полномочий
пользователей. Полномочия пользователей хранятся в специальных системных таблицах, и их
проверка осуществляется ядром СУБД при выполнении каждой операции. Логически для
каждого пользователя и каждого объекта в БД как бы строится некоторая условная матрица, где
по одному измерению расположены объекты, а по другому – пользователи. На пересечении
каждого столбца и каждой строки расположен перечень разрешенных операций для данного
пользователя над данным объектом. С первого взгляда кажется, что эта модель проверки
достаточно устойчивая. Но сложность возникает тогда, когда мы используем косвенное
обращение к объектам. Например, пользователю user_N не разрешен доступ к таблице Таb1, но
этому пользователю разрешен запуск хранимой процедуры SP_N, которая делает выборку из
этого объекта. По умолчанию все хранимые процедуры запускаются под именем их владельца.
Такие проблемы должны решаться организационными методами. При разрешении доступа
некоторых пользователей необходимо помнить о возможности косвенного доступа.
В любом случае проблема защиты никогда не была чисто технической задачей, это комплекс
организационно-технических мероприятий, которые должны обеспечить максимальную
конфиденциальность информации, хранимой в БД.
Кроме того, при работе в сети существует еще проблема проверки подлинности полномочий.
Эта проблема состоит в следующем. Допустим, процессу 1 даны полномочия по работе с БД,
а процессу 2 такие полномочия не даны. Тогда напрямую процесс 2 не может обратиться к БД,
но он может обратиться к процессу 1 и через него получить доступ к информации из БД.
Поэтому в безопасной среде должна присутствовать модель проверки подлинности, которая
обеспечивает подтверждение заявленных пользователями или процессами идентификаторов.
Проверка полномочий приобрела еще большее значение в условиях массового распространения
распределенных вычислений. При существующем высоком уровне связности вычислительных
систем необходимо контролировать все обращения к системе.
Проблемы проверки подлинности обычно относят к сфере безопасности коммуникаций и
сетей, поэтому мы не будем их здесь более обсуждать, за исключением следующего замечания.
В целостной системе компьютерной безопасности, где четкое выполнение программы защиты
информации обеспечивается за счет взаимодействия соответствующих средств в операционных
системах, сетях, базах данных, проверка подлинности имеет прямое отношение к безопасности
баз данных.
Заметим, что модель безопасности, основанная на базовых механизмах проверки
полномочий и проверки подлинности, не решает таких проблем, как украденные
пользовательские идентификаторы и пароли или злонамеренные действия некоторых
пользователей, обладающих полномочиями, – например, когда программист, работающий над
учетной системой, имеющей полный доступ к учетной базе данных, встраивает в код
программы «Троянского коня» с целью хищения или намеренного изменения информации,
хранимой в БД. Такие вопросы выходят за рамки нашего обсуждения средств защиты баз
данных, но следует тем не менее представлять себе, что программа обеспечения
информационной безопасности должна охватывать не только технические области (такие как
защита сетей, баз данных и операционных систем), но и проблемы физической защиты,
надежности персонала (скрытые проверки), аудит, различные процедуры поддержки
безопасности, выполняемые вручную или частично автоматизированные.
Физическая безопасность
Физическую безопасность необходимо обеспечить не только для БД SQL Server, но и для
других компьютерных данных. В сетях многих компаний об этом жизненно важном уровне
системы безопасности нередко забывают. В результате сети не защищены от хищения
информации, вандализма и стихийных бедствий. Физическая безопасность подразумевает
защиту жизненно важного сервера и сетевого оборудования путем размещения их на территориях с ограниченным доступом. Для очень крупных сетей это может быть целое здание
или группа зданий, а для сетей среднего размера — центр хранения и обработки данных. Для
небольшой сети достаточного единственного запираемого помещения. Для защиты от
стихийных бедствий необходимо планировать и регулярно создавать резервные копии,
которые следует хранить отдельно от места эксплуатации сервера.
Безопасность сетевого протокола
Данные, передаваемые с клиента на SQL Server, могут быть зашифрованы. Таким образом,
даже перехватив пакеты при передаче их по сети, злоумышленник не сможет прочитать их
содержимое. Шифрование пакетов реализовано на промежуточном уровне между клиентом
и SQL Server (шифрование на прикладном уровне) с помощью протокола SSL (Secure Socket
Layer) или шифрования при вызове удаленных процедур (RPC). При обмене данными между
двумя компьютерами под управлением Windows 2000 шифрование пакетов реализуется с
помощью безопасности IP (IP Security, IPSec). IPSec также поддерживается многими
современными маршрутизаторами. Утилита Client Network Utility позволяет
сконфигурировать SSL для Net-Libraries в SQL Server 2000. На рис. 1 показано, как включить
шифрование в Client Network Utility.
Рис. 1. Включение шифрования пакетов для всех активных протоколов
SSL также требует наличия у SQL Server сертификата. Подробнее об этом — в Microsoft
Windows 2000 Server Resource Kit.
Шифрование снижает сетевую производительность SQL Server. Прежде чем включать
шифрование, следует провести эталонное измерение производительности сети. После
включения шифрования следует измерить снижение производительности в сети, чтобы
определить, стоит ли использовать эту функцию. Некоторые протоколы SQL Server содержат
собственные функции безопасности. Например, Multiprotocol Net-Library использует RPC и
API шифрования RPC. Таким образом, SSL-шифрование пакетов для этого протокола
излишне.
Кроме того, существует ряд особенностей для каждого конкретного протокола. Например,
вместо порта по умолчанию 1433 для протокола TCP/IP следует использовать уникальный
порт, а в качестве базового протокола безопасности — IPSec. Следует отключить
оповещения сервера именованных каналов, чтобы сервер не фигурировал в списке
графического интерфейса Query Analyzer. Также следует отключить широковещательную
передачу для почтовых ящиков, чтобы NetBIOS-имя сервера не появлялось в сети.
Другая распространенная методика обеспечения безопасности сетевого протокола —
применение брандмауэра на основе Microsoft Internet Security and Acceleration Server или
специализированного оборудования. Простым решением является использование разных
протоколов во внутренней и внешней сети. Например, во внутренней сети можно использовать IPX/SPX, а во внешней — TCP/IP. Чтобы получить доступ к внутренней сети из внешней, достаточно подключиться к виртуальной частной сети (virtual private network, VPN).
Доменная безопасность
Если компьютер, на котором работает SQL Server 2000, является сервером — членом домена
Windows NT или Windows 2000, можно проверить пользователя с помощью его идентификатора безопасности (security identifier, SID). Для выполнения аутентификации средствами Windows администратор БД наделяет учетную запись пользователя или группы привилегиями для доступа к SQL Server и выполнения на нем определенных действий. До-
менные учетные записи пользователей Windows обеспечивают надежную проверку и блокировку учетных записей. Доменные пароли Windows шифруют во избежание их перехвата
при передаче по сети. Они чувствительны к регистру символов, что затрудняет их подбор.
Кроме того, используют такие приемы, как определение минимальной длины пароля и срока
его действия. Если при установке SQL Server задан чувствительный к регистру порядок
сортировки, то пароль, назначенный пользователю, также окажется чувствительным к
регистру. При входе в систему с клиента Windows NT или Windows 2000 доменные пароли
Windows всегда чувствительны к регистру. Механизм SQL Server, позволяющий доменным
учетным записям Windows устанавливать соединения с SQL Server, обсуждается далее в
разделе «Безопасность SQL Server».
Другая мощная возможность защиты сетей Windows 2000, работающих под управлением
служб каталога Active Directory и протокола взаимной аутентификации Kerberos, —
делегирование учетных записей системы безопасности. Она позволяет проверять идентификационные данные пользователя при подключении одного компьютера к другому в сети,
при этом пользователь проходит регистрацию лишь однажды (на первом компьютере).
Безопасность локального компьютера
SQL Server 2000 может работать под управлением Windows 98, Windows Millennium Edition
(ME), Windows NT и Windows 2000. Windows NT Server, Windows 2000 Server и более поздние
редакции этих ОС обеспечивают наивысший уровень безопасности локального компьютера,
доступный SQL Server 2000. Поэтому ОС, минимально необходимой для SQL Server 2000
Enterprise Edition, является Windows NT Server или Windows 2000 Server. Эти ОС
поддерживают аудит системы безопасности посредством службы Event Log, позволяя
отслеживать такие события, как вход пользователей в систему и попытки обращения к
файловым объектам (например, к файлам БД). Аудит файловых объектов доступен в любом
разделе NTFS (New Technology File System). NTFS необходима для работы SQL Server 2000 в
Windows NT или Windows 2000. Эта файловая система поддерживает дополнительные функции
безопасности, в том числе поддержку прав доступа к локальным каталогам и файлам, а также
сервисы шифрования. Наконец, программа SQL Server Setup автоматически конфигурирует
ограничения доступа к уязвимым настройкам реестра, связанным с j SQL Server. После
изменения системы безопасности ОС всегда тщательно проверяйте работу SQL Server, чтобы
убедиться в сохранении должной производительности и в том, что сконфигурированные
ограничения не заблокировали никаких функций SQL Server.
Безопасность SQL Server
SQL Server предоставляет обширный набор служб безопасности для защиты обслуживаемых им
баз данных. Средства безопасности SQL Server можно разделить на четыре категории:
аутентификация, авторизация, аудит и шифрование. Процесс предоставления доступа к БД
состоит из двух фаз: сначала выполняется подключение к SQL Server (аутентификация), а затем
открывается доступ к базе данных с ее объектами (авторизация). Разрешения на работу с
объектами (object permissions) позволяют или запрещают пользователю выполнять действия
над объектами БД, например таблицами и представлениями. Разрешения на выполнение SQLоператоров (statement permissions) позволяют или запрещают пользователям создавать
объекты, делать копии БД и файлов журнала. Действия, выполняемые в БД, отслеживаются с
помощью аудита SQL Server. Механизм аудита SQL Server, в отличие от службы Event Log в
Windows NT и Windows 2000, создан специально для аудита объектов БД. Некоторые объекты
БД, например хранимые процедуры, разрешается зашифровать, чтобы защитить их
содержимое.
Аутентификация
SQL Server 2000 поддерживает два режима аутентификации: средствами Windows и средствами
SQL Server. Первая позволяет локальным или доменным учетным записям Windows (Windows
NT или Windows 2000) подключаться к SQL Server. Вторая дает пользователям возможность
подключаться к SQL Server с помощью идентификатора SQL Server. Допустимо
сконфигурировать метод аутентификации на сервере во время установки SQL Server или позже
с помощью диалогового окна SQL Server Properties (Configure) в Enterprise Manager (рис. 13-2).
Параметры режима аутентификации позволяют использовать аутентификацию средствами
Windows и SQL Server одновременно или только аутентификацию средствами Windows. Режим,
в котором применяются оба метода аутентификации, называется смешанный режим (Mixed
Mode).
Использование аутентификации средствами Windows позволяет создать интегрированную
систему регистрации пользователя, поскольку SQL Server использует ОС локального
компьютера или контролера домена для проверки и сопровождения учетной записи
пользователя. Например, если User01 — локальная пользовательская учетная запись, созданная
на автономном сервере SQL с именем Server01, можно предоставить учетной записи
SERVER01 \User01 право на подключение к SQL Server или отобрать у нее это право. Если
User02 — доменная учетная запись, созданная на контроллере домена Domain01, можно дать
или отобрать право на подключение к SQL Server у записи DOMAIN01\User02.
Также разрешено наделять привилегиями и лишать их группы Windows NT и Windows 2000.
Привилегии, предоставленные группе или отобранные у нее, наследуют все ее члены. Явный
отказ в предоставлении доступа (deny) заменяет все другие привилегии, назначенные
пользователю или любым группам, членом которых он может быть. В Windows NT и Windows
2000 предусмотрены два типа групп, которым могут быть предоставлены права на подключение
к серверу: группы на локальном компьютере и доменные группы. Первые хранятся в ОС
компьютера, на котором работает SQL Server, и подразделяются на два типа: встроенные и
пользовательские. Доменные группы хранятся на контроллерах домена Windows, они бывают
трех типов: локальные для домена, глобальные и универсальные.
Аутентификация выполняется успешно, если учетной записи пользователя или его группе
предоставлено право на подключение к SQL Server. При аутентификации средствами
Windows пользователь может регистрироваться как на локальном компьютере SQL Server,
так и на любом компьютере домена, при этом отдельная регистрация в SQL Server не требуется. Если настроена смешанная аутентификация, то методом по умолчанию для подключения к SQL Server является аутентификация средствами Windows.
Случаи, когда аутентификация средствами SQL Server является единственным способом
подключения к SQL Server, перечислены ниже:
• когда клиент и сервер относятся к разным пространствам имен идентификаторов. Если
компьютер с SQL Server является автономным сервером, то клиент, зарегистрированный в
домене, должен использовать аутентификацию средствами SQL Server. Клиент может
использовать аутентификацию средствами Windows, если он зарегистрировался локально,
SQL Server сконфигурирован как автономный сервер, а также на клиенте и сервере
существуют одинаковые комбинации «учетная запись — пароль»;
• когда SQL Server работает в Windows 98 или Windows ME.
SQL Server, установленный в Windows 98 или Windows ME, поддерживает только аутентификацию средствами SQL Server;
j
• если приложение написано специально для использования аутентификации средства
ми SQL Server.
Некоторые учетные имена SQL Server (SQL Server account objects) создаются во время
установки SQL Server, например системный администратор SQL Server (sa). Это учетное
имя приписывается фиксированной роли на уровне сервера (серверной роли) Sys-Admin, и
его нельзя удалить или модифицировать. Идентификатору sa соответствует особое
пользовательское учетное имя: владелец базы данных (dbo), которое создается в каждой
БД. Помимо прочего, это соответствие делает dbo членом группы SysAdmin. О серверных
ролях рассказано в следующем разделе этого занятия. Другое специальное учетное имя —
guest — открывает доступ к БД любому пользователю, проверенному SQL Server.
Рис. 2. Конфигурирование аутентификации средствами Windows и SQL Server в Enterprise
Manager
Авторизация
Чтобы пользовательское учетное имя получило доступ к БД, одной аутентификации недостаточно. Кроме этого, у учетного имени, группы или роли, прошедшей аутентификацию,
должно быть разрешение на исполнение SQL-выражений или на работу с объектами. Как
правило, авторизация осуществляется в контексте БД. Таким образом ограничивается область
видимости пользовательского доступа. Например, разрешение на доступ к таблице из БД Pubs
не дает пользователю права на доступ к объектам БД Master. Однако есть особые
административные разрешения, область видимости которых распространяется на весь SQL
Server.
Группы и роли
Назначение разрешений каждому пользователю в отдельности занимает много времени при
сопровождении БД со средним и большим числом пользователей. Для облегчения рутинных
административных операций по назначению разрешений пользователям SQL Server 2000
поддерживает группы Windows и роли SQL Server. Все группы, прошедшие аутентификацию,
также подлежат авторизации. Например, глобальной доменной группе GlobalGroup01 в
домене Domain01 назначен ряд привилегий для подключения к SQL Server (аутентификации)
и исполнения оператора SELECT для некоторой таблицы или представления в этой БД. В
этом случае любые пользователи из домена — члены группы GlobalGroup01 — смогут
исполнить оператор SELECT (если где-либо еще для этого разрешения не задано состояние
Deny, о котором мы расскажем чуть позже).
Роли похожи на группы, но создаются и сопровождаются в рамках SQL Server. Существует
два типа ролей: стандартные и прикладные. Стандартным ролям (standard roles) назначаются
привилегии, которые могут наследоваться пользователями, получающими членство в роли.
Членами групп могут быть пользователи Windows и (в зависимости от типа группы) группы
Windows. В отличие от групп стандартные роли могут содержать все типы учетных имен:
учетные записи пользователей и групп Windows, идентификаторы SQL Server и другие
стандартные роли.
Поскольку привилегии являются кумулятивными, то с помощью вложенных групп и
стандартных ролей (групп, содержащих другие группы и роли, которые тоже содержат
группы и роли) можно построить иерархию привилегий. Например, если пользователю User01
назначена роль Role02, а сама она входит в Role01, то роль Role02 является вложенной для
Role01. Если назначить ролям Role01 и Role02 разные привилегии, то пользователь User01
будет обладать всеми привилегиями, назначенными для обеих ролей. Рис. 3 иллюстрирует
описанные иерархические связи.
Для упрощения администрирования БД и самого сервера в SQL Server предусмотрен ряд
стандартных предопределенных ролей. В основном их можно разделить на две категории:
фиксированные роли на уровне сервера, или серверные роли (fixed server role), и фиксированные
роли на уровне БД (fixed database role). Членство в фиксированных ролях на уровне сервера
дает возможность администрирования сервера. Например, если сделать пользователя членом
фиксированной серверной роли ServerAdmin, то он сможет настраивать общесерверные
параметры. Программа SQL Server Setup приписывает группу администраторов Windows
(BUILTIN\Administrators) к фиксированной серверной роли SysAdmin. Члены фиксированных
ролей на уровне БД могут администрировать некоторые БД. Например, если сделать
пользователя членом фиксированной роли на уровне БД db_BackupOperator, он сможет
создавать резервные копии этой БД. Чтобы просмотреть привилегии, назначенные для каждой
фиксированной
серверной
роли,
исполните
команду
sp_srvrolepermission
имя_фиксированной_серверной_роли, где sp_srvrolepermission — имя системной хранимой
процедуры
Рис. 3. Схема иерархических отношений, иллюстрирующая наследование пользователем
привилегий, назначенных ролям Role01 и Role01
Все пользователи, группы и роли автоматически являются членами роли Public. Эта
специальная роль похожа на специальную группу Everyone в Windows NT и Windows 2000,
Добавлять или удалять членов этой роли, как и саму роль, нельзя. Роль Public есть в каждой
БД, где по умолчанию для нее назначен ряд разрешений. Для защиты БД можно отобрать эти
разрешения у роли Public. Если группы Windows не соответствуют административным
потребностям, можно создать стандартные роли на уровне базы данных.
Иногда приложению и пользователю требуются разные разрешения. В этом случае непрактично
конфигурировать безопасность приложения с помощью разрешений SQL Server. В SQL Server
предусмотрены прикладные роли (application roles), обеспечивающие поддержку разрешений
только для приложения. Прикладные роли не содержат членов и должны передавать пароль.
Эти особые роли разработаны для управления привилегиями пользователей, обращающихся
к БД через некоторое приложение. Прикладным ролям назначаются разрешения на уровне
базы данных. После проверки пользователя прикладная роль активируется с помощью
системной хранимой процедуры sp_setapprole, которая позволяет зашифровать пароль
прикладной роли перед передачей его на сервер. Когда активна прикладная роль,
пользователь теряет все свои разрешения до конца сеанса или работы приложения. Если
приложение должно обратиться к другой БД в период активности прикладной роли, оно
сможет получить для этой БД лишь те разрешения, которые назначены учетному имени guest.
Состояния разрешения
Разрешение может быть предоставлено (Grant), снято (Revoke) или в нем может быть отказано (Deny). При предоставлении разрешения пользователю, группе или роли (любому
учетному имени) командой Grant разрешение назначается явно. При снятии разрешения с
учетного имени (командой Revoke) последнее теряет соответствующее разрешение. Наконец,
при отказе в предоставлении разрешения (с помощью команды Deny) на получение этого
разрешения налагается явный запрет. Пользовательские разрешения представляют собой
сумму всех разрешений, назначенных непосредственно этому пользователю или его группе.
Сначала SQL Server обрабатывает состояние Deny, которое отнимает разрешение —
независимо от способа его получения. Поэтому, если пользователь наследует это состояние
или получает его явно, оно исключает все другие разрешения. Допустим, пользователю
User01 дано разрешение на исполнение оператора SELECT для таблицы Table01. Этот
пользователь является членом группы Group01, обладающей разрешением на исполнение
оператора INSERT для той же самой таблицы. В результате учетное имя этого пользователя
получает права на исполнение операторов SELECT и INSERT для таблицы Table01. Однако
если группа Group01 является членом роли Role01, у которой разрешения SELECT и INSERT
находятся в состоянии Deny, пользователь не сможет ни извлечь данные из таблицы Table01,
ни добавить в нее данные.
Разрешения на работу с объектами и выполнение SQL-выражений
В SQL Server предусмотрены разрешения трех типов: разрешения на работу с объектами
(object permissions), разрешения на выполнение SQL-операторов (statement permissions) и
предполагаемые разрешения (implied permissions). Разрешения на работу с объектами относятся
к объектам БД и могут различаться для разных объектов. Например, для хранимой процедуры
допустимо назначить разрешение EXECUTE, а для таблицы — SELECT. Разрешения на
выполнение SQL-операторов применяются к операторам Transact-SQL CREATE и BACKUP,
исполняемым в БД. Например, разрешение CREATE TABLE дает пользователю возможность
создавать таблицы в БД. Далее перечислены разрешения на работу с объектами и выполнение
SQL-операторов для различных объектов БД.
Разрешение
Разрешаемое действие
CREATE (разрешение на выполнение SQL-оператора)
Создание БД, таблиц, представлений, хранимых
процедур, определений умолчания, правил и функций
BACKUP (разрешение на выполнение SQL- оператора)
Резервное копирование БД и файла журнала
SELECT и UPDATE (разрешение на работу с объектом)
Запросы и модификация таблиц, представлений и их
столбцов
INSERT и DELETE (разрешение на работу с объектом)
Добавление и удаление таблиц, представлений и их
записей
EXECUTE (разрешение на работу с объектом)
Выполнение хранимых процедур
Предполагаемые разрешения назначаются владельцам объектов, фиксированным ролям на уровне
сервера и баз данных; их нельзя отобрать. Некоторые предполагаемые разрешения на выполнение SQLоператоров можно получить только через членство в фиксированной серверной роли. Например, чтобы
иметь
право
на
исполнение
оператора
SHUTDOWN,
пользователь должен быть членом фиксированной серверной роли ServerAdmin.
Аудит
Служба Event Log обеспечивает общий аудит ОС Windows NT и Windows 2000. SQL Server
поддерживает аудит идентификаторов и событий системы безопасности. Успех или неудача
аутентификации того или иного пользователя — это серверный параметр, который разрешается
сконфигурировать
на
вкладке
Security
диалогового
окна
SQL
Server
Properties
(Configure) в Enterprise Manager (рис. 2).
Чтобы задействовать аудит, следует настроить его с помощью SQL Profiler. События системы
безопасности регистрируются в файле или в таблице БД. Необходимо указать подлежащие аудиту
события, столбцы для трассировки и свойства для хранения трассировочного файла или таблицы. После
выполнения трассировки событий системы безопасности с помощью SQL Profiler, файл трассировки
открывают в нем же или выполняют запрос к трассировочной таблице.
Шифрование объектов
Шифрование данных ограничивает доступ к информации путем хранения ее в формате, трудно
поддающемся расшифровке. Программы расшифровывают данные с помощью дешифрующего
алгоритма и ключа. В SQL Server 2000 имеется алгоритм для расшифровки и анализа зашифрованных
объектов БД. Пароли и зашифрованные объекты в SQL Server не разрешено просматривать ни
одному пользователю БД (в том числе членам фиксированной серверной роли SysAdmin). SQL Server
2000 автоматически шифрует пароли, ассоциированные с идентификаторами. При желании
можно зашифровать текст хранимых процедур, пользовательских функций, представлений и
триггеров, воспользовавшись при создании этих объектов БД конструкцией WITH
ENCRYPTION.
Безопасность приложений
Обращающееся к БД приложение вызывает системную хранимую процедуру sp_setapprole,
чтобы активировать прикладную роль. Кроме того, в приложении иногда реализована собственная система безопасности, неподконтрольная БД. Для изоляции приложений от деталей
механизма доступа к данным применяются API доступа к данным, поддерживаемые SQL
Server, например ADO, OLE DB и ODBC. Приложения должны обеспечивать безопасность
при обращении к данным SQL Server. Например, в Internet Explorer предусмотрена защита от
действий опасных сценариев
Планирование безопасности баз данных
Теперь, когда вы имеете представление об архитектуре системы безопасности БД, мы расскажем о планировании системы безопасности. Чтобы создать план системы безопасности,
необходимо определить требования к системе безопасности на основе списка системных
требований, представить эти правила в виде набора пользовательских действий и создать
список соответствий «пользователь — действие». Основное внимание в этом занятии уделяется
системе безопасности SQL Server, занимающей пятый уровень модели безопасности. Сетевые и
системные администраторы отвечают за реализацию первых четырех уровней системы
безопасности БД, администраторы и разработчики БД отвечают за пятый уровень, а
разработчики приложений — за шестой. Специалисты по безопасности, как правило,
наблюдают за проектированием всей системы безопасности. В этом занятии рассказано, как
создать план системы безопасности БД и как архитектура системы безопасности связана с
разработкой эффективного плана.
Требования к системе безопасности
Как уже говорилось, что в плане системы безопасности определяется круг пользователей БД,
доступные пользователям объекты и действия, которые им разрешено выполнять в БД. Эта
информация определяется на основе требований к системе безопасности, которые можно
вывести из системных требований. Однако часть требований к системе безопасности не
следует из системных требований напрямую. В частности, в системных требованиях иногда не
описаны действия по администрированию системы безопасности, например аудит исполнения
хранимых процедур или резервное копирование БД. После составления списка объектов БД,
нуждающихся в защите, и действий, доступных не всем пользователям БД, следует создать
список уникальных пользователей, их классов и групп, имеющих доступ к БД. На основе этой
информации готовят список соответствий «действие — пользователь» в виде таблицы с
перекрестными ссылками на элементы списков отдельных действий и пользователей. Этот
список определяет, каким пользователям доступны защищенные объекты, а также какие
защищенные действия пользователи могут выполнять в БД.
Предположим, имеется база данных о работниках, доступная 100 пользователям. База
содержит таблицу со сведениями о работниках (Employees), таблицу с категориями зарплаты
(Salaries) и адресами (Locations). Работники обращаются к таблице Employees и к информации
о расположении офисов в таблице Locations. Таблица Salaries и домашние адреса из таблицы
Locations доступны лишь небольшой группе — им разрешено добавлять, удалять и
модифицировать эти данные. Еще один пользователь отвечает за создание
резервных копий БД, которое предписано выполнять каждую ночь. Отдельная группа
пользователей имеет право создавать и удалять объекты БД.
Для этого простого примера можно сформулировать следующие требования к системе
безопасности БД:
• всем работникам разрешено исполнять операторы SELECT в таблице Employees;
• всем работникам разрешено исполнять операторы SELECT в таблице Locations для
извлечения сведений о местонахождения офиса;
• небольшая группа работников может исполнять операторы INSERT, DELETE, и UPDATE
на всех столбцах каждой из трех таблиц;
• пользователю, выполняющему каждую ночь резервное копирование и общее
администрирование БД, необходим полный доступ к серверу;
• некоторая группа пользователей исполняет операторы CREATE и DROP.
Также составим список пользователей, имеющих доступ к этой БД:
• все работники входят в класс пользователей, представленный ролью Public на уровне
БД;
• членам группы HumanResources необходим ограниченный доступ к БД;
• учетное имя JDoe принадлежит администратору БД;
• разработчики БД компании создают и удаляют объекты в SQL Server.
На основе предоставленной информации создается список соответствий «пользователь —
действие».
Учетная запись, группа или роль
Вид действий
Доступ
только для
Public (роль)
чтения к таблице
Employees
Доступ только для чтения к столбцам со
Public (роль)
сведениями о местонахождения офиса в
DOMAIN01\HumanResources (группа)
DOMAlN01\Jdoe
DOMAIN01\dbDev
таблице Location
Полный доступ к таблицам Employees,
Location
и Salaries
Полный доступ к БД
Создание БД
Вложенные роли и цепочки владения
Существует множество способов реализации системы безопасности в SQL Server. От разработчика требуется обеспечить максимальную эффективность при реализации системы
безопасности, но не за счет снижения уровня безопасности. Например, если 100 пользователям требуется одинаковый уровень доступа к БД, рациональнее всего использовать
группы и роли, а не конфигурировать систему безопасности для каждого пользователя в
отдельности. Оба способа дают одинаковые результаты, но группы и роли легче сопровождать, кроме того, этот способ быстрее осуществить. Вложенные роли, цепочки владения и
предопределенные роли позволяют сконструировать рациональный план системы
безопасности.
Вложенные группы
Использование вложенных ролей и групп позволяет избежать лишней работы по назначению
разрешений. Например, разрешение SELECT для таблиц, доступных всем прошедшим
аутентификацию пользователям, следует назначить роли Public. Разрешения на работу с
защищаемыми объектами и на выполнение операторов в этом случае лучше назначить группе
(Group01 в этом примере). Затем следует назначить специальные разрешения отдельным
пользователям или меньшей группе (SpecialGroup01). Все пользователи, группы (в том числе
Group01 и SpecialGroup01) и роли являются членами роли Public. Группа SpecialGroup01 входит
в группу Group01, поэтому SpecialGroup01 наследует разрешения, назначенные для Group01, а
члены SpecialGroup01 наследуют специальные разрешения, назначенные для этой группы.
Цепочки владения
Членство в предопределенных ролях и владение объектами предполагает наличие ряда
привилегий. Предполагаемые разрешения позволяют минимизировать ручную работу по
назначению привилегий, необходимую для выполнения требований к системе безопасности.
Согласованное владение объектами и формирование цепочек владения также эффективно
ограничивают объем и консолидацию назначаемых разрешений. Когда набор вложенных
объектов и исходный вызывающий объект принадлежат одному и тому же пользователю и
располагаются в одной и той же БД, говорят о создании цепочки владения (ownership chain).
Если у пользователей БД есть хотя бы разрешение на работу с вызывающим объектом
(хранимой процедурой или представлением), то по цепочке они смогут получать доступ к
данным и выполнить некоторые действия. Если вся цепочка объектов принадлежит одному
учетному имени, то SQL Server проверяет наличие соответствующих разрешений лишь для
вызывающей хранимой процедуры или представления.
Цепочка существует благодаря тому, что представление может вызывать таблицы или
другие вложенные представления. Кроме того, хранимые процедуры способны вызывать
таблицы, представления и вложенные хранимые процедуры. Вызывающий объект зависит от
вызываемых объектов, лежащих в его основе. Например, вызывающее таблицу представление
зависит от таблицы в смысле возвращаемого результирующего набора. Если все ' вызываемые
объекты принадлежат тому же владельцу, что и вызывающий объект, формируется цепочка
владения. Владельцем всех объектов, созданных хранимой процедурой, является владелец
процедуры, а не пользователь, запустивший ее. Цепочки владения можно применять лишь к
операторам SELECT, INSERT, UPDATE и DELETE.
Если из-за несогласованности владения объектами цепочка не сформирована, SQL Server
проверяет разрешения для каждого объекта в цепочке, у которого следующая связь с объектом
нижнего уровня указывает на объект, принадлежащий другому владельцу. Владелец сохраняет
контроль над доступом к вложенным объектам. Для оптимизации назначения разрешений
лучше создавать все объекты БД от имени ее владельца (dbo).
Рекомендации по проектированию системы безопасности
Существует ряд общих правил реализации системы безопасности в SQL Server. Сетевая среда
оказывает влияние на место учетных записей системы безопасности (пользователей, групп и
ролей) в структуре системы безопасности БД. Существующие разрешения позволяют создать
эффективную систему безопасности.
Пользователи, группы и роли
Кому следует назначать разрешения: группам, ролям или отдельным пользователям — зависит
от того, кто нуждается в этих разрешениях. Например, если единственному пользователю
необходимо уникальное разрешение, следует назначить соответствующие разрешения
отдельному учетному имени. Тип серверной среды, в которой работает SQL Server, также
влияет на выбор учетных имен, которым надо назначать разрешения (группам, ролям или
пользователям). Например, если сервер входит в домен и доступен через аутентификацию
средствами Windows, то стоит назначить разрешения пользователям домена Windows. По
возможности следует включать пользователей в предопределенные роли, а не назначать им
отдельные разрешения. Если с помощью группы Windows нельзя адекватно представить группу
пользователей, нуждающихся в разрешениях на работу с БД, если компьютер с SQL Server не
входит в домен Windows или аутентификация доступа к SQL Server осуществляется не
средствами Windows, а также если нет прав на модификацию членства в группе, следует
использовать роли. Допустим, существует группа Windows 2000 под названием developers, куда
входят все разработчики компании. Но из членов этой группы только разработчикам баз
данных необходим полный доступ к SQL Server. Поэтому следует создать роль dbDev и
включить в нее всех разработчиков баз данных. Если есть группа Windows, включающая
подходящий набор пользователей, подключающихся к БД посредством аутентификации
средствами Windows, следует назначать разрешения для работы с БД именно этой группе.
Разрешения
Для назначения разрешений на работу с объектами и выполнение SQL-операторов лучше
использовать предопределенные роли (public и фиксированные роли на уровне БД и сервера,
избегая непосредственного назначения разрешения ролям, группам и пользователям. У
фиксированных ролей имеются разрешения, которые нельзя изменить. Поэтому следует
соблюдать осторожность, приписывая пользователей к фиксированным ролям. Сначала
следует назначать разрешения группам и ролям и только потом — отдельным пользователям.
Наверху иерархии системы безопасности надо располагать разрешения, которые можно
применять ко всем пользователям, а ниже — разрешения для более ограниченного круга
пользователей. Соблюдайте согласование владельцев при создании объектов, чтобы обеспечить возможность формирования цепочек владения. Следует создавать представления и
хранимые процедуры, использующие цепочки владения, и в этом случае назначать разрешения вызывающей хранимой процедуре или представлению.
В разрешения, назначаемые учетному имени, можно включить право предоставлять работу с
объектами другим пользователям. Делегирование этой возможности другим пользователям
означает, что вам не придется назначать все разрешения самостоятельно. Соблюдайте
осторожность при назначении состояния Deny. Это состояние действительно для любого
пользователя, получившего это состояние явно или унаследовавшего его через членство в
группе или роли, независимо от разрешений, полученных им другими путями.
Реализация и администрирование системы безопасности
Для реализации и администрирования системы безопасности БД служат такие инструменты,
как Enterprise Manager и Query Analyzer. Созданную систему безопасности следует испытать,
подключаясь к БД различными учетными именами, проверяя работу разрешений и выполняя
аудит с помощью SQL Profiler. В этом занятии вы узнаете, как настраивать аутентификацию и
авторизацию с помощью различных инструментов БД. Вы также научитесь управлять
разрешениями после предоставления учетному имени доступа к БД. Управление
разрешениями включает такие действия, как их предоставление, снятие и отказ в их предоставлении. Кроме того, вы узнаете, как управлять ролями: создавать и удалять роли в БД, а
также управлять членством в пользовательских и предопределенных ролях.
Управление аутентификацией
Чтобы пользователь смог подключиться к SQL Server, для него необходимо создать на сервере учетное имя и открыть доступ к SQL Server. Эту задачу позволяет решить Enterprise
Manager или язык Transact-SQL.
Настройка аутентификации в Enterprise Manager.
Раскройте узел Security в консоли Enterprise Manager и щелкните Logins. Щелкните правой
кнопкой панель Details, затем New Login. В поле диалогового окна SQL Server Login Properties
— New Login введите имя учетной записи Windows. Доменная учетная запись пользователя
или группы включает доменное имя. Учетная запись рабочей группы Windows, пользователя
или пользовательской группы включает имя компьютера. В имя предопределенной локальной
группы Windows входит слово BUILTIN. Например, чтобы добавить пользователя User01 из
домена DOMAIN01, локального пользователя User01 экземпляра SQL Server с именем
SQLSERVER01 и локальную предопределенную группу Windows PowerUsers, необходимо
указать следующие имена, (соответственно): DOMAIN01 \User01, SQLSERVER01 \User01 и
BUILTIN\PowerUsers.
Чтобы создать идентификатор средствами диалогового окна SQL Server Login Properties —
New Login, щелкните SQL Server Authentication и введите имя идентификатора. При этом в БД
создается идентификатор и получает доступ к этой БД.
Удаляют учетные имена на панели Details в Enterprise Manager, кроме того, можно
выбирать их свойства и отказывать им в аутентификации на сервере.
Настройка аутентификации с помощью Transact-SQL
Для управления аутентификацией SQL Server предназначены системные хранимые процедуры. Процедуры sp_grantlogin, sp_denylogin и sp_revokelogin управляют аутентификацией
учетных записей Windows, а системные хранимые процедуры sp_addlogin и sp_drop-login —
идентификаторов SQL Server.
Учетные записи Windows
Чтобы добавить учетные записи Windows и предоставить им доступ, воспользуйтесь системной хранимой процедурой sp_grantlogin в Query Analyzer или в утилите командной строки osql. Следующий пример показывает, как с помощью процедуры sp_grantlogin добавить
пользователя User01 из домена DOMAIN01, пользователя User01, зарегистрированного на
компьютере SQLSERVER01 (на котором работает SQL Server), и предопределенную группу
PowerUsers:
EXEC sp_grantlogin @loginame = 'DOMAIN01 \user01'
EXEC sp_grantlogin «oginame = 'SQLSERVER01 \user01'
EXEC sp__grantlogin @loginame = 'BUILTIN \power
users'
Процедура sp_denylogin позволяет запретить некоторому пользователю или группе доступ
к серверу без удаления их учетных имен из SQL Server. Такой сценарий может потребоваться, чтобы на время устранения неисправностей или обновления БД запретить к ней
доступ, не отключая БД от сети. Следующий пример показывает, как средствами процедуры
sp_denylogin отказать членам предопределенной группы Power Users в подключении к SQL
Server:
EXEC sp_denylogin @loginame = 'BUILTIN \power users'
Чтобы удалить учетную запись Windows из SQL Server, следует использовать процедуру
sp_revokelogin.
Следующий
пример
показывает,
как
удалить
пользователя
SQLSERVER01\User01 с помощью процедуры sp_revokelogin:
Sp_revokelogin @loginame = 'SQLSERVER01\User01'
Если учетной записи Windows предоставлены некоторые привилегии для одной или
нескольких БД, процедура sp_revokelogin удалит эти привилегии и саму учетную запись из SQL
Server.
Идентификаторы SQL Server
Для создания идентификаторов SQL Server и предоставления им доступа служит системная
хранимая процедура sp_addlogin. Следующий пример показывает, как создать идентификатор пользователя User02 и предоставить ему доступ с паролем password02:
sp_addlogin
@loginame'= 'user02',
@passwd = 'password02'
Единственный обязательный параметр — @loginame. Кроме него есть необязательные
параметры @defdb, @deflanguage, @sid и @encryptopt. Базу данных задают, используя параметр @defdb (по умолчанию задана БД Master); @deflanguage определяет язык (если этот
параметр не задан, используется язык сервера по умолчанию). Параметр @sid позволяет
задать уникальный идентификатор безопасности (SID), если он не задан, уникальный SID
автоматически генерируется базой данных. Для отмены заданного по умолчанию шифрования пароля используют параметр @encryptopt.
Нельзя явно запретить аутентификацию средствами SQL Server для идентификатора SQL
Server. Для этого нужно удалить идентификатор с помощью процедуры sp_droplogin.
Любому пользователю БД соответствует идентификатор SQL Server, который нельзя удалить, пока не будут удалены все привилегии пользователя для этой БД. Для удаления привилегий применяют системную хранимую процедуру sp_revokedbaccess. Подробно об использовании этой процедуры рассказано в следующем разделе этого занятия.
Управление авторизацией
Для получения доступа к БД в SQL Server одной аутентификации не достаточно. Учетные
имена системы безопасности (учетные записи Windows и идентификаторы SQL Server) помимо
аутентификации проходят авторизацию, чтобы получить доступ к некоторой БД, если
выполняется одно из следующих условий:
• доступ к БД разрешен членам группы Guest;
• предопределенной или другой стандартной роли, членом которой является пользователь,
разрешен доступ к БД;
• группе Windows, членом которой является пользователь, разрешен доступ к БД.
Настройка авторизации в Enterprise Manager
В консоли Enterprise Manager раскройте узел Databases, затем раскройте узел нужной БД и
щелкните правой кнопкой Users. Щелкните правой кнопкой панель details, затем щелкните New
Database User. В диалоговом окне Database User Properties — New User выберите
аутентифицированное учетное имя (добавляются лишь аутентифицированные учетные имена).
Также можно выбрать идентификатор пользователя, отличный от проверенного учетного
имени. В этом диалоговом окне также задается членство в роли. Обратите внимание, что
показанная на рис. 13-4 роль Public выбирается автоматически. Любые учетные имена,
добавляемые к БД, автоматически приписываются к роли Public. Удалить пользователя БД из
роли Public невозможно.
После добавления учетного имени в диалоговом окне Database User Properties — New User,
становится активной кнопка Permissions (рис. 4). Она позволяет назначать новые или
просматривать существующие разрешения.
Настройка авторизации с помощью Transact-SQL
Как и для аутентификации, для управления авторизацией используются системные хранимые
процедуры. Предоставить учетному имени доступ к БД и отменить его позволяют процедуры
sp_grantdbaccess и sp_revokedbaccess. Они работают с любыми действительными учетными
именами (учетными записями Windows и идентификаторами SQL Server). Операция
предоставления доступа также называется определением соответствия между учетным именем
и БД. Следующая программа-пример демонстрирует, как с помощью процедуры sp_
grantdbaccess определить соответствия между БД Pubs и пользователями User01 из домена
DOMAIN01, User01 на сервере, на котором работает SQL Server (SQL- SERVER01),
идентификатором SQL Server User01 и локальной группой Power Users:
USE pubs
EXEC sp_grantdbaccess @loginame = 'DOMAIN01\User01'
EXEC sp_grantdbaccess @loginame = 'SQLSERVER01\User01',
@name_in_db = ' LocalUser01'
EXEC sp_grantdbaccess @loginame = 'user01,
@name_in_db = 'SQLUser01l'
EXEC sp_grantdbaccess @loginame = 'BUILTIN\power users'
Рис. 4. Добавление пользователя User02 к БД с помощью диалогового окна Database Users –
New User
Обратите внимание, что для SQLSERVER01\User01 и идентификатора SQL Server задан
параметр @name_in_d. Он позволяет использовать псевдонимы учетных записей. Если
@name_in_db не задан, то псевдонимом учетной записи является идентификатор пользователя.
Для удаления учетного имени из БД используется процедура sp_revokedbaccess. Невозможно удалить идентификатор SQL Server, пока для всех БД, в которых у него есть привилегии, не будет исполнена процедура sp_revokedbaccess. Однако учетную запись Windows
можно удалить без предварительного снятия ее привилегий для всех БД. Следующий пример
показывает, как с помощью sp_revokedbaccess удалить из БД Pubs пользователя User01 с
псевдонимом SQLUser01:
USE pubs
EXEC sp_revokedbaccess @name_in_db = SQLUser01
Управление разрешениями
Действующий набор разрешений учетной записи, которой предоставлен доступ к БД, — это
сумма разрешений роли Public; разрешений, предоставленных пользователю как члену других
авторизованных ролей и групп, а также всех разрешений, явно назначенных этому учетному
имени. Состояние Deny сводит «на нет» все разрешения — как унаследованные, так и
предоставленные учетному имени непосредственно.
Настройка разрешений в Enterprise Manager
Чтобы назначить дополнительные разрешения, нужно вызвать свойства учетного имени,
которые выводятся в узле Users БД. Там пользователя необходимо приписать к фиксированной
или пользовательской роли на уровне БД. Чтобы назначить разрешения непосредственно
пользователю, роли или группе, щелкнув кнопку Permissions, вызовите диалоговое окно
Database User Properties. Назначить разрешения для некоторого объекта можно через его
свойства. SQL Server позволяет назначать только те разрешения, которые действительны для
объекта. Например, разрешение на исполнение (EXEC) может быть назначено для хранимой
процедуры, но не для таблицы или представления. Если в диалоговом окне Database User
Properties выбрана таблица или представление, то становится доступной кнопка Columns, что
позволяет назначить разрешения SELECT и UPDATE для отдельных столбцов. Чтобы
назначить разрешения на исполнение операторов CREATE и BACKUP, щелкните БД в консоли
правой кнопкой и выберите из контекстного меню элемент Properties. В выводимом диалоговом
окне «имя_БД Properties» щелкните вкладку Permissions. На ней появляются все учетные имена,
обладающие привилегиями для доступа, с указанием данных им разрешений на исполнение
SQL-выражений.
Состояние любого разрешения, назначаемого посредством Enterprise Manager, отмечено
флажком. Он может быть установлен, снят или помечен знаком «X». Если разрешение
предоставлено, флажок установлен, если не предоставлено или снято, то флажок также снят.
Если в предоставлении разрешения отказано (Deny), то соответствующий флажок отмечен
знаком «X». Отказ подменяет любое разрешение, предоставленное иным путем.
Настройка разрешений с помощью Transact-SQL
Операторы GRANT, REVOKE и DENY используются для управления с помощью Query
Analyzer или утилиты командной строки типа osql разрешениями на работу с объектом и
исполнение SQL-выражений.
Оператор GRANT
При использовании оператора GRANT необходимо указать разрешение (или разрешения),
которые нужно назначить, а также имя, для которого это делается. При использовании
ключевого слова ALL назначаются все допустимые разрешения на работу с объектом и
исполнение SQL-операторов. При назначении разрешений на работу с объектом необходимо
также указать, к какому объекту они относятся. Это не требуется для разрешений на
исполнение SQL-операторов, поскольку они относятся к БД в целом, а не к какому-либо из ее
объектов. Иногда применяют конструкцию WITH GRANT OPTION, чтобы разрешить учетному
имени предоставлять это разрешение другим учетным именам. Ключевое слово AS позволяет
указать учетную запись (группу или роль) в текущей БД, обладающей полномочиями на
исполнение оператора GRANT. Если разрешение на работу с объектом дается группе или роли,
то необходимо задать группу или роль, уполномоченную назначать разрешения для других, с
помощью ключевого слова AS. Прежде чем разрешить использование оператора GRANT,
система безопасности SQL Server проверяет членство в указанной группе или роли.
Вот основные конструкции оператора GRANT для назначения разрешений на исполнение
SQL-операторов:
GRANT ALL | разрешение(я)_на_исполнение_SQL-операторов
ТО имя_учетной_записи(ей)
Далее показаны основные конструкции оператора GRANT для назначения разрешений на
работу с объектами:
GRANT ALL разрешение(я)_на_работу_с_объектами
(столбец(цы)) ON имя_таблицы| имя_представления
| ON имя_таблицы| имя представления (столбец(цы))
| ON имя_хранимой_процедуры | имя пользовательской_функции
ТО имя_учетной_записи(ей)
WITH GRANT OPTION
AS имя_групп| имя_роли
Ключевое слово ON, задающее аргумент имя_хранимой_процедуры, включает расширенные
хранимые процедуры. Разрешения (на исполнение SQL-операторов и на работу с объектами)
отделяются друг от друга запятыми, как и учетные имена:
USE pubs
GRANT CREATE TABLE, CREATE VIEW, BACKUP DATABASE, BACKUP LOG
TO user01, [BUILTIN\power users]
Пользователь User01 и группа Power Users получают четыре разрешения на исполнение
SQL-операторов. Имя группы Power Users указано в квадратных скобках, поскольку в нем
присутствуют обратный слеш и пробел.
Если нужно предоставить все допустимые разрешения на работу с объектами и исполнение SQL-операторов, воспользуйтесь ключевым словом ALL, как показано далее:
USE pubs
GRANT ALL
TO public
Роли Public даются все возможные разрешения на исполнение SQL-операторов. В результате все авторизованные пользователи получат все разрешения на исполнение операторов, выполняющих любые действия над БД. Такое действие нетипично, но этот пример
демонстрирует, как открыть для авторизованных пользователей полный доступ к БД. Если
определить для специального учетного имени Guest соответствие для БД Pubs, то все
аутентифицированные пользователи, для которых не определено соответствие БД Pubs, также
получат полный набор разрешений на исполнение SQL-операторов, поскольку учетное имя
Guest является членом роли Public.
Можно определять разрешения для всей таблицы и ее отдельных столбцов одновременно.
Таким образом, последнее из заданных разрешений может быть назначено столбцу.
Необходимо убедиться, чтобы последнее разрешение на работу с объектом было допустимым
разрешением для столбца (SELECT или UPDATE), как показано ниже:
USE pubs
GRANT INSERT, DELETE, UPDATE, SELECT
(ord_date, ord_num, qty) ON dbo.sales TO user01
Пользователь User01 получает разрешения INSERT, DELETE и UPDATE для таблицы
dbo.sales и разрешение SELECT для столбцов Ord_Date, Ord_Num и Qty. Обратите внимание,
что к имени таблицы добавлено имя ее владельца, dbo. Эта мера не обязательна, но она
полезна, если в БД есть еще таблицы с теми же именами, но принадлежащие другим
владельцами. Следующий пример показывает, как назначить разрешения UPDATE и SELECT
только для определенных столбцов:
USE pubs
GRANT UPDATE, SELECT
ON dbo.sales (ord_date, ord_num, qty)
TO test
Для хранимой процедуры действительно лишь одно из разрешений на работу с объектом
— EXECUTE. Следующий пример демонстрирует назначение разрешения EXECUTE группе
Power Users для расширенной хранимой процедуры xp_cmdshell:
USE master
GRANT EXEC
ON xp_cmdshell
TO [BUILTIN\power users]
Эта процедура расположена в БД Master, поэтому эту БД необходимо сделать текущей.
Можно предоставлять, снимать или отказывать в предоставлении разрешения лишь для
объектов текущей БД.
Оператор Revoke
Оператор REVOKE используется для снятия разрешений, ранее предоставленных учетному
имени. Формат оператора аналогичен формату оператора GRANT за некоторыми исключениями. Ключевое слово ТО оператора GRANT заменено на ключевое слово FROM при
снятии разрешений на исполнение SQL-операторов, а при снятии разрешений на работу с
объектами используются как ключевое слово ТО, так и FROM. Синтаксис снятия разрешений
на работу с объектами включает необязательные конструкции CASCADE и GRANT OPTION
FOR. Конструкция GRANT OPTION FOR используется для снятия разрешения WITH GRANT
OPTION, назначенного учетному имени. Ключевое слово CASCADE служит для снятия
разрешений с заданного учетного имени вместе со всеми разрешениями, предоставленными от
имени этого учетного имени любым другим учетным именам. Для снятия состояния
разрешения Grant, назначенного заданным учетным именем другим учетным именам, следует
использовать обе конструкции — GRANT OPTION FOR и CASCADE. Следующий пример
снимает разрешение EXEC с пользователя User01 и всех других пользователей, которым он
предоставил разрешение EXEC:
USE master REVOKE EXEC ON
xp_cmdshell FROM user01 CASCADE
Исполните следующую команду для просмотра текущих разрешений для расширенной
хранимой процедуры:
EXEC sp_helprotect 'xp_cmdshell'
Оператор DENY
Оператор DENY налагает явный запрет на предоставление учетным именам некоторых
разрешений, а также на наследование этих разрешений посредством членства в группе или
роли. Формат оператора DENY аналогичен формату операторов GRANT и REVOKE. Подобно
оператору GRANT, объект действия оператора задается ключевым словом ТО. Синтаксис
оператора DENY включает ключевое слово CASCADE, позволяющее налагать явный запрет не
только на разрешения, полученные данным учетным именем, но и на все разрешения,
предоставленные данным учетным именем другим учетным именам. Следующий код запрещает
исполнение SQL-выражений для идентификатора SQL Server и группы:
USE pubs
DENY CREATE TABLE, CREATE VIEW, BACKUP DATABASE, BACKUP LOG
TO user01, [BUILTIN\power users]
Управление ролями
Вне SQL Server можно управлять членством в группах, а в пределах SQL Server — членством в
ролях. Роли создаются в Enterprise Manager или с помощью Transact-SQL. Предопределенные
роли не могут быть членами других ролей. Например, нельзя сделать фиксированную
серверную роль SecurityAdmin членом фиксированной роли на уровне БД db_Owner. Членами
любой предопределенной роли (фиксированной роли на уровне сервера и на уровне базы
данных) могут быть как группы, так и отдельные пользователи. Членами фиксированных ролей
на уровне БД также могут быть стандартные роли, определяемые пользователем. В свою
очередь, разрешено стандартным пользовательским ролям содержать другие пользовательские
роли, группы и пользователей в качестве членов. Нельзя создать циклическое членство ролей.
Например, если роль Role01 является членом роли Role02, то роль Role02 не может быть
членом роли Role01. Прикладные роли не могут быть членами других ролей, для них также
запрещены собственные члены.
Создание и удаление ролей
В БД разрешается создавать и удалять стандартные пользовательские роли. В отличие от ^1 них
предопределенные фиксированные роли на уровне базы данных или сервера удалять нельзя.
Чтобы добавить роль с помощью Enterprise Manager, раскройте узел Roles, расположенный под
узлом базы данных в консоли, щелкните правой кнопкой панель Details, затем щелкните New
Database Role. Появляется диалоговое окно Database Role Properties — New Role, в котором
следует назвать новую роль и выбрать ее тип (стандартная или прикладная). Если выбран тип
standard (стандартная роль), то во время создания роли разрешается добавить к ней членов.
Если выбран тип application (прикладная роль), можно определить для нее пароль. Чтобы
удалить роль, выберите ее на панели и нажмите клавишу DELETE.
Средствами системной хранимой процедуры sp_addrole можно добавить роль в БД с
использованием Query Analyzer или инструмента командной строки типа osql. Входные
параметры этой хранимой процедуры позволяют задавать имя роли и (необязательно) ее
владельца. Если не задать принадлежность роли, то владельцем роли по умолчанию становится
ее создатель. Следующий пример добавляет к БД Pubs роль Role01:
USE pubs
EXEC sp_addrole @rolename = 'role01'
Стандартные пользовательские роли удаляются с помощью системной хранимой процедуры sp_droprole. Вот как удалить роль Role01:
USE pubs
EXEC sp_droprole @rolename = 'role01'
Чтобы добавить прикладную роль к БД с помощью Query Analyzer или утилиты командной
строки osql, используется системная хранимая процедура sp_addapprole. Как и в процедуре
sp_addrole, первым входным параметром здесь является @rolename. Но второй входной
параметр процедуры sp_addrole отличается; это — ©password. Имя и пароль прикладной роли
используются для ее активации, о чем рассказано в следующем разделе. Для удаления
прикладной роли используется процедура sp_dropapprole. Вот как добавить к БД Pubs
прикладную роль AppRole01 c паролем password01, а затем удалить созданную роль:
USE pubs
EXEC sp_addapprole @rolename = 'appRole01, @password = 'password01'
EXEC sp_dropapprole @rolename = 'appRole01
Управление членством в ролях
Стандартные роли располагаются в Enterprise Manager в двух узлах. Роли на уровне БД
содержатся в узле Roles, вложенном в узел данной БД; серверные роли содержатся в узле Server
Roles, расположенном под узлом Security. Чтобы добавить нового члена стандарт- i
ной роли в Enterprise Manager, щелкните правой кнопкой нужную роль на панели details, затем
щелкните Properties. В случае серверной роли выводится диалоговое окно Server Role
Properties, а в случае роли на уровне БД — диалоговое окно Database Role Properties. Диалоговое окно Server Role Properties позволяет управлять членством в ролях и просматривать
разрешения ролей. Диалоговое окно Database Role Properties также позволяет управлять
членством в ролях и устанавливать разрешения для пользовательских ролей. Модифицировать
разрешения для серверных ролей невозможно.
Системная хранимая процедура sp_addrolemember используется для добавления членов к
стандартным пользовательским ролям или фиксированным ролям на уровне БД.
Процедура sp_addsrvrolemember служит для добавления учетных записей к фиксированным
ролям на уровне сервера. Входными параметрами процедуры sp_addrolemember являются
@rolename и @membername, а для процедуры sp_addsrvrolemember — @loginame и @rolename.
Следующая программа-пример добавляет к стандартной пользовательской роли Role01 роль
Role02, группу BUILTIN\Power Users и пользователя User01:
USE pubs
EXEC sp_addrolemember @rolename = 'role01,
@membername = 'role02'
EXEC sp_addrolemember @rolename = 'role01',
ismembername = 'BUILTIN\power users'
EXEC sp_addrolemember @rolenaroe = 'role01,
@membername = 'user01
Для входного параметра @membername необходимо указать соответствующее имя. Например, если в БД псевдонимом группы Power Users является PowerU, то значение параметра
@membername — poweru. Чтобы операция добавления новых членов завершилась успешно, для
любого пользователя или группы, которые будут приписаны к роли, следует определить
соответствие для БД.
Ограничения членства в роли определяют, кого можно добавить с помощью процедуры
sp_addrolemember. Например, при попытке добавления к пользовательской роли предопределенной роли, скажем, db_DataWriter, операция завершится неудачей, как показано в
следующем примере:
USE pubs
EXEC sp_addrolemember @rolename = ' role01',
@membername = 'db datawriter'
SQL Server выводит следующее сообщение об ошибке:
Server: Msg 15405, Level 11, State 1, Procedure sp_addrolemember, Line 74
Cannot use the reserved user or role name 'db_datawriter'.
Для удаления членов роли используется системная хранимая процедура sp_droprole-member.
Вот как удалить пользователя User01 из роли Role01:
USE pubs
EXEC sp_droprolemember @rolename = 'role01,
@membername = 'user01
Активация прикладной роли
Пользователь, прошедший аутентификацию SQL Server, может использовать созданную в
БД прикладную роль, активировав ее. Действующие права прикладной роли определяются
контекстом безопасности подключенного пользователя. При активации прикладной роли
пользовательские привилегии становятся недействительными до конца сеанса. Для активации
прикладной роли служит процедура sp_setapprole. Вот как эту процедуру использовать для
активации прикладной роли Арр1 путем передачи пароля secretpass. Прикладная роль
локализована в БД Pubs:
USE pubs sp_setapprole 'арр1, 'secretpass’
Практическая часть
В лабораторной работе необходимо реализовать систему безопасности:
a. Настроить аутентификацию, путем создания учетных имен системы
безопасности и наделением их разрешениями на подключение к SQL Server.
b. Авторизовать учетные записи для доступа к БД, с помощью консоли Enterprise
Manager для вашей БД или использовать системные хранимые процедуры
sp_grantdbaccess и sp_revokeddbaccess.
c. Предоставить разрешения для работы с вашей БД, для управления
разрешениями использовать свойства учетной записи в Enterprise Manager,
свойства объекта или используя Query Analyzer с помощью операторов GRANT,
REVOKE, DENY,
d. Уметь управлять ролями; управление включает в себя создание и удаление
ролей, а также управление членством в них.
Работа производится на основе лабораторной работы № 5.