À. À. Çåëåíêîâ Â. Ì. Ñèíåãëàçîâ ÁÎÐÒÎÂÛÅ ÑÈÑÒÅÌÛ ÀÂÒÎÌÀÒÈ
реклама

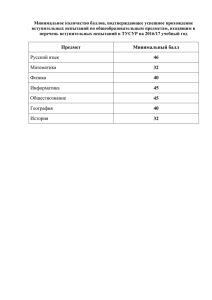
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЬІ
Национальный авиационный университет
À. À. Çåëåíêîâ Â. Ì. Ñèíåãëàçîâ
ÁÎÐÒÎÂÛÅ ÑÈÑÒÅÌÛ
ÀÂÒÎÌÀÒÈ×ÅÑÊÎÃÎ ÓÏÐÀÂËÅÍÈß.
ÎÖÅÍÊÀ ÒÎ×ÍÎÑÒÈ
ÏÎ ÐÅÇÓËÜÒÀÒÀÌ ÈÑÏÛÒÀÍÈÉ
Êèåâ 2009
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЬІ
Национальный авиационный университет
А. А. Зеленков, В. М. Синеглазов
БОРТОВЬІЕ СИСТЕМЫ
АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ.
ОЦЕНКА ТОЧНОСТИ ПО РЕЗУЛЬТАТАМ
ИСПЬІТАНИЙ
Киев
Издательство Национального авиационного университета
«НАУ-друк»
2009
УДК 629.735.051–52.018.7:519.2 (02)
ББК 052–057.0
З484
Рецензенты:
В. И. Скурихин — д-р т. н., проф., академик НАНУ;
В. В. Васильев — д-р т. н., проф., чл.-кор. НАНУ;
(Национальный авиационный университет)
Утверждено на заседании Ученого совета института электроники
и систем управления Национального авиационного университета
(протокол №8(2) от 19.10.2009 г.)
Рассмотрены вероятностно-статистические методы анализа результатов
летных и статистических испытаний магистральных самолетов, оборудованных системами управления автоматическим заходом на посадку и
посадкой, автоматизированным взлетом с целью определения показателей точности этих систем.
Для специалистов в области фундаментальной обработки результатов
испытаний сложных динамических систем управления, а также для аспирантов и студентов старших курсов соответствующих специальностей.
З484
Зеленков О.А.
Бортові системи автоматичного керування. Оцінка точності
за результатами випробувань: монографія / О.А. Зеленков,
В.М. Синєглазов. — К.: Вид. Нац. авіац. ун-ту «НАУ-друк»,
2009. — 264 с. (Рос. мовою).
ISBN 978–966–598–611–9
Розглянуто ймовірносно-статистичні методи аналізу результатів льотних та статистичних випробувань магістральних літаків, які обладнані системами керування автоматичним заходом на посадку та посадкою, автоматизованим зльотом з метою визначення показників точності цих систем.
Для фахівців у галузі фундаментальної обробки результатів випробувань складних динамічних систем керування, а також для аспірантів та
студентів старших курсів відповідних спеціальностей.
УДК 629.735.051–52.018.7:519.2 (02)
ББК 052–057.0
© Зеленков А.А.,
Синеглазов В.М., 2009
© НАУ, 2009
ISBN 978–966–598–611–9
2
СОДЕРЖАНИЕ
Введение . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1. ОСОБЕННОСТИ СОВРЕМЕННЫХ БОРТОВЫХ
СИСТЕМ УПРАВЛЕНИЯ . . . . . . . . . . . . . . . . . . . . . . 7
2. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА РЕЗУЛЬТАТОВ
ИСПЫТАНИЙ . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.1. Случайные процессы в задачах оценки точностных
характеристик бортовых систем управления . . . . . .
2.2. Методы анализа статистической структуры случайных
процессов . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2.1. Критерии стационарности относительно
среднего значения и параметра положения . . .
2.2.2. Критерии стационарности относительно
параметров рассеяния и дисперсии . . . . . . . .
2.2.3. Критерии независимости . . . . . . . . . . . . . .
2.2.4. Критерии однородности . . . . . . . . . . . . . . .
2.2.5. Критерии согласия . . . . . . . . . . . . . . . . . .
3. ОЦЕНКА ТОЧНОСТНЫХ ХАРАКТЕРИСТИК
ПО ЭКСПЕРИМЕНТАЛЬНЫМ ДАННЫМ . . . . . .
3.1. Особенности применения статистических методов
обработки данных . . . . . . . . . . . . . . . . . . . .
3.2. Определение точечных оценок вероятностных
характеристик . . . . . . . . . . . . . . . . . . . . . . .
3.3. Определение интервальных оценок вероятностных
характеристик . . . . . . . . . . . . . . . . . . . . . . .
3.4. Байесовское оценивание. . . . . . . . . . . . . . . . .
3.5. Последовательное оценивание . . . . . . . . . . . . .
3
. . 18
. . 27
. . 29
.
.
.
.
.
.
.
.
38
45
52
59
. . . . . 64
. . . . . 64
. . . . . 66
. . . . . 86
. . . . 111
. . . . 120
4. ОЦЕНКА СООТВЕТСТВИЯ ТОЧНОСТНЫХ
ХАРАКТЕРИСТИК ЗАДАННЫМ ТРЕБОВАНИЯМ . . .
4.1. Основные требования и проверка гипотез . . . . . . . .
4.2. Оценка соответствия точностных характеристик
заданным требованиям. . . . . . . . . . . . . . . . . . . .
4.3. Байесовские алгоритмы оценки соответствия . . . . . .
4.4. Планирование объемов испытаний . . . . . . . . . . . .
4.5 Последовательные алгоритмы оценки соответствия . . .
4.6. Прогнозирующий контроль точностных характеристик
. . 125
. . 125
.
.
.
.
.
5. ОЦЕНКА ВЕРОЯТНОСТНЫХ ХАРАКТЕРИСТИК
ПРИ СТАТИСТИЧЕСКОМ МОДЕЛИРОВАНИИ. . . . . .
5.1. Метод статистических испытаний . . . . . . . . . . . . . .
5.2. Особенности статистического моделирования процессов
автоматической посадки. . . . . . . . . . . . . . . . . . . .
5.3. Определение объемов испытаний при наличии
априорной информации . . . . . . . . . . . . . . . . . . . .
5.4. Методы уменьшения дисперсии оценок вероятностных
характеристик . . . . . . . . . . . . . . . . . . . . . . . . . .
.
.
.
.
.
134
167
175
184
195
. 203
. 203
. 216
. 223
. 245
Список литературы . . . . . . . . . . . . . . . . . . . . . . . . . 256
4
ВВЕДЕНИЕ
На протяжении двух последних десятилетий на воздушных судах гражданской авиации внедряются комплексы пилотажно-навигационного оборудования. Прогресс в области микроэлектроники
позволил промышленности разработать новые концепции проектирования, которые привели к созданию цифровой авиационной
электроники большой степени интеграции — интегрально — модульной авиационной электроники (IMA). Технология IMA позволяет создать бортовую отказоустойчивую систему управления, которая способна решать различные задачи управления самолетом в
условиях возникновения потока отказов с автоматическим восстановлением работоспособности.
Функциональные возможности бортовых систем управления
реализуются прикладным программным обеспечением, а сами прикладные программы являются функциональными элементами в
блочной архитектуре IMA. Повышение системной эффективности
функционирования перспективных самолетов с авионикой на борту
достигается на всех стадиях жизненного цикла, т.е. на этапах проектирования, летных и наземных испытаний, а также в эксплуатации.
Разработаны и разрабатываются нормативные требования к параметрам движения самолета, непосредственно или косвенно связанные с условиями обеспечения достаточного уровня безопасности. Как известно, уровень безопасности полета определяется уровнем летной годности самолета, т.е. свойством самолета выполнять
полет во всем диапазоне ожидаемых условий эксплуатации (в том
числе и при расчетных отказах). Автоматизация управления полетом на всех этапах должна обеспечивать, прежде всего, повышение
уровня безопасности в сложных метеоусловиях.
Можно определить три основных класса случайных воздействий, действующих на объект управления: внешние возмущающие
случайные факторы, порождаемые особенностями состояния внешней среды и процессов ее воздействия на летательный аппарат, а
5
также нестабильностью наземных средств обеспечения полета; параметрические возмущения, определяемые различного рода случайными отклонениями в конструктивных параметрах элементов
системы управления; помехи и шумы в измерительных и информационных трактах. Вследствие этого изменение параметров движения объекта управления носит стохастический характер и, следовательно, наиболее общей математической моделью описания сигналов являются случайные процессы.
Очевидно, что использование стохастических моделей, отражающих процесс функционирования объекта управления в реальной среде, приводит к необходимости получения большого объема
экспериментальных данных.
При создании новых систем управления для перспективных самолетов проводятся и будут проводиться различные виды наземных и летных испытаний, начиная с математического моделирования и заканчивая эксплуатационными испытаниями. Все они направлены на достижение единой цели, заключающейся в улучшении
характеристик системы управления и установления ее соответствия
заданным требованиям по точности и надежности для обеспечения
безопасности полета. При этом одной из основных задач является
оценка точности функционирования системы управления на всех
этапах полета (в особенности на этапах взлета и посадки, как этапах повышенной сложности), получаемая по результатам всех видов испытаний, а также подтверждения этой оценки при эксплуатации системы управления.
Все это говорит о том, что требуется хорошо развитый математический аппарат для определения вероятностных характеристик с
необходимой надежностью и позволяющий провести анализ соответствия бортовой системы управления поставленным требованиям. При этом не менее важной становится задача метрологического
обеспечения статистических измерений вероятностных характеристик и развития эффективных процедур их определения по результатам всех видов испытаний.
Предлагаемая книга построена на применении методов математической статистики и теории случайных процессов с целью разработки практически реализуемых вычислительных алгоритмов и
программного обеспечения для статистической обработки результатов испытаний сложных систем автоматического управления с
учетом специфики обрабатываемой статистической информации и
возможностей имеющейся вычислительной техники.
6
1
ОСОБЕННОСТИ СОВРЕМЕННЫХ
БОРТОВЫХ СИСТЕМ УПРАВЛЕНИЯ
Создаваемые цифровые системы управления на основе интегрально-модульной авиационной электроники (авионики), обладая
высокой степенью надежности, позволяют реализовать возможности автоматизации практически всех этапов полёта магистральных
самолетов.
Надежность, хотя и является важным и ответственным свойством, представляет лишь одну соответствующую характеристику
качества системы. Надежность, как правило, рассматривается во
взаимосвязи с иными свойствами системы такими как точность
управления и безопасность.
Авиационная электроника высокой технологии представляет
собой высокоорганизованный комплекс оборудования со своим программным обеспечением, взаимодействующим с самолетными системами. Авионике свойственны новые принципы: модульная конструкция, общая отказоустойчивая обработка информации и гибкий
самолетный интерфейс.
Область применения систем автоматического управления с повышенным уровнем надежности постоянно расширяется, так как во
многих случаях отказ системы может привести к большим материальным потерям или даже к угрозе жизни людей. Это в полной мере относится к бортовым системам управления. Под современной
бортовой системой автоматического управления понимается программно — аппаратный комплекс, состоящий из вычислительной
системы, операционной системы, прикладных программных средств
и исполнительных устройств.
Источниками отказов могут быть неисправности и ошибки любого из компонентов вычислительной системы, а также искажения
передаваемых данных. Процесс функционирования любой системы
может рассматриваться как последовательность переходов из одного состояния в другое. Отказы — это переходы, которые ведут в
7
ошибочные (или неисправные) состояния, из которых система может перейти в состояние проявления неисправности [79]. Причиной
перехода системы в неисправное состояние всегда является отказ
внутри ее. Возможны два вида отказов: отказы элементов и структурные отказы. Отказ элемента вызывается неисправным состоянием
элемента (пробой диода, искажение блока данных при записи и т.п.).
Структурные отказы вызываются неправильным взаимодействием
исправных элементов (неправильное соединение электронных элементов, несоответствие фактических параметров в операторе вызова подпрограммы типам формальных параметров в ее описании и
т.п.). Различие между двумя видами внутренних отказов существенны с точки зрения отказоустойчивости: отказы элементов легче
обнаруживаются и исправляются, чем структурные отказы. Аппаратные отказы по большей части первого вида, а программные —
второго. Это объясняется тем, что в сложных системах аппаратура
значительно проще, чем программное обеспечение, из-за меньшего
количества составляющих элементов, взаимосвязей и состояний,
так что ошибка проекта аппаратуры — событие достаточно редкое.
При создании сложного программного обеспечения уже упоминавшиеся трудности спецификации приводят к тому, что в программах неизбежно содержатся ошибки, не выявленные при тестировании и отладке, что делает уровень надежности программного
обеспечения ниже, чем у аппаратуры.
Таким образом, для повышения уровня надежности системы
управления до значений, задаваемых нормативными требованиями,
необходимо принимать специальные меры, которые можно условно разделить на два направления: предупреждение отказов и обеспечение отказоустойчивости [79].
Меры первого направления имеют целью исключить ошибки
при разработке вычислительной системы, увеличить безотказность
и долговечность ее элементов (испытания и тестирование аппаратуры, облегчение режимов нагрузки электронных компонентов, верификация, тестирование и отладка прикладных программ). Необходимо отметить, что абсолютная безотказность элементов аппаратуры
и безошибочность программ недостижимы ввиду физического старения компонентов и высокой сложности программного обеспечения.
Меры второго направления обеспечивают свойство отказоустойчивости, т.е. способность обнаруживать отказы и устранять или
уменьшать их последствия и продолжать исправное функционирование (возможно с худшими показателями качества или, если это
невозможно, утрачивать функции в порядке, обратном приоритету).
8
Другими словами, отказоустойчивостью называется способность
оборудования продолжать работать с установленными характеристиками после того, как произойдет один или несколько отказов.
Отказ может представлять собой неисправность компонентов аппаратуры или дефект, допущенный при реализации аппаратуры или
программного обеспечения. Термин «продолжающаяся работа» охватывает диапазон определений от полной работоспособности всех
функций до различных установленных уровней пониженной способности выполнять работу.
Если в отказоустойчивой системе модуль или функция в модуле
отказывают, система управления может автоматически осуществить реконфигурацию, чтобы нейтрализовать неисправность, а затем продолжать удовлетворительно работать до запланированного
технического обслуживания, во время которого отказавший модуль
может быть отремонтирован или заменен. На сегодняшний день
философия технического обслуживания строится на желании иметь
планируемые интервалы технического обслуживания. Для достижения планового технического обслуживания необходимо установить зоны удержания неисправности по всей архитектуре бортовой
системы автоматического управления. При использовании этого
подхода появляется возможность быстрого обнаружения любой
неисправности и изоляции ее до данной зоны удержания неисправности. Каждая из этих зон должна обнаруживать и объявлять достоверность выдаваемых ею данных всем потребителям. Такой подход позволяет системе точно сообщать о своем техническом состоянии и дает возможность достигать таких целей в техническом
обслуживании, которые раньше были недостижимы.
Общий принцип обеспечения отказоустойчивости систем управления — резервирование ресурсов (как на функциональном уровне,
так и резервирование компонентов): аппаратных, временных, информационных и программных, причем в комбинированной форме.
Функциональная готовность гарантируется предоставлением многочисленных путей для передачи данных от их источников к местам обработки, требуемой для приемников данных, будь то индикатор, исполнительное устройство или другое функциональное устройство. Резервирование компонентов конечно же необходимо, но
упор делается на гораздо более широком использование техники
удержания отказа, чтобы позволить другим компонентам в системе
продолжать функционировать в присутствии неисправности.
Аппаратная отказоустойчивость достигается варьированием ресурсов для получения отказоустойчивой конфигурации (выбор сред9
него значения, голосование и т.п.). Программная отказоустойчивость достигается с помощью N — вариантного программирования,
повторения последней операции, повторного выполнения программы и т.п.
Требование обеспечения отказоустойчивости оказывает существенное влияние на конструкцию оборудования. Для того, чтобы
система продолжала работать, необходимо или иметь резервирование ресурсов или иерархию задач, приносимых в жертву. Должны
быть обеспечены также механизмы контроля переключения для
распознавания отказа и предоставления пути реконфигурации.
Действия по обеспечению отказоустойчивости разбиваются на
два этапа: обнаружение неисправного состояния средствами контроля (отказавшие элементы должны быть определены и изолированы) и восстановление исправного состояния (ресурсы системы
должны быть перестроены таким образом, чтобы устранить остаточное влияние отказа на работу системы).
Переход от первого этапа ко второму происходит по специальному сигналу при обнаружении отказа определенного типа. В этом
случае вычислительная система начинает выполнять соответствующую программу, в которой задан алгоритм восстановления.
Восстановление возможно путем отката — возврата процесса к
исправному состоянию, предшествовавшему переходу в неисправное состояние, или путем исправления — перевода процесса в исправное состояние без возврата к предыдущему состоянию. Для
возможности отката нужно запоминать некоторые состояния процесса — потенциальные точки возврата, называемые точками восстановления. При откате существенным образом задействуется
временной резерв, ибо для возврата к нормальной работе процесс
повторяет пройденную последовательность состояний. Очевидно,
что откат — эффективное средство борьбы со сбоями.
Исправление гораздо менее универсально, чем откат, так как
основано на знании специфики процесса для нейтрализации неисправности.
К другим возможным способам восстановления относятся маскирование отказа путем голосования, реконфигурация (например,
выполнение альтернативной версии программы, возможно более
грубой) и мягкий останов.
Что касается программного обеспечения, то оно не изнашивается и, следовательно, не имеет зависимости частоты отказов от времени. Техника реализации программного обеспечения содействует
обеспечению общей отказоустойчивости бортовой системы управ10
ления. Наиболее широко применяется N — вариантное программирование. В этом случае для организации отказоустойчивости независимо разрабатываются по общим техническим условиям два или
больше вариантов программного обеспечения для выполнения одной и той же задачи. Эти варианты могут выполняться последовательно одним и тем же процессором, но обычно они выполняются
параллельно на отдельных процессорах (иногда на различных типах процессоров, как дополнительная мера по обеспечению отказоустойчивости).
Таким образом, создаваемые интегрированные бортовые системы управления должны пройти целый комплекс испытаний, как
наземных, так и летных, с целью оценки их соответствия заданным
требованиям, а также подтвердить характеристики точности и надежности в процессе эксплуатационного контроля.
Всё это свидетельствует об актуальности разработки единой методологии оценки точности и надежности бортовых систем управления и их программного обеспечения на всех стадиях жизненного
цикла с целью достижения единой цели — поддержания уровня отказобезопасности, рис. 1.1.
Характеристики надежности аппаратуры:
• вероятность безотказной работы;
Отказобезопасность
Отказоустойчивость
Показатели
надежности
аппраратуры
Показатели
надежности
ПО
Живучесть
Показатели
живучести
апаратуры
Показатели
живучести
ПО
Точность управления
Показатели
точности
Рис. 1.1. Взаимосвязь показателей качества системы управления
• средняя наработка до отказа;
• интенсивность отказов;
• параметр потока отказов;
• среднее время восстановления;
• резервирование (структурное, параметрическое, функциональное,
информационное);
• реконфигурация динамическая и статическая;
• среднее время между отказами;
• параметр потока восстановлений;
11
• коэффициент готовности;
• коэффициент оперативной готовности;
• среднее время до первого отказа;
• количество отказов за заданное время;
• количество восстановлений и вероятность восстановления за
заданное время.
Характеристики надежности ПО:
• вероятность правильного выполнения алгоритма при наличии
ошибок в программе (корректность ПО);
• вероятность правильного выполнения алгоритма при наличии
отказов и сбоев технических средств (устойчивость ПО);
• среднее время выполнения алгоритма;
• среднее число ошибок в программе на одну команду;
• среднее время восстановления;
• вероятность превышения длительностью восстановления (после возникновения отказа) порогового значения между отказом и
сбоем.
• алгоритмический контроль входного и выходного потока информации;
• логический контроль;
• реконфигурация;
• N-вариантное программирование;
• тестовый контроль процессоров и памяти;
• диагностическое тестирование;
Характеристики живучести аппаратуры:
• локализация отказов функциональных элементов, вызванных
воздействием окружающей среды, отличающейся от условий нормальной эксплуатации;
• адаптация (изменение свойств и характеристик) с целью исключения влияния непредусмотренных воздействий;
• постепенная деградация показателей качества функционирования при накоплении отказов;
• кратность отказа, при котором начинается постепенная деградация системы;
• коэффициент живучести;
• многопроцессорная реализация системы, её распределённость
и доступность, возможность осуществления параллельных вычислительных процессов и доступность каналов связи для полного
информационного обмена между элементами системы;
12
• функциональное резервирование;
• пожаробезопасность;
• молниезащита;
• вероятность выполнения основных функций при наличии отказов.
Характеристики живучести ПО:
• динамическая избыточность в виде неидентичных копий модулей программы, выполняющих одну и туже функцию с менее
эффективным алгоритмом, но с более высоким быстродействием;
• программа, обеспечивающая безаварийный переход к процессу ручного управления.
Характеристики точности:
• вероятность нахождения вектора определяющих параметров в
допустимой области;
• среднеквадратическое отклонение определяющего параметра;
• математическое ожидание определяющего параметра;
• доверительный интервал на статистическую характеристику;
• толерантный интервал на определяющий параметр;
• вероятность превышения определяющим параметром порогового значения;
• соответствие моделей законов распределения реальным распределениям.
Оптимизация процесса исследования точности и надежности
бортовых систем управления требует решения комплекса сложных
научно технических проблем, к числу которых относится разработка математического и программного обеспечения обработки результатов испытаний (наземных, включая статическое моделирование, и летных) и данных эксплуатации. В то же время применение
методов экспериментального статистического анализа связано не
только с разработкой их теоретических и методических основ, но и
с созданием и развитием инструментальных средств реализации в
виде управляемой базы данных, рис. 1.2.
Современные технологии разработки бортовых систем управления и их программного обеспечения требуют и соответствующего
информационного обеспечения как процесса разработки и испытаний, так и процесса эксплуатации. Анализ и классификация задач,
решаемых на стадии эксплуатации, свидетельствует об их тесной
связи с задачами на стадии разработки. В то же время номенклатура задач, решаемых на этапе эксплуатации, имеет собственную
специфику, которая должна найти отражение в информационном
13
обеспечении этого процесса, основывающемся на базе данных, как
на едином информационном ресурсе.
Информационное сопровождение испытаний и эксплуатации авионики обеспечивает:
• сбор, обработку и анализ данных испытаний о точности процессов автоматического управления на различных этапах полета;
Разработчик
Требования
Эксплуатант
Статистическое
моделирование
ПО текущей оценки
точности
Обоснование
технического
задания
Полунатурное
моделирование
ПО текущей оценки
надёжности
Стендовые
испытания
База данных
эксплуатационных компаний
Заводские
летные испытания
ПО регистрации,
систематизации,
классификации
отказов техники и ПО
Проектирование
Разработка
Серийное
производство
Априорная информация
Замысел
Создание
новых
версий ПО
Государственные
летные испытания
Эксплуатационные
испытания
База данных
ПО текущей оценки
надёжности версий ПО
ПО оценки
текущего прогноза
База данных
Рис. 1.2. Структурная схема мониторинга
бортовых систем
• сбор, обработку и анализ данных о надежности бортовой системы управления и её программного обеспечения;
• регистрацию, систематизацию и классификацию отказов техники и программного обеспечения на этапе испытаний и эксплуатации для каждого экземпляра воздушного судна данного типа;
• обработку и анализ полученной информации с целью прогнозирования технического состояния воздушного судна;
• передачу необходимой информации соответствующим эксплуатационным компаниям, разработчикам систем управления и программного обеспечения.
14
Одним из наиболее важных этапов информационного сопровождения является этап статистической обработки экспериментальных данных. Как правило, на этом этапе используют три основных
группы методов обработки: классические (параметрические), робастные и непараметрические.
В классической статистике рассматривается параметрическая
модель: выборка x1 , x2 , …, xn соответствует распределению известного вида F(x), которое задано с точностью до 1—2 неизвестных моментов. Например, для предполагаемого нормального распределения выборки неизвестными являются параметры смещения
m и масштаба σ, для экспоненциального распределения неизвестным является один параметр. Параметрическая модель позволяет
применять полный статистический аппарат для решения основных
задач оценивания и проверки гипотез.
Робастные оценки строятся таким образом, чтобы их свойства
оставались хорошими даже в том случае, когда предполагается не
строгая модель нормального распределения, а распределение с
«тяжелыми хвостами» (когда вероятности больших отклонений от
среднего существенно больше, чем при гауссовском распределении). Одной из таких моделей является модель засорения (модель
грубых ошибок), представляющая собой сумму основного гауссовского распределения и засоряющего распределения h(x) с соответствующими весами:
pε ( x) = f ( x)(1 − ε) + εh( x).
Как правило, распределение h(x) принимают нормальным, но со
значительно большей дисперсией, чем f ( x) (например, отношение
среднеквадратических отклонений σ h к σ f принимают равным 3
или 10). Необходимо отметить, что робастные методы, основанные
на достаточно общих моделях, все же являются параметрическими.
Непараметрические методы не предполагают использование
какого-либо параметрического семейства и в настоящее время составляют сложившуюся систему обработки данных, которая по своим
возможностям сопоставима с классической теорией. Большинство
методов основано на вариационном ряде с использованием порядковых статистик.
Очевидно, что для получения надежных статистических выводов относительно точностных характеристик необходимо применять параллельную обработку экспериментальных данных, исполь15
зуя как параметрические, так и непараметрические методы обработки, учитывающие также и априорную информацию, полученную на предыдущих этапах испытаний, рис. 1.3
Статистическое моделирование
Летные испытания
Параметрическая
обработка
Проверка
гепотезы
Робастное
оценивание
Выводы
Непараметрическая
обработка
Статистическая
обработка случайных
процессов
Априорная
информация
Рис. 1.3. Схема обработки результатов испытаний
Кроме того, обеспечение требуемого уровня безопасности полётов самолётов в условиях сниженных минимумов посадки определяет постановку проблемы создания эффективных методов оценки
соответствия систем управления заданным требованиям, которые
должны быть составной частью процесса сертификации систем управления. Основные требования, которые должны быть удовлетворены, представляют собой уровни вероятностей опасных и безопасных ситуаций, а также среднеквадратические отклонения определяющих параметров движения самолета в наиболее критических
режимах полета: заход на посадку, приземление, пробег, уход на
второй круг и автоматизированный разбег.
Все указанные характеристики определяются на основе статистической обработки экспериментальной информации, полученной
на различных этапах испытаний, в том числе и на этапе статистического моделирования.
16
2
ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА
РЕЗУЛЬТАТОВ ИСПЫТАНИЙ
Общая схема статистического анализа результатов испытаний,
как правило, состоит из следующих этапов:
• Предварительный анализ исследуемой системы управления с
целью выделения тех параметров движения самолета, которые определяют точность системы управления, определение необходимой
априорной информации и представление ее в виде удобном для последующей статистической обработки, составление математической модели объекта управления для проведения статистического
моделирования, определение вероятностных моделей случайных
факторов, влияющих на поведение объекта управления.
• Составление плана эксперимента с целью получения статистической информации необходимого объема и продолжительности
для выбранных внешних условий, определение диапазонов изменения внешних и внутренних факторов при проведении статистических испытаний методом Монте–Карло, а также при проведении
полунатурных и летных испытаний.
• Формирование массивов исходных статистических данных в
виде матриц соответствующих размерностей и их первичная статистическая обработка, включающая в себя анализ резко выделяющихся наблюдений, восстановление пропущенных наблюдений;
проверка статистической независимости последовательности измеренных значений, проверка однородности нескольких массивов
(групп измерений), стационарности и эргодичности случайных
процессов на выделенных временных участках их изменения; экспериментальный анализ законов распределения исследуемых генеральных совокупностей; определение вероятностной структуры исследуемых случайных процессов, приведение реальных нестационарных процессов к квазистационарной форме путем выделения
стационарных участков и аппроксимации нестационарной части
реализации комбинацией известных функций времени и неизвест17
ных постоянных коэффициентов, определяемых исходя из заданной точности аппроксимации.
• Параметрические и непараметрические оценки как точечных,
так и интервальных вероятностных характеристик по результатам
летных испытаний (математические ожидания, дисперсии, вероятности нахождения контролируемых параметров в заданных допустимых областях); оценка вероятностных характеристик при наличии априорной информации, полученной в процессе предшествующих теоретических расчетов, статистического моделирования и
испытаний, представленной в виде априорных законов распределения; оценка соответствия исследуемой системы управления заданным требованиям по точности на основе полученных вероятностных характеристик и согласованных рисков (вероятностей ошибок
первого и второго рода) как по результатам статистического моделирования, так и по результатам летных испытаний.
• Выводы по результатам статистического анализа реализаций
случайного изменения параметров движения самолета на всех этапах полета, полученных при статистическом моделировании и в
процессе летных испытаний; проверка адекватности математической модели реальному объекту на основе рассогласования тех или
иных вероятностных характеристик распределения выходных координат объекта и модели (как правило функций или плотностей
распределения); оценка возможности распространения полученных
результатов на всю область факторного пространства с целью сертификации системы управления.
2.1. Случайные процессы в задачах оценки точности
бортовых систем управления
Как уже отмечалось, современное пилотажно-навигационное оборудование представляет собой комплекс взаимосвязанных контуров управления, состоящих из средств измерения параметров режимов полета и положения самолета, корректирующих и вычислительных устройств с соответствующим программным обеспечением, преобразователей, усилителей мощности, линий связи, приводов, пультов управления, систем встроенного и внешнего контроля,
индикации и сигнализации. При выполнении многочисленных
функций бортовая система управления должна обеспечивать необходимый уровень безопасности во всем диапазоне ожидаемых условий эксплуатации, а также необходимый уровень живучести при
усложнении условий полета.
18
Условия работы системы управления не могут быть полностью
известны, по крайней мере часть воздействий не может быть заранее определена. При этом можно получить не точное описание поведения объекта управления, а лишь общие вероятностные закономерности. Может быть использовано статистическое описание,
когда закономерности выявляются не в каждом конкретном случае,
а в совокупности большого числа случаев. Тогда воздействие задается в виде случайного процесса, представляющего собой множество реализаций с вероятностной мерой, заданной на этом множестве. Соответственно выходной сигнал системы также считается
случайной функцией и определению подлежат вероятностные характеристики этой функции, которые далее будем называть также
точностными характеристиками.
Показателями точности управления являются статистические точностные характеристики, определяющие возможный разброс параметров движения самолета, обусловленный случайными и систематическими ошибками, а также действием возмущающих факторов
[1–8]. Можно определить три основных класса случайных воздействий, действующих на объект управления:
• внешние возмущающие факторы, порождаемые особенностями состояния внешней среды и процессами ее воздействия на летательный аппарат, а также нестабильностью наземных средств обеспечения полета;
• параметрические возмущения, определяемые различного рода
случайными отклонениями в конструктивных параметрах элементов бортовой системы управления;
• помехи и шумы в измерительных и информационных трактах.
Таким образом, изменение параметров движения объекта управления носит стохастический характер и, следовательно, наиболее
общей математической моделью их описания являются случайные
процессы.
Это означает, что задача оценки точностных характеристик и
сертификации бортовых систем управления включает в себя задачу
измерения (оценки) вероятностных характеристик случайных величин и процессов.
При разработке методики измерения и соответствующих алгоритмов принципиальными являются четыре признака [74]: класс
исследуемого случайного процесса, вид измеряемой точностной
характеристики, тип используемого оператора усреднения и вариант организации измерительного эксперимента. Не учет статистической структуры случайного процесса может приводить к возник19
новению сколь угодно больших погрешностей измерений и неверной интерпретации получаемых результатов.
Уже на первых этапах статистической обработки исходных данных {zij } необходимо ответить на целый комплекс вопросов, ответы на которые определят правомерность и эффективность применяемых методов анализа:
• можно ли считать имеющиеся данные {zij } как данные, полученные в результате независимых наблюдений;
• можно ли считать некоторый выделенный интервал случайного процесса стационарным и эргодическим;
• при наличии нескольких массивов выборочных данных
{zij }(1) ,...,{zij }( k ) можно ли считать, что все они относятся к одной
и той же генеральной совокупности;
• какой закон распределения (вернее его теоретическая модель)
выборочных данных {zij } является наиболее подходящим для последующей эффективной статистической обработки и как проверить соответствие этого закона реальным данным;
• какие статистические критерии проверки тех или иных гипотез являются наиболее эффективными при статистической обработке результатов испытаний.
В соответствии с действующими национальными и зарубежными нормами [1–3] точностные характеристики автоматизированного управления движением самолета для различных режимов полета
(захода на посадку, посадки, разбега, пробега, маршрутного полета) определяются вектором вероятностных характеристик распределений определяющих параметров движения самолета, содержащим в общем случае параметры положения, масштаба (разброса) и
вероятностной меры допустимой области отклонений параметров
движения.
Не останавливаясь подробно на особенностях каждого этапа заметим, что на каждом из них можно выделить определяющие параметры движения, существенно влияющие на уровень безопасности полета. Очевидно, что в процессе любой особой ситуации изменяются параметры движения летательного аппарата. Параметры,
которые имеют ограничения из условий обеспечения безопасности
полета, называют определяющими. Связь областей режимов полета
и особых ситуаций с рекомендованными, допустимыми и предельными значениями определяющего параметра можно представить в
виде, показанном на рис. 2.1 [45].
20
Эксплуатационные
Предельные
режимы
режимы
Нормальные
Усложнение
Опасные
(штатные)
условий
ситуации
ситуации
полета
z рек
z доп
Критичесекие
режимы
Аварийные
ситуации
z пр
z
Рис. 2.1. Связь режимов полета и особых ситуаций
Задача оценки точностных характеристик в различных режимах
полета сводится к задаче оценки вероятностных характеристик
случайных величин и процессов. Их вид существенно зависит от
рассматриваемого режима полета, реализуемого способа управления, контролируемого параметра движения самолета и типа его вероятностного распределения. Основными видами управления в режимах разбега, маршрутного полета, захода на посадку, посадки и
пробега являются стабилизация и терминальное управление.
В процессе стабилизации самолет удерживается в пространстве
или на взлетно-посадочной полосе в положении близком к заданному в течении определенного времени Т выполнения режима полета. К таким режимам относится, например, маршрутный полет,
режим захода на посадку, управление боковым движением самолета при разбеге и пробеге по взлетно-посадочной полосе. Требования
к точности процессов управления в режиме стабилизации устанавливаются на все время Т выполнения режима. Здесь оцениваемые
точностные характеристики представляют собой средние или интегральные вероятностные характеристики случайного процесса.
В режиме терминального управления бортовая система должна
приводить самолет в заданное конечное состояние в назначенный
момент времени t0 или в заданную точку пространства. Терминальный характер имеют управление в режиме посадки (ВПР и точка
касания), управление продольным движением самолета при разбеге
(момент отрыва передней стойки от ВПП). Требования к точности
функционирования бортовой системы управления в этих режимах
устанавливаются в терминальный момент времени t0 , соответствующий завершению режима управления.
Требования к точности функционирования бортовых систем
управления определяются в виде равенств и неравенств, накладываемых на компоненты вектора точностных характеристик.
Ограничения, накладываемые на координаты вектора Z образуют пространство допустимых отклонений D. В частности, при21
земление будет успешным, если обеспечивается выполнение ограничений:
γ ≤ γ доп
ψ ≤ ψ доп
ϑдоп min ≤ ϑ ≤ ϑдоп max
Vдоп min ≤ V ≤ Vдоп max
Vy доп min ≤ Vy ≤ Vy доп max
α ≤ α доп max
β ≤ β доп max
z ≤ zдоп
z ≤ zдоп
Lmin доп ≤ L ≤ Lmax доп
⇒ Z ∈D
где γ, ψ, υ — угловые координаты, V, V y — скорость и вертикальная скорость, α и β — углы атаки и скольжения, z и z — боковое
отклонение от оси ВПП и его производная, L — продольное отклонение самолета от некоторой заданной точки на оси ВПП. Величина допустимой области зависит главным образом от летно-технических характеристик самолета и размеров ВПП.
Очевидно, что источником информации для оценки точностных
характеристик являются реализации случайных процессов изменения вектора Z (t ) контролируемых параметров движения самолета, получаемые в летных испытаниях, в процессе моделирования соответствующих режимов полета, а также в процессе
эксплуатации.
Вычислительные алгоритмы процедур статистического оценивания вероятностных характеристик случайных процессов образуются последовательным применением к исходному массиву {zij }
измеренных значений параметров оператора преобразования h, лежащего в основе функционального определения искомой вероятностной характеристики и оператора усреднения.
В основу определения вероятностных характеристик случайных
процессов могут быть положены следующие соотношения:
1 N
∑ h[ zki (t )],
N →∞ N k =1
θ z = lim
22
1T
∫ h[ zki (t )]dt ,
T →∞ T 0
θ z = lim
где zki (t ) представляет собой k-ю реализацию исследуемого процесса zi (t ) (і-го определяющего параметра вектора Z ), h(z) — некоторый оператор преобразования, лежащий в основе определения
характеристики θ , N — число реализаций определяющего параметра, по которым проводится усреднение, Т — интервал усреднения одной реализации.
Очевидно, что при усреднении по ограниченной совокупности
реализаций, оценка вероятностных характеристик осуществляется
как
1 N
θ∗ (t ) = θ∗ [ zi (t )] = ∑ h[ zi (t )],
N k =1
где θ∗ (t ) — текущая вероятностная характеристика.
При усреднении по одной реализации ограниченной длительности используется соотношение:
1T
θ∗ (k ) = θ∗ [ zki (t )] = ∫ h[ zki (t )]dt ,
T0
где θ∗ (k ) — локальная вероятностная характеристика.
При последовательном усреднении по каждой реализации и по
ансамблю реализаций используется выражение
1 NT
θ∗ср = θ∗ [ zki (t )] =
∑ ∫ h[ zki (t )]dt ,
NT k =1 0
где θ∗ср — средняя вероятностная характеристика [74].
Выделим фундаментальные свойства случайных процессов,
обеспечивающие корректность применения рассмотренных выше операторов усреднения при оценке вероятностных характеристик случайных процессов. Как известно [17, 43, 63], стационарным является процесс, вероятностные характеристики которого не зависят от времени. В качестве примера стационарного
случайного процесса можно указать на процесс изменения скорости самолета в режиме установившегося полета. Примерами
нестационарного процесса являются переходные процессы, возникающие в системе управления при любом случайном входном
сигнале. В зависимости от изменчивости вероятностных свойств
от номера реализации различают эргодические и неэргодические
23
случайные процессы. Процесс является эргодическим, если его
вероятностные характеристики, полученные усреднением по
множеству возможных реализаций, с вероятностью, сколько
угодно близкой к единице, равны временным средним, полученным усреднением за достаточно большой промежуток времени
по одной реализации случайного процесса.
Необходимыми и достаточными условиями эргодичности случайного процесса являются его строгая стационарность и метрическая транзитивность [49, 62], состоящая в том, что любая часть совокупности реализаций случайного процесса, вероятностная мера
которой отлична от нуля или единицы, уже не является стационарной. Очевидно, что стационарность должна быть необходимым условием эргодичности, так как для нестационарного процесса вероятностные характеристики, определенные по совокупности реализаций, являются функциями времени, и, следовательно, характеристики, определяемые по времени, не будут совпадать с характеристиками, определяемыми по совокупности.
В то же время стационарность не является достаточным условием. Примером стационарного, но неэргодического случайного процесса является процесс, заданный выражением [11]:
Z(t) = X (t) + Y,
где X(t) — эргодический случайный процесс, Y — непрерывная
случайная величина, плотность вероятности которой f (ξ), −∞ < ξ < ∞
(здесь ξ — реализация случайной величины Y). Хотя процесс стационарный, однако условие метрической транзитивности нарушается. Совокупность реализаций z(t) может быть разбита на две части: в одной из них возможные значения случайной величины Y > 0
∞
0
0
−∞
и p1 = ∫ f (ξ)dξ > 0, а в другой Y< 0 и p2 = ∫ f (ξ)d ξ > 0, так что
p1 + p2 = 1.
Очевидно, что каждая из частей сохраняет свойство стационарности при вероятностных мерах p1 и p2 , отличных от 0 или
1, рис. 2.2.
Таким образом, если случайный процесс эргодический, то любая его реализация представляет свойства всей совокупности, и поэтому результат усреднения по времени, выполненного над одной
реализацией, совпадает с соответствующим средним по совокупности в любой момент времени, рис. 2.3.
24
z(t)
ξ
∞
P1
0
0
t
0
P2
−∞
Рис. 2.2. Стационарный неэргодический процесс
zi(t)
z(t)
t
T
t
to
Рис. 2.3. Стационарный эргодический процесс
Оценка математического ожидания, определяемая по совокупности реализаций в момент времени t0 , равна
1 N
∑ zi (t0 ) ,
N i =1
а оценка, определяемая временным усреднением одной (любой)
реализации, равна:
1T
mT∗ = ∫ zi (t )dt.
T0
< m(t0 )∗ >=
Для эргодического процесса
< m(t0 )∗ >= mT∗ ,
где равенство понимается в статистическом смысле проверки соответствующих гипотез.
25
Как правило, проверка условия метрической транзитивности
оказывается весьма затруднительной, однако в некоторых случаях
легко указать достаточные условия эргодичности [43]:
• Случайный процесс Z(t) с постоянным математическим ожиданием m эргодичен по отношению к математическому ожиданию
1T
если стохастический интеграл ∫ z (t ) dt сходится по вероятности к
T0
m при T → ∞. Из неравенства Чебышева следует, что для этого достаточно выполнение соотношения:
2
⎧1 T
⎫
M ⎨ ∫ z (t ) dt − m ⎬ → 0,
⎩T 0
⎭
T → ∞.
• Если корреляционная функция процесса K (t1 , t2 ) стремится к
нулю при t2 − t1 → ∞, то случайный процесс Z(t) эргодичен по отношению к математическому ожиданию.
• Если корреляционная функция К(τ) стационарного случайного процесса Z(t) имеет вид K ( τ) =
∞
∫e
2 πiωτ
dF (ω) , где спектраль-
−∞
ная функция F(ω) непрерывна в точке ω = 0, то процесс Z(t) эргодичен по отношению к математическому ожиданию.
• Нормальный (гауссовский) стационарный процесс Z(t) эргодичен по отношению к корреляционной функции K(τ), если K(τ) → 0
при τ → ∞.
На практике вместо вычисления интеграла от реализации случайного процесса усредняют значения процесса в отдельных точках, рассматривая выражение
ηn =
1 n
∑ z (k Δ).
n k =1
Так как
M [ηn ] = m,
1 n
D[ηn ] = 2 ∑ M ⎡⎣ z (0) (k Δ ) z (0) ( j Δ ) ⎤⎦ =
n k , j =1
n
1
1 n
= 2 ∑ K [(k − j )] = 2 ∑ (n − i ) K (iΔ ) =
n k , j =1
n i =− n
26
i⎞
1 n ⎛
∑ ⎜1 − ⎟K (iΔ ),
n i =− n ⎝ n ⎠
(0)
где z (•) — центрированная реализация случайного процесса, а
K (τ) → 0, то ηn сходится по вероятности к m, т.е. вместо инте=
n →∞
грального усреднения можно использовать усреднение по значениям процесса в точках t = kΔ.
Совершенно аналогична вероятностная интерпретация корреляционной функции стационарного случайного процесса при выполнении свойства эргодичности относительно этой функции:
K (τ) = M [ z (t0 + τ)z (t0 )] = ∫ z (t0 + τ,ω)z (t0 ,ω)P (dω) =
Ω
1 n
= lim ∑ z (t0 + τ,ωk )z (t0 ,ωk ) =
n →∞ n k =1
T
1
1 n
= lim ∫ z (t + τ)z (t )dt = lim ∑ z (k Δ + τ)z (k Δ ),
T →∞ T
n →∞ n k =1
0
где все пределы следует понимать в смысле сходимости по вероятности, Ω — множество элементарных событий такое, что Z(t) =
= Z(t, ω), ω ∈ Ω является случайным процессом, а при фиксированном ω функция Z(t, ω) представляет собой реализацию случайного процесса, Р(dω) — вероятностная мера.
Таким образом, при определении вероятностных характеристик
необходимо исследовать статистическую структуру исследуемого
случайного процесса с целью эффективного использования того или
иного оператора усреднения.
2.2. Методы анализа статистической структуры
случайных процессов
Задача определения статистической структуры процессов изменения определяющих параметров движения летательного апарата
может бать основана на методах теории статистических решений.
Реализации случайного процесса формируються в выборки объема
N, в которых условия полета приблизительно одинаковы, что обеспечивает статистическую однородность результатов. В частности, в
условиях летных испытаний выборка соответствует одному испытательному полету и включает в себя 5–10 реализаций. При по27
строении оптимальных решающих правил относительно вектора
оцениваемых вероятностных характеристик целесообразно использование сложного составного критерия, при котором последовательно исследуются свойства стационарности процессов относительно каждой оцениваемой характеристики, а решение о классе и
структуре процессов осуществлять на основе результата проверки
ряда гипотез. Тогда идентификация статистической структуры случайного процесса заключается в выделении однородных компонент
процесса, несущих информацию об оцениваемых вероятностных
характеристиках [11]. Свойства стационарности могут быть проверены на основе равенства значений измеряемых вероятностных
характеристиках, соответствующих различным временным сечениям
траэктории полета летательного аппарата в рассматриваемом режиме.
В большинстве случаев проверка стационарности ограничивается анализом средних значений и корреляционных функций процесса. Задача выделения интервала стационарности случайного процесса сводится к проверке гипотезы H 0 : H 0m ∩ H 0σ , где H0m : mi = m j ,
H 0σ : σi = σ j , i ≠ j в независимых сечениях траектории движения в
рассматриваемом режиме полета (см. также раздел 3).
Как правило, из множества статистических критериев проверки
тех или иных гипотез выбираются наиболее мощные несмещенные
рещающие правила фиксированного уровня значимости α, минимизирующие вероятность β ошибки второго рода при фиксированном объеме выборки (или максимизирующие асимптотическую относительную эффективность). Следует отметить, что величина β
существенно зависит от свойств робастности решающих правил к
нарушению принятых допущений.
Алгоритм решающего правила определения интервала стационарности случайного прцесса достаточно простой. Вначале формируется массив измеренных значений определяющего параметра
{zij } , имеющий n реализаций, каждая из которых имеет k независимых временных сечений ( i = 1, n; j = 1, k ). Далее на основе
массива вычисляется некоторая статистика критерия T(k) и сравнивается с критическим значением статистики Tкр (k , α) . Если
T (k ) ≤ Tкр (k , α), то kc = k , если T (k ) > Tкр (k , α), то количество
независимых сечений уменьшается на единицу (k – 1) и процедура
повторяется до тех пор, пока не будет выделен интервал стационар28
ности (в пределе при kc = k = 1 процесс является нестационарным).
Длина интервала стационарности Tc = kc Δ , где Δ — шаг дискретности независимых сечений.
Рассмотренную задачу можно обобщить. Предположим, что имеется матрица, состоящая из n строк и k столбцов с измеренными
значениями определяющего параметра z11 , ..., z1k , ..., zn1 , ..., znk = {zij },
i = 1, n, j = 1, k .
Требуется проверить нулевую гипотезу об отсутствии различия
между столбцами (в нашем случае гипотезы H 0m и H 0σ ). Если гипотеза не отвергается, то можно применить оператор двойного усреднения θ ср (при выполнении условия эргодичности) для получения оценок вероятностных характеристик m∗ = z и s 2 на основе nk
измерений. Эти оценки можно отнести к любому сечению случайного процесса, в частности, к k-му терминальному сечению, соответствующему, например, фазе пролета высоты принятия решения
(ВПР) при автоматическом заходе самолета на посадку или точке
касания при посадке. Это означает, что для оценки точностных характеристик в этой фазе привлекается дополнительная информация
стационарного участка, непосредственно примыкающего к этому
сечению, что, в свою очередь, позволяет увеличить точность получаемых оценок.
Рассмотрим основные критерии стационарности случайных процессов относительно оцениваемых вероятностных характеристик,
которые наиболее часто используются в статистической обработке.
В общем случае критерии для проверки статистических гипотез
можно разделить на два основных класса:
• критерии, у которых распределение статистик (в условиях справедливости нулевой гипотезы) зависит от распределений, порождающих выборки (так называемые параметрические критерии);
• критерии, свободные от распределения, т.е. критерии, у которых распределение статистик не зависит от порождающих распределений (непараметрические критерии).
2.2.1. Критерии стационарности относительно
среднего значения и параметра положения
Как уже отмечалось, отклонение распределения случайного процесса от нормального приводит к отклонению фактических вероят29
ностей ошибочных решений α и β от установленных значений и,
вследствие этого, к снижению достоверности анализа. Поэтому при
отклонении распределения f(z) анализируемого процесса от нормального N(m, σ) используются свободные от распределения критерии, робастные относительно их фактического уровня значимости при нарушении этих условий.
Свободные от распределения критерии могут применяться к последовательности выборочных средних z j процесса, либо к исходной выборке измеренных ординат {zij }, i = 1, n, j = 1, k . Критерии
первого типа представляют собой одновыборочные критерии однородности, единственным условием применения которых является
независимость сравниваемых оценок. Поскольку истинные значения параметров положения и масштаба случайного процесса неизвестны, для построения решающего правила привлекаются критерии, не требующие численных значений этих параметров. Эти критерии позволяют выполнять независимую проверку H 0m и H 0σ и
допускают достаточно общие альтернативы в отклонении законов
распределений сравниваемых временных сечений случайного процесса.
Критерии второго типа обычно строгие и при малом числе
сравниваемых сечений (коротких реализаций) обеспечивают большую мощность. Однако, помимо независимости ординат случайного процесса они предполагают примерно постоянный вид одномерных распределений случайного процесса в сравниваемых сечениях.
Статистики основных критериев и их свойства представлены в
табл. 2.1.
Наиболее эффективным параметрическим критерием при нормальном законе распределения ординат случайного процесса является критерий Фишера-Снедекора, наблюденное значение статистики которого определяется дисперсионным отношением,
F=
s12
,
s22
которое составляется так, чтобы, s12 ≥ s22 , т.е. F ≥ 1. Сравниваются
значения межгрупповой дисперсии
sм2 =
(
)
2
1 k
zj −z
∑
k − 1 j =1
30
и среднее значение внутригрупповых оценок дисперсий
sв2 =
(
n k
1 k 2
1
∑ sj =
∑ ∑ zij − z j
k j =1
k (n − 1) i =1 j =1
)
2
.
Таблица 2.1
Критерий
Статистика
(
Критерий
Фишера —
Снедекора
)
2
1 k
n Zj −Z
∑
k − 1 j =1
F=
n k
2
1
zij − Z j
∑∑
k (n − 1) i =1 j =1
1 k
1 n
Z = ∑ Z j , Z j = ∑ zij
k j =1
n i =1
k −1
Критерий
инверсий
Решение
k
T (k ) = ∑
∑
(
)
(
)
u Z j, Z p
j =1 p = j +1
⎪⎧1, Z j > Z p
u Z j, Z p = ⎨
⎪⎩0, Z j ≤ Z p
(
)
R (n1 , n2 ) =
T
1−
α
2
(k ) < T (k ) ≤
≤ Tα ( k )
2
∑ серий в {Z j },
j =1, k
1
⎡ Z ( q ) + Z ( q +1) ⎤ , k + 2q
⎦
2⎣
1
med = Z ( q +1) , k + 2q + 1
2
Критерий
серий
med =
Критерий
Рамачандрана
H = ∑ N p2
N p — число серий длины p
Критерий
КраскелаУоллиса
F ≤ F1−α ( p, q )
p = k − 1,
q = k (n − 1)
k R2 ⎤
⎡
12
j
H =⎢
∑ ⎥ − 3(kn + 1)
⎢⎣ kn(kn + 1) j =1 n ⎥⎦
n
R j = ∑ rij
qα (n1 , n2 ) < R <
< Gα (n1 , n2 )
H < Hα
H ≥ h (α , k , n )
H ≤ χ α2 (k − 1)
для n ≥ 5, k ≥ 4
i =1
Критерий
Фридмана
k R2 ⎤
⎡
12
j
S=⎢
⎥ − 3(kn + 1)
∑
⎣⎢ kn(kn + 1) j =1 n ⎦⎥
n
R j = ∑ rij
i =1
31
s ≤ F1− α ( p, qr ),
p = k − 1, q = k − 1
r = n −1
s ≤ χ α2 (k − 1), n ≥ 10
Статистика критерия имеет распределение Фишера с (k – 1) и
k(n – 1) степенями свободы. Гипотеза стационарности выделенного
интервала не отвергается, если наблюденное значение статистики F
не попадает в критическую область, т.е.,
F ≤ F1− α [k − 1, k (n − 1)],
где F1− α — квантиль распределения Фишера [14].
Необходимо отметить, что в современном программном обеспечении компьютерных систем обработки статистической информации имеются соответствующие программные комплексы прикладной математической статистики, позволяющие получать необходимую количественную информацию о любом вероятностном распределении, которая имеется в справочниках и таблицах математической статистики
Очевидно, что гипотеза о стационарности выделенного интервала существенно зависит от принятого уровня значимости. Заметим, что значения α = 0,05; 0,01 и 0,001 соответствуют классификации явлений на редкие, очень редкие и чрезвычайно редкие, т.е.
уровень значимости характеризует меру риска или степень уверенности, с которой делается заключение о стационарности.
Необходимо отметить отличия вероятностной логики принятия
или отклонения гипотезы от обычных логических выводов. Если
F > Fα , то гипотеза H 0 считается опровергнутой, но это не равносильно ее логическому опровержению. Даже если гипотеза H 0
верна, то событие F > Fα может произойти, хотя и с малой вероятностью α. При однократной проверке гипотезы H 0 такая возможность на практике исключается, однако при многократной проверке
гипотезы на различных выборках рано или поздно получают отклонение гипотезы (хотя она и верна).
С другой стороны, получение одного значения F < Fα не является доказательством правильности гипотезы H 0 . Это лишь показывает, что в отношении данного критерия совпадение данных и
сделанных предположений удовлетворительное. Для практического обоснования гипотезы ее следует исследовать более тщательно,
с помощью других критериев.
Справедливость статистических выводов на основе критерия
Фишера–Снедекора зависит от равенства дисперсий в сечениях
случайного процесса ( σ 2j = σi2 ; i, j = 1, k , i ≠ j ). Поэтому приме32
нению F — критерия обязательно предшествует проверка гипотезы H 0σ .
Далее рассмотрим непараметрические критерии, не требующие
знания выборочных распределений.
Пусть в ряду выборочных средних z j , j = 1, k определяется общее число инверсий Т. Если за некоторым выборочным значением
z j следует меньшее по величине z j +1 , то имеет место инверсия.
Наблюденное значение статистики критерия инверсий определяется суммой числа инверсий:
k −1
k
(
)
T (k ) = ∑ ∑ u z j , z p ,
j =1 p = j +1
⎪⎧1, z j > z p
u z j,zp = ⎨
⎪⎩0, z j ≤ z p
где k — как и ранее, число независимых сечений выбранного интервала случайного процесса. Например, в ряду {z j } = 4,6; 4,5; 4,8;
4,3; 4,0; 4,7 T (k ) = 9 .
Статистика критерия Т(k) имеет среднее значение и дисперсию
соответственно:
(
M (T ) =
)
k (k − 1)
,
4
D (T ) =
2k 3 + 3k 2 − 5k
.
72
В [52] приводятся значения квантилей распределения Т(k).
Область принятия гипотезы стационарности выделенного интервала определяется неравенством
T
1−
α
2
(k ) < T ( k ) ≤ Tα (k )
2
с уровнем значимости α.
Критерий серий основан на анализе числа серий R в последовательности и позволяет определить являются ли изменения средних
случайными или имеется некоторый тренд. Если изменения случайные, то гипотеза стационарности не отвергается. После расчета
выборочной медианы z0 в ряду {z j } определяется последовательность серий так, что при z j ≥ z0 ставится символ «+», а при z j < z0
ставится символ «−». Серия представляет собой последователь33
ность одинаковых символов. Например в ряду {z j } = 4,6; 4,5; 4,8;
4,3; 4,0; 4,7 наблюдается последовательность + — + — — +, так
что число серий равно 5.
При отсутствии тренда серия из большого числа одинаковых
символов не должна наблюдаться. Число серий является случайной величиной со средним значением и дисперсией соответственно
M [ R] =
2n1n2
2n n (2n n − n)
+ 1, D[ R] = 1 2 2 1 2
,
n
n (n − 1)
где n1 — число символов со знаком «+», n2 — число символов со
знаком «–», n = n1 + n2 .
Область принятия гипотезы определяется неравенством
g α (n1n2 ) < R < Gα (n1n2 ),
где нижнее g α и верхнее Gα критические значения для количества
серий R, соответствующие уровню значимости α. Значения g α и
Gα приведены в [14].
Критерий Рамачандрана [72] является более мощным, так как
учитывает кроме числа и длину серий. Статистика критерия задается выражением
H = ∑ N p2 ,
p
где N p — число серий длины р, р — длина серии.
Для рассмотренного выше ряда {z j } наблюденная статистика
равна H = 4 ⋅ 12 + 1 ⋅ 22 = 8. .
Квантили распределения P{H > H α } = α для различных объемов
k
наблюдений n = и уровней значимости α приведены в [52].
2
Рассмотрим непараметрические методы, основанные на вариационном ряде, который получается, если члены исходного ряда
расположить в порядке возрастания: z (1) ≤ z (2) ≤ ... ≤ z ( k ) . Такие методы часто называют ранговыми. В общем случае ранговые критерии основаны на использовании номеров наблюдений в вариационном ряду после упорядочивания объединенной выборки объема
34
k
N = ∑ n j . Номер, который получает наблюдение zij в упорядоченj =1
ной выборке, называется его рангом и обозначается через rij .
Вследствие высокой асимптотической эффективности для различных семейств распределений при анализе стационарности эргодических относительно среднего случайных процессов рекомендуется применять критерий Краскера–Уоллиса. Общий вид статистики дается соотношением:
2
k R ⎤
⎡ 12
j
H =⎢
∑ ⎥ − 3(kn + 1),
⎢⎣ kn(kn + 1) j =1 n ⎥⎦
n
R j = ∑ rij ,
i =1
где R j — сумма рангов j-го сечения.
Решающее правило на уровне значимости α имеет вид
H ≥ h(α, k , (n1 , ..., nk )),
т.е., если неравенство выполняется, то гипотеза H 0m не отвергается.
Критические значения статистики определяются из таблиц [35].
При n ≥ 5 и k ≥ 4 статистика Н имеет асимптотическое χ 2 -распределение с k-1 степенями свободы [14]. Приближенный критерий
уровня α в этом случае имеет вид
H < χ α2 (k − 1)
для принятия гипотезы H 0m . .
Пример 2.1. В пяти реализациях испытательного полета выделены четыре сечения с шагом Δt для некоторого определяющего
параметра. Требуется проверить гипотезу стационарности выделенного участка траектории.
Выборочные данные:
5,1
4,8
5,3
5,0
4,7
4,8
5,2
4,6
4,9
5,1
4,7
5,1
5,0
4,6
4,8
5,2
4,8
4,9
4,7
5,1
Для того, чтобы применить рассмотренный критерий, рекомендуется следующая процедура.
35
Каждому значению приписывается ранг согласно месту, занимаемому этим элементом в вариационном ряду. В случае совпадения выборочных величин рекомендуется приписать каждому члену
группы совпадающих величин среднее значение рангов совпадающих членов.
Для рассматриваемого примера:
5,1 (15,5)
4,8 (7,5)
5,3 (20)
5,0 (12,5)
4,7 (4)
4,8 (7,5)
5,2 (18,5)
4,6 (1,5)
4,9 (10,5)
5,1 (15,5)
4,7 (4)
5,1 (15,5)
5,0 (12,5)
4,6(1,5)
4,8(7,5)
5,2 (18,5)
4,8 (7,5)
4,9 (10,5)
4,7 (4)
5,1(15,5)
Таким образом, сумма рангов в сечениях процесса: R1 = 59,5;
R2 = 53,5; R3 = 41; R4 = 56.
Статистика критерия:
H=
12 11219,5
⋅
− 63 = 1,11.
20 ⋅ 21
5
Для критического значения на уровне значимости α = 0,05
χ (3) = 7,81 гипотеза стационарности выделенного участка не отвергается, так как
2
0,05
2
H = 1,11 < χ 0,05
(3) = 7,81.
Многообразие ранговых процедур порождается множеством способов ранжирования измеренных значений ординат zij случайного
процесса и типов функционального преобразования рангов, используемых при построении статистики критерия. Существенно,
что тип оптимального функционального преобразования, лежащего
в основе статистического критерия, определяется видом семейства
одномерных распределений f(z) случайного процесса. В ситуации,
когда вид семейства f(z) известен, становится возможным найти
оптимальный асимптотически наиболее мощный свободный от
распределения критерий. Это обстоятельство обусловливает целесообразность параллельного использования нескольких критериев
проверки гипотез, а также оценки вида распределения определяющих параметров движения летального аппарата.
Рассмотрим непараметрический критерий Фридмана, допускающий некоторое изменение законов распределения наблюдаемых
36
параметров в отдельных реализациях случайного процесса, а также
статистическую зависимость последних. В отличии от статистики
Краскела–Уоллиса ранжирование осуществляется в каждой реализации процесса в отдельности. При небольших объемах выборки критерий Фридмана имеет достаточно высокую эффективность.
Статистика критерия дается выражением [35]:
k
⎡ 12
2⎤
S=⎢
∑ R j ⎥ − 3n(k + 1),
⎣ nk (k + 1) j =1 ⎦
k
R j = ∑ rij .
i =1
Решающее правило критерия Фридмана для гипотезы H 0m имеет вид
S ≤ F1− α (k − 1, (k − 1)( n − 1)) ,
где F1−α (•) — квантиль F-распределения уровня 1-α с соответствующими степенями свободы.
Если гипотеза H 0m верна, то статистика S имеет асимптотическое (при n ≥ 10 ) распределение χ 2 с (k – 1) степенями свободы [73].
Критерий с приближенным уровнем значимости имеет вид:
S < χ α2 (k − 1).
Пример 2.2. Для рассмотренных в предыдущем примере выборочных данных в соответствии с критерием Фридмана проводим
ранжирование (в пределах каждой строки):
5,1(3)
4,8(1,5)
5,3(4)
5,0(4)
4,7(1)
4,8(2)
5,2(4)
4,6(1)
4,9(3)
5,1(3,5)
4,7(1)
5,1(3)
5,0(3)
4,6(1)
4,8(2)
5,2(4)
4,8(1,5)
4,9(2)
4,7(2)
5,1(3,5)
так что сумма рангов в каждом сечении процесса равна соответственно: R1 = 13,5; R2 = 13,3; R3 = 10; R4 = 13,0 .
Наблюденное значение статистики критерия Фридмана:
12
S=
(13,32 + 13,52 + 102 + 132 ) − 3 ⋅ 5 ⋅ 5 = 1,02
20 ⋅ 5
и гипотеза стационарности выделенного интервала не отвергается
(1,02 < 7,81).
37
2.2.2. Критерии стационарности относительно
параметров рассеяния и дисперсии
Статистики основных параметрических и непараметрических
критериев и их свойства представлены в табл.2.2.
Таблица 2.2
Критерий
Статистика
Критерий
Хартли
H=
2
s max
2
s min
k
1⎡
2
2⎤
⎢( n − 1) k ln s − ( n − 1) ∑ ln s j ⎥ ,
C⎣
j =1
⎦
1 ⎡ k
1 ⎤
C = 1+
−
⎢
⎥,
3(k − 1) ⎣ n − 1 (n − 1)k ⎦
2
1 n
1 k
s 2j =
zij − z j , s 2 = ∑ s 2j
∑
n − 1 i =1
k j =1
Решение
H < H α (n − 1, k )
B=
Критерий
Бартлетта
(
B ≤ χα2 (k − 1)
)
max s 2j
Критерий
Кочрена
G=
j
k
∑ s 2j
G ≤ Gα (n − 1, k )
j =1
Критерий
Левене
k D2 ⎤
⎡
12
j
L=⎢
⎥ − 3(nk + 1)
∑
⎢⎣ nk ( nk + 1) j =1 n ⎥⎦
n
D j = ∑ rij
i =1
Критерий
СиджелаТьюки
k C2 ⎤
⎡
12
j
S=⎢
∑ ⎥ − 3(nk + 1)
⎢⎣ nk ( nk + 1) j =1 n ⎥⎦
n
C j = ∑ rij
i =1
L ≤ S α ( n, k )
L ≤ χ α2 (k − 1)
для
n ≥ 5, k ≥ 4
S ≤ S α ( n, k )
S ≤ χ α2 (k − 1)
для
n ≥ 5, k ≥ 4
k
R (n1 , n2 ) = ∑ серий в ряду
j =1
Критерий
серий
при
1
⎡ z( q ) + z( q +1) ⎤⎦ , nk = 2q
2⎣
1
med = z( q +1) , nk = 2q + 1
2
med =
38
g α (n1 , n2 ) < R <
< Gα (n1 , n2 )
Основными параметрическими критериями проверки гипотезы
H 0σ являются критерии Хартли, Кочрена и Бартлетта [14, 16], использующие схему дисперсионного анализа без взаимодействий.
Наиболее простым критерием проверки H 0σ является критерий
2
и миниХартли, основанный на сопоставлении максимальной smax
2
мальной smin выборочных дисперсий:
H=
2
smax
.
2
smin
Гипотеза о стационарности процесса H 0σ по отношению к дисперсии не отвергается если
H < H α (n − 1, k ).
Значения H α для α = 0,05 и 0,01 приведены в [19, 22] для рядов
измерений одинакового объема.
Пример 2.3. Для исходных данных рассмотренного выше при2
2
мера имеем максимальную smax
= 0,057 и минимальную smin
= 0,043
дисперсии в сечениях случайного процесса, так что наблюденная
статистика критерия Хартли равна H = 1,325, а критическое значение статистики на уровне значимости α = 0,05 равно H α (4, 4) = 19, 2,
т.е. H < H кр и гипотеза равенства дисперсий во всех сечениях случайного процесса не отклоняется.
Критерий Хартли является наиболее простым и менее чувствительным для проверки гипотезы H 0σ , так как не учитывает информацию, которая содержится в других дисперсиях.
Более эффективным является критерий Бартлетта, для которого
статистика имеет вид:
k
s 2j
BR = −(n − 1) ∑ ln 2 ,
s
j =1
где
k
(
)
∑ sj
2
1
2
s =
∑ zij − z j , s = i =1 .
n − 1 i =1
k
2
j
n
2
Статистика BR приближенно распределена как случайная величина χ 2 (k − 1).
39
Лучшей аппроксимацией к χ 2 — распределению с k − 1 степенями свободы имеет статистика
k
1⎡
⎤
B = ⎢ (n − 1)k ln s 2 − (n − 1) ∑ s 2j ⎥ ,
C⎣
j =1
⎦
1 ⎡ k
1 ⎤
.
−
C =1+
⎢
3(k − 1) ⎣ n − 1 ( n − 1)k ⎥⎦
Критерий, основанный на этой статистике, и называется критерием Бартлетта (при одинаковых объемах измерений в сравниваемых сечениях).
Нулевая гипотеза H 0σ не отвергается, если выполняется неравенство B ≤ χ α2 (k − 1).
Пример 2.4. Для исходных даннях расмотренного выше примера
рассчитываем несмещенные оценки дисперсий в каждом сечении:
s12 = 0,057; s22 = 0,057; s32 = 0,043; s42 = 0,043
и среднюю дисперсию
∑sj
2
s =
2
4
Наблюденное значение статистики
B=
= 0,05.
4 ⋅ 4(−2,9957) + 4 ⋅ 12,022
= 0,142.
1,104
Так как при нулевой гипотезе H 0σ статистика Бартлетта имеет
2
хи-квадрат распределение с 3 степенями свободы χ 0,05
(3) = 7,81, то
сравнивая, получаем
2
B < χ 0,05
(3),
так что с 5% уровнем значимости гипотеза о равенстве дисперсий
не отклоняется.
Следует отметить, что критерий Бартлетта очень чувствителен к
отклонениям от предположения о нормальности наблюдений. Было
показано, что если значение статистики критерия лежит в критическом множестве, то это могло произойти с одинаковым успехом
как от нарушения предположения о нормальности, так и от того,
что дисперсии различны. Кроме того критерий достаточно эффективен в случае kn ≥ 100.
40
Поскольку распределение статистики критерия Бартлетта известно лишь приближенно, то для обеспечения заданного уровня
значимости решающего правила предпочтительнее использовать
критерий Кочрена (возможно параллельное использование), распределение статистики которого известно точно.
Статистика критерия имеет вид
G=
max s 2j
j
k
∑ s 2j
.
j =1
Гипотеза о равенстве дисперсий не отвергается если
G ≤ Gα (n − 1, k ),
где Gα (•) — критическое значение статистики, представляющее
собой квантиль уровня α распределения Кочрена с (n – 1) и k степенями свободы. Значения статистики Gα (•) приведены в [14].
Строгие решающие правила анализа стационарности случайного процесса относительно меры рассеяния для произвольного семейства распределений ординат случайного процесса основаны на
применении свободных от распределения критериев рангового типа к выборке {zij } . Основными из них являются многовыборочные
процедуры Левене [81] и Сиджела-Тьюки [83], реализованные на
основе критерия Краскела-Уоллиса. При этом для первого критеn
рия определяется сумма рангов D j = ∑ rij по выборке абсолютных
i =1
значений zij − z j , а для второго критерия определяется сумма ранn
гов C j = ∑ rij по упорядоченной последовательности вида
i =1
z(1) z( N ) z( N −1) z(2) z(3) z( N − 2) z( N −3) z(4) z(5) ...,
k
где N = ∑ n j (при равных объемах N = nk).
j =1
Статистики критериев соответственно равны:
k 1
⎡
⎤
12
L=⎢
∑ D 2j ⎥ − 3(nk + 1),
⎣ nk (nk + 1) j =1 n ⎦
41
k 1
⎡
12
2⎤
S=⎢
∑ C j ⎥ − 3(nk + 1).
⎣ nk (nk + 1) j =1 n ⎦
Решающее правило критериев для нулевой гипотезы имеет вид
L ≤ Lα (n, k ),
S ≤ S α (n, k ),
где Lα (•) и Sα (•) — критические значения соответствующих статистик. При n ≥ 5 и k ≥ 5
Lα (•) = Sα (•) = χ α2 (k − 1).
Пример 2.5. В пяти реализациях автоматического захода на посадку (Рис.2.4) получены значения определяющего параметра в четырех временных сечениях, непосредственно примыкающих к фазе
пролета высоты принятия решения:
10,5
6,8
9,3
5,4
11,6
7,2
6,8
7,0
7,5
6,9
7,6
7,1
7,3
8,0
7,2
6,9
7,4
7,0
7,5
7,2
Требуется проверить нулевую гипотезу о равенстве дисперсий в
указанных сечениях критериями Левене и Сиджела-Тьюки.
z(t)
t
t4
t3
t2
t1
ВПР
Рис. 2.4. Реализации определяющего параметра
Критерий Левене. Рассчитываются оценки математических ожиданий в сечениях случайного процесса:
z1 = 8,72; z 2 = 7,08; z 3 = 7, 44; z 4 = 7, 2.
42
Тогда абсолютные разности zij − z j равны:
1,78(17)
1,92(18)
0,58(16)
3,32(20)
2,88 (19)
0,12(3)
0,28(10)
0,08(2)
0,42(14)
0,18(6)
0,16(5)
0,34(13)
0,14(4)
0,56(15)
0,24(9)
0,3(11,5)
0,2(7,5)
0,2(7,5)
0,3(11,5)
0(1)
Проводя ранжирование полученных данных (номера рангов элементов указаны в скобках) определяем суммы рангов в сечениях
процесса:
D = 90, D = 35, D = 46, D = 39.
Наблюденное значение статистики равно: L = 11,07.
В соответствии с решающим правилом, определяем квантиль
2
χ 2 -распределения на уровне значимости α = 0,05 как χ 0,05
(3) = 7,81.
2
(3), то гипотеза о равенстве дисперсий отклоняется.
Так как L > χ 0,05
Критерий Сиджела-Тьюкси. В соответствии с критерием упорядоченная последовательность имеет вид:
5,4
7,5
11,6 10,5 6,8
7,0 7,0 7,5
6,8
7,4
9,3
7,1
8,0
7,2
6,9
7,3
6,9
7,2
7,6
7,2
Тогда номера рангов в каждом сечении равны соответственно:
3
4,5
6
1
2
17
4,5
12,5
14
8,5
10
16
18
7
19,5
8,5
15
12,5
14
18,5
что позволяет определить соответствующие суммы рангов:
C = 16,5 С = 56,5 С = 70,5 С = 68,5
Наблюденное значение статистики равно: S = 12,01.
В соответствии с решающим правилом гипотеза H 0 принимает2
ся если S ≤ χ α2 (k − 1). В нашем случае S > χ 0,05
(3) = 7,81 и гипотеза
о равенстве дисперсий отклоняется.
Следует отметить, что рассмотренные критерии Левене и Сиджела-Тьюки предполагают равенство параметров положения сравниваемых сечений при справедливости нулевой гипотезы. Нарушение этого допущения приводит к увеличению вероятности ошибки
43
второго рода в критерии Сиджела-Тьюки и завышению фактического уровня значимости в критерии Левене.
Для сравнения нескольких дисперсий могут быть использованы
непараметрические критерии, рассмотренные выше при сравнении
средних. Методика применения этих критериев полностью аналогична. При этом критерии могут быть применены как для исследуемой исходной выборки, так и для исследования выборочных
средних и дисперсий. Так как трудоемкость вычислений при применении этих критериев резко возрастает с увеличением объема
выборки, то для оценки стационарности, как правило, используют
выборки, составленные из оценок математических ожиданий и
дисперсий.
Пример 2.6. Для исходных данных предыдущего примера проверить гипотезу стационарности выделенного участка случайного
процесса критерием серий:
10,5(+)
6,8(−)
9,3(+)
5,4(−)
11,6(+)
7,2(−)
6,8(−)
7,0(−)
7,5(+)
6,9(−)
7,6(+)
7,1(−)
7,3(+)
8,0(+)
7,2(−)
6,9(−)
7,4(+)
7,0(−)
7,5(+)
7,2(−)
Расположив измеренные значения последовательно сечение за
сечением (четыре сечения в пяти реализациях) получаем выборку
из 20 значений, для которой применяем критерий.
После расчета выборочной медианы
1
med = ⎡⎣ z( q ) + z( q +1) ⎤⎦ , nk = 2q,
2
med = 7, 2,
определяется последовательность знаков («+» при zi > med , «−»
при zi ≤ med , i = 1, 20 ) и количество серий, равное R = 16.
Для количества плюсов n1 = 9, минусов n2 = 11 и серий R = 16
определяем нижнее g α (n1 , n2 ) и верхнее Gα ( n1 , n2 ) критические значения числа серий для уровня значимости α = 0,05 из таблицы [14]:
g α (9,11) = 6,
Gα (9,11) = 16.
В соответствии с решающим правилом если число серий R
удовлетворяет неравенству g α (n1 , n2 ) < R < Gα (n1 , n2 ) , то нет ос44
нований утверждать, что R противоречит нулевой гипотезе H 0 .
В нашем случае R = 16 = G0,05 (9,11) , что заставляет отвергнуть
гипотезу H 0 .
Очевидно, что такой вывод нельзя считать очень надежным, так
как если бы уровень значимости равнялся бы 0,01, то гипотеза стационарности не отвергалась бы ( G0,01 (9,11) = 17 ).
2.2.3. Критерии независимости
Вопрос о независимости измеренных значений H 0 : F1 ( z ) =
F2 ( z ) = ... = FL ( z ) = F ( z ) случайного процесса является очень важным и от его решения зависит эффективность и надежность статистической обработки. Поэтому, перед тем как подвергнуть результаты измерений соответствующей статистической обработке, необходимо убедиться в том, что они действительно образуют случайную выборку и являются стохастически независимыми.
Решение этой задачи осуществляется, как правило, параллельно
непараметрическими и параметрическими методами с целью получения более надежных статистических выводов.
В качестве непараметрического критерия можно использовать
рассмотренный выше критерий серий. Полученная после применения критерия последовательность плюсов и минусов характеризируется общим числом серий R(N), N = kn и протяженностью самой
длинной серии τ(N). Очевидно, что если измерения стохастически
независимы, то чередование плюсов и минусов в последовательности должно быть более или менее случайным, т.е. такая последовательность не должна содержать слишком длинных серий, и соответственно общее число серий R(N) не должно быть слишком
малым. Так что в данном критерии целесообразно рассматривать
одновременно пару критических статистик {R(N), τ(N)}.
В [9] предлагается приближенный критерий, основанный на нормальном приближении распределения случайной величины R(N) с
⎪⎧ N + 2 N − 1 ⎪⎫
,
параметрами ⎨
⎬ и пуассоновским распределением (с
2 ⎪⎭
⎪⎩ 2
Nτ
параметром λ = 0 + 1 ) числа серий с длиной, большей или рав2
45
ной τ 0 . Решающее правило для 5% уровня значимости состоит из
двух неравенств:
(
)
1
⎧
⎪ R ( N ) > N + 1 − 1,96 N − 1 ,
⎨
2
⎪⎩ τ( N ) < 3,3lg( N + 1).
Если хотя бы одно из неравенств окажется нарушенным, то гипотеза о стохастической независимости результатов измерения отвергается с вероятностью ошибки 0,05 < α < 0,0975.
Пример 2.7. Для выборки измерений {zij } из предыдущего примера было получено, что R(20) = 16, τ(20) = 3 для N = 20.
Тогда при α = 0,05 имеем:
(
)
⎧1
⎪ N + 1 − 1,96 N − 1 = 6, 2,
⎨2
⎩⎪3,3lg( N + 1) = 4, 4,
⇒
{
16 > 6,2,
3 < 4,4,
и, следовательно, гипотеза о стохастической независимости массива
измерений {zij } не отвергается.
В [9] предлагается критерий серий, позволяющий «улавливать»
постепенное смещение среднего значения в исследуемом распределении не только монотонного, но и периодического характера.
Правило образования последовательности плюсов и минусов такое:
на i-ом месте последовательности ставится плюс, если zi +1 − zi > 0,
и минус, если zi +1 − zi < 0 (если два или несколько следующих друг
за другом выборочных значений равны между собой, то принимается во внимание только одно из них). Очевидно, что последовательность подряд идущих плюсов будет соответствовать возрастанию результатов измерения, а последовательность минусов — их
убыванию. Критерий основан на тех же соображениях, что и рассмотренный выше.
Решающее правило критерия для уровня α = 0,05 записывается
в виде:
⎧
1
16 N − 29
⎪ R ( N ) > (2 N − 1) − 1,96
,
⎨
3
90
⎪⎩ τ( N ) < τ 0 ( N ),
где τ 0 ( N ) определяется следующим образом:
46
N
N ≤ 26
26 < N ≤ 153
153 < N ≤ 1170
τ0 ( N )
5
6
7
Если хотя бы одно из неравенств окажется нарушенным, то гипотезу о случайности выборки следует отвергнуть.
Пример 2.8. Для выборки измерений в примере 2.6 получаем,
что R = 15, τ(N) = 2. Тогда в соответствии с критерием:
⎧1
16 N − 29
⎪ (2 N − 1) − 1,96
= 9,5 → 15 > 9,5
⎨3
90
⎪⎩ τ 0 ( N ) = 5
→ 2<5
и, следовательно, гипотеза о независимости элементов выборки не
отвергается.
Одним из наиболее простых параметрических критериев проверки независимости результатов измерений является критерий
Аббе [14] (критерий квадратов последовательных разностей).
Статистика критерия записывается в виде:
N −1
( zi +1 − zi ) 2
1 i∑
q = =1N
,
2 ∑ ( z − z )2
i
где
i =1
z=
1 N
∑ zi .
N i =1
Решающее правило критерия:
q < qN (α),
где qN (α) — критическое значение статистики, определяемое при
N > 60 как
uα
qN (α) = 1 +
,
N + 0,5(1 + uα2 )
где uα — квантиль нормированного нормального распределения
уровня α.
Если неравенство выполняется, то гипотеза о стохастической
независимости результатов измерений отвергается.
47
Значения q N (α) для N ≤ 60 и различных уровней значимости
приведены в [14] .
Пример 2.9. Для исходных дынных примера 2.6 рассчитываем
квадраты соответствующих разностей:
∑ ( zi +1 − zi ) = 96,51; ∑ ( zi − z ) = 34,92 ,
19
20
2
i =1
2
i =1
так что наблюденное значение статистики равно q = 1,38, а критическое значение равно q20 (0,05) = 0,65. Так как q > q20 (0,05), то
гипотеза о стохастической независимости результатов измерений
не отвергается на уровне значимости α = 0,05.
Перейдем теперь к вопросу об определении слабо коррелированных сечений в реализациях случайного процесса, по которым
определяются оценки вероятностных характеристик. В расчетах
таких оценок широко используется понятия интервала корреляции,
под которым понимается интервал времени, определяемый соотношением [58]
∞
τ к = ∫ Rz (τ)dτ ,
0
где Rz (τ) — нормированная корреляционная функция случайного
процесса Z(t).
Величина τ к указывает, на каком временном интервале в среднем имеет место корреляция между измеренными значениями случайного процесса. Так как при проверке различных статистических
гипотез элементы выборки должны быть независимыми, то необходимо оценивать степень коррелированности результатов измерений во временных сечениях случайного процесса.
Простейшей характеристикой связи случайных величин ξ1 и ξ 2
является коэффициент корреляции, определяемый выражением:
r=
M ⎡⎣( ξ1 − m1 )( ξ 2 − m2 ) ⎤⎦
σ1σ 2
где m1 = M [ξ1 ], m2 = M [ξ 2 ], σ12 = D[ξ1 ], σ 22 = D[ξ 2 ] .
Для независимых величин ξ1 и ξ 2 коэффициент корреляции
равен 0. В общем случае он лежит в пределах −1 ≤ r ≤ 1. При нор48
мальном законе распределения некоррелированность ординат процесса означает их независимость.
Коэффициент корреляции характеризует лишь степень линейной зависимости между ξ1 и ξ 2 . Пусть, например, ξ1 — симметрично распределенная величина с плотностью f ξ ( x) такой, что
f ξ (− x) = f ξ ( x), и пусть ξ 2 = ξ1 .
Тогда, хотя величина ξ 2 и связана жесткой функциональной
зависимостью с ξ1 , коэффициент корреляции величин ξ1 и ξ 2 будет равен 0, поскольку
∞
M {ξ1} = ∫ xf ξ ( x)dx = 0,
−∞
∞
M {ξ1 , ξ 2 } = ∫ x x f ξ ( x)dx = 0.
−∞
Кроме интервала корреляции иногда используют понятие максимального интервала корреляции τ max , указывающего величину
временного интервала, при котором значение ρ z (τ) меньше заданной величины, например, 0,05, т.е. при τ > τ max ординаты случайного процесса практически не коррелированны:
{
}
τ max = min τ τ: ρ∗z (τ) < 0,05 .
τ
В [15] рекомендуется интервал корреляции τ 0 принимать из условия:
{
}
τ 0 = τ: ρ∗z (τ) < 0,3 .
Таким образом, временной интервал, на котором проводится
статистическая обработка результатов измерения случайного процесса, определяется как
T = (k − 1)τ 0 ,
где k — количество слабо коррелированных сечений, при этом отсчет ведется против направления полета от терминального момента
t0 , соответствующего определенной фазе полета (момент пролета
высоты принятия решения, момент отрыва стойки шасси, момент
приземления и т.п.).
Перед тем как определить величину τ 0 (или τ к ) необходимо
провести оценку корреляционной функции на выбранном времен49
ном интервале случайного процесса. Применяя оператор двойного
усреднения (считая процесс стационарным) в дискретной форме,
получаем выражение для оценки корреляционной функции
K ∗ (τ) = K ∗ ( pΔt ) =
1 m − p −1 1 n −1
=
∑
∑ zij − z j zi , j + p − z j + p ,
m − p j =0 n − 1 i =0
(
)(
)
для оценки нормированной корреляционной функции
R∗ ( pΔt ) =
(
)(
)
1 m − p −1 1 n −1 zij − z j zi , j + p − z j + p
,
∑
∑
m − p j =0 n − 1 i =0
s j s j+ p
где Δt — шаг дискретизации случайного процесса.
Очевидно, что точность оценки корреляционной функции зависит от длительности реализаций исследуемого процесса и при
дискретном представлении алгоритма для сохранения одинаковой точности в определении оценки в сравнении с непрерывным
алгоритмом (при одинаковом интервале анализа) шаг временной
дискретизации Δt необходимо выбирать так, чтобы на интервале
корреляции процесса Z (t ) укладывалось 10−20 дискретных отсчетов [30].
Пример 2.10. По шести испытательным полетам (каждый полет
содержал 10 реализаций) были определены оценки нормированных
корреляционных функций угла крена при автоматической посадке
самолета на некотором временном интервале, примыкающем к
точке касания, рис. 2.5.
Критерии проверки однородности результатов шести полетов
показали, что гипотеза однородности подтверждается, т.е. генеральные совокупности, из которых получены выборки, одинаковы
и, значит, им соответствуют одинаковые функции распределения
F(x) = N (m, σ).
Проведя усреднение по всем полетам, получаем оценку нормированной корреляционной функции, аналитическая аппроксимация
которой имеет вид:
R∗ (τ) = e
−α τ
cosβτ = e
50
−0,28 τ
cos 0, 28τ .
R γ*
1
0.8
0.4
0
5
10
15
20
25
τ, c
-0.4
-0.8
Рис. 2.5. Оценки корреляционных функций угла крена
Интервал корреляции определяется в соответствии с выражением:
∞
τк = ∫ e
−α τ
cosβτdτ = 1,8 c.
0
Величина интервала корреляции τ 0 на уровне R∗ (τ 0 ) = 0,3 равна 2,9 с.
При статистической обработке целесообразно проверять гипотезу о значимости коэффициента корреляции соответствующим
критерием. В [16] показывается, что случайная величина (наблюденное значение статистики)
n−2
T =r
1− r2
подчиняется t-распределению Стьюдента с (n-2) степенями свободы при справедливости нулевой гипотезы H 0 : ρ = 0. Здесь ρ — истинное значение коэффициента корреляции, r — выборочный коэффициент корреляции.
Решающее правило для принятия гипотезы H 0 имеет вид:
T ≤ t α (n − 2),
2
51
где t α — критическая точка двусторонней критической области,
2
которая определяется по таблице критических значений распределения Стьюдента [14] при заданном уровне значимости α.
Пример 2.11. По результатам измерений определяющего параметра в сечениях случайного процесса Z(t), отстоящих друг от друга на предполагаемый интервал корреляции τ к , бала получена
оценка коэффициента корреляции r = 0,2.
Требуется проверить нулевую гипотезу H 0 о равенстве нулю
генерального коэффициента корреляции при уровне значимости
α = 0,05. Конкурирующая гипотеза H1 : ρ ≠ 0 . Объем измерений
N = n(k – 1) = 80.
Наблюденное значение статистики критерия равно:
T=
r n−2
1− r2
= 1,8.
Так как критическое значение статистики критерия t α (n − 2) =
2
= 1,99, то нет оснований отвергать нулевую гипотезу, т.е. выборочный коэффициент корреляции незначимо отличается от нуля. Это
означает, что выбранные сечения случайного процесса Z(t) можно
считать слабо коррелированными. Остаточный уровень корреляции
можно учесть в последующей статистической обработке.
2.2.4. Критерии однородности
Как правило, в совокупности L испытательных полетов каждый
полет обрабатывается в отдельности, в результате чего получают L
оценок вероятностных характеристик, если в пределах полета выполняется условие стационарности.
Очевидно, что для повышения точности получаемых оценок
желательно объединить полученные результаты, т.е. выполнить совместную статистическую обработку этих полетов. Однако объединение результатов правомерно и может привести к повышению
точности лишь при определенных условиях, а именно при статистической однородности полетов. В результате проверки однородности полетов могут возникнуть следующие варианты:
• полеты однородны, т.е. при одинаковом рассеянии полетов
различие средних (параметров положения) незначительно;
52
• полеты не равнорассеяны, но различие средних значительно;
• полеты равнорассеяны, но различие средних значительно;
• полеты не равнорассеяны и различие средних значительно.
По первому и второму вариантам для повышения точности
вероятностных характеристик можно объединить все полеты в
один и вычислить по нему общие статистические характеристики; по третьему и четвертому вариантам объединять полеты нецелесообразно, а необходимо исследовать причины расхождений
между ними.
Рассмотрим основные статистические критерии при проверке
гипотез однородности.
Пусть имеется L ≥ 2 независимых выборок, содержащих соответственно n1 , n2 ,..., nL независимых измерений (наблюдений):
{zij }i =1,k
1
j =1, m1
n1 = m1k1
{zij }i =1, k
2
j =1, m2
n2 = m2 k2
... {zij }i =1, k
L
j =1, mL
nL = mL k L
где ki — количество слабо коррелированных сечений в i-м полете,
mi — количество реализаций в i — м полете.
Гипотеза однородности состоит в том, что генеральные совокупности, из которых извлечены выборки, одинаковы и, значит, им
соответствуют одинаковые функции распределения
H 0 : F1 ( z ) = F2 ( z ) = ... = FL ( z ) = F ( z ) ,
где Fi ( z ) — функция распределения i–ой генеральной совокупности.
Для проверки однородности можно использовать критерий χ 2 ,
для чего интервал изменения определяющего параметра по всем
полетам разбивается на r групп.
Пусть для L массивов {zij } объемом ni (i = 1, L) данные каждой
выборки сгруппированы в r групп (интервалов). Количество элементов j-й выборки, попавших в i-й интервал, обозначим через ν ij .
Статистикой критерия является величина [47]:
ν i (⋅) ν (⋅) j ⎞
⎛
⎜ ν ij −
⎟
r L
ν ij2
n ⎠
⎝
2
= n∑ ∑
− 1,
χ = n∑ ∑
ν i ( ⋅) ν ( ⋅) j
i =1 j =1
i =1 j =1 ν i ( ⋅) ν ( ⋅) j
r
L
53
где
L
ν i (⋅) = ∑ ν ij ,
i =1
r
L
j =1
i =1
ν (⋅) j = ∑ ν ij , n = ∑ n i .
В частном случае L = 2 приведенную выше статистику можно
записать в виде
2
⎛ μi νi ⎞
⎜ − ⎟
r
n n2 ⎠
2
χ = n1n2 ∑ ⎝ 1
,
μi + νi
i =1
где μ i , ν i (i = i, r ) — соответственно количество элементов первой и
второй выборок, попавших в i-й интервал.
В случае нулевой гипотезы H 0 величина χ 2 имеет распределения χ 2 с (r – 1)(L – 1) степенями свободы.
Пример 2.12. Применим критерий χ 2 для проверки гипотезы
однородности двух испытательных полетов:
{zij } ← n1 = 100
{zij } ← n2 = 100 ,
где zij — измеренные значения некоторого определяющего параметра.
Диапазон изменений параметра {zmin , zmax } = {−4,6; 4,0} разбит
на 9 интервалов. Здесь zmin , zmax — соответственно наименьшее и
наибольшее значения параметра, определяемые по всем реализациям двух испытательных полетов.
Определив частоты попадания элементов выборки в соответствующие интервалы μ i (для первого полета ) и ν i (для второго полета) находим наблюденное значение статистики критерия χ 2 (см.
таблицу 2.3), равное 10,54.
В соответствии с таблицами процентных точек распределения
2
2
χ с r – 1 = 8 степенями свободы [14], имеем χ 0,05
(8) = 15,507.
Таким образом, гипотеза о равенстве функций распределения не
отвергается при размере критерия 0,05. Одинаковость функций
распределения позволяет объединить обе выборки для дальнейшего статистического анализа.
54
Таблица 2.3
Интервалы
определяющего
параметра
–4,6
–3,7
–2,8
–1,9
–1,0
–0,1
0,8
1,7
2,6
–3,7
–2,8
–1,9
–1,0
–0,1
0,8
1,7
2,6
4,0
1 полет
2 полет
μi
νi
4
4
15
45
20
6
3
3
—
1
2
8
41
27
10
4
4
3
μi + νi
μi − νi
5
6
23
86
47
16
7
7
3
3
2
7
4
–7
–4
–1
–1
–3
Рассмотрим некоторые ранговые критерии проверки гипотезы
H 0 для L > 2 выборок. В этом случае вся объединенная выборка
L
объемом n1 + n2 + ... + nL = ∑ n j = N упорядочивается, и наблюдеj =1
ниям присваиваются ранги, соответствующие их положению в этой
выборке.
Как и ранее будем рассматривать так называемые линейные
ранговые критерии, статистики которых имеют вид:
nj
S j = ∑ Ri , N ,
i =1
где суммирование распространяется по элементам соответствующей выборки.
Предлагаемые ниже критерии состоятельны при проверке гипотезы неоднородности, когда неоднородность порождается различием в параметре положения (например, средних значений, медиан)
распределений. Например, для случая двух выборок альтернативные гипотезы можно записать в виде:
H1 : F1 ( x) = F2 ( x − μ), μ ≠ 0,
для которой распределения сдвинуты относительно друг друга;
H1 = F1 ( x) = F2 ( x − μ), μ > 0,
для которой второе распределение сдвинуто влево по отношению к
первому;
H1 = F1 ( x) = F2 ( x − μ), μ < 0,
55
для которой второе распределение сдвинуто вправо по отношению
к первому.
Здесь нулевая гипотеза (равенства распределений) может быть
записана как H 0 : μ = 0.
В общем случае при гипотезе H 0 все функции распределения
равны некоторой одной и той же произвольной функции. Альтернативы различий в сдвиге, против которых предназначены следующие ниже критерии, могут быть выражены как Fj ( x) = F ( x − Δ j ),
j = 1, L , где параметры Δ j неизвестны и не все равны между собой. Критерии обладают только односторонними критическими
областями, т.е. если статистика критерия, вычисленная по экспериментальным данным, больше, чем соответствующее критическое
значение, то H 0 отвергается в пользу альтернативы.
Таким образом, для каждого из L распределений вычисляется
величина S j ( j = 1, L) . Каждая из величин S j имеет асимптотически нормальное распределение [22]. Так как полная сумма
N
S0 = ∑ Si известна, т.е. между ними существует одна линейная
i =1
связь, то случайная величина
L
H =∑
( Si − M [ Si ])
2
D[ Si ]
в случае истинности нулевой гипотезы имеет χ 2 — распределение с
L — 1 степенями свободы. В частности, используя в качестве Si
сумму рангов, приходим к рассмотренному ранее критерию Краскела–Уоллиса [22]:
i =1
H=
2
2
L 1 ⎡ L
L S ⎤
N + 1 ⎤ ⎡ 12
12
j
S
n
−
=
∑ ⎢∑ j
∑ ⎥ − 3( N + 1),
⎢
j
⎥
N ( N + 1) j =1 n j ⎣ j =1
2 ⎦ ⎢⎣ N ( N + 1) j =1 n j ⎥⎦
nj
S j = ∑ rij ,
i =1
где S j — сумма рангов для наблюдений из j-й выборки в объединенной выборке.
Пример 2.13. Проверить гипотезу однородности двух испытательных полетов:
56
2,8 (89,5)
0,5 (60)
–3,6 (3,5)
–1,2 (37,5)
3,8 (99)
2,1 (81)
–1,4 (35)
–3,2 (7,5)
1,7 (74,5)
–4,6 (1)
3,1 (93,5)
–1,1 (39)
–2,9 (10)
–0,2 (52)
3,4 (97,5)
1,7 (74,5)
–1,6 (29,5)
–3,6 (3,5)
2,5 (84,5)
–3,4 (5)
3,2 (95)
–1,8 (27)
–2 (22)
0,6 (61,5)
3,1 (93,5)
1,5 (70)
–0,8 (44)
–4,0 (2)
1,9 (78)
–2,4 (15,5)
2,6 (87)
–2,7 (11,5)
–1,6 (29,5)
1,4 (68)
2,5 (84,5)
0,8 (63)
–0,2 (52)
–3,3 (6)
1,6 (71.5)
–2,0 (22)
1,4 (68)
–2,0 (22)
0 (54,5)
1,7 (74,5)
1,8 (77)
0,2 (56,5)
0,3 (58)
–2,5 (13)
1,2 (65)
–1,4 (35)
–0,8 (44)
1,6 (71,5)
0,4 (59)
–0,6 (48,5)
–3,2 (7,5)
1,7 (74,5)
0,9 (64)
–1,0 (41)
–2,4 (15,5)
3,3 (96)
–1,6 (29,5)
2,0 (79,5)
0 (54,5)
–1,0 (41)
–2,2 (18)
2,2 (82,5)
1,3 (66)
–1,5 (32)
–3,0 (9)
3,0 (91,5)
–1,8 (27)
2,2 (82,5)
–0,6 (48,5)
–1,9 (25)
–1,5 (32)
2,8 (89,5)
1,6 (71,5)
–2,1 (19)
–2,7 (11,5)
2,6 (87)
–1,2 (37,5)
2,6 (87)
–1,8 (27)
–2,4 (15,5)
–0,7 (46,5)
3,4 (97,5)
0,2 (56,5)
–1,4 (35)
–2,0 (22)
2,0 (79,5)
–0,5 (50)
3,0 (91,5)
–2,4 (15,5)
–2,0 (22)
–0,2 (52)
4,0 (100)
–0,7 (46,5)
–1,0 (41)
–0,8 (44)
1,4 (68)
объемами n1 = 50, n2 = 50.
Проводя ранжирование выборочных данных двух испытательных полетов (номера рангов указаны в скобках), рассчитываем статистику критерия (для N = 100), равную 0,31. Пользуясь таблицей
процентных точек распределения [14] с L – 1 = 1 степенью свобо2
= 3,84. Следовательно, гипотеза о том, что все выды, имеем χ 0,05
борочные данные принадлежат одному и тому же распределению
не отвергается на уровне значимости 0,05.
Еще одним ранговым критерием является критерий Ван дер
Вардена, основанный на статистике
N −1
1
Q=
2 ∑
N ⎡
⎛ i ⎞ ⎤ j =1 n j
∑ ⎢Φ −1 ⎜
⎟⎥
i =1 ⎣
⎝ M + 1 ⎠⎦
L
2
⎡ n j −1 ⎛ Si ⎞ ⎤
Φ ⎜
⎟⎥ ,
⎢∑
⎝ N + 1 ⎠⎦
⎣ i =1
где Φ −1 (⋅) — обратная функция стандартного нормального распределения. Критерий является асимптотически оптимальным для задачи
L выборок с основной функцией распределения F нормального типа.
57
Значение величины Q сравнивается с квантилем распределения
χ 2 с L – 1 степенями свободы на уровне значимости α. Если
Q ≥ χ α2 ( L − 1) ,
то гипотеза H 0 отвергается.
В заключение отметим, что если имеется основание считать выборочные данные в L испытательных полетах распределенными по
нормальному закону, то для проверки нулевой гипотезы об их принадлежности к общей генеральной совокупности можно использовать критерий, основанный на статистике дисперсионного отношения (критерий Фишера):
FL ( L − 1, n1 + nL2 + ... + nL − L) = F ( L − 1, N − L) =
2
1 L
∑ n j ⎡⎣ x j ( n j ) − x( N ) ⎤⎦
L − 1 j =1
=
,
2
s (N )
где
L
1
1 L
x( N ) =
∑ n j x j (n j ) = ∑ n j x j (n j ),
n1 + ... + nL j =1
N j =1
L
2
1
2
s (N ) =
∑ ( n j − 1) s j (n j ),
N − L j =1
2
1 nj
2
s j (n j ) =
∑ xi − x j , n1 + ... + nL = N
n j − 1 i =1
(
)
Можно показать, что если справедлива гипотеза H 0 , то статистика FL подчиняется закону F-распределения с числом степеней
свободы числителя и знаменателя L − 1 и N – L соответственно.
Гипотеза об однородности не отвергается, если удовлетворяется
неравенство
FL ≤ Fα ( L − 1, N − L) .
Для испытательных полетов одинакового объема n j = n, N = nL
критерий записывается в виде:
2
n L
∑ xj − x
L − 1 j =1
FL [ L − 1, L( n − 1)] =
,
2
s
2
2
1 L
1 L
1 n
x = ∑ x j , s = ∑ s 2j , s 2j =
∑ xi − x j .
L j =1
L j =1
n − 1 i =1
)
(
(
58
)
Отметим, что слишком «большое» значение статистики FL , т.е.
такое, при котором нарушается неравенство FL ≤ Fα , может быть
следствием как значимого расхождения средних, так и значимого
расхождения дисперсий.
2.2.5. Критерии согласия
Очевидно, что точная оценка распределения случайной величины по результатам эксперимента принципиально невозможна и необходимо поэтому строить различные гипотезы о распределении
случайной величины, например, гипотезу о том, что она распределена нормально и согласуется с экспериментальными данными.
Такая задача тесно связана с задачей определения доверительных
областей для плотности или функции распределения. Однако она
имеет и некоторые особенности, заключающиеся в том, что оценка
параметров распределения проводится по той же выборке, по которой проверяется гипотеза о распределении (проверяя гипотезу о
нормальности распределения по той же выборке оценивают математическое ожидание и дисперсию). Вследствие этого гипотетическое распределение оказывается само случайным — функцией случайных результатов измерений. Это и отличает задачу проверки
гипотез о распределении от задачи определения доверительных областей для распределений.
Для проверки гипотез о распределении используются различные
критерии согласия. Наиболее универсальным критерием является
критерий χ 2 , который не зависит ни от распределения случайной
величины, ни от ее размерности. Критерий состоятелен и очень
чувствителен к альтернативным гипотезам. Если нулевая гипотеза
неверна, то χ 2 при большем значении r (r — количество интервалов разбиения диапазона изменения случайной величины) оказывается настолько большим, что даже при сравнительно малых значениях α попадает в критическую область. Он, вероятно, забракует
неправильную гипотезу, обеспечивая минимальную вероятность
ошибок второго рода, особенно в условиях большего числа измерений. Однако при группировке результатов измерений нужно
стремиться к образованию больших по численности интервалов. В
каждом интервале должно быть не менее четырех результатов измерений и малочисленные интервалы необходимо объединять [13].
Это вызвано приближенным характером закона распределения стати59
стики χ 2 критерия (приближение допустимо при больших по численности интервалах). Кроме того, в самом способе проверки есть некоторый произвол. Это касается выбора числа интервалов, от которых
зависит значение χ α2 , определяемое по соответствующей таблице [14].
Для проверки гипотезы используют экспериментальные данные,
объединенные в r интервалов. В результате можно построить эмпирическое распределение f ∗ ( z ) . Сравнение эмпирического f ∗ ( z )
и теоретического (модельного) f(z) распределений и осуществляется с помощью критерия χ 2 . Ясно, что группировка связана с некоторым «обеднением» выборки и частичной потерей информации.
Обозначим количество наблюденных значений в k-м интервале
через f k , а количество ожидаемых значений случайной величины
в этом интервале, если истинная плотность распределения случайной величины Z есть f(z), через Fk . Таким образом, Fk — теоретическая частота попадания случайной величины в k-й интервал, а
f k — реальная частота попадания, рассчитанная по экспериментальным данным. Чтобы определить общую степень расхождения
2
для этих интервалов, суммируют квадраты отклонений ( f k − Fk ) и
получают выборочную (наблюденную) статистику критерия:
r
( f k − Fk )
k =1
Fk
χ =∑
2
2
,
которая имеет распределение χ 2 с (r – s − 1) степенями свободы,
где s — количество параметров распределения f(z), рассчитанных
по экспериментальным данным.
Решающее правило критерия для проверки гипотезы H 0 определяется неравенством
χ 2 ≤ χ α2 (r − s − 1).
Диапазон изменения случайной величины рекомендуется разбивать на r интервалов в зависимости от числа наблюдений в соответствии с табл. 2.4.
Таблица 2.4
Число наблюдений
Рекомендуемое число интервалов
40 — 100
100 — 500
500 — 1000
1000 — 10000
7—9
8 — 12
10 — 16
12 — 22
60
Известны два основных способа разбиения диапазона изменения случайной величины. Первый заключается в выборе таких интервалов группировки, которые обеспечивают равенство ожидаемых частот для всех интервалов (за исключением гипотезы о
равномерности распределения). Этот способ приводит к интервалам группировки различной длины. Второй способ состоит в выборе интервалов одинаковой длины. В этом случае разными окажутся
частоты попадания в тот или иной интервал. При проверке нормальности обычно используются интервалы одинаковой длины.
Если принять длины интервалов равными, то их длину целесообразно выбирать из условия Δz = 0, 4 ÷ 0,5s , где s — оценка среднеквадратического отклонения, полученная по выборке. Так как
частоты, соответствующие хвостам распределения, быстро убывают, то в качестве первого и последнего интервалов выбирают интервалы, простирающиеся соответственно до − ∞ и ∞ (при условии, что в этих интервалах f k > 3 ). Тогда границы интервалов группировки экспериментальных данных определяются в соответствии
со стандартным нормальным распределением. Так как нормированное значение случайной величины равно
z−z
u=
,
s
где z — выборочное среднее, то границы интервалов определяются
в соответствии с выражением
z = su + z .
Ожидаемые вероятности pk попадания выборочных значений в
каждый из интервалов определяются с помощью таблицы стандартного нормального распределения [14], а ожидаемые (теоретические) частоты попадания в соответствующие интервалы Fk определяются произведением Fk = Npk . Очевидно, что наблюденные
частоты подсчитываются после ранжирования выборочных значений, используя границы интервалов.
Пример 2.14. Проверить гипотезу нормальности объединенной
выборки двух испытательных полетов (пример 2.13) объемом N = 100.
Статистическая обработка экспериментальных данных дает оценки среднего и дисперсии z = −0,09, s 2 = 5,08. Необходимые
вычисления при проверке гипотезы нормальности показаны в
табл. 2.5.
61
Таблица 2.5
Границы
Номер
интервала
u
z
1
2
3
4
5
6
7
8
9
10
–2,0
–1,5
–1,0
–0,5
0
0,5
1,0
1,5
2,0
∞
–4,6
–3,465
–2,34
–1,215
–0,09
1,035
2,16
3,285
4,41
∞
pk
Fk
fk
0,0228
0,044
0,0919
0,1499
0,1914
0,1914
0,1499
0,0919
0,044
0,0228
2,3
4,4
9,2
15
19,1
19,1
15
9,2
4,4
2,3
1
3
13
19
17
11
17
14
5
—
χ2
10,59
Заметим, что крайние интервалы объединены, чтобы выполнялось условие f k > 3. Критическое значение статистики находим из
таблицы распределения χ 2 (таблица процентных точек) [14] на
уровне значимости α = 0,05 (5%):
2
2
χ 0,05
(8 − 2 − 1) = χ 0,05
(5) = 11,07.
2
Так как χ 2 < χ 0,05
= 11,07 , то гипотеза о нормальности принимается с уровнем значимости α = 0,05.
В [9] рекомендуется решающее правило применять в следующем виде:
χ 2 α (r − s − 1) ≤ χ 2 < χ 2α (r − s − 1) ,
1−
2
2
то гипотеза H 0 принимается;
χ 2 ≥ χ 2α (r − s − 1) ,
2
то гипотеза H 0 отвергается;
χ 2 ≤ χ 2 α ( r − s − 1) ,
1−
2
то требуется дополнительные исследования.
62
В последнем случае нужно отметить, что хотя статистика χ 2 и
является мерой отклонения гипотетического закона от истинного,
но мерой случайной, т.е. величиной, подверженной неконтролируемому разбросу. И в этом отношении одинаково маловероятными следует считать как слишком большие значения наблюденной
статистики χ 2 , так и слишком малые. Слишком малое значение статистики может свидетельствовать о неудачном выборе модельного
закона f(z), о нарушении корректности или объективности, вызванном стремлением «подогнать» экспериментальные данные под желаемый результат.
63
3
ОЦЕНКА ТОЧНОСТНЫХ
ХАРАКТЕРИСТИК
ПО ЭКСПЕРИМЕНТАЛЬНЫМ ДАННЫМ
3.1. Особенности применения статистических методов
обработки данных летных испытаний
Важную группу исходных данных составляют характеристики
движения самолета, а именно статистические свойства определяющих параметров как случайных функций времени. Непосредственно обрабатывая данные летных испытаний, мы имеем дело сразу с
суммарным эффектом действия всех возмущений.
При получении статистических характеристик движения летательного аппарата необходимо четко устанавливать, по какому
множеству реализаций проводится усреднение, и как эти данные
будут использоваться в дальнейшем. Строго говоря, исходные данные должны быть взяты для тех же диапазонов изменения внешних
условий, для которых бортовая система управления должна работать без перестройки (генеральная совокупность, из которой делается выборка для составления статистики, должна совпадать с генеральной совокупностью, для которой строятся решения).
Для того, чтобы построить конкретный алгоритм статистической обработки, необходимо с максимальной полнотой формализовать априорные представления о поведении объекта в тех или иных
условиях ( другими словами, нужно знать что искать и среди чего
искать). Если область поиска не ограничена, то интерпретация становится неосуществимой. Необходимо обеспечить учет интересующих особенностей объекта и в то же время не переусложнить
модель введением большого числа неизвестных, ибо для их определения может не хватить информации, содержащейся в экспериментальном материале. При интерпретации результатов следует
учитывать, что достоверность результатов не может быть выше,
чем достоверность исходных данных и сделанных допущений.
Как известно, любое распределение вероятностей полностью
определяется значениями всех своих моментов [62]. Если известны
64
не все моменты, а лишь некоторые из них (как правило, несколько
первых моментов), то эти распределения оказываются неопределенными, т.е. существует целый класс различных распределений,
имеющих одинаковые заданные моменты. В этом классе существует некоторое распределение, характеризующееся наибольшей свободой выбора (максимальной энтропией). Очевидно, что при неизвестном действительном распределении алгоритм обработки целесообразно строить именно для этого максимально — энтропийного
распределения, так как при этом исследователь рассчитывает на
самый «худший» случай.
Анализ максимально — энтропийных распределений с фиксированными первыми моментами, проведенный в [65], показывает,
что если заданы первые два момента, то максимально — энтропийным оказывается нормальное распределение.
Это означает, что независимо от того, каким является действительное распределение, при известных первых двух моментах в качестве «заменителя» необходимо выбирать нормальное распределение.
Таким образом, при статистической обработке экспериментальной информации необходимо использовать широкие, гибкие модели, позволяющие учитывать свойства реальных исходных данных,
в том числе их неопределенность, использовать не только строгие
классические, но также робастные и непараметрические методы
обработки и критерии проверки различных гипотез, позволяющие
вместе получать достаточно высокую надежность (устойчивость)
статистических выводов.
Можно выделить две основные статистические задачи:
• оценка параметров некоторого распределения;
• проверка статистических гипотез как о параметрах распределения, так и о самих распределениях.
В классической статистике предполагается, что исходные экспериментальные данные представляют собой выборку из вероятностного распределения известного вида, чаще всего гауссовского, и неизвестны лишь его параметры. При этом используется
естественный критерий оптимальности оценок — минимум дисперсии. Традиционные статистические методы позволяют решать
широкий круг задач, таких как нахождение оптимальных оценок и
доверительных интервалов для параметров, проверка значимости
параметров и т.д.
Однако для некоторых практических задач классические методы оказываются неадекватными, о отклонение от моделей сильно
влияет на свойства оптимальных оценок. В этом случае можно ис65
пользовать робастный подход, в котором вероятностная модель
предполагается менее строгой (например, распределение выборки
может быть приближенно нормальным). При этом оценки параметров должны быть достаточно эффективными (близкими к оптимальным) на всем принятом классе распределений, т.е. устойчивыми по отношению к отклонениям от основной гауссовской
модели.
В некоторых случаях необходимо использовать непараметрический подход, при котором не вводятся ограничения на вид распределения. При таком подходе применяемые методы менее эффективны, но имеют большую устойчивость.
Как уже отмечалось, для получения более надежных статистических выводов необходимо использовать как параметрические,
так и непараметрические методы статистической обработки экспериментальных данных.
3.2. Определение точечных оценок
вероятностных характеристик
Параметрическое оценивание. Допустим, что имеется n реализаций определяющего параметра zi (t ), i = 1, n некоторого испытательного полета. На рис. 3.1 показан пример записи параметра на
временном интервале, примыкающем к моменту времени пролета
высоты принятия решения.
Очевидно, что на промежутке АБ все реализации имеют нестационарный участок, в то же время в промежутке БВ все реализации
носят стационарный характер.
Это означает, что при повторении наблюдений (в примерно
одинаковых условиях) будут зарегистрированы иные реализации
того же параметра, которые также будут случайными и обладать
свойствами стационарности. Эти реализации на участке БВ можно
рассматривать в качестве типичных представителей некоторого эргодического ансамбля и описывать при помощи усредненных (статистических) характеристик.
При дискретном представлении реализаций используются их
мгновенные значения, измеренные через некоторый временной интервал Δt и при статистической обработке вводят понятие временных сечений процесса, в которых реализации представлены своими
дискретными значениями, т.е. массивом {zij }, i = 1, n, j = 1, m.
66
1
2
3
.....
n
А
Б
m
. . . . .
3
2
1
В
Рис. 3.1. Реализации определяющего параметра
Статистические характеристики можно рассчитать несколькими
способами. Если n достаточно велико, то можно провести одно сечение t = t0 (например, в интересующий исследователя фазе полета) и определить, например, точечную оценку математического
ожидания по формуле
1 n
z = ∑ zi (t0 ).
n i =1
Если n сравнительно мало, то можно провести несколько сечений t = t1 , t2 , ..., tm и в случае стационарности и эргодичности процесса определить оценку математического ожидания с помощью
оператора двойного усреднения:
z=
1 n m
1 m
∑ ∑ zij = ∑ z j .
mn i =1 j =1
m j =1
Полученная таким образом оценка z характеризует любое сечение случайного процесса, в том числе и терминальное сечение.
Очевидно, что оценка, полученная с помощью оператора двойного усреднения будет точнее ( при прочих равных условиях), так
как использует больший объем статистических данных (N = mn).
67
Однако необходимо помнить, что все статистические выводы (проверка статистических гипотез, определение точности получаемых
оценок вероятностных характеристик) используют независимые
измерения (отсчеты). Поэтому при статистической обработке необходимо выделить только независимые отсчеты, число которых k <
m. Для этого нужно знать корреляционную функцию случайного
процесса с целью определения интервала корреляции τ к . В некоторых случаях [20, 21] вводят понятие эффективного объема выборки N эф , учитывающего остаточную корреляцию в массиве {zij },
i = 1, n; j = 1, k . Например при определении оценки математического ожидания эффективный объем выборки можно определить как
N
, N = nk .
i ⎞
⎛
1 + 2 ∑ ⎜ 1 − ⎟ R (iΔτ)
N⎠
i =1 ⎝
Известно [47], что точность оценки определяется ее дисперсией.
В рассматриваемом случае имеем :
N эф =
N −1
m2 − m 2 Dz
=
,
N
N
где m2 — второй начальный момент, N = nk — количество независимых измерений.
В общем случае дисперсия оценки z определяется выражением:
2
⎧ 1 N −1
⎫
D[ z ] = M ⎨ ∑ [ z (iΔt ) − mz ]⎬ =
⎩ N i =0
⎭
D[ z ] =
N −1
1
⎧ N −1
⎫
M ⎨ ∑ [ z (iΔt ) − mz ] ∑ [ z ( j Δt ) − mz ]⎬ =
2
N
i
j
=
=
0
0
⎩
⎭
1 N −1 N −1
= 2 ∑ ∑ M {[ z (iΔt ) − mz ][ z ( j Δt ) − mz ]} =
N i =0 j =0
1 N −1 N −1
= 2 ∑ ∑ K z [( j − i )Δt ].
N i =0 j =0
Полученное выражение можно представить в виде (обозначив
j – i = l):
l ⎞
1 N −1 ⎛
D[ z ] =
∑ ⎜1 − ⎟ K z (l Δt ) .
N l =− ( N −1) ⎝ N ⎠
=
68
Учитывая симметричность корреляционной функции стационарного случайного процесса, можно записать, что
[]
Dz =
N −1⎛
⎤
l ⎞
1 ⎡
⎢ K z (0) + 2 ∑ ⎜⎜1 − ⎟⎟ K z (lΔt )⎥ .
N ⎣⎢
N⎠
l =1 ⎝
⎦⎥
В [21] обосновывается возможность использования в расчетах
вместо неизвестной функции K z (lΔt ) ее оценки, найденной в результате обработки реализаций случайного процесса Z(t).
Если интервал корреляции невелик и корреляционная функция
K z (l Δt ) быстро убывает с увеличением l, то D [ z ] → 0 при N → ∞,
что свидетельствует о состоятельности оценки z .
При использовании некоррелированных отсчетов, полученных с
шагом Δt ≥ τ к , можно считать для l ≠ 0, что K z (l Δt ) ≈ 0. В этом
случае
K (0) Dz
=
.
D[z ] = z
N
N
При оценке дисперсии выделяют два случая: среднее значение
случайного процесса M [ Z (t )] = m известно или не известно. При
o
известном m процесс центрируют, т.е. рассматривают Z (t ) = Z (t ) − m
и определяют оценку дисперсии в соответствии с выражением:
1 N 0
2.
∑
N i =1 Z (ti )
s2 =
Для гауссовского процесса дисперсия оценки s 2 определяется
выражением
4T⎛
t⎞
D[ s 2 ] = ∫ ⎜ 1 − ⎟ K z2 (t )dt .
T 0⎝ T ⎠
Однако, как правило, на практике математическое ожидание m
бывает неизвестно. Тогда при вычислении оценки дисперсии используется оценка среднего z , которая получается по этой же реализации (или по ансамблю реализаций) процесса. В этом случае
используется оценка вида
T
2
s 2 = c ∫ ⎡⎣ z (t ) − z ⎤⎦ dt ,
0
69
c=
1
,
T (1 − h)
h=
D[ z ]
Dz
,
где коэффициент c, удовлетворяющий условию нормировки, обеспечивает несмещенность оценки s 2 . Для вычисления коэффициента h достаточно знать лишь нормированную корреляционную функцию R(t):
2T⎛
t⎞
h = ∫ ⎜ 1 − ⎟ R (t )dt.
T 0⎝ T ⎠
1
Коэффициент с может существенно отличаться от , соответT
ствующего оценке дисперсии при известном параметре m. Напри−α τ
мер, при нормированной корреляционной функции R (τ) = e cosβτ
при Т = 50, α = 0,05; β = 0,12 значение h = 0,392, и, следовательно,
1
с = 0,033, тогда как = 0,02.
T
Дисперсия несмещенной оценки s 2 , полученной при таком выборе коэффициента с, определяется выражением:
⎡4T⎛
t⎞
D[ s 2 ] = Dz2 ⎢ ∫ ⎜1 − ⎟ R 2 (t )dt + 2h + 3h 2 −
⎣T 0 ⎝ T ⎠
4
2
⎤
− 3 ∫∫∫ R(t − u ) R (τ − u )dtdudτ ⎥ / (1 − h ) .
T
⎦
Оценка дисперсии (или среднеквадратического отклонения) может
быть получена по выборке ( z1 , z2 , ..., zk ) из нормального закона
распределения с помощью статистики
Wk = zmax − z min ,
называемой размахом выборки и определяемой как разность между
наибольшим и наименьшим наблюдениями выборки.
Известно [14], что в случае нормального распределения математическое ожидание статистики определяется выражением
⎡W ⎤
M ⎢ k ⎥ = dk ,
⎣ σ ⎦
70
где σ — среднеквадратическое отклонение выборки, d k — константа, зависящая от объема выборки k. Значения d k табулированы, например, в [14].
W
Таким образом, отношение k определяет собой несмещенную
dk
оценку для среднеквадратического отклонения:
⎡W ⎤
M ⎢ k ⎥ = σ,
⎣ dk ⎦
дисперсия которой равна
⎡ W ⎤ D[Wk ]
D
D⎢ k ⎥ =
= σ 2 2k .
2
dk
dk
⎣ dk ⎦
Значения Dk также приведены в [14].
Для оценки σ берется n выборок объемом k каждая, определяются соответствующие им размахи Wki , по которым рассчитывается средний размах
1 n
W k = ∑ Wki
n i =1
и оценивается параметр σ как
s=
Wk
.
dk
Оценка W k более проста в вычислительном отношении, но
следует заметить, что с увеличением числа наблюдений k относительная эффективность размаха монотонно убывает. Например, для
k, равного 5, 10, 15 и 20, она соответственно будет 0,96; 0,85; 0,77
и 0,7. Поэтому применять размах имеет смысл тогда, когда k < 10.
Применение этой оценки при k > 10 сопряжено со значительной
потерей информации, содержащейся в выборке.
В [28] приводится оценка zmax в виде математического ожидания наибольшей порядковой статистики в случайной выборке объема k с непрерывной строго возрастающей функцией распределения, имеющей нулевое математическое ожидание и единичную
дисперсию:
71
M [ zmax ] ≤
k −1
2k − 1
.
Если математическое ожидание и дисперсия генеральной совокупности равны m и σ 2 , то неравенство принимает вид
M [ zmax ] ≤ m +
( k − 1)σ
2k-1
.
Поведение максимального члена вариационного ряда имеет
сложный характер. Его увеличение относительно минимального
члена происходит более или менее быстро только при малых значениях k. С возрастанием k размах вариационного ряда уменьшается и в поведении zmax и zmin наблюдается некоторая асимптотическая устойчивость. Размах увеличивается пропорционально ln k .
Дисперсия крайних членов вариационного ряда с увеличением k
стремится к нулю и для больших k равна:
D[ zmax ] = D[ zmin ] ≈
σ2 ( z) π2
.
ln k 6
Рассмотренные выше оценки размаха и экстремальных значений могут быть использованы для экспресс-анализа результатов
испытаний с целью грубой оценки дисперсии выборки, значений
zmax и zmin .
В большинстве случаев флюктуации определяющих параметров
оказываются относительно медленными, что приводит к появлению корреляционных связей между отсчетными значениями сигналов. Оценка корреляционных функций при статистической обработке результатов испытаний позволяет учесть эти связи.
Определим оценку корреляционной функции по дискретным
отсчетам как:
K z∗ (l Δt ) =
≈
1 N −l −1
∑ [ z (iΔt ) − mz ][ z (i + l )Δt − mz ] ≈
N i =0
1 N −l −1
∑ [ z (iΔt ) − z ][ z (i + l )Δt − z ],
N i =0
где lΔt принимает значения, кратные шагу квантования по времени Δt . При l = 0 формула обеспечивает вычисление дисперсии. В
72
этом случае интервал выборки Δt совпадает с интервалом отсчетов
и полученная оценка почти не уступает непрерывной оценке по
статистической точности, а выборка называется сильно коррелированной. Недостатком такого способа обработки является значительная избыточность исходной информации. Эффективность выборочного алгоритма можно повысить, если использовать для усреднения лишь те отсчеты, для которых корреляционные связи ослаблены (слабо коррелированная выборка). Вместе с тем увеличение
интервала Δt приводит к возрастанию дисперсии оценки при той же
длительности реализации.
Приведенные выше соотношения имеют большое значение при
использовании выборочных методов определения вероятностных
характеристик случайных процессов. В частности, они позволяют
решить вопрос о статистической точности важнейших оценок статистического анализа. В [25, 58] дан анализ соотношений для дисперсии оценки корреляционной функции для типовых случайных
процессов и выработаны рекомендации относительно интервала и
объема выборки.
Математическое ожидание оценки корреляционной функции определяется выражением:
{
}
M K z∗ (l Δt ) =
{
}
1 N −l −1
l ⎞
⎛
∑ M [ z (iΔt ) − z ][ z (i + l )Δt − z ] = ⎜1 − ⎟ K z (l Δt ).
N i =0
⎝ N⎠
и не равно K z (l Δt ). Данная оценка становится несмещенной лишь
при N → ∞.
В [25] показано, что дисперсия этой оценки для нормального
случайного процесса равна:
D ⎡⎣ K z∗ (l Δt ) ⎤⎦ =
i ⎞
1 N −1 ⎛
∑ ⎜1 − ⎟ K z2 (iΔt ) + K z [(i + l )Δt ]K z [(i − l )Δt}.
N i =− ( N −1) ⎝ N ⎠
{
Отклонение закона распределения Z(t) от нормального вызывает
увеличение дисперсии оценки.
Очевидно, что для получения несмещенной корреляционной функl ⎞
⎛
ции необходимо коэффициент перед суммой умножить на ⎜ 1 − ⎟ .
⎝ N⎠
Тогда:
1 N −l −1
K z∗ (l Δt ) =
∑ ⎡ z (iΔt ) − z ⎤⎦ ⎡⎣ z (i + l )Δt − z ⎤⎦ .
N − l i =0 ⎣
73
Для оценки корреляционной функции можно использовать некоррелированные отсчеты [25, 18], выбирая Δτ = mΔt > τ к . Тогда
выражение для оценки корреляционной функции имеет вид:
K z∗ (τ) =
где
1 N / −l −1
∑ ⎡ z (imΔt ) − z ⎤⎦ ⎡⎣ z (im + l )Δt − z ⎤⎦ ,
N / − l i =0 ⎣
N Δτ
=
= m.
N / Δt
Дисперсия оценки в этом случае равна:
D ⎡⎣ K z∗ (l Δt ) ⎤⎦ ≈
1
⎡ K 2 (0) + K z2 (l Δt ) ⎤⎦ ,
/ ⎣ z
N
так как отличны от нуля только слагаемые для i = 0.
Подставляя l = 0, получаем оценку дисперсии, так что для некоррелированных значений ее дисперсия определяется выражением:
2 2
2
K z (0) = / σ 4z .
/
N
N
При некоррелированных выборках среднеарифметическая оценка
корреляционной функции центрированных стационарных случайных процессов обеспечивает минимальную среднеквадратичную
погрешность в классе линейных выборочных оценок [23].
Рассмотрим необходимую последовательность действий для
получения оценок вероятностных (точностных) характеристик определяющих параметров в одном испытательном полете:
• Определение оценки нормированной корреляционной функции по множеству реализаций испытательного полета, а также временного интервала τ к , на котором корреляционная функция убывает до заданного уровня корреляции (например, R = 0,2).
• Определение k1 слабо коррелированных сечений случайного
процесса, отстоящих друг от друга на интервал τ к , начиная от
терминального момента времени t0 .
• Проверка гипотезы однородности экспериментальных данных
непараметрическими критериями (например, критериями Крускала-Уоллиса и Рамачандрана).
• Проверка гипотезы нормальности экспериментальных данных
D ⎡⎣ s 2 ⎤⎦ =
(например, критерием χ 2 ).
74
• Определение оценок математических ожиданий и дисперсий в
выделенных k1 сечениях случайного процесса и расчет точности
полученных оценок.
• Проверка гипотезы стационарности выделенного интервала
длительностью T = ( k1 − 1)τ к как параметрическими, так и непараметрическими критериями. Для определения интервала стационарности Tст случайного процесса, непосредственно примыкающего к
терминальному сечению, целесообразно проверить стационарность
в выделенных временных сечениях, начиная от терминального сечения в обратном по времени направлении. Интервал стационарности задается числом независимых отсчетов k ≤ k1 , для которых гипотеза стационарности не отвергается параметрическими критериями Фишера-Снедекора и Кочрена:
⎧ F ≤ F1− α [ k − 1, k (n − 1)]
k ←⎨
⎩G ≤ Gα (n − 1, k ),
а также непараметрическими критериями (например, критериями
инверсий и Сиджела–Тьюки).
• Определение средних оценок математических ожиданий и
дисперсий (если экспериментальные данные не противоречат гипотезе эргодичности)
2
1 k
1 k
z = ∑ zj,
s = ∑ s 2j
k j =1
k j =1
по объему выборочных данных, равному N = nk.
Определим последовательность действий при статистической
обработке экспериментальных данных, полученных в L испытательных полетах :
• Проверка гипотезы однородности выборочных данных параметрическими (критерий χ 2 ) и непараметрическими (критерии
Крускала-Уоллиса и Ван дер Вардена) методами как по каждому
полету, так и по совокупности полетов.
• Проверка гипотезы о нормальности распределения всех выборочных данных критерием χ 2 для случая L ≥ 2.
• Выделение интервала стационарности случайного процесса
путем определения числа k независимых отсчетов в каждом полете.
Общий интервал стационарности случайного процесса, заданного
75
реализациями L испытательных полетов объемами n1 , n2 , ..., nL , задается минимальным числом отсчетов k, для которых еще не отвергается гипотеза стационарности.
• Определение оценок математических ожиданий и дисперсий
по совокупности L полетов:
L
1 L
∑ ni z i , N = ∑ ni ,
N i =1
i =1
2
L
L
2
1
⎡
⎤
2
(
1)
s =
n
s
n
z
−
+
i −z
∑
∑
i
i
i
⎢
⎥,
N ( N − 1) ⎣ i =1
i =1
⎦
где второе слагаемое определяет так называемую межгрупповую
дисперсию.
Если полеты содержат одинаковые объемы выборочных данных
( ni = n ) , то
z=
(
z=
2
s =
1 L
∑ z i , N = nL,
L i =1
)
( )
2⎤
⎡ n −1 L 2 1 L
1
s
z
z
+
−
i
∑
∑
⎢
⎥.
i
N ( N − 1) ⎣ n i =1
L i =1
⎦
2
В общем случае оценки z и s определяются по выборке объемом Nk.
• Расчет оценок корреляционных функций как по ансамблю, так
и по одной «склеенной» реализации достаточной протяженности с
целью определения степени затухания корреляционной функции с
ростом аргумента τ , что в свою очередь, позволяет подтвердить
(или отвергнуть) гипотезу эргодичности случайного процесса .
Робастные оценки. Как известно, классические методы математической статистики разработаны для тех случаев, когда экспериментальные данные удовлетворяют строгим математическим
моделям и являются оптимальными только для этих моделей. В частности, оценки z и s 2 являются наилучшими при нормальном распределении, однако при отклонениях от него или наличии выбросов их свойства резко ухудшаются. В практических задачах строгие
модели нередко нарушаются и поэтому необходимо при статистической обработке параллельно использовать робастные методы, которые слабо зависят от нарушения введенных предположений,
однако дают достаточно высокую точность оценки.
76
Робастные оценки строятся таким образом, чтобы их свойства
оставались хорошими даже в том случае, когда истинное распределение экспериментальных данных отличается от предполагаемого.
Если робастные оценки близки к классическим, то можно быть
уверенным, что распределение данных близко к нормальному.
Простейшие устойчивые оценки среднего основаны на использовании упорядоченной выборки {z( i ) }: z(1) ≤ z(2) ≤ ... ≤ z( n ) .
Усеченные средние (trimmed means) z (α), (0 ≤ α < 0,5) получают, отбрасывая по k = [nα] крайних членов слева и справа в упорядоченной выборке, а затем усредняя оставшиеся члены:
z (α) =
1 n−k
∑ z( i ) .
n − 2k i = k +1
В частности, при предельном значении α = 0,5 получается выборочная медиана:
n = 2k + 1,
⎧ z( k +1) ,
⎪
med = ⎨ 1
⎪ ⎡⎣ z( k ) + z( k +1) ⎤⎦ , n = 2k ,
⎩2
а при α = 0 получается классическое среднее z (0) = z.
Другой оценкой среднего является среднее по Винзору уровня α
(0 ≤ α < 0,5) или винзоризованная средняя zw . В этом случае крайние члены не отбрасывают, а заменяют на ближайшие к ним из оставшихся членов. Тогда:
n − k −1
1
zw (α) = (k + 1) ( z( k +1) + z( n − k ) ) + ∑ z(i ) .
n
i=k +2
В общем случае оценки z (α) и zw (α) ориентированы на борьбу
с экстремальными наблюдениями, которые рассматриваются как
грубые ошибки. Эти оценки обладают хорошими свойствами, если
грубые ошибки появляются одинаково часто как в левой, так и в
правой частях вариационного ряда.
Наиболее распространенным методом построения робастных
оценок является обобщенный метод максимального правдоподобия, в котором оценка получается из решения уравнения
{
}
n
∑ F ( zi − a) = min Q( F ),
i =1
77
где весовая функция F(z) выбирается так, чтобы при больших
2
z возрастала медленнее, чем квадратичная z (метод наимень2
ших квадратов), но при малых z была близка к z . Поэтому такая М-оценка слабо зависит от выбросов (промахов) и «утяжеленных» хвостов распределения, но при гауссовском распределении
выборки близка к среднему z.
М-оценки не выражаются в явном виде, даже при оценке среднего, а являются решениями уравнений:
n
∑ f ( zi − a) = 0,
i =1
где f ( z ) = F ( z ). Уравнения решаются итерационными методами.
Наиболее распространенной является М-оценка Хубера, содержащая весовую функцию F с некоторой постоянной с, которая носит характер параметра усечения:
/
⎧ − c,
⎪
F ( z ) = ⎨ z,
⎪ c,
⎩
z < −c
z ≤c
z > c, 1 < c < 2; c ≈ 1,5.
Для решения уравнения
n
∑ f ( zi − a) = 0,
i =1
определяющего М-оценку, как правило, применяют итерационную
процедуру Гаусса–Ньютона:
n
al +1 = al +
∑ f ( zi − al )
i =1
n
∑ f / ( zi − al )
,
i =1
где сумма в знаменателе правой части равна числу тех членов выборки zi , для которых выполнено условие zi − ai < c. Если это
выполняется для всех zi , то оценка среднего ai +1 совпадает с классической оценкой среднего z . В качестве начального приближения
для итерационной процедуры можно взять выборочную медиану.
78
Необходимо отметить, что уравнение
n
∑ f ( zi − a ) = 0
i =1
определяет М-оценки при известном значении среднеквадратического отклонения (можно считать, что σ = 1). Если же оно неизвестно, то оценки следует искать как решение уравнения
n
⎡z −a⎤
∑f⎢ i
⎥ = 0,
i =1
⎣ s ⎦
где s — устойчивая оценка среднеквадратического отклонения, определяемая, например, через выборочную медиану
s=
med { zi − med ( zi ) }
0,675
,
или через выборочные квартили
s=
z( n − k ) − z( k )
1,35
n
, k= ,
4
где через med ( zi ) обозначается медиана выборки {zi } . Выборочная р — квантиль представляет собой порядковую статистику
z([ np ]+1) (или z( np ) при np целом), т.е. элемент выборки, левее
[np]
≤ p наблюдений. Для p = 0,25
n
выборочная квантиль называется квартилью.
В большинстве случаев нет необходимости точно решать уравнение, определяющее М-оценку, достаточно выполнить всего 2–3
итерации, чтобы получить удовлетворительное приближение, либо
убедиться, что начальная оценка практически не изменилась.
Как уже отмечалось, приближение оценок а и s 2 к классическим оценкам z и s 2 говорит в пользу гипотезы нормальности
распределения выборочных данных и о возможности применения
соответствующего программного обеспечения.
Кроме М-оценок Хубера можно получать и другие робастные
оценки, в частности М-оценки Хампела, Андрюса и Тьюки с соответствующими весовыми функциями:
(правее) которого находится доля
79
• М-оценка Хампела:
⎧z,
⎪
⎪ a,
⎪
FHA ( z ) = sign z ⎨ a (c − z )
,
⎪
⎪ c−b
⎪⎩0,
z <a
a< z <b
b< z <c
z >c
с рекомендованными параметрами а = 1,7; b = 3,4; c = 8,5.
• М-оценка Андрюса:
⎧ ⎛z⎞
z ≤ cπ
⎪sin ⎜ ⎟ ,
FA = ⎨ ⎝ c ⎠
⎪0,
z > cπ
⎩
с рекомендуемым значением с = 2,1.
• М-оценка Тьюки:
2
2
⎧ ⎡⎛
⎞⎤
z
⎛
⎞
⎟⎥ ,
⎪⎪ z ⎢⎜ 1 −
FT ( z ) = ⎨ ⎢⎜⎝ ⎜⎝ c ⎟⎠ ⎟⎠ ⎥
⎣
⎦
⎪
⎪⎩0,
z ≤c
z >c
с рекомендуемым значением параметра с = 4,7σ (при известном σ),
4 < c <6.
Пример 3.1. По выборке определяющего параметра {zi } объемом n = 10 определить робастные оценки среднего и дисперсии:
{zi } = 6,8; 6,2; 7,5; 7,1; 6,0; 7,4; 5,9; 6,3; 7,2; 8,4.
Определим М-оценку среднего, используя весовую функцию Хубера. Сначала определяем медиану выборки, равную med {zi } = 6,95.
Так как дисперсия выборочных данных неизвестна, то рассчитываем устойчивую оценку среднеквадратического отклонения s в соответствии с выражением (после ранжирования выборки):
s=
med zi − med {zi }
0,675
80
= 0,89.
М-оценку среднего определяем в соответствии с итерационной
процедурой Гаусса-Ньютона:
n
⎛ z −a ⎞
∑F⎜ i l ⎟
i =1
⎝ s ⎠ .
al +1 = al +
n
/⎛ z −a ⎞
∑F ⎜ i l ⎟
i =1
⎝ s ⎠
Знаменатель в этом выражении определяет число тех членов
выборки, для которых выполнено условие
zi − al
< c = 1,5
s
в соответствии с весовой функцией Хубера.
Таким образом, итерационная процедура дает следующий результат:
a(0) = med{zi } = 6,95;
−0,91
= 6,85;
9
0, 28
a(2) = 6,85 +
= 6,88 ≈ 6,9; a(3) = 6,9,
9
т.е. оценка среднего равна zH = a(3) = 6,9 , а среднеквадратическое
отклонение исходной выборки равно s = 0,89.
Классический метод определения оценок z и s 2 дает следующие значения (при условии нормальности распределения выборки):
a(1) = 6,95 +
z = 6,88; s 2 = 0,628; s = 0,79.
Необходимо отметить, что при глубоком анализе свойств неизвестного распределения F(z) по соответствующей выборке используются не только выборочные моменты, но и другие характеристики выборки, например порядковые статистики z( k ) , в частности
выборочные квантили z[ np ] , которые рассматриваются в качестве
оценки р — квантиля распределения наблюдаемой случайной величины.
Известно [28], что для больших выборок из достаточно гладких
распределений средние члены вариационного ряда асимптотически
нормальны, т.е.
81
⎧⎪
p (1 − p ) ⎫⎪
F { z([ np ]) } ∝ N ⎨ξ p , 2
⎬,
nf (ξ p ) ⎭⎪
⎩⎪
где ξ p — квантиль непрерывного распределения F (ξ), имеющего
плотность f (ξ).
Можно выделить важный частный случай, соответствующий
1
p = . Величина ξ 1 называется медианой распределения F (ξ) , а
2
2
z([ n , 1 ]) = z([ n +1]) — выборочная медиана. В этом случае можно запи2
сать, что
2
{
F z([ n , 1
} ∝ N ⎛⎜⎝ μ, 2πn σ ⎞⎟⎠.
2
2
])
С другой стороны соответствующее выборочное среднее z при
⎛ σ2 ⎞
любом n нормально N ⎜ μ,
⎟ . Тогда, если бы μ было неизвестно,
⎝ n ⎠
то в качестве оценки для него можно было бы использовать (при
больших n) как z([ n , 1 ]) так и z . Однако последняя оценка более
2
π
= 1,57 раза меньше дисперсии
2
в случае нормального распределения исходной выборки.
точная, так как ее дисперсия в
z([ n , 1
2
])
Непараметрические оценки. Робастные методы основаны на
достаточно общих моделях, которые все же остаются параметрическими. В отличие от них непараметрические методы не предполагают использование какого-либо параметрического семейства; для
них класс возможных распределений очень широк — обычно
включает в себя все непрерывные функции распределения.
1 ⎞
⎛
Согласно теореме Чебышева не менее ⎜ 1 − 2 ⎟ 100% распреде⎝ k ⎠
ления случайной величины сосредоточены в интервале m ± k σ. Так
для большинства распределений вероятностные меры интервалов
m ± 2σ и m ± 3σ составляют соответственно не менее 0,75 и 0,889.
Очевидно, что выводы, основанные на использовании характеристик m, σ, становятся весьма приближенными. Иногда наруше82
ния, кажущиеся незначительными, могут существенно исказить
конечные результаты: привести к смещению оценок, доверительных пределов и коэффициентов доверия. У любого инженераисследователя всегда остается «неприятный осадок» в случае предположения о гипотезе нормальности. Поэтому необходимо проводить статистическую обработку полученных экспериментальных
данных еще и непараметрическими методами с целью более глубокой убежденности в правильности полученных результатов, сравнивая их с результатами, полученными параметрическими методами.
Параллельное использование непараметрических методов (и основанных на них статистических критериев), которые являются более устойчивыми к отклонениям распределения от нормального,
представляется как защитная мера от «всяких неожиданностей»,
особенно в тех случаях, когда оценивается точность функционирования систем высокой ответственности, влияющая на безопасность
полета.
Одной из основных непараметрических оценок является оценка
вероятности
P Z ∈ Dm
{
}
как вероятности того, что вектор определяющих параметров Z
(размерность вектора равна m) принадлежит области допустимых
отклонений D m . В качестве оценки применяется эмпирическая частота
r
p∗ = ,
n
где r — число попаданий вектора Z в заданную область D m (например, в прямоугольное «окно» в фазе высоты принятия решения
или на взлетно-посадочной полосе при автоматическом заходе на
посадку и посадке соответственно), n — общее число реализаций в
испытаниях.
Известно [47], что в соответствии с законом сложения двух взаимно исключающих событий с вероятностями p и (1 – p) вероятность появления r успешных исходов (попадание вектора Z в область D m ) в n независимых испытаниях определяется биномиальным распределением (при условии, что величина p неизменна при
проведении испытаний):
n!
P(r , n / p) =
p r (1 − p) n − r .
r !( n − r )!
83
Оценка p∗ является несмещенной ( M [ p∗ ] = p) и эффективной,
так как имеет минимально возможную дисперсию :
p(1 − p)
D[ p∗ ] =
.
n
Вычислить дисперсию оценки по этой формуле нельзя, так как
она выражается через саму оцениваемую величину p. Как правило,
используется формула [65]:
r (n − r )
D[ p∗ ] = 2
,
n (n − 1)
что позволяет рассчитать дисперсию оценки непосредственно по
результатам испытаний (кроме случая, когда r = n ). Если на эту
оценку не накладывать условия несмещенности, то, как показано в
[65], может быть получена смещенная оценка, имеющая меньшее
среднеквадратическое отклонение от истинного значения, чем
D[p]. Такая смещенная оценка определяется формулой
r (n − r )
Dсм ( p ∗ ) = 2
.
n (n + 1)
Выражения для p∗ и Dсм ( p∗ ) совпадают с выражениями для
математического ожидания и дисперсии В — распределения, имеющего плотность:
Γ(a1 + a2 ) a1 −1
f ( x) =
x (1 − x) a2 −1 , 0 ≤ x ≤ 1 ,
Γ(a1 )Γ( a2 )
где a1 и a2 являются параметрами плотности распределения,
имеющей среднее значение
a1
M [ B (a1 , a2 ) ] =
a1 + a2
и дисперсию
D [ B (a1 , a2 ) ] =
a1a2
.
(a1 + a2 ) (a1 + a2 + 1)
2
Действительно, если принять a1 = r , a2 = n − r , то
r
M [ B(r , n − r )] = ,
n
84
D[ B (r , n − r )] =
r (n − r )
.
n 2 (n + 1)
Это распределение может быть использовано для аппроксимации распределения оценки p∗ при большом числе испытаний, что
может быть достигнуто при статистическом моделировании. При
малом числе испытаний n точность оценки p∗ можно характеризовать доверительным интервалом, используя для этого непосредственно биномиальное распределение.
Другой не менее важной оценкой вероятностных характеристик
является эмпирическая функция распределения, соответствующая
выборке ( z1 , z2 , ..., zn ) и задаваемая соотношением:
z < z(1)
⎧0,
⎪
⎪r
Fn ( z ) = ⎨ ,
zr ≤ z ≤ z( r +1)
⎪n
z ≥ z( n )
⎪⎩1,
где z(⋅) — порядковая статистика, r — случайная величина, равная
числу элементов выборки, значения которых не превышают z, т.е.
r = j : zj ≤ z .
Очевидно, что функция Fn (z ) является кусочно-постоянной и
возрастающей только в точках вариационного ряда, построенного
1
по выборке, скачками величиной .
n
По своему определению эмпирическая функция распределения
является случайной функцией: для каждого z значение Fn ( z ) —
1
случайная величина, реализациями которой являются числа 0, ,
n
2
n −1 n
, ...,
, =1.
n
n n
Эмпирическая функция распределения играет фундаментальную роль в статистической обработке результатов как летных испытаний, так и статистического моделирования. Важнейшее ее
свойство состоит в том, что при увеличении числа испытаний происходит сближение этой функции с теоретической:
85
lim P{Fn ( z ) − F ( z ) < ε} = 1 .
n →∞
Таким образом, если объем выборки большой, то значение эмпирической функции распределения в каждой точке z может служить оценкой теоретической функции распределения в этой точке.
3.3. Определение интервальных оценок
вероятностных характеристик
В предыдущем разделе были рассмотрены точечные оценки для
параметра θ (например для m, σ 2 и Р). Любая точечная оценка
представляет собой функцию выборки {z1 , z2 , ..., zn }, т.е. является
случайной величиной, и при каждой реализации z выборки эта
функция определяет единственное значение оценки, принимаемое
за приближенное значение оцениваемой характеристики. При этом
надо принимать во внимание , что в каждом конкретном случае
значение оценки может отличаться от значения параметра; следовательно полезно знать и возможную погрешность, возникшую при
использовании предлагаемой оценки. Например, указать такой интервал (или область в случае векторного параметра), внутри которого с высокой вероятностью γ находится точное значение оцениваемого параметра. Такой интервал называют доверительным. Доверительную вероятность γ выбирают заранее; она отражает «степень
готовности мириться с возможностью ошибки».
При заданном γ длина доверительного интервала характеризует
точность локализации значения параметра, поэтому желательно
выбирать кратчайший интервал.
Доверительный интервал по своей природе случаен (поэтому и
идет речь о вероятности накрыть некоторую не известную нам, но
не случайную точку θ) как по своему расположению (ведь θ является случайной величиной), так и по своей длине. Ширина доверительного интервала зависит от объема выборки n (уменьшается с
ростом n) и от величины доверительной вероятности (увеличивается с приближением γ к единице).
Необходимо отметить, что из метода доверительных интервалов
следует утверждение: вероятность того, что пределы (которые могут меняться от выборки к выборке) заключают между собой значение неслучайного параметра θ, соответствующего фактической
выборке, равно γ.
86
Таким образом, мы утверждаем лишь то, что существует правило вычисления доверительных интервалов для параметра θ, которое в частном случае выборки приводит к заданному, причем это
правило относится к коэффициенту доверия γ [47].
Очевидно, что доверительный интервал (в случае многомерного
параметра — доверительная область) должен конструироваться вокруг точечной оценки θ∗ параметра θ. Закон распределения случайной величины θ∗ (в частности ее функция распределения Fθ∗ (θ) ,
которая, к сожалению, тоже зависит от неизвестного истинного
значения параметра θ) определяет характеристики доверительного
интервала (точный вид и объем доверительной области в случае
многомерного параметра).
Параметрические доверительные интервалы. Существует два
подхода в построении интервальных оценок (интервалов и областей). Первый подход основан на том, что распределение выборочной статистики описывается с помощью стандартных (модельных)
законов и не зависит от неизвестного параметра θ.
Второй подход более прост и универсален, однако он основан
на асимптотических свойствах оценок и пригоден лишь при достаточно больших объемах выборок. Он использует тот факт, что
оценки максимального правдоподобия имеют асимптотически нормальное распределение, зависящее от неизвестного параметра θ.
Здесь принимается два допущения: во-первых, асимптотический
вид распределений выборочной статистики применяется при конечных объемах и, во-вторых, вместо неизвестного параметра θ
используется его оценка θ∗ . Далее рассматривается первый подход.
При построении интервальной оценки для математического
ожидания m используется статистика
( z − m)
s
n −1
,
имеющая t — распределение Стьюдента с (n – 1) степенями свободы, которое не зависит от неизвестной дисперсии σ 2 выборочных
данных. Определив из таблиц по заданной доверительной вероятности γ квантиль t1+ γ (n − 1) распределения Стьюдента, получаем γ–
2
доверительный интервал для параметра m:
87
⎡
⎤
s
s
t1+ γ (n − 1); z +
t1+ γ (n − 1) ⎥ .
⎢z −
n −1 2
n −1 2
⎣
⎦
Пример 3.2. По результатам двух испытательных полетов была
получена выборка {zij } объемом n = 100. Статистическая обработ-
ка данных дала следующие оценки: z = −0,09; s 2 = 5,8.
Доверительный интервал для истинного значения математического ожидания при доверительной вероятности γ = 0,95 имеет вид:
2, 41
⎡
⎢ −0,09 − 9,95 1,984;
⎣
− 0,09 +
2, 41
⎤
1,984 ⎥ = [−0,57; 0,39].
9,95
⎦
Интервальная оценка для дисперсии использует статистику
(n − 1) s 2
,
σ2
которая подчинена χ 2 — распределению с (n – 1) степенями свободы. Действительно, сумма квадратов n независимых нормально
распределенных случайных величин с нулевым средним и единичной дисперсией имеет χ 2 — распределение с n степенями свободы.
Отсюда следует:
⎧
⎫ b
(n − 1) s 2
< b ⎬ = ∫ p ( n −1) ( x)dx = γ,
P ⎨a <
2
σ
⎩
⎭ a
где p ( N −1) ( x) — плотность вероятности χ 2 — распределения с (n – 1)
степенями свободы.
Определив из таблиц по заданной доверительной вероятности γ
процентные точки χ 2 — распределения χ 12+ γ (n − 1) и χ 12- γ ( n − 1) полу2
2
чаем неравенство:
a = χ 12+ γ (n − 1) <
2
(n − 1) s 2
< χ 12− γ (n − 1) = b,
2
σ
2
которое выполняется с вероятностью γ.
88
Это равенство эквивалентно равенству
⎧ ( N − 1) s 2
( N − 1) s 2 ⎫
< σ2 <
P⎨
⎬ = γ,
b
a
⎩
⎭
Отсюда следует, что доверительный интервал
⎡
⎢ 2 n −1
⎢ s χ 2 (n − 1) ;
1-γ
⎢
⎣
2
⎤
n −1 ⎥
s 2
,
χ 1+ γ (n − 1) ⎥
⎥
⎦
2
2
накрывает неизвестное значение дисперсии σ 2 с заданной вероятностью γ.
Извлекая корень из полученных значений границ доверительного интервала, получаем доверительный интервал для среднеквадратического отклонения σ.
Пример 3.3. В условиях предыдущего примера получаем доверительный интервал для дисперсии:
99
⎡
⎢5,8 128, 42 ;
⎣
5,8
99 ⎤
= [4,52; 7,9].
73,36 ⎥⎦
Доверительный интервал для среднеквадратического отклонения может быть построен с помощью оценки среднего размаха выборки W k (см. раздел 3.2). Из известных в теории порядковых статистик приближений для среднеквадратического отклонения наиболее удобным является приближение Кокса [28]:
Wk c 2
= χν,
σ
ν
так как позволяет использовать хорошо отработанное в статистике
χ 2 — распределение.
Множители ν(n, k) и c(n, k) определяются с помощью первых
двух моментов d k и Dk по следующему алгоритму:
• вычисляется вспомогательная величина
A(n, k ) =
89
2 Dk
,
nd k2
• рассчитывается эквивалентное число степеней свободы
ν = A−1 +
1 3
3 2
A
− A+
4 10
64
• определяется константа
−1
1
1 ⎞
⎛
+
.
c = d k ⎜1 −
2 ⎟
⎝ 4ν 32ν ⎠
Таким образом, оценка среднеквадратического отклонения определяется соотношением:
ν
s =W k 2 .
cχ ν
По известному числу степеней свободы ν и заданном коэффициенте доверия γ определяется доверительный интервал на σ. Для
этого рассчитываются квантили χ 2 -распределения:
⎡ 1− γ ⎤
χ 12 = χ 2 ⎢ ν,
;
2 ⎥⎦
⎣
⎡ 1+ γ ⎤
.
χ 22 = χ 2 ⎢ ν,
2 ⎥⎦
⎣
Так как
{
}
P χ 2 ∈ ⎡⎣ χ12 ; χ12 ⎤⎦ = γ ,
то
⎧⎪ cχ 2 W k cχ 22 ⎫⎪
P⎨ 1 ≤
≤
⎬=γ,
σ
ν ⎪⎭
⎩⎪ ν
откуда определяются верхняя и нижняя границы доверительного интервала
Wkν
Wkν
≤σ≤ 2 .
2
cχ 2
cχ 1
Отметим также, что для статистики
Wk
1 n
=
∑ wki ,
d k nd k i =1
90
которая является несмещенной оценкой параметра σ, при k = const
и n → ∞ можно записать [16]:
⎧⎪ W k − d k σ
⎫⎪
⎛ 1 ⎞
P⎨ n
< z ⎬ = Φ( z ) + o ⎜
⎟,
σ Dk
⎝ n⎠
⎪⎩
⎪⎭
откуда следует, что
⎧
⎫
⎪
⎪
Wk
Wk
⎪
⎪
P⎨
<σ<
⎬=γ,
Dk
Dk ⎪
⎪d + u
d k − u1+ γ
1+ γ
⎪ k
n
n ⎪⎭
2
2
⎩
где u — соответствующий квантиль стандартного нормального распределения N(0,1).
Выше были рассмотрены доверительные интервала для скалярного параметра (m или σ 2 ), которые с заданной доверительной вероятностью γ накрывают истинное значение соответствующего неизвестного параметра. Было бы неверным считать, что двумерная
точка θ = (m, σ 2 ) с вероятностью γ лежит в прямоугольнике:
⎡
⎤
s
s
t1+ γ ( n − 1); z +
t1+ γ ( n − 1) ⎥ ,
⎢z −
n −1 2
n −1 2
⎣
⎦
⎡
⎤
n −1 ⎥
⎢ 2 n −1
2
⎢ s χ 2 ( n − 1) ; s χ 2 (n − 1) ⎥ ,
1− γ
1+ γ
⎢
⎥
2
2
⎣
⎦
z−m
так как случайные величины
и s 2 , на основании которых
s
строились эти интервалы, зависимы.
Рассмотрим оценивание векторного параметра θ = (m, σ 2 ) с использованием доверительной области ω(Z) ⊂ Θ при условии, что
P{θ ∈ ω(Z )} ≥ γ, ∀θ ∈ Θ .
Соответствующую γ-доверительную область для пары (m, σ 2 )
можно построить, например, используя двумерную статистику
( z, s2 ), компоненты которой являются независимыми случайными
91
величинами [63]. Тогда вероятность γ одновременного накрытия
доверительной областью истинных значений m и σ 2 равна произведению вероятностей γ1 и γ 2 . При этом γ1 — доверительная вероятность, с которой параметр m будет накрыт соответствующим
доверительным интервалом, а γ 2 — доверительная вероятность, с
которой соответствующий интервал накроет неизвестную дисперсию. Определив γ1 = γ 2 = γ, доверительную область на параметр
θ задаем системой неравенств:
s
s
⎪⎧
⎪⎫
P ⎨z −
t1+ γ (n − 1) < m < z +
t1+ γ (n − 1) ⎬ ×
n −1 2
n −1 2
⎪⎩
⎪⎭
⎧
⎫
n −1 ⎪
⎪ 2 n −1
2
2
× P ⎨s 2
<σ <s 2
⎬ = γ.
χ 1+ γ (n − 1) ⎪
⎪ χ 1− γ (n − 1)
2
2
⎩
⎭
Разрешая неравенства относительно параметров m и σ 2 , получаем искомую γ-доверительную область ωγ (n). Область представляет собой часть плоскости (m, σ 2 ), ограниченную параболой и
двумя прямыми, рис. 3.2. Величина площади, ограниченная этой
областью, зависит от доверительной вероятности γ, объема выборочных данных, а также от полученных оценок z и s 2 .
Рис. 3.2. Доверительная область на параметр θ
Если вместо дисперсии σ 2 использовать среднеквадратическое
отклонение σ, то γ-доверительная область будет представлять собой трапецию. Координаты доверительной области могут быть ис92
пользованы при оценке соответствия бортовой системы управления
заданным требованиям на точностные характеристики.
Необходимо отметить, что доверительные интервалы и критерии, которые относятся к дисперсии σ 2 ( χ 2 -распределение), более
чувствительны к отклонению от нормального распределения, чем доверительные интервалы и критерии для математического ожидания m.
Согласно центральной предельной теореме распределение величины χ 2n стремится к нормальному при n → ∞ и для достаточно
точного приближения используется аппроксимация Фишера [47].
Тогда доверительный интервал для среднеквадратического отклонения определяется как:
2( n − 1) s
2(n − 3) + u
<σ<
2(n − 1) s
2(n − 3) − u
,
где u — квантиль стандартного нормального распределения уров1+ γ
.
ня
2
Отметим однако, что такая аппроксимация не гарантирует точного доверительного интервала с заданным значением доверительной
вероятности γ. Это связано с тем, что хотя при n → ∞ χ2n → N n, 2n ,
(
)
2
s
(n − 1) из произσ2
вольной совокупности будет асимптотически приближаться к χ 2n −1 распределению. По этой причине нормальная теория не может
быть использована в качестве основы для статистических выводов
о σ при существенных отклонениях исходного распределения от
нормального.
Для построения доверительных интервалов при больших n в
случае существенного отклонения от нормальности можно исходить из асимптотической нормальности второго центрального выσ
борочного момента s 2 с параметрами ms2 = σ 2 , σ s 2 = 2 , где
n
однако нет никакой гарантии, что статистика
σ 2 = M {( Z − m) 2 } — среднеквадратическое отклонение случай-
ной величины (Z – m) [33], т.е.
93
s2 − σ2
n ∝ N (0,1).
σ2
Заменяя неизвестное σ 2 его приближенным выборочным значением s2 получаем γ-доверительный интервал для дисперсии:
s2 −
где
s2 =
us2
n
< σ2 < s2 +
(
1 n
∑ zi − z
n i =1
)
4
us2
n
,
− s4 .
Несколько более точное выражение для дисперсии s2 выборочной оценки дисперсии получено в [42]. Исходя из этого можно
ожидать, что параметр эксцесса будет больше влиять на распределение оценки, чем параметр асимметрии. Это влияние приводит к
изменению истинного значения доверительной вероятности к получаемому доверительному интервалу по сравнению с заданной
величиной γ. Изменение происходит в сторону уменьшения истинного значения.
Отметим, что построение γ = γ m γ σ — доверительной области
совместно на параметр θ = [m, σ 2 ] основывается на независимости
выборочных оценок z , s 2 . Если генеральная совокупность исследуемого определяющего параметра симметрична, то оценки z , s 2
асимптотически независимы, так что доверительная область при
больших n может быть получена на основании рассмотренных выше соотношений.
Кроме доверительных интервалов на оцениваемые параметры в
статистической обработке результатов испытаний используют другой вид интервалов — толерантных. Толерантными пределами
некоторого распределения F(z) называют такие две функции
T1 ( z1 , z2 , ..., z N ) и T2 ( z1 , z2 , ..., z N ) , для которых выполняется соотношение
Pr {[ F (T2 ) − F (T1 ) ] ≥ P} = γ.
Это утверждение говорит о том, что вероятность того, что вероятностная мера распределения F(z), равная P, будет сосредоточена
94
внутри толерантного интервала, ограниченного пределами T1 и T2 ,
равна γ, рис. 3.3.
Рис. 3.3. Определение толерантного интервала
В случае нормального распределения с неизвестными параметрами (m, σ 2 ) в качестве толерантных пределов выбирают функции
вида
T1 = z − ks, T2 = z + ks ,
где
z=
1 N
∑ zi ,
N i =1
s2 =
1 N
2
∑ ( zi − z ) .
N − 1 i =1
Очевидно, что толерантный интервал также является случайным. Толерантный множитель k есть решение уравнения
⎧ ⎡ z + ks − m ⎤
⎫
⎡ z − ks − m ⎤
Pr ⎨Φ ⎢
−Φ⎢
≥ P ⎬ = γ.
⎥
⎥
σ
σ
⎦
⎣
⎦
⎩ ⎣
⎭
Множитель k не зависит от параметров m и σ 2 и представляет
собой функцию трех переменных N, γ и Р. Вычисление точных значений множителя очень трудоемко. Для большинства практических
приложений можно использовать приближенное равенство:
2
⎧
⎫
⎡ ⎛ 1 + P ⎞⎤
⎪
− 3⎪
2 ⎢Ψ ⎜
⎟
⎥
⎬
N −1
1
⎛1+ P ⎞⎨
⎝ 2 ⎠⎦
k=
Ψ⎜
− ⎣
⎪,
⎟ ⎪1 +
2
2
χ γ ( N − 1) ⎝ 2 ⎠ ⎩ 2 N
24 N
⎭
95
где Ψ (⋅) — функция, обратная функции нормального распределения, т.е. Ψ ( P) = N −1 ( P; 0,1) . Значения функции Ψ ( P ) приведены в
[14] для 0,5 ≤ P < 1, так как Ψ ( P) + Ψ (1 − P ) = 0.
Пример 3.4. Определить границы толерантного интервала, в котором сосредоточено не менее чем 99% нормальной совокупности
(определяющий параметр имеет нормальное распределение) с доверительной вероятностью γ = 0,95. Результаты летных испытаний:
N = 100, z = −0,09, s 2 = 5,8.
Расчет толерантного множителя дает величину
k=
99
1
10, 27 ⎤
⎡
2,58 ⎢1 +
−
⎥ = 2,93.
77,05
200
240000
⎣
⎦
Границы толерантного интервала равны:
⎡ z ± ks ⎤ = [−7,15; 6,98].
⎣
⎦
При N > 20 можно использовать другое выражение для толерантного множителя, определяемого через квантиль нормального
распределения:
1
N−
N
k = u1+ P 2
,
χ γ ( N − 1)
2
где u1+ P — квантиль стандартного нормального распределения
2
1+ P
.
2
Рассмотренные выше толерантные интервалы являются симметричными относительно оценки среднего значения z , которая,
как правило, не совпадает с центром допустимой области (интервала ) на отклонения определяющего параметра.
Например, в соответствии с нормативными требованиями вероятностная мера P некоторого определяющего параметра должна
быть не менее 0,98 в симметричном относительно нуля фиксированном допуске [–8,2; 8,2] с доверительной вероятностью γ = 0,95.
При этом, как правило, ставится задача определения вероятностной
меры Р при заданной доверительной вероятности γ или определении γ при заданной Р.
N(0, 1) уровня
96
Для расчета толерантных пределов, несимметричных относительно оценки z , определим фиксированный интервал допустимых отклонений определяющего параметра как [a1 , a2 ] (в большинстве случаев a1 < 0, a1 = a2 ). Пусть ( a1 − z ) и ( a2 − z ) являются несимметричными относительно z пределами, рассматриваемые как толерантные. Разделив значения этих пределов на
величину s, получаем значения толерантных множителей k1 и k2 и,
следовательно, можно рассчитать значение квантилей:
u1+ P1 =
2
k1
1
N−
N
χ 2γ ( N − 1)
u1+ P2 =
,
2
k2
1
N−
N
χ 2γ ( N − 1)
.
Используя таблицы распределения N(0,1), определяем вероятностную меру как P = P2 − P1 .
Пример 3.5. В условиях предыдущего примера определить вероятностную меру P, сосредоточенную в интервале [–8,2; 8,2] с доверительной вероятностью γ = 0,95.
Рассчитываем толерантные множители:
−8, 2 − ( −0,09)
= −3,368;
2, 408
8, 2 − (−0,09)
k2 =
= 3, 443,
2, 408
k1 =
Значения квантилей распределения N(0,1):
u1+ P2 =
2
3, 443
= 3,022;
1,139
u1+ P1 =
2
−3,368
= −2,957,
1,139
и вероятностную меру P, сосредоточенную в заданном интервале:
P = 0,9987 – 0,0015 = 0,9972.
Таким образом, с вероятностью 0,95 в фиксированном интервале
[–8,2; 8,2] находится не менее 99,7% функции распределения N (m, σ)
определяющего параметра.
97
Непараметрические доверительные интервалы.
Рассмотрим интервальное оценивание, основанное на непараметрических методах.
Если в качестве оценки центра распределения F(z) принимают
выборочную медиану, т.е. среднее значение вариационного ряда, то
доверительный интервал, характеризующий точность этой оценки,
при доверительной вероятности γ имеет вид [ z(u ) , z(v ) ] , где
N + 1 − u1+ γ N
u=
N + 1 + u1+ γ N
, v=
2
2
2
2
,
а u1+ γ — квантиль нормального распределения N(0,1) уровня
2
1+ γ
.
2
При этом u — наибольшее целое число, но меньше рассчитанного,
а v — наименьшее целое число, но больше, чем рассчитанное.
Пример 3.6. Для N = 100, γ = 0,95 получаем:
med =
1
101 − 19,6
z(50) + z(51) ) , u =
40,7 → 41,
(
2
2
101 + 19,6
= 60,3 → 61.
v=
2
Таким образом, доверительный интервал для медианы равен
[ z(41) ; z(61) ].
Доверительный интервал для вероятности P, оценка которой
определяется по частоте событий, как правило, строится для случая
большого объема испытаний (N > 100). Напомним, что:
M [ P ∗ ] = P;
D[ P∗ ] =
P (1 − P )
.
N
Тогда случайная величина
Y=
( P∗ − P) N
P (1 − P )
стремится к нормальному распределению N(0,1) при N → ∞ . Вследствие этого, биноминальное распределение при большом N сколь
угодно мало отличается от нормального. Это дает возможность
пользоваться нормальной функцией вместо точной биномиальной
98
для приближенного определения доверительных интервалов для
вероятности. Доверительные границы P1 и P2 определяются из соотношения [63]:
u12+ γ
u1+ γ
u12+ γ
P∗ + 2
∗
∗
P
(1
P
)
−
2N ±
2
+ 22 =
P1 , P2 =
u12+ γ
u12+ γ
N
4N
2
2
1+
1+
N
N
⎡
u12+ γ
u12+ γ ⎤
∗
∗
⎢ ∗
⎥
N
P
(1
P
)
−
2
= 2
± u1+ γ
+ 22 ⎥
⎢P +
u1+ γ + N ⎢
N
2N
4N ⎥
2
2
⎢⎣
⎥⎦
где u1+ γ — квантиль стандартного нормального распределения
2
1+ γ
, γ-доверительная вероятность, с которой доверитель2
ный интервал [ P1 , P2 ] содержит значение Р, которое неизвестно.
Пример 3.7. При проведении летных испытаний объемом N = 100
не было зафиксировано ни одного выхода определяющего параметра за допустимые границы. Таким образом, частота P∗ приняла
значение, равное 1. Найти доверительный интервал для вероятности P этого события, соответствующий доверительной вероятности
γ = 0,95.
1 + 0,95
Квантиль нормального распределения N(0,1) уровня
=
2
= 0,975 равен 1,96. Подставляя это значение в выражение, определяющее границы интервала P1 и P2 , получаем P1 = 0,963, а P2 = 1,
т.е. [0,963; 1]. Полученный интервал представляет собой реализацию случайного интервала [ P1 , P2 ] , который с доверительной вероятностью γ = 0,95 содержит неизвестную вероятность P.
Основным недостатком рассмотренной приближенной оценки,
использующей нормальную аппроксимацию биномиального распределения, является малая точность при тех значениях n, которые
характерны для большинства практических приложений. Например, при n < 100 формула пригодна лишь для грубых расчетов.
уровня
99
Более обстоятельные вычисления, связанные с биномиальным распределением, осуществляются с помощью В-распределения. В математической статистике используется формула:
n
I P (r , n − r + 1) = ∑ Cnk P k (1 − P ) n − k ,
k =r
позволяющая вычислять значения функции биномиального распределения, где I P ( a, b) — функция В-распределения (a > 0, b > 0).
Действительно:
P {μ ≤ r n, P} = ∑ P {μ = i n, P} =
r
i =0
= I1− P (n − r , r + 1) = 1 − I P ( r + 1, n − r ).
Следовательно, значения функции биномиального распределения P{μ ≤ r n, P} в целочисленных точках r = 0, 1, 2,…,n совпадают со значениями функции В — распределения I1− P ( n − r , r + 1) .
Поэтому, согласно общей теории интервальных оценок нижний
и верхний доверительные пределы для вероятности Р определяются как решения уравнений:
⎧⎪ I P (r , n − r + 1) = 1 − β
⎨
⎪⎩ I P (r + 1, n − r ) = β,
где β — заданный коэффициент доверия. При этом, если r = 0, то
P = 0 , а если r = n, то P = 1 .
Границы P и P определяют для неизвестной вероятности Р
доверительный интервал с доверительной вероятностью γ = 2β – 1.
Очевидно, что искомые значения P и P находятся как соответствующие квантили В – распределения:
P = χ 1− γ (r , n − r + 1),
2
P = χ 1+ γ (r + 1, n − r ).
2
В некоторых случаях при проведении испытаний целесообразно
фиксировать оценочный интервал вида [ PT , 1] и определять его доверительную вероятность γ. В такой постановке двусторонний ин100
тервал PT ≤ P ≤ 1 эквивалентен одностороннему PT ≤ P, коэффициент доверия γ которого определяется из уравнения
P = PT = χ 1− γ (r , n − r + 1),
откуда
или
I PT (r , n − r + 1) = 1 − γ ,
γ = 1 − I PT (r , n − r + 1) = I1− PT (n − r + 1, r ).
Для вычисления функции В-распределения, когда параметр a =
= n – r + 1 является малой величиной, что характерно для высокоточных систем, можно использовать асимптотическую формулу [14]:
I x (a, b) = 1 − P (2 y, 2a) +
μ(y, a)
,
6(2b + a − 1) 2
где P(2y, 2a) — интеграл вероятностей χ 2 , соответствующий квантили 2y и числу степеней свободы 2а,
y=
μ(y, a) =
x(2b + a − 1)
,
2− x
y a e− y
⎡⎣ 2 y 2 − (a − 1) y − (a 2 − 1) ⎤⎦ .
Γ(a)
При оценке вероятностей уровня 0,95 − 0,99 третьим слагаемым
в выражении для I x (a, b) можно пренебречь.
Тогда:
⎧ γ = 1 − P(2 y, 2a),
⎪
(1 − PT )(n + r )
⎨
, a = n − r + 1.
⎪y =
1 + PT
⎩
Как уже отмечалось, для повышения надежности получаемых
статистических выводов можно использовать информацию об определяющих параметрах на участке, непосредственно примыкающем к оцениваемой фазе полета (например, к ВПР). Тогда, определив число попаданий вектора Z в допустимую область в независимых сечениях стационарного участка можно повысить эффективный объем выборки и тем самым повысить достоверность точностных
характеристик.
101
Рассмотрим возможность построения непараметрического толерантного интервала, для которого вероятностная мера, сосредоточенная в нем, была бы не меньше, чем PT (заданная вероятностная
мера), с вероятностью γ. Однако, в отличие от рассмотренного ранее параметрического толерантного интервала, в этом случае закон
распределения определяющего параметра предполагается произвольным. Границы интервала L и U также являются случайными и
ищутся такими, чтобы выполнялось соотношение:
⎧U
⎫
Pr ⎨ ∫ f ( x)dx ≥ PT ⎬ = γ.
⎩L
⎭
Левая часть уравнения имеет значение, не зависящее от f(x), тогда и только тогда, когда L и U являются порядковыми статистиками [69]. Тогда, обозначив значения границ через порядковые статистики, а именно, L = X ( r ) и U = X ( s ) , s > r , можно записать:
{
}
Pr ⎣⎡ F ( X ( s ) ) − F ( X ( r ) ) ⎦⎤ > PT = γ.
Это выражение указывает на то, что доля распределения F(x),
сосредоточенная в интервале, образованном порядковыми статистиками, будет не менее PT с доверительной вероятностью γ.
Рассмотрим некоторую генеральную совокупность из закона
распределения F ( x). Из этой совокупности производится случайная выборка x1 , x2 , ..., xn . Предположив, что элементы выборки
взаимно независимы, определим плотность вероятности f ( r ) ( x) r-й
порядковой статистики.
Величина x(r ) занимает r-е место в вариационном ряду, т.е. в
выборке
{ x1 , x2 , ..., xn }
имеется (r − 1) величин, меньших x( r ) и
(n − r ), больших x( r ) . Найдем вероятность dF( r ) ( x) = f ( r ) ( x)dx того,
что величина x( r ) попадет в интервал ( x, x + dx). На r -м месте в
вариационном ряду может быть любая из величин xі . При этом одновременно должны быть выполнены три независимых события:
• Любая из n величин xі попадает в интервал ( x, x + dx) с вероятностью dP1 = nf ( x)dx.
• Из оставшихся n − 1 величин xі ровно r − 1 любых из них находятся в интервале (−∞, x) с вероятностью
102
P2 = Cnr−−11 F r −1 ( x) =
(n − 1)!
F r −1 ( x) .
(r − 1)!(n − r )!
• Остальные n − r величин xі располагаются на интервале
( x + dx, ∞) с вероятностью
P3 = [1 − F ( x)]n − r .
Искомая вероятность dF( r ) ( x) определяется как произведение
dF( r ) ( x) = P2 P3 dP1 = f ( r ) ( x)dx ,
откуда
f ( r ) ( x) = nCnr−−11 F r −1 ( x)[1 − F ( x)]n −1 f ( x) .
При r = 1 получаем плотность вероятностей минимальных значений в выборке
f (1) ( x) = n[1 − F ( x)]n −1 f ( x) ,
так что функция распределения определяется выражением
F(1) ( x) = 1 − [1 − F ( x)]n −1 .
При r = n получаем плотность вероятностей максимальных
значений в выборке
f ( n ) ( x) = nF n −1 ( x) f ( x) ,
так что функция распределения равна
F( n ) ( x) = F n ( x).
Как видно из полученных выражений закон распределения r-й
порядковой статистики зависит от закона распределения генеральной совокупности f ( x), ранга r статистики и объема выборки n.
После упорядочения выборки x1 , x2 , ..., xn образуется набор совершенно других случайных величин x(1) , x(2) , ..., x( n ) , существенно
отличающихся по своим свойствам от элементов xі исходной выборки. Хотя в исходной выборке величины независимы, порядковые статистики образуют набор взаимно зависимых случайных величин. Поэтому для описания набора порядковых статистик недостаточно знать только одномерные плотности распределения f ( i ) ( x),
103
так как более полные сведения о свойствах порядковых статистик
содержатся в многомерных распределениях.
В [28] показано, что плотность совместного распределения l
порядковых статистик, ранги которых представляют собой такие
целые числа, что
1 ≤ α1 < α 2 < ... < αl ≤ n ,
определяется выражением:
f ( α1 , α2 , ..., αl ) ( x( α1 ) , x( α2 ) , ..., x( αl ) =
−1
α j −α j −1 −1 l
⎡ l +1
⎤ l +1
= n !⎢ Π (α j − α j −1 − 1)!⎥ ∏ ⎡ F ( x( α j ) ) − F ( x( α j −1 ) ) ⎤
∏ f ( x( α j ) ).
⎦
j =1
⎣ j =1
⎦ j =1 ⎣
Это выражение отлично от нуля в области x(α1 ) < x(α2 ) < ... < x(αl ) ,
а вне ее равно 0. При этом α0 = 0, αl +1 = n + 1, F ( x(α0 ) ) = 0, F(x(α0 +1) ) =1.
Обозначим с целью сокращения записей Fr = F ( x( r ) ), Fs = F ( x( s ) ) .
Так как нас интересует плотность совместного распределения
только двух статистик x( r ) и x(s ) , то
f r , s ( x( r ) , x( s ) ) =
×Frr −1 [ Fs − Fs ]
n!
×
( r − 1)!( s − r − 1)!( n − s )!
s − r −1
[1 − Fs ]
n− s
f ( x( r ) ) f ( x( s ) ) .
Вводя бета-функцию, определяемую как [44]:
⎛ n + m − 1⎞
⎛ n + m − 1⎞
1
= m⎜
⎟ = n⎜
⎟=
B ( n, m )
⎝ n −1
⎠
⎝ m −1 ⎠
(n + m − 1)!
(n + m − 1)
=
=n
(m − 1)!( n + m − 1 − m + 1)!
( m − 1)!n!
получим выражение для совместного распределения Fr и Fs
Frr −1 [ Fs − Fr ]
s − r −1
dFr , s =
[1 − F5 ]
n−s
B(r , s − r ) B( s, n − s + 1)
dFr dFs .
Теперь можно получить точное распределение случайной величины F ( x( s ) ) − F ( x( r ) ) = Fs − Fr с помощью преобразования:
104
y = Fs − Fr , z = Fr ,
для которого якобиан преобразования равен единице. Тогда:
dH y , z =
z r −1 y s − r −1 (1 − y − z ) n − s
dydz , 0 ≤ y + z ≤ 1.
B (r , s − r ) B ( s, n − s + 1)
Так как область изменения z равна (0, 1 − y ), то интегрируя по
z , получаем
dF( s ) − ( r ) =
1− y
y s − r −1dy
r −1
n−s
∫ z (1 − y − z ) dz.
B (r , s − r ) B ( s, n − s + 1) 0
Положив z = (1 − y )t , получаем (с учетом того, что dz = (1 − y )dt )
dF( s ) − ( r ) =
y s − r −1 (1 − y ) n − s + r dy 1 r −1
n−s
∫ t (1 − t ) dt.
B (r , s − r ) B ( s, n − s + 1) 0
Интеграл в полученном выражении представляет собой В-функцию Эйлера
1
B (a, b) = ∫ t a −1 (1 − t )b −1 dt ,
0
так что
dF( s ) − ( r ) =
B( r , n − s + 1)
y s − r −1 (1 − y ) n − s + r dy =
B (r , s − r ) B ( s, n − s + 1)
=
y s − r −1 (1 − y ) n − s + r
dy.
B( s − r , n − s + 1 + r )
Таким образом, y = F( s ) − F( r ) имеет В-распределение первого
рода. Выражение
{
}
Pr ⎡⎣ F ( x( s ) ) − F ( x( r ) ) ⎤⎦ ≥ PT = γ
можно привести к виду
1
Pr { y ≥ PT } = ∫
PT
y s − r −1 (1 − y ) n − s + r
dy = γ.
B( s − r , n − s + 1 + r )
105
Вводя неполную В-функцию [44]
I z ( p, q ) =
z
Bz ( p, q)
1
p −1
q −1
=
∫ t (1 − t ) dt ,
B ( p, q ) B ( p, q ) 0
получаем
{
}
Pr ⎡⎣ F ( x( s ) ) − F ( x( r ) ) ⎤⎦ ≥ PT = 1 − I PT ( s − r , n − s + r + 1) = γ,
или
I PT ( s − r , n − s + r + 1) = 1 − γ.
Полученное соотношение является важным для практического
применения при оценке точности систем управления и содержит
пять величин:
• PT — вероятностная мера, сосредоточенная в толерантном интервале x ( r ) , x( s ) ,
[
]
• γ — вероятность того, что интервал ⎡⎣ x( r ) , x( s ) ⎤⎦ содержит долю распределения PT ,
• n — объем выборки,
• r и s — положения порядковых статистик в выборке.
Если заданы любые четыре из них, то можно решить полученное уравнение относительно пятой. Если PT и γ зафиксировать, а
r и s выбрать симметрично, так что s = n − r + 1, то получим выражение в виде:
I PT (n − 2r + 1, 2 r ) = 1 − γ.
Если использовать экстремальные значения выборки x(1) и x(n ) ,
то длина непараметрического толерантного интервала x( n ) − x(1) соответствует размаху выборки. В этом случае выражение
I PT (n − 1, 2) = 1 − γ
определяет вероятность γ того, что размах выборки из n измерений покрывает по меньшей мере долю PT неизвестного распределения, из которого получена выборка. При заданных n и γ можно
определить величину PT путем решения уравнения.
106
В случае, когда выборка задается своим размахом x( n ) − x(1) , полученное выражение может быть записано в более компактной
форме. Представив
I PT (n − 1, 2) = 1 − γ
в виде
PT
1
n−2
∫ y (1 − y )dy = 1 − γ ,
B(n − 1, 2) 0
вычислим интеграл:
PT
PT
PT
0
0
0
n−2
n−2
n −1
∫ y (1 − y )dy = ∫ y dy − ∫ y dy =
1
1
PTn − 2 − PTn .
n −1
n
Так как
1
n!
=2
= (n − 1)n ,
B(n − 1, 2)
(n − 2)!2!
то
1 − γ = nPTn −1 − ( n − 1) PTn .
В табл. 3.1 приведены результаты расчета вероятностной меры
PT для различных значений коэффициента доверия γ .
Таблица 3.1
n
500
1000
5000
10000
50000
100000
Доверительная вероятность
γ = 0,9
γ = 0,95
γ = 0,99
0,99226
0,99612
0,99922
0,99961
0,99992
0,99996
0,99057
0,99527
0,99905
0,99953
0,99991
0,99995
0,98682
0,99339
0,99867
0,99934
0,99987
0,99993
Рассмотрим теперь задачу нахождения доверительной области
для функции распределения, которая очень сложна и для векторных величин пока еще не решена. Для скалярных случайных величин эта задача упрощается вследствие того, что для любой непрерывной функции распределения F(x) следует утверждение:
107
{
}
P lim sup Fn ( x) − F ( x) = 0 = 1 ,
n →∞ −∞< x <∞
т.е. это соотношение показывает, что отклонение Dn эмпирической
функции распределения от теоретической на всей оси с вероятностью 1 будет сколь угодно мало при достаточно большом объеме
выборки.
Известна также теорема Колмогорова, что если функция F(x)
непрерывна, то при любом фиксированном t > 0
lim P
n →∞
{
}
∞
nDn ≤ t = K (t ) = ∑ (−1) k e −2 k
k =−∞
2t 2
∞
= 1 − 2 ∑ (−1) k +1 e−2 k
k =1
2t 2
,
где Dn = sup Fn ( x) − F ( x) .
−∞< x <∞
При этом предельную функцию К(t) можно с хорошим приближением использовать для практических расчетов уже при n > 30, а
сама функция табулирована, например в [14].
Теорему Колмогорова применяют для того, чтобы определить
границы, в которых с заданной вероятностью находится теоретическая функция распределения F(x), если она неизвестна.
Пусть для заданной вероятности γ число t γ определяется уравнением K (tγ ) = γ. Тогда из теоремы Колмогорова следует:
P
{
tγ
tγ ⎫
⎧
≤ F ( x) ≤ Fn ( x) +
nDn ≤ tγ = P ⎨ Fn ( x) −
⎬ → K (tγ ) = γ.
n
n ⎭ n →∞
⎩
}
Таким образом, при больших n с вероятностью γ значение функции F(x) для всех x удовлетворяет неравенству:
tγ
tγ
.
Fn ( x) −
≤ F ( x) ≤ Fn ( x) +
n
n
Так как 0 ≤ F ( x) ≤ 1, то эти неравенства можно записать в виде:
tγ ⎫
tγ ⎫
⎧
⎧
max ⎨0, Fn ( x) −
, 1⎬ .
⎬ ≤ F ( x) ≤ min ⎨ Fn ( x) +
n⎭
n ⎭
⎩
⎩
Область, определяемая этими границами, называется асимптотической γ-доверительной зоной для теоретической функции распределения.
108
Пример 3.8. Пусть имеется оценка функции распределения
Fn ( z ), полученная по выборке объемом n = 100. Требуется найти
доверительную область для F(z) с доверительной вероятностью γ = 0,95.
По соответствующей таблице функции распределения Колмогорова определяем квантиль tγ = 1,362 , и, следовательно, величину
tγ
= 0,1362.
n
Для построения доверительной области необходимо сдвинуть
на величину 0,1362 вверх и вниз полученную эмпирическую функцию распределения Fn ( z ), имея ввиду, что 0 ≤ F ( z ) ≤ 1, рис. 3.4.
Fвz)
F*(z)
Fн(z)
z
Рис. 3.4. График неизвестной F(z) с вероятностью γ = 0,95
полностью заключен внутри этой области
Из рис. 3.4 видно, что полученные экспериментальные данные
могут соответствовать большому разнообразию кривых распределения. Здесь необходимо обратить внимание на тот факт, что аппроксимация полученного эмпирического распределения может
быть проведена с высокой степенью точности (можно, например,
учесть даже неожиданные скачки) с помощью широкого класса
модельных распределений. Однако попытка применить полученный модельный закон к другой выборке (извлеченной из той же
самой генеральной совокупности, задаваемой, например, серией
статистических испытаний) может оказаться неудовлетворительной. Следовательно, для этой выборки необходима другая модель,
а значит и само моделирование теряет смысл, так как главное назначение модели — распространение закономерностей, подмеченных в выборке, на всю генеральную совокупность, что и является
основой задачи оценки соответствия системы управления заданным требованиям.
109
Правильно подобранная аппроксимирующая кривая остается
устойчивой, инвариантной по отношению к смене выборки, т.е. она
одинаково хорошо может описывать характер распределения, наблюдаемого в разных выборках из одной и той же генеральной совокупности.
Рассмотрим возможность использования характеристик выбросов [39, 68], которые дают не только количественную информацию,
но и наглядное представление о точности процесса стабилизации
(например, при оценке вероятности нахождения бокового отклонения самолета в «трубке» ± 8,2 м при автоматизированном разбеге).
Такой подход может использовать функционал траектории реализации случайного процесса, который описывает поведение системы на анализируемом участке стабилизации. Числовые характеристики такого экстремального функционала как случайной величины можно назвать экстремальными показателями точности
системы управления. Одним из таких функционалов является показатель τ ∑ , определяющий суммарную длительность превышения
процессом Z(t) допустимой области при t ∈ T.
Если допустимая область является симметричной, т.е. D[l, u] =
= D[− u, u], то определив индикаторную функцию как
⎧⎪1, z (t ) > u ,
I u (t ) = ⎨
⎪⎩0, z (t ) ≤ u ,
можно записать, что
P{I u (t ) = 1} = P Z (t ) > u .
{
}
Определим математическое ожидание процесса I u (t ) :
M { I u (t )} = P {Z (t ) > u } ⋅ 1 + P {Z (t ) ≤ u } ⋅ 0 =
= P { I u (t ) = 1} ⋅ 1 + P { I u (t ) = 0} ⋅ 0 =
= P {I u (t ) = 1} = P {Z (t ) > u } .
Вводя относительное время пребывания процесса Z(t) над уровτ
нем u как ∑ , можно определить вероятность нахождения Z(t) в
T
допустимой области как математическое ожидание функционала
1
⎧τ ⎫
P {Z (t ) ∈ D} = 1 − M ⎨ ∑ ⎬ = 1 − M {τ ∑ }.
T
⎩T ⎭
110
Оценка вероятности выхода определяющего параметра за допустимую область по результатам испытаний равна:
Q∗ =
1 n 1 k
∑ ∑ τij ,
n i =1 Ti j =1
где k — количество выбросов за допустимый уровень в одной реализации z(t).
Очевидно, что оценка Q∗ представляет собой среднее время
пребывания реализацией z(t) выше уровня, полученное по результатам испытаний. Для каждой реализации ее время пребывания над
уровнем ⎟ u⎟ является случайной величиной
k
τ i = ∑ τ ij , i = 1, n ,
j =1
оценка дисперсии которой равна:
sτ2 =
1 n
(τi − Q ∗)2 .
∑
n − 1 i =1
Верхняя граница для вероятности Q выхода определяющего параметра за допустимую область по результатам n испытаний определяется в соответствии с выражением:
Q = Q ∗ +t γ (n − 1)
sτ
,
n
где t γ ( n − 1)-квантиль распределения Стьюдента уровня γ с (n – 1)
степенями свободы, γ-доверительная вероятность. Очевидно, что
нижняя граница вероятности нахождения определяющего параметра в «трубке» равна P = 1 − Q.
Для получения информации о потенциальных возможностях
системы управления можно определить оценку средней площади
выбросов определяющего параметра за допустимую область.
3.4. Байесовское статистическое оценивание
Информационная сущность обработки результатов испытаний
становится до конца понятной в рамках статистической теории, в
которой получаемая информация определяется разностью энтропий [9] распределений вероятностей априорных и апостериорных
111
(после испытаний) суждений о возможности системы. Тем самым
признается случайность суждений, которая является прямым следствием случайности измерений. Если информации, содержащейся в
экспериментальном материале, оказывается недостаточно, то необходимо либо уменьшить желаемую детальность суждений об объекте управления, что равносильно требованию меньшего количества полезной информации, либо увеличить информативность экспериментального материала, привлекая комплексирование методов и
учитывая дополнительную априорную информацию, получаемую
из независимого эксперимента.
Априорная информация — один из факторов, обусловливающих
эффективность измерения (обработки): при ее отсутствии измерение невозможно, при наличии в максимальном объеме (известном
значении оцениваемой характеристики) — ненужно. Априорная
информация определяет достижимую точность измерений и их эффективность. Хотя использование априорной информации при обработке данных является затруднительным (поскольку она с трудом поддается формальному описанию), однако ее полезность и
необходимость не вызывает сомнений. Впрочем, «априорная опасность», возникающая из — за отсутствия априорных данных о статистических характеристиках случайных факторов в важных инженерных задачах, часто преувеличивается, так как исследователь на
основании накопленного опыта в проектировании и испытании
аналогичных систем управления уверенно оценивает максимальные случайные ошибки, максимальные случайные возмущения,
максимальные разбросы начальных условий, максимальные интервалы корреляции и, пользуясь в соответствии с неравенством Чебышева правилом «2σ» или «3σ», без значительных погрешностей
может назначать первые два момента случайных величин и корреляционные функции случайных процессов, входящих в описание
математической модели системы управления; известный закон
больших чисел обычно позволяет без значительной идеализации
считать первичные случайные величины нормально распределенными. Эти соображения, конечно, не исключают необходимости
исследования чувствительности получаемых результатов к вариации априорных статистических характеристик.
Основная идея байесовского подхода состоит в использовании
при оценке некоторого параметра θ информации как от полученной
выборки {z1 , z2 , ..., zn } , так и априорной информации об оцениваемом параметре. Предполагается, что параметр θ является случай112
ной величиной (в отличие от классического подхода, где параметр
θ является неизвестной постоянной) и имеет некоторую известную
исследователю априорную плотность распределения h(θ).
Априорные вероятности отражают сведения об оцениваемом
параметре, полученные путем обобщения экспериментов (как натурных, так и моделирования), предшествующих данному.
С помощью формулы Байеса [27, 64] можно получить условную
апостериорную плотность распределения f ( θ z1 , z2 , ..., zn ) параметра θ после наблюдения выборки, которая задается условной плотностью распределения при данном θ, называемой функцией правдоподобия f ( z1, z2 , ..., zn θ) . Выражение для апостериорной плотности
имеет вид:
f ( θ z1 , z2 , ..., zn ) =
f ( z1 , z2 , ..., zn θ )
g ( z1 , z2 , ..., zn )
h(θ) ,
где g ( z1 , z2 , ..., zn ) — нормирующая константа, не зависящая от θ и
определяемая выражением
g ( z z , z2 , ..., zn ) = ∫ f ( z z , z2 , ..., zn θ ) h(θ)dθ.
Θ
Очень часто байесовский подход имеет следующий физический
смысл. Если выборочные данные поступают в два этапа, то в случае их объединения теорема Байеса дает апостериорную оценку
параметра с использованием этих данных. Однако, если данные поступают последовательно, например данные {zi }1 поступают раньше {zi }2 , то представляет интерес проанализировать объект управления в свете данных {zi }1 , а затем пересмотреть полученные
результаты в свете {zi }2 , рис. 3.5. Такую последовательность действий иногда называют эмпирической байесовской процедурой.
Сущность байесовского подхода: данные не создают представлений, они скорее видоизменяют существующие представления.
В результате появления новых наблюдений происходит сближение
априорного распределения с функцией правдоподобия, которые
отражают представления инженеров. Это движение в направлении
согласования становится еще более заметным, когда увеличивается
объем выборки.
113
Априорная
информация f(θ)
Данные
{ zi }1
Байесовское оценивание
Апостериорная
оценка параметра
f ( θ z1 , ..., zn )
Данные
{ zi } 2
Априорная информация
Байесовское оценивание
Рис. 3.5. Эмпирическая байесовская процедура
Затруднения, которые могут возникать при использовании байесовского подхода, всецело касаются исходной постановки задачи:
когда параметр можно считать значением случайной величины с
известной априорной плотностью.
В большинстве практических случаев априорные вероятности
допустимо считать медленно меняющимися функциями состояния
объекта по сравнению с аналогичными зависимостями для функций правдоподобия.
Используя апостериорную плотность f ( θ z1 , ..., zn ) , можно определить точечную оценку параметра как среднее значение, вычисленное по апостериорному распределению:
θ∗ ( z1 , ..., zn ) = ∫ θf ( θ z1 , ..., zn )dθ .
Θ
Вычислительная реализуемость байесовской процедуры оценивания в значительной степени зависит от сложности математического описания выбираемой функции потерь. Апостериорное математическое ожидание минимизирует средний риск при квадра-
тичной функции потерь W (θ∗ , θ) = ( θ∗ − θ ) [27]. Минимальный сред2
ний риск при этом равен дисперсии оцениваемого параметра θ.
Необходимо отметить, что оценка θ∗ при n → ∞ сходится к оценке максимального правдоподобия независимо от выбора априорной
плотности h(θ).
114
Как правило, априорную плотность выбирают таким образом,
чтобы апостериорная плотность имела такой же функциональный
вид, отличаясь только значениями параметров в зависимости от поступивших выборочных данных. Семейство таких априорных плотностей называется сопряженным [64]. Например, если функция
правдоподобия имеет биномиальное распределение, то сопряженным априорным распределением является β-распределение (B-распределение). В результате применения теоремы Байеса апостериорное распределение также будет β -распределением.
Рассмотрим возможность применения байесовского подхода к
определению оценок вероятностных характеристик определяющих
параметров, имеющих нормальное распределение.
Пусть получена выборка из нормального распределения с пара1
метрами ( m, σ 2 ) или (m, r), где r = 2 — параметр точности.
σ
Функция правдоподобия выборки (плотность вероятности выборки)
определяется как совместное распределение выборочных значений:
n
n n
⎧ ( z − m) 2
⎡ 1 ⎤2
f ( z1 , ..., zn m, r ) = ∏ f ( zi m, r ) = ⎢ ⎥ r 2 ∏ exp ⎨− i
2
i =1
i =1
⎣ 2π ⎦
⎩
n
⎫
r⎬ =
⎭
n
n
⎡ 1 ⎤2
⎧ r n
⎫
= ⎢ ⎥ r 2 exp ⎨− ∑ ( zi − m) 2 ⎬ .
⎣ 2π ⎦
⎩ 2 i =1
⎭
Представим выражение для суммы следующим образом:
n
n
∑ ( zi − m)2 = ∑ zi2 − 2mzn + nm 2 =
i =1
n
2
i =1
n
2
(
= ∑ zi2 − 2 z n + 2 z n − 2mzn + nm 2 = ∑ zi − z
i =1
i =1
)
2
(
)
2
+n z−m .
Тогда функция правдоподобия может быть записана в виде:
n
n
2⎫
2⎫
⎡ 1 ⎤2
⎧ r n
⎧ nr
f ( z1 , ..., zn m, r ) = ⎢ ⎥ r 2 exp ⎨− ∑ zi − z ⎬ × exp ⎨−
z − m ⎬.
⎣ 2π ⎦
⎩ 2 i =1
⎭
⎩ 2
⎭
(
)
(
)
Проведенная факторизация показывает, что функция правдоподобия зависит от результатов наблюдений величин z1 , ..., zn только
115
(
)
2
через z и ∑ zi − z . Это значит, что каждый из сомножителей зависит только от выборочных значений.
В качестве априорного распределения целесообразно выбрать
нормальное — гамма распределение из сопряженного семейства
двумерных распределений [27].
В этом случае априорная плотность математического ожидания —
нормальная:
1
⎡ τr ⎤ 2
⎧ τr
⎫
h(m) = ⎢ ⎥ exp ⎨− ( m − μ) 2 ⎬
⎣ 2π ⎦
⎩ 2
⎭
со средним μ и мерой точности τr, а априорная плотность распределения меры точности есть гамма — распределение с параметрами α и β [64]:
β α α −1
h( r ) =
r exp(−βr ).
Γ(α)
Совместная априорная плотность имеет вид:
h(m, r ) = h(m)h(r ) =
1
2
1
α
⎡ τ ⎤ β
⎧ τr
⎫
=⎢ ⎥
r 2 r α −1 exp ⎨− (m − μ) 2 ⎬ exp(−βr ).
⎣ 2π ⎦ Γ(α)
⎩ 2
⎭
Апостериорная плотность в соответствии с теоремой Байеса
пропорциональна произведению априорной плотности распределения и функции правдоподобия:
f ( m, r z1 , ..., zn ) ∝ f ( z1 , ..., zn m, r ) h(m, r ),
где символ ∝ — знак пропорциональности.
Тогда можно записать:
f ( m, r z1 , ..., zn ) ∝
n
2
(
)
(
)
2⎫
2⎫
⎧ r n
⎧ nr
∝ r exp ⎨− ∑ zi − z ⎬ exp ⎨−
z − m ⎬×
⎩ 2 i =1
⎭
⎩ 2
⎭
1
⎧ τr
⎫
× r 2 r α −1 exp ⎨− ( m − μ) 2 ⎬ exp(−βr ).
⎩ 2
⎭
116
После преобразований можно записать выражение для апостериорной плотности с точностью до постоянного множителя:
1
⎧ τ/
⎫ /
f ( m, r z1 , ..., zn ) ∝ r 2 exp ⎨− (m − μ / ) 2 ⎬ r α −1 exp(−β / r ) ,
⎩ 2
⎭
Для дальнейших рассуждений примем квадратичную функцию
потерь, что позволяет записать простые выражения для байесовских
оценок среднего z и меры точности R∗ , а также их дисперсии:
∞ ∞
z=
∫ ∫ mf ( z1 ,..., zn m, r ) dmdr
−∞ 0
∞ ∞
∫ ∫ f ( z1 ,..., zn m, r ) dmdr
,
−∞ 0
∞ ∞
σ 2z =
2
∫ ∫ m f ( z1 ,..., zn m, r ) dmdr
−∞ 0
∞ ∞
∫ ∫ f ( z1 ,..., zn m, r ) dmdr
2
− z ,
−∞ 0
∞ ∞
∗
R =
∫ ∫ rf ( z1 ,..., zn m, r ) dmdr
−∞ 0
∞ ∞
∫ ∫ f ( z1 ,..., zn m, r ) dmdr
,
−∞ 0
∞ ∞
σ R∗ =
2
2
∫ ∫ r f ( z1 ,..., zn m, r ) dmdr
−∞ 0
∞ ∞
∫ ∫ f ( z1 ,..., zn m, r ) dmdr
− ( R∗ )2 .
−∞ 0
Рассмотрим эмпирическую байесовскую процедуру.
Пример 3.9. Пусть к началу государственных летных испытаний известна некоторая априорная информация, так что в качестве
априорного распределения из семейства сопряженных распределений выбрано нормальное — гамма распределение. При этом известно, что:
M{M} = μ = 2,1; D{M} = 1,0; M{R} = r = 2,0; D{R} = 1,6.
Тогда параметры априорного распределения выбираются следующим образом.
117
Так как параметр точности R имеет гамма-распределение
h( r ) =
β α α −1
r exp(−βr ),
Γ(α)
то его математическое ожидание и дисперсия равны [27]:
α
α
M {r} = ,
D{r} = 2 ,
β
β
откуда определяются параметры априорного распределения для
меры точности: α = 2,5; β = 1,25.
Если совместная плотность вероятности параметров M и R —
нормальное — гамма распределение, то условное распределение
M для любого заданного значения R = r будет нормальным, но маргинальное распределение M не будет нормальным, а определяется
соотношением:
∞
hM (m) = ∫ h(m, r )dr.
0
Поэтому, воспользовавшись символом пропорциональности, можно опустить все множители, не содержащие m, и получить выражение:
или
τ
⎡
⎤
hM (m) ∝ ⎢β + (m − μ) 2 ⎥
2
⎣
⎦
−
2α +1
2
⎡
1 ατ(m − μ) 2 ⎤
hM (m) ∝ ⎢1 +
⎥
β
⎣ 2α
⎦
−
,
2α +1
2
,
Сравнивая это выражение с плотностью распределения Стьюдента, получаем, что маргинальное распределение M имеет t - распределение с 2α степенями свободы, параметром сдвига μ и мерой
α
ατ
,
. Так как для исходного t — распределения D{X } =
точности
α−2
β
то для рассматриваемого случая
D{M } =
откуда следует (для D{M } =
2α
α
=
,
2α − 2 α − 1
β
β
= 1 ), что τ =
= 0,833.
ατ
α −1
118
Таким образом, параметры априорного распределения определены:
μ = 2,1; τ = 0,833; α = 2,5; β = 1,25.
Пусть после первого испытательного полета извлечена выборка
из 50 наблюдений, такая, что
z = 2,8;
∑ ( zi − z ) = 12,6.
50
2
i =1
Тогда параметры апостериорного распределения будут равны:
μ/ =
τμ + nz
= 2,79; τ / = τ + n = 50,833;
τ+n
n
α / = α + = 27,5;
2
(
1 n
β = β + ∑ zi − z
2 i =1
/
)
2
+
(
τn z − μ
)
2
2(τ + n)
= 7,75
Апостериорные средние и дисперсии параметров M и R соответственно равны:
β/
M {M } = μ / = 2,79; D{M } = / /
= 0,00575;
τ (α − 1)
M {R} =
α/
= 3,55;
β/
D{R} =
α/
(β )
/ 2
= 0, 458.
Пусть после второго испытательного полета получена выборка
объемом n = 50 из данного нормального распределения, причем
z = 3,1;
∑ ( zi − z ) = 9, 4.
n
2
i =1
Рассматривая предыдущие апостериорные распределения среднего и меры точности в качестве априорных распределений для полученных новых наблюдений, рассчитываем параметры вновь полученного апостериорного распределения M и R :
μ // = 2,94; τ // = 100,833; α // = 52,5; β // = 13,66.
В результате средние и дисперсии параметров M и R будут равны:
M{M} = 2,94; D{M} = 0,00263; M{R} = 3,84; D{R} = 0,281.
119
Поскольку распределение M имеет теперь 2α // = 105 степеней своτ // α //
боды, параметр сдвига μ // = 2,94 и меру точности
= 387,597,
β //
то можно достаточно точно оценить доверительным интервалом
значение математического ожидания:
⎧⎪
⎫⎪
τ // α //
//
μ
P ⎨−tγ,n ≤
m
−
≤
t
γ,n ⎬ = γ ,
β //
⎩⎪
⎭⎪
(
)
где tγ, n — квантиль t — распределения уровня γ с n степенями свободы.
Для рассматриваемого примера при γ = 0,99 и n = 2α = 105 имеем:
P {−2,624 ≤ (m − 2,94) ≤ 2,624} = 0,99,
откуда с вероятностью γ = 0,99 среднее значение находится в интервале 2,806 ≤ m ≤ 3,074.
Аналогичные рассуждения можно провести и для вновь поступающей информации.
Эмпирическую байесовскую процедуру можно проводить и на
этапе эксплуатационного контроля при наличии соответствующей
информационной базы с целью контроля за некоторыми точностными характеристиками на последовательных временных интервалах. Можно использовать один из статистических критериев для
оценки возможного их тренда [55].
3.5. Последовательное оценивание
С точки зрения интервального оценивания точность может быть
выражена через длину интервала с заданной доверительной вероятностью. Утверждения, которые следуют из метода доверительных интервалов, являются утверждениями типа: вероятность того,
что полученные доверительные пределы (которые могут меняться
от выборки к выборке) заключают между собой значение параметра θ, соответствующее фактической выборке, равняется 1 – α [47].
Пусть имеется последовательность независимых испытаний,
каждое из которых заключается в извлечении выборки объемом n
значений из совокупности с плотностью f(z; θ). По каждому множеству выборочных значений вычисляются значения пределов
120
(
)
(
)
c1 = c1 θ∗ , α и c2 = c2 θ∗ , α , используя заранее заданное значение
α. В различных испытаниях c1 и c2 будут иметь различные значения, т.е., извлекая еще одну выборку, мы, вообще говоря, можем
получить и более длинный интервал. Каждое испытание считается
успешным, если интервал ( c1 , c2 ) покрывает соответствующую
точку θ, и неудачным в обратном случае. Вероятность успеха постоянно равна 1 – α, т.е.
P{c1 < θ < c2 } = 1 − α,
и, следовательно, успехов в данной последовательности испытаний
будет с точностью, определяемой случайными колебаниями, равняться 1 – α.
Следует отметить, что заданному α соответствует не единственная система доверительных интервалов. Так же, как можно брать
различные оценки для одного и того же параметра θ, можно рассматривать различные системы доверительных интервалов, приводящие к различным правилам действий, связанным с одним и тем
же риском ошибки.
Например, при оценке среднего значения m нормальной совокупности с известной дисперсией σ 2 доверительный интервал определяется выражением:
σ
σ
z−
uP < m < z +
uP , P = 1 − α ,
n
n
σ
u P , где uP — квантиль станn
дартного нормального распределения N(0, 1).
Таким образом, правило, заключающееся в том, что как только
выборка фактически получена, неизвестное среднее m заключено
между указанными пределами, дает постоянный риск ошибки, равный α.
С другой стороны, предположим, что рассматривается неэффективная оценка среднего med(z) — медиана выборки, которая асимпто⎛
π ⎞
kσ ⎞
π
⎛
, где k =
= 1, 253.
тически нормальна N ⎜⎜ m, σ
⎟⎟ = N ⎜ m,
⎟
2n ⎠
2
n⎠
⎝
⎝
Предположим, что n велико и аппроксимацией можно пренебречь,
так что пределы c1 и c2 равны z ±
121
т.е. распределение med(z) нормальное. Тогда доверительный интервал может быть записан в виде:
med {z} −
kσ
n
uP < m < med {z} +
kσ
n
uP ,
для которого риск ошибки α такой же, как и для интервала, рассмотренного выше на основе оценки z . Однако очевидно, что первое правило всегда дает более короткий интервал, чем второе.
Таким образом, можно сделать вывод, что длина доверительного интервала сама является случайной величиной и в каждом частном случае может оказаться большой. Однако известно, что нельзя
построить доверительный интервал заранее фиксированной длины,
если дисперсия σ 2 неизвестна и дана только одна выборка [80].
Задача построения доверительного интервала с заранее фиксированной длиной может быть решена с помощью последовательного выбора (двухшаговая процедура Стейна [84]).
Сначала извлекается выборка {z1 , z2 , ..., zm } фиксированного
объема m, по которой определяется оценка дисперсии
s2 =
(
1 m
∑ zi − z
m − 1 i =1
)
2
.
Обозначим через n (n > m) такой объем выборки, для которого
выполняется условие:
s2 c2
≤ ,
n b2
m −1
— дисперсия распределегде с — заданная константа , b =
m−3
ния Стьюдента с (m – 1) степенями свободы, поскольку
(
n z −μ
а значит
σ
) ∝ N (0,1),
(
(m − 1) 2
s ∝ χ 2 (m − 1),
2
σ
)
n z −μ
∝ t (m − 1) .
s
После извлечения второй выборки объемом (n – m) определяется
оценка среднего значения по результатам всех измерений:
122
1 n
∑ zi ,
n i =1
z=
где z — несмещенная оценка среднего μ со среднеквадратическим
отклонением меньшим с. Действительно:
(
)
(
(
)
)
⎧n z − μ 2 2 ⎫
⎧n z − μ 2 2 ⎫
s ⎪
c ⎪
⎪
⎪
M z −μ = M ⎨
⋅ ⎬≤ M ⎨
⋅ 2⎬=
2
2
s
n⎪
s
b ⎪
⎪
⎪
⎩
⎭
⎩
⎭
2
⎧
⎫
c2 ⎪ n z − μ ⎪ c2 2
2
= 2M⎨
⎬= 2 b =c .
2
b
s
b
⎪
⎪
⎩
⎭
Пусть заданная длина доверительного интервала для параметра
μ равна 2l, т.е. c1 = μ − l , а c2 = μ + l. Тогда при выборе
bl
c= ,
tα
{(
)}
2
2
α
где t α (m −1) квантиль уровня
распределения Стьюдента с (m – 1)
2
2
степенями свободы, доверительная вероятность будет не меньше
1 – α:
⎧
⎫
⎧ n z −μ
⎫
n ⎪
b ⎪
⎪
⎪ n z −μ
<
< l ⎬.
P z −μ < l = P⎨
l⎬ ≥ P ⎨
s ⎪
c ⎪
s
s
⎪⎩
⎪
⎭
⎩
⎭
{
Если
}
(
(
)
)
b
bl
l = t α или c = , то
c
tα
2
2
(
)
⎧ n z −μ
⎫
bl ⎪
⎪
< ⎬ = 1 − α.
P⎨
s
c⎪
⎪
⎩
⎭
Таким образом, двухвыборочная процедура для построения интервальной оценки среднего заданной длины полностью определяется для любого фиксированного объема первой выборки. Отме123
тим, что в рассмотренной процедуре не используется информация
о параметре σ 2 , которая имеется во второй выборке.
Пример 3.10. Требуется получить фиксированную длину доверительного интервала для среднего значения некоторого определяющего параметра, равную 2l = 0,2, с доверительной вероятностью γ = 1 – α = 0,95.
Назначив фиксированный объем первой выборки, например,
m = 50, определяем оценку дисперсии, равную s 2 = 0,5. Поскольку
дисперсия случайной величины, подчиняющейся t — распределению с (m – 1) степенями свободы, равна:
b=
m −1
= 1,0425,
m−3
то постоянная с соответственно равна:
c=
bl
= 0,052.
t α (m − 1)
2
Теперь определяем величину объема полной выборки n, необходимую для построения интервальной оценки:
n=
b2 s 2
≈ 200.
c2
Таким образом, вторая (дополнительная) выборка должна иметь
объем n – m = 150 измерений.
Допустим, что после извлечения этих выборок, получена оценка
среднего, равная:
z (200) =
z (50) ⋅ 50 + z (150) ⋅ 150
= 1, 25.
200
Тогда доверительный интервал, покрывающий истинное значение среднего, имеет заданную длину, такую, что:
P{1,15 < m < 1,35} = 0,95.
124
4
ОЦЕНКА СООТВЕТСТВИЯ
ТОЧНОСТНЫХ
ХАРАКТЕРИСТИК ЗАДАННЫМ
ТРЕБОВАНИЯМ
4.1. Основные требования и проверка гипотез
Обеспечение требуемого уровня безопасности полетов самолетов гражданской авиации в условиях сниженных минимумов посадки определяет постановку проблемы создания как методов оценки
точности бортовых систем управления, так и методов оценки соответствия этих систем заданным требованиям, которые должны
быть составной частью процесса сертификации самолета. Полученные в результате различного вида испытаний и моделирования
точностные характеристики являются основой для принятия решения о степени соответствия.
В соответствии с нормативными требованиями точность автоматического захода на посадку, автоматического приземления, пробега и разбега определяется значениями вероятностных характеристик распределения определяющих параметров на высоте принятия
решения, в точке касания, в момент отрыва самолета от ВПП,
при движении по ВПП в процессе разбега и пробега.
Выбор определяющих параметров, определение их допустимых
значений или областей зависит от этапа полета. Соответственно задаются и вероятности возникновения ситуаций, приводящих к усложнению условий полета. Так в Британских нормах летной годности гражданских самолетов используются следующие оценки повторяемости событий, отнесенные к одному полету:
• частые события с вероятностью возникновения более 10−3 ;
• умеренно-вероятные события с вероятностью возникновения
−3
10 ÷ 10−5 ;
• маловероятные события с вероятностью возникновения
−5
10 ÷ 10−7 ;
• крайне маловероятные события с вероятностью возникновения меньше 10−7 ÷ 10−8 ;
125
• практически невероятные события с вероятностью возникновения 10−9.
Уровень безопасности полета определяется вероятностью того, что
в полете не возникнут аварийная или катастрофическая ситуации.
Практически используют в качестве численного критерия обратную величину – вероятность возникновения соответствующих
ситуаций. Так, допустимыми значениями вероятностей, отнесенными к одному полету, являются для аварийной ситуации 10−6 , для
катастрофической ситуации 10−9 .
Для установления уровня безопасности на различных этапах
полета разработаны и разрабатываются нормативные требования
на определяющие параметры, непосредственно или косвенно связанные с условиями обеспечения достаточного уровня безопасности. Как уже отмечалось, успешность любого этапа полета (например, посадки) определяется вероятностью нахождения случайного вектора-функции внутри области допустимых отклонений
[10, 12]. Размеры области зависят от ограничений на координаты
вектора.
В табл. 4.1–4.3 представлены систематизированные требования
к точности автоматического управления с использованием бортовых систем в наиболее критических режимах полета, определяемые
из условия обеспечения безопасности полета различными нормативными документами ICAO, США, России, Англии и Франции
[1–8].
Определяющими параметрами являются отклонения самолета
от равносигнальных линий курса и глиссады, скорость движения,
боковое и продольное отклонения от номинальной точки касания,
вертикальная скорость, углы крепа, скольжения и тангажа в точке
касания, боковое отклонение самолета от оси ВПП в процессе пробега и разбега, скорость самолета в момент отрыва.
В основном, требования к точностным характеристикам задаются по каждому определяющему параметру в отдельности и представляют собой вероятностные характеристики положения (математические ожидания) и рассеяния (дисперсии), а также вероятностную меру распределения, которая должна быть сосредоточена
в допустимой области, границы которой заданы.
В общем случае требуемые численные значения точностных характеристик для различных режимов полета зависят от типа самолета и его летно-технических данных.
126
Таблица 4.1
Автоматический заход на посадку
Определяющий
параметр
Допустимая
область
Вероятностная
мера
Отклонение от линии курса с Н = 90 м до ВПР
[–20; 20] мкА
0,95
Отклонение от линии
глиссады с Н = 90 м
до ВПР
[–50; 50] мкА
0,95
Примечание
Автоматическое приземление
Продольное отклонение
от порога ВПП
[60; 870] м
1 − 2 ⋅ 10−6
Боковое отклонение от
оси ВПП
[–21; 21] м
1 − 2 ⋅ 10−6
Вертикальная скорость
Vy < 4
Угол крена
[–7,5; 7,5] град.
Vz < 17
Боковая скорость
Угол тангажа
м
с
м
с
[0,5; 7,5] град.
1 − 10−6
σ L < 90 м
mном = 450 м
σ z < 4,1 м
mном = 0 м
σ < 0, 2
м
с
1 − 10−8
1 − 10−6
1 − 10−6
σ < 1°
Таблица 4.2
Автоматизированный разбег
Определяющий
параметр
Допустимая
область
Вероятностная
мера
Продольная скорость в момент принятия
решения
Vg > Vgпр
1 − 10 −4
Пройденная дистанция в момент принятия
решения
X g < Lпр
1 − 10 −4
Продольная скорость в момент отрыва от ВПП
Vg > Vgотр мин
1 − 10 −4
Пройденная дистанция в момент отрыва
от ВПП
X g < Lпр
1 − 10−6
127
Окончание табл. 4.2
Автоматизированный разбег
Определяющий
параметр
Допустимая
область
Вероятностная
мера
Боковое отклонение от оси ВПП за время
разбега
[–5; 5] м
0,95
Боковое отклонение от оси ВПП за время
разбега
[–21; 21] м
1 − 10−6
Боковое отклонение от оси ВПП при отказе двигателя
[–9; 9] м
0,95
Угол тангажа в момент отрыва
ϑ < ϑотр пр
1 − 10−6
Таблица 4.3
Автоматический пробег
Пройденная дистанция до момента остановки
X g < Lрпд −
Боковое отклонение от оси ВПП
[–8,2; 8,2] м
0,95
Боковое отклонение от оси ВПП
[–21; 21]
1 − 10−6
Lрпд
1 − 10−6
1,67
Совокупность экспериментальных работ, направленных на определение соответствия фактических точностных характеристик
заданным требованиям, включающая летные испытания и необходимые виды моделирования, образует систему целенаправленных
этапов испытаний. Конечным результатом их должен быть анализ
фактически достигнутых точностных характеристик данного типа
самолета, оборудованного конкретной системой управления, обеспечивающей режимы автоматического захода на посадку и посадки, а также интегральная оценка соответствия этих характеристик
заданным требованиям.
Принципиально ограниченные возможности летных испытаний,
исключающие достижение необходимого объема эксперимента,
широкое варьирование параметров системы управления, а также
воспроизведение граничных режимов функционирования объекта,
предопределяют значимость модельных экспериментов на специальных моделирующих стендах с использованием реальных узлов
128
системы управления, а также статистического моделирования поведения объекта в широком спектре возмущающих воздействий.
Так как оценка соответствия точностных характеристик заданным требованиям проводится на основе проверки соответствующих статистических гипотез, то рассмотрим основные положения
этой теории [51].
Пусть получена некоторая оценка θ∗ параметра θ, которая является случайной величиной с выборочным распределением f (θ∗ ).
Если принять, что значение параметра θ = θ 0 , то необходимо
определить при каком отклонении θ∗ − θ 0 нулевая гипотеза H0 :θ = θ0
отвергается.
Если распределения f (θ∗ ) известно, то можно определить вероятность такого отклонения. В случае малого значения вероятности такого отклонения разность следует считать значимой и гипотезу H 0 необходимо отклонить. Если же вероятность отклонения
θ∗ − θ 0 велика, то гипотеза H 0 принимается, что может быть объяснено выборочной изменчивостью оценки θ∗ . Приведенные соображения закладываются в основу статистической процедуры, называемой проверкой статистических гипотез.
Таким образом, если гипотеза H 0 верна, то распределение f (θ∗ )
имеет среднее значение, равное θ 0 . Если определить доверительную вероятность γ как
⎪⎧
⎪⎫
P ⎨θ1− γ < θ < θ1+ γ ⎬ = γ,
⎪⎩ 2
2 ⎪
⎭
то вероятность 1 – γ = α называется критерием значимости. Тогда
вероятность того, что θ∗ окажется меньше нижней границы
θ1− γ = θ α , определяется соотношением:
2
2
θα
⎧⎪
⎫⎪ 2
α
P ⎨θ∗ < θ α ⎬ = ∫ f (θ∗ )dθ∗ = ,
2
⎪ −∞
2⎭
⎩⎪
а вероятность превышения верхней границы θ1+ γ = θ
2
венно равна:
129
1−
α
2
соответст-
θ
1−
α
2
⎧⎪
⎫⎪
⎧⎪
⎫⎪
α
P ⎨θ∗ > θ α ⎬ = 1 − P ⎨θ∗ < θ α ⎬ = 1 − ∫ f (θ∗ )dθ∗ = .
1−
1−
2
−∞
⎪
⎪
2⎭
2⎭
⎩⎪
⎩⎪
Таким образом, вероятность того, что параметр окажется вне
интервала ⎡θ α ; θ α ⎤ равна α, рис. 4.1, а.
⎣⎢ 2 1− 2 ⎦⎥
Область
принятия
f(θ*)
Область
отклонения
Область
отклонения
α/2
α/2
1–α
θα/2
θ0
θ1 – α/2
θ
a
Область
принятия
f(θ*)
θα
θ0
θ
б
Рис. 4.1. Общая схема проверки двусторонней (а)
и односторонней (б) гипотез
Область значений θ∗ , при которых гипотеза отклоняется, называется критической, а область, для которой гипотеза H 0 не отвергается, называется областью принятия гипотезы.
Двусторонний критерий проверки гипотезы заключается в следующем: при достаточно малом уровне значимости критерия α, если оценка θ∗ оказалась вне интервала, то гипотеза θ = θ 0 должна
быть отклонена, поскольку такое значение маловероятно; если же
значение θ∗ попадает в интервал, то нет сомнения в истинности
130
гипотезы θ = θ 0 . При двустороннем критерии проверяется значимость отклонений от θ 0 в обе стороны.
В некоторых случаях используются односторонние критерии.
Например, при проверке гипотезы θ ≤ θ 0 используется только нижняя граница рис. 4.1, б. В этом случае:
{
}
θα
P θ∗ ≤ θ α = ∫ f (θ∗ )dθ∗ = α.
−∞
Очевидно, что для гипотезы H 0 : θ ≥ θ 0 справедливо равенство:
{
}
θα
P θ∗ ≥ θ α = 1 − ∫ f (θ∗ )dθ∗ = α.
−∞
Результаты проверки любой статистической гипотезы нужно
интерпретировать следующим образом: если приняли гипотезу H1
(альтернативную), то можно считать ее доказанной, а если приняли
гипотезу H 0 , то признали, что гипотеза не противоречит результатам наблюдений. Однако этим свойством наряду с H 0 могут обладать и другие гипотезы. Например, если мы принимаем гипотезу
H 0 : m = 5, то может случиться, что по данной выборке можно принять и другие гипотезы, например, H 0 : m = 5,5 или H 0 : m = 4 и
т.д. Следует помнить, что принимая гипотезу H 0 , необходимо
проводить еще дополнительные испытания. Вот почему при проверке гипотезы H 0 , как правило, используется не один критерий, а
несколько, как параметрических, так и непараметрических.
При проверке гипотез определяют ошибки первого рода: гипотеза отклоняется, когда на самом деле она верна; ошибки второго
рода: гипотеза принимается, хотя фактически она неверна, рис. 4.2.
Рис. 4.2. Определение ошибок первого и второго рода
131
Из рис. 4.2 видно, что ошибка первого рода состоится в том случае, когда при справедливости гипотезы θ = θ 0 оценка θ∗ попадет в
критическую область, т.е. вероятность ошибки первого рода равна
уровню значимости критерия α.
Для того, чтобы определить вероятность ошибки второго рода β
необходимо задать альтернативное значение параметра θ1 и определить конкурирующую гипотезу H1 : θ = θ1 или H1 : θ = θ 0 ± δ. Допустим, что истинное значение параметра равно θ = θ 0 + δ. Если
гипотеза состоит в том, что θ = θ 0 , тогда как на самом деле она
равна θ 0 + δ, то вероятность того, что θ∗ попадет в область приня-
(
тия гипотезы θ α , θ
2
1−
α
2
) , равна β, т.е. ошибке второго рода.
Вероятность π = 1 − β называют мощностью критерия. Очевидно, что при заданном объеме выборки n вероятность β уменьшается
за счет уменьшения уровня значимости критерия. Единственный
способ одновременного уменьшения значений α и β состоит в увеличении объема испытаний.
Случайная величина, определенная по некоторому правилу на
основании выборочных данных, называется статистикой критерия
(наблюденное значение статистики критерия).
Точка, которая отделяет критическую область от области принятия решения, называется критической точкой. Если статистика
критерия принадлежит критической области, то гипотеза отвергается, если же она принадлежит области принятия, то гипотеза принимается.
Рациональный принцип выбора критической области можно
сформулировать следующим образом: при заданном объеме испытаний n устанавливается граница для вероятности ошибки первого
рода и при этом выбирается та критическая область, для которой
вероятность ошибки второго рода минимальна.
В конкретных задачах выбор уровня значимости до некоторой
степени произволен и связан с практической стороной вопроса.
Так, часто ошибочное принятие или отбрасывание гипотезы H 0
связано с материальными затратами. Если принятие гипотезы H 0 в
то время, когда она не верна (ошибка второго рода), приводит к
большим затратам, тогда как отклонение истинной гипотезы H 0
(ошибка первого рода) приводит к небольшим потерям, то ясно,
132
что желательно сделать как можно меньшей вероятность ошибки
второго рода, допуская сравнительно большие значения α. Обычно
для α выбирают одно из следующих стандартных значений: 0,005;
0,01; 0,05; для этих значений рассчитывают соответствующие таблицы, используемые при проведении испытаний.
В заключение обратим внимание на практическую неизбежность проявления двух «невыгодных» для всей теории проверки
статистических гипотез эффектов: эффекта слишком малого объема выборки и эффекта слишком большого объема выборки.
Эффект слишком малого объема выборки состоит в том, что при
заданной величине уровня значимости критерия α и малом числе
наблюдений n, на основании которых принимается решение, мощность критерия, т.е. вероятность отклонить проверяемую нулевую
гипотезу H 0 в ситуации, когда она в действительности не имеет
места, оказывается слишком маленькой.
Известно, что в достаточно широком классе случаев при различении близких простых гипотез, т.е. при малых значениях расстояния ρ = ρ(H 0 , H1 ) между гипотезами H 0 и H1 , определяемого по
формуле:
f ( X ; θ1 )
ρ( H 0 , H1 ) = ∫ ln
⎡ f ( X ; θ1 ) − f ( X ; θ 0 ) ⎤⎦ dX ,
f X; θ ⎣
(
0
)
справедливо приближенное соотношение
(u
n(α; β; ρ) ≈
1− α
+ u1−β )
ρ(H 0 , H1 )
2
,
где u — соответствующий квантиль стандартного нормального распределения.
Есть два выхода из этой ситуации: либо увеличить объем выборки n, либо несколько увеличить уровень значимости α, что повлечет соответствующее уменьшение β, т.е. увеличение мощности
критерия. С другой стороны огромная выборка почти наверняка
(т.е. с вероятностью, стремящейся к единице при неограниченном
возрастании n ) отвергает в этом случае нулевую гипотезу при любом заданном уровне значимости α.
Казалось бы, налицо тупиковая ситуация: при малых выборках
вывод статистически ненадежен, а при слишком больших — однозначно предопределен. Чтобы избежать эффекта большой выборки,
133
априорное задание характеристик точности критерия (значения α и β)
необходимо увязывать с объемом имеющихся данных: выигрыш в
чувствительности критерия, получающийся в результате увеличения n, целесообразно использовать для уменьшения как α, так и β.
4.2. Оценка соответствия точностных характеристик
заданным требованиям
В некоторых фазах полета самолета требуемые вероятности нахождения определяющих параметров в допустимой области устанавливаются в пределах 0,95 ÷ 0,99 с доверительной вероятностью
γ = 0,9 ÷ 0,95. В этом случае оценка соответствия точностных характеристик, полученных в летных испытаниях, заданным требованиям может быть проведена путем построения допустимых и доверительных областей.
Для скалярного параметра, как правило, устанавливаются соответствующие допустимые границы. Например, для высоты принятия решения могут быть заданы ограничения для отклонений самолета от
равносигнальных линий курса и глиссады ± a и ±b соответственно.
Если определяющий параметр имеет нормальное распределение, то по заданной вероятностной мере PT интервала допустимых
отклонений D[–a, a] или D[–b, b] однозначно определяется допустимая параметрическая область такая, что
( m, σ ) ∈ S → P{D} ≥ P .
2
T
Граница области S определяется методом последовательных
приближений из уравнения [37, 38]:
где
⎛a−m⎞
⎛ −a − m ⎞
Φ⎜
⎟ − Φ⎜
⎟ = PT ,
⎝ σ ⎠
⎝ σ ⎠
Φ( z ) =
1
z
∫e
−
t2
2
dt.
2π −∞
Область S является теоретической, соответствующей бесконечно большему объему испытаний (n → ∞) и может быть построена
как в абсолютных единицах (в координатах m, σ), так и в относи⎛m σ⎞
тельных единицах ⎜ , ⎟ .
⎝ a a⎠
134
На рис. 4.3 показаны области S для различных вероятностей
PT = 0,95; 0,98; 0,99 при условии, что границы допустимой области
симметричны относительно нуля.
σσ
aa
0.51
0.43
SS(P
( PтT ==0,95)
0 , 95 )
SS(P
( PтT ==0,98)
0 , 98 )
0.39
SS(P
( PтT ==0,99)
0 , 99 )
m
aa
mm
−−
aa
-1,0
–1,0
-0,5
–0,5
0,5
0,5
1,0
1,0
Рис. 4.3. Допустимая параметрическая область
При конечных объемах испытаний n можно построить γ-доверительную область Ω γ (n) (см. раздел 3.3) для оценок z , s 2 . Если
выполняется условие, что доверительная область принадлежит допустимой, то доля P распределения определяющего параметра, сосредоточенная в интервале [−a, a] больше или равна требуемой, т.е.
( z , s ) ∈ Ω ( n) ⊂ S → P ( D ) ≥ P
2
γ
T
с заданным уровнем значимости α. Это, в свою очередь означает,
что система управления обеспечивает точностные характеристики,
удовлетворяющие заданным требованиям по этому определяющему параметру, рис. 4.4.
Рис. 4.4. Допустимая и доверительная параметрические области
135
Построение доверительной области Ω γ (n) может быть выполнено с помощью как доверительных, так и толерантных пределов.
Рассмотрим способ построения Ω γ (n) как решение обратной
задачи методом последовательных приближений: определяются оценки z , s 2 при заданных значениях Р, γ и фиксированном объеме n
через вычисленные толерантные множители (см. раздел 3.3.):
1
n ,
2
χ γ (n − 1)
n−
k = u1+ P
2
в результате чего определяются границы γ-доверительно области.
На рис. 4.5. показаны γ-доверительные области, построенные
для различных значений PT = 0,95; 0,98, доверительной вероятности γ = 0,9 и различных объемов испытаний n.
s
a
0,48
Ω( Pт = 0,95, γ = 0,9)
n = 200
n = 100
n = 80
0,44
n = 50
n = 30
0,4
z
a
1,0
s
a
0,4
Ω( Pт = 0,98, γ = 0,9)
n = 200
n = 100
0,38
n = 80
n = 50
n = 30
0,35
z
a
1,0
Рис. 4.5. Доверительные параметрические области
для различных объемов испытаний и значений Р
136
Оценка соответствия точностных характеристик заданным требованиям может быть проведена непараметрическим методом по
известной в результате испытаний частоте попадания определяющего параметра в интервал допустимых отклонений [–a, a]. Критерий основан на нормальной аппроксимации биномиального закона
распределения. В этом случае при заданном уровне значимости
проверяется нулевая гипотеза H 0 : P = PT о равенстве неизвестной
вероятности Р значению вероятности PT , заданной нормативными
требованиями при конкурирующей гипотезе H1 : P < PT .
Для проверки гипотезы рассчитывается наблюденное значение
статистики критерия:
T=
P∗ − PT
n
PT (1 − PT )
,
а по таблице стандартного нормального распределения N(0, 1) находится критическое значение статистики из соотношения:
Φ (Tкр ) = 1 − α,
так как критическая область является левосторонней.
В случае выполнения неравенства
T > −Tкр
нет оснований отвергнуть нулевую гипотезу, что, в свою очередь,
говорит о том, что бортовая система управления соответствует заданным требованиям по точности для рассматриваемого определяющего параметра (или вектора параметров) в контролируемой
фазе полета. Рассмотренный критерий обеспечивает заданный уровень значимости при достаточно большом объеме испытаний, определяемом из неравенства [16]:
nPT (1 − PT ) > 9.
Пример 4.1. После проведения испытаний (200 испытательных
полетов) не было зафиксировано ни одного выхода самолета за
пределы «прямоугольного окна», образованного на высоте принятия решения максимально допустимыми значениями отклонений
самолета от равносигнальных линий курса и глиссады. На уровне
значимости α = 0,05 проверить нулевую гипотезу H 0 : P = PT = 0,95
при конкурирующей гипотезе H1 : P < PT .
137
Значение наблюденной статистики критерия равно:
T=
(1 − 0,95) 200
= 3, 24
0,95(1 − 0,95)
а значение Tкр при Φ (Tкр ) = 0,95 равно 1,645.
Так как T > Tкр , то нет оснований отвергать нулевую гипотезу.
Необходимо отметить, что точность оценки вероятности повышается пропорционально n .
Для определения вероятности ошибки второго рода β (мощности критерия π) необходимо определить вероятность того, что при
справедливости альтернативной гипотезы случайная величина P∗
примет значение из критического множества.
Тогда, обозначив через P1 ( P1 < PT ) альтернативное значение вероятности, можно записать:
⎡ P − P1
π( P1 ) = 1 − β = 1 − Φ ⎢ T
n + uα
⎣⎢ P1 (1 − P1 )
PT (1 − PT ) ⎤
⎥=
P1 (1 − P1 ) ⎦⎥
⎡⎛
⎞ P (1 − PT ) ⎤
PT − P1
= Φ ⎢ ⎜ uα +
n⎟ T
⎥.
⎟ P (1 − P ) ⎥
P1 (1 − P1 )
⎢⎣⎜⎝
1 ⎦
⎠ 1
Для рассмотренного выше примера при конкурирующей гипотезе
P1 = 0,9 < PT получаем мощность вывода, равную:
⎡⎛
0,05
⎞ 0, 218 ⎤
π( P1 ) = Φ ⎢⎜ −1,645 +
14,14 ⎟
⎥ = Φ (1,16) = 0,88.
0, 218
⎠ 0,3 ⎦
⎣⎝
Рассмотрим алгоритмы оценки соответствия системы управления заданным требованиям по боковому и продольному каналам
при автоматическом приземлении.
На рис. 4.6 а, б показаны гистограммы бокового и продольного
отклонений самолета BOEING 767 в точке касания, полученные в
результате моделирования 1500 автоматических посадок [82]. Нормальность распределения подтверждается на уровне ±3σ.
138
а
б
Рис. 4.6. Гистограммы бокового и продольного
отклонений самолета в точке касания
В предположении нормальности распределения отклонений определяющих параметров приземления, достаточными статистиками
являются оценки математических ожиданий и дисперсий. Тогда
оценка соответствия системы управления заданным требованиям
139
может быть проведена с помощью статистических гипотез относительно указанных оценок как по результатам летных испытаний,
так и по результатам статистического моделирования.
Боковой канал. В соответствии с требованиями, предъявляемыми к точности системы управления в точке касания, необходимо
оценить смещение приземлений (отсутствие или наличие смещения, возможность допустимого смещения) и допустимый разброс
боковых отклонений ( σ z = 4,1 м без учета погрешностей РТС посадки при ширине полосы 45м ).
Будем считать, что уровень значимости критерия α, мощность
критерия π = 1 − β и необходимый объем испытаний (любого вида)
согласованы. Тогда требуемые уровни значимостей α m , α σ и значение мощностей π m , π σ могут быть определены как:
αm =
α
β
; π m = πσ = 1 − .
2
2
Требуется проверить гипотезу о среднеквадратическом отклонении H 0 : σ ≤ σ0 против альтернативы H1 : σ > σ1 где, σ1 = 4,1 м,
σ0 — некоторое «приемочное» значение, такое что σ0 < σ1 . Значение параметра разброса σ1 = 4,1 м является предельно допустимым, при котором вероятностная мера боковых отклонений, сосредоточенная в допустимой области D = ± 21 м от оси ВПП (с
учетом размеров основного шасси), равна PT = 0,999999 = 0,96 в
соответствии с заданными требованиями, т.е. вероятность превышения допустимых границ не более 10−6.
Очевидно, что при проверке гипотеза H 0 при σ0 → σ1 с заданными вероятностями ошибок α σ и βσ необходимый объем испытаний n → ∞. Чем меньше разница между σ0 и σ1 , тем выше
мощность критерия и тем больше необходимый объем испытаний.
Поэтому, до проведения испытаний (любого вида) необходимо
указать значение нулевой гипотезы σ 0 , которая при реальном объеме испытаний обеспечит заданную мощность вывода.
При заданных σ1 , уровнях ошибок α и β значение σ0 можно
определить при помощи интеграла вероятностей χ 2 в соответствии
с выражением
140
⎧⎪
Cкр σ02 ⎫⎪
Pr ⎨χ 2 >
⎬ = 1 − β,
σ12 ⎭⎪
⎩⎪
где Cкр = χ 2 (α σ , n − 1) определяется как квантиль χ 2 -распределения уровня α с n − 1 степенями свободы. Функция распределения
χ 2 определяется выражением
{
}
Fn ( x) = P χ n2 < x ,
а интеграл вероятностей χ 2 связан с функцией распределения соотношением:
{
}
Pn ( x) = 1 − Fn ( x) = χ 2n > x .
В [14] приведены значения Pn ( x) для различных значений n.
В табл. 4.4 приведены значения σ 0 , рассчитанные для разных
уровней α σ = βσ и объемов испытаний.
Таблица 4.4
«Приемочное» значение σ 0 z для бокового отклонения
Риски
α
0,05
0,025
0,01
0,005
Объемы испытаний
β
50
100
150
200
300
500
1000
1500
0,95
2,94
3,24
3,39
3,47
3,58
3,69
3,81
3,86
0,975
2,84
3,17
3,32
3,42
3,53
3,65
3,78
3,84
0,995
2,64
3,01
3,19
3,31
3,44
3,58
3,73
3,79
0,95
2,86
3,18
3,33
3,42
3,54
3,66
3,78
3,84
0,975
2,76
3,1
3,27
3,37
3,49
3,62
3,76
3,82
0,995
2,57
2,95
3,14
3,26
3,4
3,55
3,7
3,77
0,95
2,77
3,1
3,27
3,37
3,49
3,62
3,75
3,81
0,975
2,67
3,03
3,32
3,21
3,44
3,58
3,73
3,79
0,995
2,48
2,88
3,08
3,2
3,35
3,51
3,67
3,75
0,95
2,71
3,06
3,22
3,33
3,46
3,59
3,73
3,8
0,975
2,62
2,98
3,16
3,27
3,41
3,55
3,71
3,78
0,995
2,43
2,84
3,04
3,16
3,32
3,48
3,65
3,73
141
Наблюденное значение статистики критерия определяется соотношением
Cσ =
(n − 1) s 2
,
σ02
где s 2 — оценка дисперсии боковых отклонений, полученная в эксперименте. Очевидно, что при C0 < Cкр гипотеза H 0 не отвергается, т.е разброс отклонений точки приземления не превышает допустимого значения.
Далее необходимо проверить гипотезу об отсутствии смещения
приземлений в боковом канале H 0 : m = 0 против альтернативы
H 0 : m > m1 . Если значения возможных альтернатив параметра в
явном виде не указаны, то они могут быть определены следующим
образом. При отсутствии смещения (m = 0) и среднеквадратическом отклонении, равном предельному значению σ = 4,1 м, расчетная вероятностная мера распределения однозначно определяет
долю PT = 0,96 , сосредоточенную в допустимой области D = ± 21 м.
С появлением смещения приземлений для сохранения неизменной
доли PT в указанной области допустимое значение σ должно быть
уменьшено. При этом каждому значению параметра смещения m
соответствует единственное значение σ, при котором доля распределения в области D равна PT . Множество значений (m, σ) образует допустимую параметрическую область S (m, σ). Граница области S (m, σ) определяется решением уравнения:
⎛u−m⎞
⎛l−m⎞
Φ⎜
⎟ − Φ⎜
⎟ = PT = 0,96
⎝ σ ⎠
⎝ σ ⎠
методом последовательных приближений, где Φ (•) определяется
как:
Φ (•) =
1
(•)
−
t2
2
∫ e dt.
2π −∞
Область S (m, σ) для бокового канала показана на рис. 4.7.
142
4
σ 0Z , м
2
S (m + , σ )
0
4
8
12
16
20
m +1 , м
Рис. 4.7. Допустимая параметрическая область
для бокового отклонения
Наблюденное значение статистики критерия определяется соотношением
m* − 0
Cm =
n.
σ0
Критическое значение Cкр (α m ) определяется как квантиль уровня
1 − αm
распределения N (0, 1). При Cm ≤ Cкр гипотеза H 0 не от2
вергается на уровне значимости α m . При Cm > Cкр делается вывод
о наличии смещения приземлений. Для определения мощности
критерия πm/ необходимо по значению σ0 из графика допустимой
области S (m, σ) определить альтернативное значение m1. Тогда
πm/ = 1 − ⎡⎣Φ (uкр − δ) + Φ (uкр + δ) ⎤⎦
где
δ=
m1 − 0
n.
σ0
Если πm/ < πm , то необходимо увеличить объем испытаний или
уменьшить заданную мощность вывода.
При наличии систематического смещения приземлений (при условии σ < σ0 ) необходимо определить критическое значение mкр
для проверки гипотезы о допустимом значении смещения. Критическое значение определяется методом последовательных приближений из уравнения
143
⎛ mкр − m1
⎞
⎛ − mкр − m1
⎞
Φ⎜
n ⎟ − Φ⎜
n ⎟ = βm .
σ0
⎝ σ0
⎠
⎝
⎠
*
При m < mкр на уровне значимости α m с заданной мощностью
πm делается вывод, что смещение приземлений находится в допустимых пределах. При заданных α m и βm допустимая величина
смещения m доп определяется из уравнения:
⎛ mкр − mдоп
⎞
⎛ − mкр − mдоп
⎞
Φ⎜
n ⎟ − Φ⎜
n ⎟ = 1 − αm .
σ0
σ0
⎝
⎠
⎝
⎠
Необходимо отметить, что при оценке точности в линейных единицах необходимо учитывать при косвенных измерениях возможный разброс положения курсовой линии относительно оси ВПП,
создаваемый наземными РТС посадки.
Продольный канал. Оценка соответствия системы управления
заданным требованиям в продольном канале может быть проведена
аналогично боковому каналу. В этом случае альтернативное значения σ1L = 84 м, а «приемочноё» значение σ0 L выбирается в зависимости от объема испытаний и уровня ошибок α и β из табл. 4.5.
Таблица 4.5
«Приемочное» значение σ0 L для продольного отклонения
Риски
α
Объемы испытаний
β
50
100
150
200
300
500
1000
1500
0,05
0,95
0,975
0,995
80,7
77,9
72,4
89,1
86,9
82,8
93,0
91,2
87,7
95,4
93,8
90,7
98,3
97,0
94,4
101,4
100,3
98,3
104,5
103,8
102,3
105,9
105,3
104,1
0,025
0,95
0,975
0,995
78,5
75,7
70,4
87,2
85,1
81,1
91,4
89,6
86,2
94,0
92,4
89,4
97,1
95,8
93,3
100,4
99,4
97,3
103,8
103,1
101,6
105,3
104,7
103,5
0,01
0,95
0,975
0,995
76,0
73,3
68,2
85,2
83,2
79,2
89,6
87,9
84,5
93,4
90,8
87,9
95,8
94,5
92,0
99,3
98,3
96,3
103
102,2
100,8
104,7
104,0
102,8
0,005
0,95
0,975
0,995
74,4
71,8
66,7
83,9
81,8
78,0
88,5
86,7
83,4
91,3
89,8
86,9
94,9
93,6
91,1
98,5
97,5
95,6
102,4
101,7
100,2
104,2
103,6
104,2
144
Альтернативное значение математического ожидания распределения продольных отклонений в точке касания m1L необходимо
определить по значению σ0 L из графика допустимой параметрической области S (mL , σ L ), рис. 4.8.
Необходимо отметить, что значение σ1L = 84м соответствует
тому, что вероятностная мера распределения продольных отклонений в допустимой области D = [ 60, 870] м (при m = 450 м), определяемой нормативными документами, в точности равна заданному
значению PT = 0,958, если закон распределения нормальный.
90
σ0L,м
60
30
0
150
300
S (m , σ)
450
600
750
900
m 1, м
Рис. 4.8. Допустимая область для продольного отклонения
Если для определяющих параметров нормативными документами задается вероятностная мера на допустимую область их отклонений (например углы крена и тангажа в точке касания, боковое
отклонение при разбеге и пробеге и некоторые другие), то методика оценки соответствия может быть построена следующим образом.
По заданной вероятностной мере PT может быть построена до-
(
)
пустимая область S в пространстве параметров m, σ 2 такая, что
Ω ⊂ S (m, σ ) ⇒ P { D} ≥ PT ,
2
где Ω = Ω(m* , s 2 ) — доверительная область на параметры ( m, σ 2 ),
построенная по экспериментальным данным в соответствии с уравнением [61]:
⎧ (n − 1) s 2
uσ
uσ ⎫
(n − 1) s 2 ⎫
⎧
Pr ⎨ m* −
< m < m* +
<
σ
<
⎬ ⋅ Pr ⎨
⎬ = γ,
2
χ12 ⎭
n
n⎭
⎩
⎩ χ2
145
где γ -доверительная вероятность, u -квантиль нормального рас1+ γ
, χ12 и χ 22 квантили χ 2 -распределения
2
1− γ
1+ γ
уровней
и
соответственно, рис. 4.4.
2
2
Тогда задача проверки статистической гипотезы H 0 : P ≥ PT
против альтернативы H1 : P < PT сводится к проверке гипотезы
H 0 : Ω ⊂ S против альтернативы H1 : Ω ⊄ S при заданных вероятностях ошибок α и β .
На первом этапе статистика стандартного критерия проверки
гипотезы H 0σ : σ 2 ≤ σ02 против альтернативы H1σ : σ > σ02 при мешающем параметре (−∞ < m < ∞) используется для определения
точного значения параметра σ02 , которое при заданном уровне значимости α σ и полученной в результате испытаний выборке измерений приводит к принятию (отклонению) нулевой гипотезы H 0σ о
дисперсии генеральной совокупности .
Полученное значение параметра σ02 используется для определения интервала допустимых значений для среднего I m = [ m1 , m2 ] .
Границы интервала получаются из уравнения
пределения уровня
⎛u−m⎞
⎛l−m⎞
Φ⎜
⎟ − Φ⎜
⎟ = PT .
⎝ σ ⎠
⎝ σ ⎠
Для симметрического относительно нуля интервала допустимых
значений следует, что m2 = − m1 .
Следующий этап состоит в применении обычной процедуры
проверки сложной гипотезы относительно оставшегося параметра.
При фиксированном уровне значимости α m производится проверка
гипотезы о среднем значении H 0m : m ∈ [ m1 , m2 ] против альтернативы H1m : m ∉ [ m1 , m2 ].
Отметим, что принятая процедура обеспечивает уровень значимости α соответствующего критерия гипотезы H 0 : Ω ⊂ S , не превышающий суммы уровней α m и α σ критериев проверки гипотез о
среднем и дисперсии соответственно[66]:
146
α ≤ αm + ασ .
Аналогичное соотношение следует и для ошибки второго рода
β ≤ βm + βσ ,
откуда
π ≥ 1 − (βm + βσ ).
Пример 4.2. Пусть по результатам n = 50 испытаний получены
оценки точностных характеристик бокового отклонения самолета
при автоматическом пробеге m* = 1, 2 м; s 2 = 5 м 2 при условии, что
процесс бокового отклонения является стационарным и учтены
корреляционные связи между измерениями случайного процесса).
Требуется при заданном уровне значимости α = 0,05 проверить двухпараметрическую гипотезу H0 : Ω ⊂ S против альтернативы H1 : Ω⊄ S.
В соответствии с изложенной процедурой определяем значение
σ02 , которое при уровне значимости α σ = 0,025 и полученной выборке приводит к принятию гипотезы H 0σ : σ 2 ≤ σ02 .
Тогда из
(n − 1) s 2
,
Cσ <
σ02
где Cσ = χ 2 (α σ , n − 1) = 70, 22, определяем что σ02 = 3, 49 м.
Вероятность ошибки второго рода βσ для некоторого альтернативного значения σ12 определяется соотношением
∞
βσ = 1 − ∫ χ 2 n −1 ( x)dx,
σ2
C0 0
σ12
где соответствующий интеграл есть интеграл вероятностей χ 2 [14].
Например, при σ12 = 8м 2 получаем β σ = 0,05 .
Интервал допустимых значений среднего при σ 02 = 3,49м определяем методом последовательных приближений (для случая автоматического пробега PT = 0,95 при допустимых границах u = 8, 2 м
и l = −8, 2 м ):
⎛ 8, 2 − m ⎞
⎛ −8, 2 − m ⎞
Φ⎜
− Φ⎜
⎟
⎟ = 0,95,
⎝ 3, 49 ⎠
⎝ 3, 49 ⎠
147
откуда
I m = [−2, 42; 2, 42]м = [ m1 , m2 ].
Далее необходимо провести проверку сложной гипотезы H 0m :
m1 ≤ m ≤ m2 против альтернативы H 0m : m ∉ [ m1 , m2 ] при уровне значимости α m .
Полагая, что σ 2 = σ02 можно принять критерий, основанный на
нормальном распределении (при любой из гипотез H 0m или H1m
оценка m* имеет нормальное распределение). Границы области
принятия нулевой гипотезы [ a1 , a2 ] на заданном уровне значимости α m определяются из уравнения:
⎡ a − m1
⎤
⎡ a − m1
⎤
Pr a1 < m* < a2 m = m1 = Φ ⎢ 2
n⎥ −Φ⎢ 1
n ⎥ = 1 − αm
⎣ σ0
⎦
⎣ σ0
⎦
{
}
или
⎡ a − m2
⎤
⎡ a − m2
⎤
Pr a1 < m* < a2 m = m2 = Φ ⎢ 2
n⎥ −Φ⎢ 1
n ⎥ = 1 − αm .
⎣ σ0
⎦
⎣ σ0
⎦
{
}
При естественном требовании симметрии критических областей
(рис. 4.9):
⎡ a − m2
⎤
⎡ a − m1
⎤
n ⎥ =1− Φ ⎢ 1
n⎥
Φ⎢ 2
⎣ σ0
⎦
⎣ σ0
⎦
границы критической области определяется из уравнения:
⎡ a − m1
⎤
⎡ a − m2 ⎤
Φ⎢ 1
n ⎥ + Φ⎢ 1
⎥ = αm ,
⎣ σ0
⎦
⎣ σ0 ⎦
при этом a2 = − a1 = a.
Решение уравнения определяет границы области принятия, которые являются критическими для оценки m *. При m * > a нулевая гипотеза H 0m отвергается на уровне значимости α m .
148
Рис. 4.9. Границы области принятия гипотезы
Для рассматриваемого примера
⎤
⎡ a − 2,42
⎤
⎡ a − (−2,42)
50 ⎥ + Φ ⎢ 1
50 ⎥ = 0,025 ,
Φ⎢ 1
3,49
⎦
⎣ 3,49
⎦
⎣
откуда критическая область равна
[ a1 , a2 ] = [ −3,39; 3,39] ì .
Поскольку m* = 1, 2 ∈ [ −3,39; 3,39] , то нет оснований отвергать
нулевую гипотезу. При этом вероятность ошибки второго рода
{
βm = Pr m* ∈ [ − a; a ] H1m
}
и при любой альтернативе mh ∈ H 1m
⎡ a − mh
⎤
⎡ − a − mh
⎤
βm = Pr {− a < m* < a m = mh } = Φ ⎢
n⎥ −Φ⎢
n⎥ .
⎣ σ0
⎦
⎣ σ0
⎦
Так, например, при mh = 4,2 м получаем βm ≈ 0,05.
Таким образом, если σ02 = σ
2
2
( σ — нижняя граница довери-
тельного интервала для σ , т.е. σ < σ 2 < σ2 ) и выполняется условие m* ∈ [ a; − a ] , то с вероятностями ошибок α ≤ α m + α σ и
β ≤ βm + βσ выполняется условие
2
Ω(m*, s 2 ) ⊂ S ( m, σ2 ) ⇒ P { D} ≥ PT ,
и система удовлетворяет заданным требованиям.
149
Непараметрическая оценка зоны приземления. Соотношение
для непараметрического толерантного интервала
⎧⎪ x( s )
⎫⎪
Pr ⎨ ∫ dF ( x) ≥ PT ⎬ = γ
⎪⎩ x( r )
⎪⎭
запишем в виде
Pr {Yμ ≥ PT } = 1 − I P (μ, ν) = γ ,
где Yμ = F ( x( s ) ) − F ( x( r ) ), μ — число выборочных блоков вариационного ряда, лежащих между порядковыми статистиками x( r ) и
x( s ) , ν — число исключенных выборочных блоков, лежащих вне
толерантного интервала ⎡⎣ x( r ) , x( s ) ⎤⎦ [69].
Если оценка точности проводится совместно по k ≤ m коордиG
натам случайного вектора z ( z1 , z2 , ..., zm ) , то на основании выборочных данных можно построить k -мерную независимую от распределения толерантную область. С доверительной вероятностью
γ вероятностная мера такой области, отвечающая многомерной
функции распределения F ( z1 , z2 , ..., zm ) , не менее P. В общем случае k -мерная выборка объема n > k может быть упорядочена в
виде пространственного вариационного ряда, а выборочное пространство разбито на (n + 1) непересекающихся блоков, заполняющих все пространство k -мерных выборочных блоков. Тогда при любом правиле выбора μ таких блоков, образующих многомерную
толерантную область, полученное ранее соотношение между PT , μ, n, γ
для одномерного толерантного интервала полностью переносится
на многомерный случай.
Область допустимых значений D m задается в виде m -мерного
параллелепипеда. Если толерантная область строится по размаху
выборочных данных, то отбрасывается ν = 2k первых k -мерных
выборочных блоков. Тогда с доверительной вероятностью ν по
крайней мере доля PT будущих наблюдений генеральной совокупности с неизвестной функцией распределения попадет в область,
ограниченную экспериментальными выборочными значениями.
Соотношение для вероятностей PT и γ в этом случае имеет вид
150
Pr {Yμ ≥ PT } = 1 − I PT (n + 1 − 2k , 2k ) = γ.
При использовании экстремальных значений k = 2. После определения по экспериментальным данным размахов бокового и продольного отклонений в точке касания
WL = Lmax − Lmin ,
WZ = Z max − Z min
толерантная область может быть построена в виде прямоугольника, расположенного на ВПП (рис. 4.10), вероятностная мера которого определяется из решения уравнения относительно PT :
1 − I PT (n − 3, 4) = γ .
Рис. 4.10. Толерантная область для бокового
и продольного отклонений на ВПП
В табл. 4.6 приведены результаты расчета вероятностной меры
Р в зависимости от объема выборочных данных для различных значений доверительной вероятности γ.
Рассмотрим теперь алгоритм оценки соответствия вертикальной
скорости в точке касания заданным требованиям.
Предварительный анализ результатов летных испытаний и статистического моделирования указывает на нестационарность этого
параметра, так что его статистические оценки должны определяться по множеству реализаций. Что касается вида распределения вертикальной скорости, то оно достаточно близко к логарифмически
нормальному, функция распределения которого равна:
151
F (Vy ) =
ln V y
1
2πσ
∫
e
−
( t − ln a )2
2 σ2
dt ,
0
где a, σ — параметры положения и масштаба (дисперсии) соответственно.
Таблица 4.6
Объем
испытаний
n
Вероятностная мера Р
γ = 0,9
γ = 0,95
γ = 0б99
50
100
200
500
1000
10000
0,8713
0,9344
0,9669
0,9867
0,99338
0,999332
0,8524
0,9244
0,9617
0,98454
0,99227
0,999226
0,813
0,9036
0,95097
0,98018
0,990056
0,9999002
На рис. 4.11 показана гистограмма вертикальной скорости при
посадке по результатам моделирования автоматической посадки
самолета BOEING 767 (1500 реализаций). Очевидно, что распределение вертикальной скорости относится к типу логарифмически
нормального распределения.
Рис. 4.11. Гистограмма распределения вертикальной скорости
в точке касания
152
Если принять, что Y = ln Vy , то случайная величина Y распределена по нормальному закону N (m, σ 2 ) .Для совокупности независимых одинаково распределенных случайных величин Vy1 , Vy2 , ..., Vyn ,
имеющих логарифмически нормальное распределение, достаточными статистиками являются
(
)
2
1 n
1 n
ln Vyi , s 2 =
ln Vyi − Y
∑
∑
n i =1
n − 1 i =1
как оценки среднего и дисперсии величины Y.
Известно, что первый и второй моменты логарифмически нормального распределения равны [9, 16]:
Y=
⎧
σ2 ⎫
m1 = exp ⎨ a + ⎬ , m2 = exp 2a + σ 2 exp σ 2 − 1 ,
2⎭
⎩
где а и σ есть параметры случайной величины ξ, подчиняющейся
логарифмически нормальному закону. Тогда приближенно несмещенными оценками математического ожидания и дисперсии для
V y являются
{
}{ ( ) }
1 ⎫
⎧
V y = exp ⎨Y + s 2 ⎬ ,
2 ⎭
⎩
2
2
sVy = exp 2Y + s exp( s 2 ) − 1 .
{
}{
}
Так как случайная величина Y распределена нормально, то для
оценки точностных характеристик можно использовать процедуру
толерантного оценивания. В требованиях, как правило, указывается, что вероятность приземления с максимально допустимой на
конструкцию самолета скоростью снижения Vyдоп не должна превышать значение QT = 10−8. Такая постановка соответствует задаче
одностороннего толерантного оценивания и в данном случае – задаче определения верхнего толерантного предела:
U = Y + ku s ,
при этом
⎪⎧ ⎛ Y + ku s − m ⎞
⎪⎫
P ⎨Φ ⎜⎜
⎟⎟ > PT ⎬ = γ .
σ
⎠
⎩⎪ ⎝
⎭⎪
153
После определения значения толерантного множителя
k=
lnU − Y
s
рассчитывается квантиль стандартного нормального распределения
(по аналогии с боковым каналом, рассмотренным выше):
k
.
uP =
1
N−
N
χ 2γ ( N − 1)
По найденному значению квантиля определяется вероятностная
мера случайной величины Y в заданном допуске ⎡⎣ 0,ln Vyдоп = ln U ⎤⎦
с заданной доверительной вероятностью γ. В случае, если PY ≥ PT ,
делается вывод о соответствии вероятностных характеристик вертикальной скорости заданным требованиям.
Пример 4.3. По результатам двух испытательных полетов (N = 20)
были зафиксированы значения вертикальной скорости (далее используются значения Vy ) в точке касания:
Vy
1,7
1,3
1,4
1,6
1,2
1,0
1,1
0,9
1,6
1,4
Y
0,53
0,26
0,34
0,47
0,18
0
0,1
–0,11
0,47
0,34
Vy
0,8
1,8
1,5
1,3
1,7
1,2
1,0
1,9
1,2
1,5
Y
−0,22
0,59
0,41
0,26
0,53
0,18
0
0,64
0,18
0,41
Известно, что предельно допустимое значение Vy для данного
типа самолета равно 4 м/с.
Определить с доверительной вероятностью γ = 0,95 вероятностную меру толерантного интервала [0, Vyдоп ].
Оценки среднего и дисперсии случайной величины Y = ln Vy соответственно равны:
Y = 0, 278;
s 2 = 0,06;
154
s = 0, 245.
Величина толерантного множителя определяется в соответствии
с выражением:
ln(Vyдоп ) − Y
k=
= 4,522.
s
Квантиль стандартного нормального распределения равен
uP =
k
1
N−
N
χ 2γ ( N − 1)
= 3,97,
в соответствии с которым вероятностная мера толерантного интервала равна Р = 0,999964.
Если заданная вероятностная мера интервала равна, например,
PT = 0,96 , то в этом случае система управления не соответствует
заданным требованиям по точности для вертикальной скорости.
Однако, учитывая малый объем выборки, очевидно, что испытания
необходимо продолжить.
Оценка вероятностных характеристик на участках разбега и
пробега. Процесс разбега можно рассматривать как совокупность
независимого продольного и бокового движения. По определению
[46] взлет — это движение самолета от момента старта до набора условной высоты препятствий H усл и достижения безопасной
скорости. Процесс разбега можно разделить на два участка: разбег в стояночном положении (на всех стойках шасси) до скорости подъема передней опоры VR и разбег на главных колесах до
достижения скорости отрыва Vотр с одновременным увеличением
угла тангажа υ.
Процесс разбега контролируется системой контроля таким образом, чтобы в случае существенного отклонения определяющих
параметров от расчетных, пилот имел возможность принять меры
для прекращения взлета.
В качестве вектора определяющих параметров продольного движения
рассматривается двумерный вектор связанных координат
G
Θ = {Vg , xg } и скалярный параметр υ, рис. 4.12.
G
На диаграмме показана допустимая область вектора Θ, соответствующая режимам нормального и прерванного взлета.
155
Рис. 4.12. Допустимые области для режимов нормального
и прерванного взлета
Допустимая область для нормального взлета определяется условием
Vg ( xg ) ≥ Vg ( xg ) доп ,
где Vg ( xg ) доп — предельная траектория продолженного взлета.
Основным назначением системы управления продольным движением при разбеге является достижение условий безопасного отрыва самолета от ВПП, которые для момента отрыва имеют вид:
⎧Vg ≥ Vg отр доп ,
⎪
⎨ xg ≤ Lотр доп = LВПП − Lд ,
⎪ϑ ≤ ϑ
отр доп,
⎩ отр
где Lg — расстояние, необходимое для набора безопасной высоты
H óñë и скорости Váåç над выходной кромкой ВПП.
156
Для обеспечения необходимого уровня безопасности разбега
система управления должна обеспечить заданную вероятность нахождения параметров продольного движения в допустимой области в терминальные моменты времени.
Поскольку координаты Vg и xg продольного движения являются
зависимыми, требование относительно этих параметров может быть
представлено одной из следующих эквивалентных зависимостей:
{ (
}
)
P Vg xg xg = Lотр д ≥ Vотр ≥ PT
или
{ (
}
)
P xg Vg Vg = Vотр ≤ Lотр д ≥ PT .
Условие, накладываемое на угол тангажа υ, имеет вид:
P {ϑотр ≤ ϑотр д
}≥ P .
T
Во всех случаях PT — требуемый уровень вероятности безопасного взлета, равный 1 − 10−6.
При отказе двигателя в процессе разбега взлет целесообразно
прекратить. Это возможно, если оставшаяся длина ВПП и концевой
полосы безопасности (КПБ) достаточна для полной остановки самолета при использовании всех средств торможения. В ином случае взлет необходимо продолжить с отказавшим двигателем. Границей, разделяющей области продолженного и прерванного взлета
является траектория торможения. Пересечение предельных траекторий продолженного и прерванного взлета определяет точку принятия решения о продолжении или прекращении взлета.
Очевидно из физических условий рассматриваемого процесса,
что дистанция принятия решения есть аналог высоты принятия решения в процессе захода на посадку. Эта дистанция определяет
промежуточное терминальное сечение в процессе разбега. Поскольку в этом сечении при невыполнении приведенных выше условий у пилота имеется возможность прервать взлет, то требуемый
G
уровень вероятности нахождения вектора Θ в допустимой области
определяется допустимой частотой прерванных взлетов Qпрер = 10−7.
Требования к точностным характеристикам процесса взлета в
этом сечении имеют вид [36]:
157
{ (
}
)
P Vg xg xg = Lпрер ≥ Vкр ≥ PT
или
{ (
}
)
P xg Vg Vg = Vкр ≤ Lпрер ≥ PT .
где Vкр — критическая скорость при отказе двигателя, PT = 1 − 10−4.
Управление боковым движением при разбеге осуществляется с
целью удержания самолета на ВПП при всех допустимых воздействиях. Определяющим параметром в этом случае является боковое
отклонение самолета от оси ВПП z(t), t∈T, где T — временной интервал длительности разбега. Требования к точностным характеристикам этого параметра, как правило, задаются нормативными документами, например [2, 4, 5, 8]. Технические характеристики
системы управления должны быть такими, чтобы вероятность смещения осевой линии самолета в месте установки основного шасси
более чем на 5м от оси ВПП как при продолженном, так и прерванном взлете была меньше 0,05 (за исключением случая отказа двигателя, для которого боковое смещение не должно превышать 9 м).
вероятность отклонения основной стойки шасси от оси ВПП на величину более 21,3 м не должна превышать величину 10−6.
Таким образом, требования к точности автоматизированного
управления боковым движением самолета в процессе разбега определяются следующими неравенствами (см. табл. 4.3):
P { z (t ) ∈ D1 t ∈ T } ≥ P1T ,
P { z (t ) ∈ D2 t ∈ T } ≥ P2T ,
где D1 = [−5;5] м, P1T = 0,95; D2 = [−21,3; 21,3] м, P2T = 1 − 10−6 .
Непараметрический алгоритм оценки соответствия системы управления заданными требованиям может быть записан в общем виде:
⎧
⎪⎪a1 ,
a=⎨
⎪
⎪⎩a2 ,
m
c=∑
j =1
(y
j
− NPj )
( NPj )
2
≤ χ 12− α (m − 1),
c > χ 12− α (m − 1),
где a1 — решение о соответствии системы заданным требованиям,
a2 — решение о несоответствии,
158
N
⎧⎪1, zi ∈ D j
y j = ∑ ξ ij , ξ ij = ⎨
i =1
⎪⎩0, zi ∉ D j , j = 1, m
y j — число попаданий определяющего параметра zi в соответст-
вующую допустимую область D j , m — количество определяющих
параметров процесса разбега, Pj — заданная вероятность.
Величина ошибки второго рода β, допускаемая решающим правилом, определяется как
β=
χ12− α ( m −1)
∫
χ 2 (m − 1, λ, y )dy ,
–∞
где χ ( m − 1, λ, y ) — плотность нецентрального χ 2 -распределения
с (m – 1) степенями свободы и параметром нецентральности
2
λ = N ∑ ( P1 j − Pj ) Pj−1 ,
m
2
j =1
где P1 j — альтернативное значение вероятности.
В том случае, когда соответствие определяется по каждой составляющей вектора точностных характеристик, решающее правило может быть записано в виде:
⎧ a , y ≥ b[ N , P, α],
a=⎨ 1
⎩ a2 , y < b[ N , P, α],
где b[ N , P, α] — квантиль биномиального распределения уровня
α, определяемый через функцию B — распределения из уравнения:
α = I1− P ( N − b[ N , P, α], b[ N , P, α] + 1) .
Вероятность ошибки второго рода β, допускаемая алгоритмом,
определяется из выражения:
β = I P ( b[ N , P, α] + 1, N − b[ N , P, α]) .
Для параметрической оценки точности в боковом канале можно
воспользоваться некоторыми результатами из теории порядковых
статистик [28, 70] применительно к максимально возможным значениям определяющего параметра бокового отклонения самолета
от оси ВПП на участке разбега длительностью T.
159
Известно, что распределение максимумов (наибольшей порядковой статистики Z (n ) ) случайного стационарного процесса определяется соотношениями для функции и плотности распределения:
Fmax ( z ) = P {Z max ≤ z} = P{все zi не превосходят z} = F n ( z ),
f max ( z ) = nf ( z ) F n −1 ( z ),
где n — объем выборки максимальных значений параметра по результатам испытаний (моделирования), F(z) — функция распределения определяющего параметра z(t) (в данном случае бокового отклонения самолета от оси ВПП).
Соответственно распределение наименьшей порядковой статистики задается соотношениями:
Fmin ( z ) = P {Z (1) = Z min ≤ z} = 1 − P {Z (1) > z} =
= 1 − P{все zi > z} = 1 − [1 − F ( z ) ] ,
n
f min ( z ) = nf ( z )[1 − F ( z )]n .
Если n велико, то можно использовать некоторые общие асимптотические результаты, зависящие от класса исходного распределения F(z). Например, представляя Fmax ( z ) в виде
n
⎡ n[1 − F ( z )] ⎤
Fmax ( z ) = F ( z ) = ⎢1 −
exp {− n[1 − F ( z )]} ,
⎥ n→
n
⎣
⎦ →∞
n
получаем асимптотическое выражение, позволяющее получить распределение максимальных значений параметра в зависимости от
объема выборки и статистических характеристик генеральной
совокупности.
Аналогично можно получить
Fmin ( z ) = 1 − exp {nF ( z )} .
Используя соответствующие критерии можно проверить гипотезу о том или ином законе распределения Fmax ( z ) и Fmin ( z ).
Результаты испытаний показывают, что закон распределения
максимальных значений боковых отклонений хорошо описывается распределением Релея (частный случай распределения Вейбулла):
160
⎧⎪
⎡ z 2 ⎤ ⎫⎪
Fmax ( z ) = 1 − exp ⎨exp ⎢ − 2 ⎥ ⎬ ,
⎪⎩
⎣ 2λ 0 ⎦ ⎭⎪
⎡ z2 ⎤
1
f max ( z ) = 2 = exp ⎢ − 2 ⎥ .
λ0
⎣ 2λ 0 ⎦
Распределение зависит от единственного параметра λ 0 , связанного с дисперсией соотношением σ 2 = 2λ 02 .
На рис. 4.13 показано распределение максимального бокового
отклонения самолета BOEING 767 при пробеге по результатам моделирования 1500 автоматических посадок [82]. Гистограмма показывает, что статистика пиковых значений случайной величины, как
правило, дает распределение Релея.
Рис. 4.13. Гистограмма распределения максимальных значений
боковых отклонений при автоматическом пробеге
Очевидно, что точечная оценка параметра λ 0 может быть определена как
1 n 2
λ∗ =
∑ zi .
2n i =1
Доверительный интервал для истинного значения параметра λ
может быть получен вследствие того, что распределение нормированной переменной
161
(λ )
n
∗ 2
u=
− λ 02
λ 02
асимптотически (практически при n > 100) следует нормальному
закону распределения N(0,1), т.е.
u1+ γ
2
t
2
−
⎧⎪
⎫⎪
1
2
P ⎨ u ≤ u1+ γ ⎬ =
e
dt = γ ,
∫
2π − u1+ γ
⎪
2 ⎭
⎩⎪
2
где u — соответствующий квантиль распределения N(0,1), γ-доверительная вероятность.
Тогда γ-доверительный интервал для λ 02 имеет вид
(λ )
(λ )
∗ 2
2
0
λ =
1+
1
u1+ γ
n 2
∗ 2
<λ <
2
0
1−
1
u1+ γ
n 2
2
= λ0 .
Вероятность невыхода максимального значения бокового отклонения на интервале T за верхнюю границу допустимой области
D при фиксированном значение параметра λ 02 равна:
⎧⎪ z 2 ⎫⎪
P {Z max ≤ zдоп } = 1 − exp ⎨− доп2 ⎬ .
⎩⎪ 2λ 0 ⎭⎪
Очевидно, что γ-доверительный интервал для искомого значения вероятности P при фиксированном уровне определяется соотношением:
2
2
⎪⎧ z ⎪⎫
⎪⎧ z ⎪⎫
P = 1 − exp ⎨− доп2 ⎬ < P < 1 − exp ⎨− доп2 ⎬ = P .
⎩⎪ 2λ 0 ⎭⎪
⎩⎪ 2λ 0 ⎭⎪
Правило принятия решения о степени соответствия точностных
характеристик заданным требованиям на основе нижней доверительной границы имеет вид
⎧a ,
a=⎨ 1
⎩a2 ,
162
P ≥ PT ,
P < PT .
Рассмотрим еще один вид асимптотически предельного (при
n → ∞ ) распределения экстремальных значений, которое справедливо для класса исходных распределений с неограниченными
«хвостами», имеющими экспоненциальный вид .
К этому классу исходных распределений относится и нормальное распределение.
Плотность распределения максимальных и минимальных значений имеет вид [26, 28]:
⎧
⎡ 1
⎤⎫
Fmax ( z; a, b) = exp ⎨− exp ⎢ − ( z − a) ⎥ ⎬ ,
⎣ b
⎦⎭
⎩
⎧
⎡1
⎤⎫
Fmin ( z; a, b) = 1 − exp ⎨− exp ⎢ ( z − a) ⎥ ⎬ ,
⎣b
⎦⎭
⎩
⎧ 1
1
⎡ 1
⎤⎫
f max ( z; a, b) = exp ⎨− ( z − a ) − exp ⎢ − ( z − a ) ⎥ ⎬ ,
b
⎣ b
⎦⎭
⎩ b
⎧1
1
⎡1
⎤⎫
f min ( z; a, b) = exp ⎨ ( z − a ) − exp ⎢ ( z − a ) ⎥ ⎬ ,
b
⎣b
⎦⎭
⎩b
где a — параметр положения распределения (мода распределения),
b — параметр масштаба. Параметры a и b связаны с математическим ожиданием и среднеквадратическим отклонением:
d
ln Γ( z ) z =1 = a − bΓ / (1) = a + 0,577b,
dz
= a + bΓ / = a − 0,577b,
πb
= σ min =
= 1, 283b.
6
mmax = a − b
mmin
σ max
Приведенные соотношения позволяют получить оценки параметров распределения экстремальных значений путем приравнивания моментов:
∗
amax
= z − 0,577b∗ ,
∗
amin
= z + 0,577b∗ ,
и для обоих моментов
b∗ =
s
.
1, 283
163
Оценки вероятностей нахождения экстремальных значений в
допустимой области могут быть получены из приведенных соотношений для функций распределения:
⎧
⎡ 1
⎤⎫
P∗ {Z max < zдоп } = exp ⎨− exp ⎢ − ∗ zдоп − a∗ ⎥ ⎬ ,
⎣ b
⎦⎭
⎩
⎧
⎡1
P∗ {Z min < − zдоп } = 1 − exp ⎨− exp ⎢ ∗ − zдоп − a∗
⎣b
⎩
(
)
(
)⎤⎥⎦ ⎫⎬.
⎭
Эти оценки позволяют провести предварительный (ориентировочный) анализ точностных характеристик, который, как правило,
используется в процессе предварительной обработки результатов
летных испытаний.
Допустимая область параметров продольного и бокового движения самолета в процессе пробега представлена на рис.4.14.
Рис. 4.14. Допустимые области бокового и прокольного
движения самолета при автоматическом пробеге
164
Задача управления пробегом будет выполнена, если на заданной
дистанции пробега скорость движения будет снижена до допустимого уровня VT . Тогда аналогично этапу разбега, требования к
точностным характеристикам параметров продольного движения в
процессе пробега могут быть записаны в виде:
{ (
}
)
P Vg xg xg = LT ≤ VT доп ≥ PT ,
или
{ (
)
P xg Vg Vg = Vg доп ≤ LT
}≥ P ,
T
где LT — требуемая дистанция снижения скорости пробега до допустимого уровня VT доп , PT = 1 − 10−6.
Управление боковым движением при пробеге осуществляется с
целью удержания самолета на ВПП при всех допустимых воздействиях и начальных условиях.
Как и при разбеге, требования к точности управления боковым
движением самолета в процессе пробега определяется следующими
условиями (см.табл.4.3):
P { z (t ) ∈ D1 t ∈ T } ≥ P1T ,
P { z (t ) ∈ D2 t ∈ T } ≥ P2T ,
где D1 = [−8, 2; 8, 2] м, D2 = [−21,3; 21,3] м, P1T = 0,95, P2T = 1 − 10−6.
Для оценки соответствия точностных характеристик заданным
требованиям на этапе пробега могут быть использованы те же алгоритмы, что и для процесса разбега.
Рассмотрим еще один подход к оценке распределения максимальных значений бокового отклонения самолета, связанный с распределением Пуассона.
Если при большем объеме выборки n вероятность P выхода определяющего параметра за допустимую область стремится к нулю
(на такую задачу проектируется система управления), то распределение числа выходов определяющего параметра за допустимый
уровень подчиняется распределению Пуассона (закону редких событий):
k λm
Fλ ( k ) = P { X ≤ k λ} = ∑
e− λ ,
m =0 m!
165
Pn ( k ) =
λk −λ
e ,
k!
k = 0, 1, 2...
где λ = nP есть среднее число выходов параметра за допустимую
область.
В точных расчетах используют аппроксимацию распределения
Пуассона χ 2 -распределением:
λm −λ
e = P {χ 2 (2k + 2) ≥ 2λ} .
m = 0 m!
В [16] получены выражения для доверительных пределов параметра λ. Верхний предел λ удовлетворяет уравнению:
P { X ≤ k λ} = ∑
k
{
}
P X ≤k λ=λ =
1+ γ
= 1 − P χ 2 (2k + 2) < 2λ
2
{
}
откуда
{
}
P χ 2 (2k + 2) < 2λ =
1− γ
,
2
где γ — доверительная вероятность.
Так как
то
⎪⎧
⎪⎫ 1 − γ
2
P ⎨χ 2 (2k + 2) < χ 1-γ
(2k + 2) ⎬ =
,
2
⎪⎩
⎪⎭
2
1 2
λ = χ 1-γ
(2k + 2),
2 2
1− γ
.
2
2
Аналогичным образом можно найти нижний доверительный
предел λ , который удовлетворяет уравнению:
где χ 12− γ — квантиль χ 2 — распределения уровня
P { X ≤ k λ = λ} =
1− γ
= 1 − P {χ 2 (2k ) < 2λ}
2
откуда
{
}
P χ 2 (2k ) < 2λ =
166
1+ γ
,
2
1
λ = χ 12+ γ (2k ).
2 2
Таким образом доверительный интервал для параметра имеет вид:
1
1
λ = χ 12+ γ (2k ) ≤ λ ≤ χ 12− γ (2k + 2) = λ.
2 2
2 2
Подставляя полученные значения доверительных границ (при
отсутствии выходов определяющего параметра за допустимую область) в выражение для вероятности Р получаем нижнюю P и
верхнюю P границы γ — доверительного интервала. Таким образом, вероятность отсутствия выходов определяющего параметра за
допустимый уровень в n испытаниях находится в пределах:
(
)
{ }
P ( 0, n λ ) = exp {− λn} .
P 0, n λ = exp − λn ,
Пример 4.4. В 200 испытаниях на этапе разбега не было зафиксировано ни одного выхода определяющего параметра за допустимую область [-8,2; 8,2] м. Требуется определить γ-доверительный
интервал для вероятности P нахождения бокового отклонения самолета от оси ВПП в допустимых пределах при γ = 0,95.
Из приведенных выше соотношений находим границы интервала для параметра λ:
1 2
λ = χ 0,975
(0) = 0;
2
1 2
λ = χ 0,025
(2) = 3,69 .
2
Тогда границы доверительного интервала для вероятности Р
равны:
⎧ 3,69 ⎫
P = 1, P 0, 200 λ = 3,69 = exp ⎨−
⎬ = 0,982,
⎩ 200 ⎭
т.е.
0,982 ≤ P ≤ 1.
(
)
4.3. Байесовские алгоритмы оценки соответствия
Рассмотрим байесовские алгоритмы оценки соответствия точностных характеристик заданным требованиям. Общая схема байесовской процедуры оценки соответствия показана на рис. 4.15.
167
План
испытаний
Распределения
искомого
параметра
Байесовский
доверительные
интервал
Результаты
испытаний
Функция
правдоподобия
f(ω/θ)
Формула
Байеса
Апостериорное
распределение
f(ω/θ)
Априорная
информация
Априорное
распределение
f(θ)
Функция
потерь
Минимизация
апостериорного
риска
Оценка
параметра
Рис. 4.15. Общая схема байесовского алгоритма
Как и ранее, требования к точности определяют разбиение пространства состояний на два интервала, как два альтернативных класса:
ρ1 = [ P1 , 1],
ρ 2 = [0, P2 ],
P1 > PT > P2 .
При оценке терминальных точностных характеристик по результатам испытаний достаточной статистикой является число попаданий k определяющего параметра (или вектора определяющих параметров) в допустимую область
n
k = ∑ ξi ,
i =1
⎧1, z (t0 ) ∈ D,
ξi = ⎨
⎩0, z (t0 ) ∉ D,
где n — количество реализаций параметра, зафиксированных на
момент оценки.
Статистика k имеет биномиальное распределение, так что функция правдоподобия имеет вид:
f ( k , n, P ) = Cnk P k (1 − P ) n − k .
Априорная информация о точностных характеристиках формируется в виде априорной плотности распределения f(P), которая
может быть определена, например, на основе экспериментальных
данных предшествующих этапов испытаний. Достаточная статистика k определяет тот факт, что для вычисления апостериорного
распределения параметра Р (исходя из любого априорного распре168
деления), достаточно знать распределение этой статистики, а не
значение определенного параметра.
В качестве априорного распределения параметра Р необходимо
выбрать сопряженное распределение, которым является В — распределение с параметрами а, b, согласующееся с функцией правдоподобия
f ( P) = B (a, b) P a −1 (1 − P )b −1
где
B ( a, b ) =
Γ( a + b)
.
Γ(a)Γ(b)
Тогда апостериорное распределение, которое в соответствии с
формулой Байеса имеет вид:
f ( P ) f ( k n, P )
f ( P, k ) =
∫ f ( P ) f ( k n, P )
ρ
также будет В — распределением. Действительно:
f ( P, k ) =
B(a, b) P a −1 (1 − P)b −1 Cnk P k (1 − P ) n − k
1
=
a −1
b −1 k k
n−k
∫ B(a, b) P (1 − P) Cn P (1 − P) dp
0
=
P a + k −1 (1 − P ) n + b − k −1
1
∫P
a + k −1
(1 − P )
n + b − k −1
0
dp
=
B (a + k ; n + b − k ) P a + k −1 (1 − P ) n + b − k −1
1
B(a + k ; n + b − k ) ∫ P
a + k −1
(1 − P )
n + b − k −1
=
dp
0
1
=
∫P
0
a + k −1
Γ ( a + k )Γ ( n + b − k )
=
Γ ( a + b + n)
=
1
=
B(a + k ; n + b − k )
(1 − P) n + b − k −1 dp =
= B(a + k ; n + b − k ) P a + k −1 (1 − P ) n + b − k −1 ,
так как знаменатель по определению В — распределения равен
единице. Таким образом апостериорное распределение есть B —
распределение с новыми параметрами:
(
)
/
f ( P, k ) = B a / , b / P a −1 (1 − P )b
169
/ −1
,
где
a/ = a + k;
b/ = n + b − k .
Параметры априорного распределения a и b можно трактовать
как количество значений определяющего параметра, попавших в
допустимую область на предшествующих этапах испытаний (параметр а) и количество выходов за допустимую область (параметр b),
так что a + b = N , где N — объем испытаний предшествующих
этапов. Чем больше уверенность в потенциальной точности системы управления после проведения предварительных испытаний, тем
больше концентрация априорной информации.
Зная апостериорную плотность можно определить доверительную вероятность γ, с которой контролируемый параметр точности
Р принадлежит допустимой области ρ1 . Для этого достаточно проинтегрировать апостериорную плотность по этой области:
1
(
)
Pr ( P ≥ P1 ) = ∫ f ( P k ) dp = ∫ B a / , b / P a −1 (1 − P)b −1 dp =
ρ1
=
P1
/
/
/
/
Γ(a + b )
P a −1 (1 − P)b −1 dp = γ.
/
/ ∫
Γ(a )Γ(b ) P1
/
/
1
Такая доверительная вероятность есть мера уверенности в том,
что P ∈ [ P1 , 1] при данных результатах испытаний объемом n и соответствующей априорной информации.
Критерием оптимальности алгоритма принятия решения является минимум безусловной вероятности ошибочного решения:
ε = ∫ f ( P k )α(P)dp + ∫ f ( P k )β(P )dp .
ρ1
ρ2
В этом случае оптимальным по критерию минимума безусловной вероятности ошибки ε является байесовское решающее правило максимума апостериорной вероятности.
Обозначив для рассматриваемого случая
A=
∫ f ( P k ) dp
ρ2
∫ f ( P k ) dp
ρ1
P2
=
/
/
a −1
b −1
∫ P (1 − P ) dp
0
1
∫P
P1
170
a / −1
/
(1 − P )b −1 dp
правило решения можно записать в виде:
⎧a ,
a=⎨ 1
⎩ a2 ,
A < 1,
A ≥ 1.
В тех случаях, когда априорная информация определяет интервал возможных значений P ∈ [Pн , Рв ] , то вводя переменную
P/ =
P − Pн
,
Pв − Рн
априорная плотность распределения может быть записана в виде
[48, 52]:
B (a, b) ⎛ P − Pн ⎞
f a ( P) =
⎜
⎟
Pв − Pн ⎝ Pв − Pн ⎠
а −1
⎛
P − Pн ⎞
⎜1 −
⎟
⎝ Pв − Pн ⎠
b −1
и при Pв = 1 (что справедливо для высокоточных систем)
B (a, b) ⎛ P − Pн ⎞
f a ( P) =
⎜
⎟
1 − Pн ⎝ 1 − Pн ⎠
а −1
⎛ P − Pн ⎞
⎜1 −
⎟
1 − Pн ⎠
⎝
b −1
.
Тогда для функции правдоподобия
k
⎛ P − Pн ⎞ ⎛ P − Pн ⎞
f ( k n, P ) = C ⎜
⎟ ⎜1 −
⎟
1 − Pн ⎠
⎝ 1 − Pн ⎠ ⎝
n−k
k
n
.
апостериорная плотность Р запишется в виде
B(a / , b / ) ⎛ P − Pн ⎞
f (P k) =
⎜
⎟
1 − Pн ⎝ 1 − Pн ⎠
а / −1
⎛ P − Pн ⎞
⎜1 −
⎟
1 − Pн ⎠
⎝
b / −1
,
а доверительная вероятность γ определяется выражением:
(
Γ a / + b/
)
⎛ P − Pн ⎞
γ=
∫⎜
⎟
/
/
Γ a Γ b (1 − Pн ) P1 ⎝ 1 − Pн ⎠
( ) ( )
1
171
а / −1
⎛ P − Pн ⎞
⎜1 −
⎟
1 − Pн ⎠
⎝
b / −1
dp.
Аналогичным образом видоизменяется выражение для решающего правила.
В рассматриваемом случае происходит еще большая концентрация априорной плотности, ограниченной более узким интервалом
определения. Однако при малом числе испытаний N на предшествующих этапах ошибки в задании априорной плотности существенно влияют на достоверность принимаемых решений.
Выбор параметров априорной плотности распределения не является статистической задачей, а определяется мерой уверенности
в потенциальных возможностях исследуемой системы управления,
подкрепленная всеми видами предшествующих испытаний и моделирования. В [52] приводятся рекомендации по выбору параметров
априорного распределения, если принять некоторые предположения о характере апостериорной информации (например, приблизительно известно, на какое среднее количество испытаний можно
рассчитывать). Анализ априорной информации, проводимой с учетом некоторых сведений о будущих испытаниях, носит название
предапостериорного анализа [59].
Представляет интерес оценить объем текущей информации, необходимый для подтверждения соответствия точностных характеристик системы управления в зависимости от уровня априорной
информации и от значений вероятностей P1 и P2 . В табл.4.7 приведены результаты расчета доверительной вероятности γ, с которой
контролируемый параметр Р принадлежит интервалу [ P1 , 1] такому, что P1 > PT при априорной информации, заданной на интервале
[0, 1] (для P1 = 0,96 и P2 = 0,95.
Таблица 4.7
Объем
текущих
испытаний
Количество выходов за допуск
0
1
2
3
50
100
200
300
400
500
0,98380
0,99789
0,99996
1
1
1
0,91565
0,98466
0,99959
0,99999
1
1
0,77366
0,94330
0,99766
0,99993
1
1
0,57842
0,85771
0,99097
0,99962
0,99999
1
В табл. 4.8 приведены результаты расчета допустимого значения P1 при заданной доверительной вероятности γ = 0,95.
172
Таблица 4.8
Объем
текущих
испытаний
Количество выходов за допуск
0
1
2
3
50
100
200
300
400
500
0,9707
0,9803
0,9818
0,9881
0,9915
0,9934
0,9539
0,9640
0,9812
0,9865
0,9895
0,9914
0,9390
0,9589
0,9751
0,9821
0,9861
0,9886
0,9250
0,9494
0,9694
0,9780
0,9829
0,9860
Для оценки соответствия точностных характеристик на участках
стабилизации достаточной статистикой является число выходов
случайного процесса на рассматриваемом участке за допустимую
область, которое имеет распределение Пуассона. Альтернативные
классы состояний для параметра Λ имеют вид:
Λ1 = {Λ : Λ ≤ Λ1} ; Λ 2 = {Λ : Λ > Λ 2 } , Λ1 ≤ ΛT ≤ Λ 2 ,
Λ1 = − ln P1 ; Λ 2 = − ln P2 ; ΛT = − ln PT .
Очевидно, что функция правдоподобия при фиксированных значениях n и k имеет вид:
f (k Λ) =
Λk
e −Λn ,
k1 !...kn !
n
где k = ∑ ki — количество выходов определяющего параметра в n
i =1
испытаниях.
В качестве априорного распределения необходимо использовать
гамма-распределение с параметрами α и β, которое является сопряженным к функции правдоподобия:
f (Λ) =
β α α-1 −βΛ
Λ e .
Γ(α)
Выбирая соответствующие значения параметров α и β, можно
подобрать такой вид кривой гамма — распределения, который будет отражать положение и разброс априорных представлений в
широком диапазоне. Чем больше значение β, тем больше концентрация априорных представлений.
173
Параметры априорного распределения могут трактоваться как
количество выходов k за допустимую область (α) и количество испытаний N на предшествующих этапах (β).
Апостериорное распределение параметра Λ в соответствии с формулой Байеса определяется выражением:
f (Λ k ) =
Λ α-1 exp{−βΛ}Λ k exp{− Λn}
∞
∫Λ
α + k −1
=
exp{− Λ(β + n)}d Λ
0
∞
= ∫ Λ α + k −1 exp{− Λ(β + n)}d Λ =
0
=
Γ(α + k )
=
(β + n)α + k
(β + n)α + k α + k −1
Λ
exp{− Λ(β + n)}
Γ(α + k )
и также является гамма-распределением с новыми параметрами:
β / = β + n;
α/ = α + k ,
так что
/
/ α
(β ) Λ
f (Λ k ) =
Γ (α )
α / −1
/
{
}
exp −Λβ / .
Апостериорная оценка Λ определяется математическим ожиданием апостериорного распределения и равна
Λ∗
/
/ α
(β ) Λ(
= ∫ Λf ( Λ k ) d Λ =
∫
Γ (α )
∞
∞
/
0
)
α / +1 −1 −Λβ /
e
/
/ α
(β ) Γ ( α + 1) = α
dΛ =
β
Γ (α ) β
( )
/
/
/ α +1
/
0
/
/
.
Доверительная вероятность γ, с которой контролируемый параметр Р принадлежит допустимой области, определяется выражением:
/
/ α
(β ) Λ
Pr { P ≥ P } = Pr {Λ ≤ Λ } =
∫
Γ (α )
1
1
/
Λ1
0
α / −1
{
}
exp −Λβ / d Λ = γ
в силу монотонности Λ = − ln P.
Байесовское решающее правило можно определить как:
⎧a , A < 1,
a=⎨ 1
⎩a2 , A ≥ 1,
174
где
∞
A=
Λ2
∫ f ( Λ k ) d Λ 1 − ∫ Λ α −1 exp {−Λβ / } d Λ
Λ
2
Λ1
∫ f (Λ k ) dΛ
0
=
/
0
Λ1
∫Λ
0
α / −1
{
}
.
exp −Λβ d Λ
/
В заключение отметим, что источником априорной информации
являются данные испытаний всех видов на нижних уровнях иерархии. Поскольку объемы этих испытаний ограничены, то оценки вероятностных характеристик обладают некоторой неопределенностью, т.е. являются случайными величинами и, следовательно,
априорная информация должна описываться соответствующими законами распределения.
4.4. Планирование объемов испытаний
Для достижения высокой достоверности получаемых статистических характеристик требуется достаточно большое число реализаций режимов полета в соответствующих испытаниях, которое зависит от требований к точностным характеристикам и доверительной вероятности.
Очевидно, что наиболее информативным видом испытаний являются летные испытания в реальных эксплуатационных условиях
с учетом суммарного эффекта взаимодействия всех подсистем и
влияния полного комплекса факторов окружающей среды.
Это означает, что летные испытания остаются основным наиболее надежным и эффективным методом оценки аэронавигационных
и летных характеристик самолета, на основании которых делается
заключение о летной годности создаваемого самолета.
Не останавливаясь подробно на структуре летных испытаний,
особенностях их проведения [48, 52, 53, 57, 60], отметим следующее. На сегодняшний день происходит существенное уменьшение
соотношения объемов испытаний в идеальных атмосферных и эксплуатационных условиях и испытаний в предельных условиях, а
также существенное увеличение объема наземных испытаний.
Очевидно, что условия проведения летных испытаний не могут
обеспечить полную проверку влияния на характеристики самолета
всех внешних факторов во всем спектре их изменения в ожидаемых
условиях летной эксплуатации, поэтому окончательная оценка соответствия точностных характеристик должна быть основана на ре175
зультатах как летных испытаний, так и статистического моделирования, которое должно сопутствовать всем видам летных испытаний и полунатурного моделирования с целью корректировки их
направленности.
Рассмотрим вопрос о количестве реализаций, необходимых для
оценки точности процессов управления с необходимой достоверностью при проведении летных испытаний и полунатурного моделирования. Диапазон оцениваемых вероятностей в соответствии с
требованиями находится в пределах 0,95 ÷ 0,96.
Параметрическая оценка объемов испытаний. Как уже отмечалось (см. раздел 3.3), при конечных объемах n можно построить γ доверительные допустимые области Ω γ (n) для оценок z , s 2 , соответствующие выполнению условия:
( z, s ) ∈ Ω (n) ⊂ S → P{D} ≥ P .
2
γ
T
Очевидно, что площади под допустимыми областями Ω γ (n),
определяемые возможными значениями оценок z , s 2 , уменьшаются со снижением объема испытаний n. Указанные области позволяют заранее оценить первоначальный объем n0 летных (полунатурных) испытаний для оценки точности системы управления,
если известна априорная информация об оценках z , s 2 , полученная
на ранних этапах исследований. Отложив значение параметра
θ = z, s 2 на плоскости, можно получить точку внутри некоторой
(
)
области Ω γ (n). Например, при θ = ( z н = 0,15; sн = 0,36 ) точка
(0,15; 0,36) находится между областями Ω0,9 (50) и Ω0,9 (30) (см.
рис.4.5, б). Путем интерполяции (в первом приближении линейной)
можно уточнить величину n0 = 42.
Таким образом, достаточно провести 42 независимых измерения
определяющего параметра для получения оценки z, s2 , и, если най-
(
)
денные оценки не будут превышать априорных, то следует вывод, что
Pr { P( D) ≥ 0,98} = 0,9.
Сделаем следующие замечания. Очевидно, что использование
параметрических оценок позволяет существенно сократить объем
испытаний (измерений), а также увеличить информативность вы176
водов по их результатам. Оценим отклонение выборочной дисперсии s 2 относительно ее фактического значения σ 2 при уровне доверия γ (например 0,9 и 0,99) с помощью χ 2 -распределения:
⎧ n −1
n − 1 ⎫⎪
σ2
P⎪ 2
≤ 2 ≤ 2
= γ.
⎨ χ 1− γ (n − 1) s
χ 1+ γ (n − 1) ⎬
⎩⎪ 2
⎭⎪
2
На рис.4.16 изображены 95% и 99% доверительные границы отs
ношения .
σ
Скорость сходимости среднеквадратического отклонения резко
уменьшается примерно при n = 1000, что означает ослабление эффекта повышения надежности и точности оценки s при возрастании
объема выборки. Сходимость оценки s к ожидаемому предельному
значению σ устанавливает тот факт, что с увеличением размера
выборки вероятность неожиданно встретить экстремальное значение параметра, превышающее текущий максимум (или минимум),
незначительна при условии, что распределение приблизительно
правильно представляет устойчивость статистики отклонений определяющих параметров в предполагаемом состоянии вероятностной среды и данной конфигурации самолета.
γ = 0.9
10000
1000
1000
100
100
0.8
1.0
γ = 0.99
10000
1.2
0.8
σ
s
1.0
σ
s
Рис. 4.16. Доверительные интервалы для отношения
177
1.2
σ
s
Для сравнения на рис. 4.17, 4.18 показана реальная статистика
среднеквадратического отклонения s бокового и продольного отклонений самолета (BOEING 767) в точке касания по результатам
моделирования автоматической посадки [82].
3.05
S,M
zmax,M
15.0
2.9
9.0
2.75
3.0
-0
2.6
-3.0
2.45
-9.0
2.3
0
400
800
1200
1600
-15.0
Рис. 4.17. СКО бокового отклонения и экстремальные
отклонения самолета в точке касания
(∗ — влево, — вправо)
Lmax,M
915
SL, M
73
70
762
67
609
64
456
61
303
58
0
400
800
1200
150
1600
Рис. 4.18. СКО продольного отклонения и экстремальные
отклонения самолета в точке касания
(∗ — ближняя посадка, — дальняя посадка)
178
Можно убедиться, что при n = 1000÷1200 оценки s этих отклонений находятся в ± 2,5% «трубке» относительно соответствующих
оцениваемых предельных значений sz = 2,73 м и sL = 66,5 м.
Отметим также, что сходимость оценки математического ожидания по сравнению с оценкой s является более быстрой и, следовательно, ее оценка не влияет на объем моделирования.
Таким образом, при параметрическом подходе к оценке точности (если гипотеза нормальности не отвергается) системы управления необходимый объем выборки можно существенно уменьшить.
В частности, для оценки соответствия среднеквадратического отклонения определяющих параметров в точке касания необходимый
объем не превышает несколько тысяч реализаций, что может быть
реализовано летными и полунатурными испытаниями.
Непараметрическая оценка объемов испытаний.
Полученные в разделе 3.3 соотношения определяют доверительную вероятность γ, с которой нижняя граница вероятности нахождения определяющего параметра (или вектора параметров) в
допустимой области равна PT :
1 − P(2 y, 2a) = γ,
где P(2y, 2a) есть интеграл вероятностей χ 2 ,
y=
(1 − PT )(n + r )
, a = n − r +1,
1 + PT
r — число успешных исходов.
Вводя переменную r = n − r , соответствующую количеству выходов определяющего параметра, можно записать:
⎛ P (2 y, 2a) = 1 − γ,
⎜ 2y = χ 2 (2a),
1− γ
⎝
2
2
где χ (⋅) – квантиль χ –распределения уровня (1 − γ) с 2а степенями свободы. В этом случае:
(
)
2a = 2(n − r + 1) = 2 r + 1 ,
2
(1 − PT )(n + r )
= χ 12− γ ⎡ 2 r + 1 ⎤ ,
⎣
⎦
1 + PT
(
откуда следует
179
)
(
)
2 ⎡
⎤
1 χ 1− γ ⎣ 2 r + 1) ⎦ (1 + PT )
n+r =
2
1 − PT
или
(
)
⎧⎡ 2 ⎡
⎫
⎤
⎤
1 ⎪ ⎢ χ 1− γ ⎣ 2 r + 1) ⎦ (1 + PT ) ⎥
⎪
n= ⎨
+ 2r ⎬ .
⎢
⎥
4⎪
1 − PT
⎪
⎦⎥
⎩ ⎣⎢
⎭
В табл.4.9 приведены значения объемов испытаний для различных значений PT = 0,95; 0,98; 0,99, доверительной вероятности
γ = 0,9; 0,95; 0,99 и числа выходов определяющего параметра за
допустимые пределы r = 0, 1, 2, 3.
Таблица 4.9
Число
выходов
0
1
2
3
γ = 0,9
γ = 0,95
γ = 0,99
P
0,95 0,98 0,99
P
0,95 0,98 0,99
P
0,95 0,98 0,99
45
77
105
132
59
93
124
153
90 228
130 329
165 417
198 499
114
193
265
333
230
388
531
667
149
236
313
386
298
473
688
773
458
661
838
1000
В тех случаях, когда при оценке соответствия точностных характеристик заданным требованиям, необходимо проверить гипотезу H 0 : P ≥ P1 при конкурирующей гипотезе H1 : P ≤ P2 , где
P2 ≤ PT ≤ P1 , с заданными уровнями ошибок α и β, необходимый
объем испытаний можно оценить исходя из мощности критерия π,
которая зависит от расстояния между конкурирующими гипотезаr
распределена при
ми P1 − P2 . Так как случайная величина P∗ =
n
больших n приближенно нормально со средним nP и дисперсией
P(1 − P)
, то при использовании нормальной аппроксимации (см. разn
дел 3.2) можно записать:
⎡⎛
⎞ P (1 − P1 ) ⎤
P1 − P2
n⎟ 1
1 − β = π(P2 ) = Φ ⎢⎜ uα +
⎥,
⎟ P (1 − P ) ⎥
P1 (1 − P1 )
⎢⎣⎜⎝
2 ⎦
⎠ 2
180
или
⎛
⎞ P (1 − P1 )
P1 − P2
u1−β = ⎜ uα +
n⎟ 1
,
⎜
⎟ P (1 − P )
(1
)
P
P
−
1
1
2
2
⎝
⎠
откуда
n=
1
2
( P1 − P2 )
2
⎡u1−β P2 (1 − P2 ) − uα P1 (1 − P1 ) ⎤ ,
⎣
⎦
где u1− β и uα — квантили уровней 1 − β и α распределения N(0, 1).
В табл. 4.10 приведены результаты расчета объемов испытаний
для различных значений α = β = 0,01; 0,05; 0,1; PT =0,95; 0,98; 0,99
с фиксированными значениями расстояния между конкурирующими гипотезами.
Таблица 4.10
Ошибки
α=β
0,1
0,05
0,01
PT = 0,95
PT = 0,98
PT = 0,99
P1 = 1 P2 = 0,95
P1 = 1 P2 = 0,98
P1 = 1 P2 = 0,99
32
52
103
81
133
266
164
268
536
Оценим величину необходимого объема испытаний для подтверждения вероятностей высоких уровней. Необходимые результаты можно получить с помощью соотношения (см. раздел 3.3):
γ = I1− PT (n − r + 1, r ) = 1 − I PT (r , n − r + 1),
где I PT (a, b) — функция B-распределения, определенная на отрезке ( 0 ≤ PT ≤ 1) и зависящая от двух положительных аргументов a = r,
b = n – r +1.
В табл.4.11 приведены результаты расчета объема испытаний
для различных значений PT и γ.
Таблица 4.11
Вероятность γ
PT = 0,93
PT = 0,94
PT = 0,95
PT = 0,96
0,9
0,95
0,99
2306
3004
4654
23074
30056
46562
230758
300576
465644
2 307396
3 005781
4 656461
181
Приведенные выше рассуждения справедливы при оценке соответствия точностных характеристик всех определяющих параметров в различных режимах полета, если в нормативных документах
заданы требуемые значения среднеквадратических отклонений(во
многих случаях нормативные значения можно рассчитать и обосновать) или допустимые области с определенными на них вероятностными мерами.
Рассмотрим вопрос, связанный с продолжительностью летных испытаний заданного объема. Ввиду стохастического характера изменения большинства внешних влияющих факторов, нельзя гарантировать
наличие необходимых условий в конкретном пункте испытаний, в
конкретное время года. Можно лишь говорить о вероятности наличия
выбранного комплекса условий в течение требуемого периода времени.
В аэропортах предполагаемой эксплуатации данного типа самолета с соответствующей системой управления накоплены статистические данные о вероятности появления и непрерывной продолжительности наблюдаемых факторов, например, статистические гистограммы распределения факторов, характеризующих состояние
атмосферы, представленные авиационно-климатическим атласом.
Для эффективного проведения летных испытаний, как правило,
формируется соответствующая программа и проводится расчет
продолжительности всего цикла испытаний. Поскольку изменение
внешних условий во времени носит стохастический характер, расчетное время и продолжительность испытаний может определяться
на вероятностной основе.
Исходными данными для расчета являются необходимое число
периодов k непрерывной продолжительности существования определенного комплекса факторов (например, скорость ветра в диапам
, высота облачности и др.), а также интенсивность λ
зоне 5÷8
сек
(среднее число событий в единицу времени) появления требуемых
условий в выбранном пункте проведения испытаний.
Необходимое число периодов появления соответствующих условий определяется отношением заданного объема испытаний к числу
посадок n0 в одном испытательном полете (как правило n0 = 8 – 10).
Интенсивность появления требуемых условий может быть определена
на основе априорных статистических данных в пункте испытаний.
Расчет основан на распределении Пуассона [16, 63], которое хорошо аппроксимирует случайный поток появления необходимых
условий в пункте испытаний:
182
P{ X = k} =
Λ k −Λ
e ,
k!
где Λ — параметр распределения, Λ = λt, λ — интенсивность потока.
В соответствии с теорией этого распределения нетрудно получить доверительный интервал ( Λ1 , Λ 2 ) для истинного значения
Λ = λt, при котором с заданной доверительной вероятностью γ число появлений необходимых условий в пункте испытаний будет не
менее требуемого числа k. Используя аппроксимацию распределения Пуассона χ 2 -распределением определим нижний и верхний
доверительные пределы:
1 2
⎧
⎪ Λ1 = 2 χ 1+ γ (2k ),
⎪
2
⎨
1
⎪ Λ 2 = χ 12− γ (2k + 2).
⎪⎩
2 2
Тогда верхняя t1 и нижняя t2 доверительные границы необходимого времени для проведения k периодов летных испытаний
объемом n соответственно равны:
t1 =
Λ1
,
λ
t2 =
Λ2
.
λ
Пример 4.5. Анализ повторяемости периодов ΔT = 2 – 3 часа
м
поканепрерывной продолжительности скорости ветра 5 – 8
сек
зывает, что наибольшую повторяемость имеет аэропорт №1. Накопленная статистическая информация дает оценку интенсивности
λ = 0,32. Определить доверительный интервал для продолжительности летных испытаний с доверительной вероятностью γ = 0,9 в
предположении, что число периодов k повторения этих условий
равно 5.
Определяем доверительный интервал для параметра Λ:
1 2
Λ1 = χ 0,95
(10) = 1,97,
2
1 2
Λ 2 = χ 0,05
(12) = 10,513.
2
183
Тогда временной интервал продолжительности испытаний равен:
t1 =
Λ1
= 6,
λ
t2 =
Λ2
= 33.
λ
В табл. 4.12 приведены результаты расчета значений t1 и t2 для
различных значений k и γ.
Таблица 4.12
γ
k=2
k=5
k = 10
k = 15
0,8
0,9
0,95
2 – 17
1 – 20
1 – 23
8 – 29
6 – 33
5 – 36
19 – 48
17 – 53
15 – 57
32 – 66
29 – 72
26 – 77
4.5. Последовательные алгоритмы оценки соответствия
Известно, что выбор оптимального плана испытаний сводится к
поискам процедуры, которая минимизирует необходимый объем
испытаний, обеспечивающий заданную точность и достоверность
оценки точностных характеристик при принятии решения о степени их соответствия заданным требованиям. Под достоверностью
понимается достигаемый уровень вероятностей ошибочных решений α и β (в отдельных случаях доверительная вероятность γ).
Отметим, что все три показателя процесса испытаний: точность,
достоверность и объем испытаний взаимосвязаны. С увеличением
объема испытаний монотонно повышается точность или достоверность оценки вероятностных характеристик. По заданным точности
и достоверности может быть рассчитан объем испытаний, а, следовательно, и их стоимость.
Очевидно, что оптимальным является правило планирования
процесса испытаний, при котором заданные характеристики точности и достоверности достигаются при минимальном объеме испытаний. Существуют правила, которые позволяют определить точную верхнюю грань объема испытаний, гарантирующего независимо от результатов испытаний заданные уровни точности и достоверности оценки точностных характеристик. Такие решающие правила относятся к классу статических, т.е. позволяющих принимать
решение по выборке фиксированного объема.
Вместе с тем, оперативный анализ результатов испытаний в темпе
их поступления на основе последовательных методов позволяет
184
минимизировать средний объем испытаний при условии, что вероятности ошибочных решений не превышают установленных уровней α 0 и β 0 соответственно. Структура последовательного правила
остановки процесса испытаний имеет вид:
N n = min {n ≥ 1: ln Ln ∉ (ln B, ln A)} ,
где
B=
β0
,
1 − α0
A=
1 − β0
,
α0
Ln — отношение правдоподобия выборки Z = ( z1 , ..., zn ) результатов испытаний на n-ом шаге, определяемое как
Ln =
f ( z1 , θ 2 ) f ( z2 , θ 2 )... f ( zn , θ 2 )
,
f ( z1 , θ1 ) f ( z2 , θ1 )... f ( zn , θ1 )
f ( zi , θ) — вероятность получения zi выборочного значения из генеральной совокупности с плотностью вероятности f ( z , θ) , содержащей неизвестный контролируемый вероятностный параметр θ.
При остановке процесса испытаний в соответствии с последовательным правилом принятие решения о степени соответствия точностных характеристик заданным требованиям осуществляется в
соответствии с алгоритмом:
ln Ln ≤ ln B,
⎧a ,
aN ( Z ) = ⎨ 1
,
ln Ln ≥ ln A,
a
⎩ 2
где a1 и a2 решения о соответствии (не соответствии) системы заданным требованиям.
Принципиально важным является свойство замкнутости последовательного критерия. Это означает, что математическое ожидание объема выборки последовательной процедуры ограничено, т.е.
значение N n , при котором прекращаются испытания, конечно с
вероятностью 1, а «хвосты» распределения объема испытаний стремятся к нулю [35]. Вместе с тем конкретное значение объема испытаний является случайной величиной, а минимизация среднего значения объема не означает, что будет минимизировано его конкретное значение, реализуемое в процессе испытаний.
Для ограничения реализуемого объема эксперимента в [69, 78]
предложены усеченные последовательные процедуры. Пусть объем
185
испытаний ограничен числом n1 реализаций и последовательный
процесс не закончился при n = 1, 2, ..., n1 − 1. Усеченное последовательное решающее правило имеет вид
ln B ≤ ln Ln1 ≤ 0,
ln A ≥ ln Ln1 > 0.
⎧a1 ,
aN/ ( Z ) = ⎨
⎩a2 ,
Отметим, что пороги В и А, обеспечивающие в не усеченной последовательной процедуре вероятности ошибок первого и второго
рода α 0 и β 0 , в случае усеченной процедуры приводят к увеличению вероятностей ошибок. Можно показать [78], что вероятности
ошибок первого α / и второго β / рода в усеченной последовательной процедуре удовлетворяют неравенствам:
{
+ P {ln L
}
< 0} .
α / ≤ α(n1 ) = α 0 + P ln Ln1 ≥ 0 ,
β ≤ β(n1 ) = β 0
/
n1
Для случая большого значения n1 для оценки вероятностей в
правых частях можно воспользоваться нормальной аппроксимацией [78]:
⎛ n M ln L ⎞
1
1
n1
/
⎟,
α ≤ α(n1 ) + 1 − Φ ⎜ −
⎜
⎟
⎜
n1 D1 ln Ln1 ⎟
⎝
⎠
⎛ n M ln L ⎞
1
2
n1
/
⎟,
β ≤ β(n1 ) + Φ ⎜ −
⎜
⎟
⎜
n1 D2 ln Ln1 ⎟
⎝
⎠
{
{
{
{
{
} {
}
}
}
}
}
где M i ln Ln1 , Di ln Ln1 — математическое ожидание и дисперсия
случайной величины ln Ln1 , взятые соответственно при справедливости i-й гипотезы, і = 1, 2.
Очевидно, что при конечных значениях n1 классическая усеченная последовательная процедура теряет свои оптимальные
свойства по сравнению с не усеченной (истинные значения вероятностей α / и β / превышают допустимые значения α 0 и β 0 ). Это
связано с тем, что для усечения последовательной процедуры на
186
n1 -м шаге, здесь используется критерий максимального правдоподобия. Действительно, как видно из выражения для усеченного последовательного решающего правила aN/ ( Z ) величина логарифма
отношения правдоподобия ln Ln1 на n1 -м шаге сравнивается с 0, что
эквивалентно сравнению отношения правдоподобия с 1 [49, 50]. По
этой причине классическая усеченная процедура не приемлема для
планирования объема испытаний.
Для сохранения оптимальных свойств усеченной последовательной процедуры в качестве правила усечения можно использовать решающее правило типа Неймана-Пирсона. Тогда структура
динамического правила остановки процесса испытаний имеет вид:
N 0 = min { N 0 ( Z ), n0 } ,
где N 0 ( Z ) — последовательный момент остановки, который минимизирует средний объем испытаний при заданных вероятностях α 0 и β 0 :
N 0 ( Z ) : M { N 0 ( Z )} ≤ M { N ( Z )} ,
n0 — статический момент остановки, получаемый из соответствующего наиболее мощного решающего правила:
n0 = min {n ≥ 1: α(n) ≤ α 0 , β(n) ≤ β 0 } ,
и минимизирующий независимо от результатов испытаний вероятности ошибочных решений до допустимых уровней α 0 и β 0 .
Оптимальное свойство динамического правила планирования
испытаний заключается в том, что оно минимизирует реализуемый
необходимый объем испытаний при заданных вероятностях α 0 и
β 0 . При заданных α 0 и β 0 статический момент остановки n0 независимо от результатов испытаний определяет минимальную верхнюю грань объема испытаний, последовательный момент остановки N 0 ( Z ) минимизирует средний объем испытаний при n < n0 .
Непараметрические алгоритмы. Формальная постановка задачи
анализа соответствия точностных характеристик заданным требованиям на основе результатов испытаний сводится к принятию одного из двух взаимоисключающих решений:
a1 : P ∈ [ P1 , 1] — система соответствует требованиям,
a2 : P ∈ [ 0, P2 ] — система не соответствует требованиям,
187
где P1 , P2 — согласованные значения точностных характеристик,
такие что P1 ≥ PT ≥ P2 , P1 ≠ P2 .
Последовательное правило остановки процесса испытаний строится на анализе достаточной для параметра 1 – Р статистики k – числа
выходов определяющего параметра в терминальном сечении за допустимую область в выборке результатов испытаний нарастающего
объема n. Статистика k(n) следует биномиальному распределению
независимо от вида распределения определяющего параметра движения. Для выборки объема n, содержащей k выходов параметра за
допустимую область, функция правдоподобия имеет вид
p1n = (1 − P1 ) P1n − k ,
k
если истинное значение точностной характеристики есть P = P1 , и
p2 n = (1 − P2 ) P2n − k ,
k
если P = P2 .
Логарифм отношения правдоподобия равен
ln Ln = k ln
1 − P2
P
+ (n − k ) ln 2 .
P1
1 − P1
Как правило, вместо непосредственного анализа величины ln Ln
с постоянными нижним и верхним порогами анализируют число
выходов k с линейно возрастающими нижним и верхним порогами.
Тогда последовательное ( α 0 , β 0 ) — правило остановки процесса
испытаний имеет вид:
N 0 (k ) = min {n ≥ 1: k ∉ ( bn , an )}.
При остановке процесса испытаний в соответствии с указанным
правилом решение о состоянии точностных характеристик принимается в соответствии с алгоритмом:
где
⎧a ,
aN (k ) = ⎨ 1
⎩a2 ,
bn = h1 + h0 n,
k ≤ bn ,
k ≥ an ,
an = h2 + h0 n,
188
β0
1 − β0
ln
1 − α0
α0
h0 =
, h1 =
, h2 =
.
P
P
P
1 − P2
1 − P2
1 − P2
− ln 2
− ln 2
− ln 2
ln
ln
ln
P1
P1
P1
1 − P1
1 − P1
1 − P1
ln
P1
P2
ln
Рассмотренные правила остановки процесса испытаний относятся к классу свободных от распределения критериев, поскольку распределение достаточной статистики и функции правдоподобия
выборки не зависит от вида распределения определяющего параметра движения. В том случае, когда тип семейства распределения параметров движения самолета известен, можно построить эффективные
параметрические последовательные правила остановки испытаний.
Параметрические алгоритмы. В случае нормального распределения параметра движения в терминальном сечении требования к
точности взаимно однозначно формулируются в терминах парамеG
тров нормального распределения Θ = (m, σ) . Условие соответствия
точностных характеристик заданным требованиям имеет вид:
m = m1 , σ ≤ σ1 .
Формальная постановка задачи анализа соответствия точностных характеристик заданным требованиям заключается в выборе
одного из двух решений:
a1 : m = m1 ,
a2 : m ≥ m2 ,
σ ≤ σ1 ,
σ ≥ σ2 .
При такой параметризации задачи последовательное правило
остановки испытаний ищется в виде:
{
}
N 0 ( Z ) = max N 0σ ( Z ), N 0m ( Z ) ,
где N 0σ ( Z ), N 0m ( Z ) — маргинальные последовательные моменты
остановки, минимизирующие средние объемы испытанийG при оценке компонент σ и m вектора точностных характеристик Θ.
Определим маргинальный момент остановки N 0σ ( Z ) в общем
случае при неизвестном параметре m.
Пусть в результате первых n реализаций определяющего параметра движения получены n – 1 оценок дисперсии s22 , ..., sn2 . Считая
эти оценки «наблюдениями» и применяя к ним критерий отноше189
ния правдоподобия, маргинальный момент остановки N 0σ ( Z ) можно представить в виде:
N 0σ ( Z ) = min {n ≥ 2, Ln ∉ ( B, A)} ,
где отношение правдоподобия Ln определяется как:
).
σ )
f
В силу совместной достаточности ( z , s ) для (m, σ) и функциоLn =
(
( s , ..., s
f n s22 , ..., sn2 σ 22
n
2
2
2
n
2
1
нальной независимости статистик s22 , ..., sn2 от sn2 и z совместная
(
плотность вероятностей f n s22 , ..., sn2 σ 2
)
допускает факторизацию
и отношение правдоподобия имеет вид:
⎛σ ⎞
Ln = ⎜ 1 ⎟
⎝ σ2 ⎠
n −1
⎧ 1
⎫
exp ⎨− ( n − 1) sn2 σ −22 − σ1−2 ⎬ .
⎩ 2
⎭
(
)
Переходя к логарифму отношения правдоподобия, момент остановки N 0σ ( Z ) можно записать в виде:
{
}
N 0σ ( Z ) = min n ≥ 2, sn2 ∉ ( Bn , An ) ,
где
−1
⎡ ln B
σ ⎤
Bn = 2 ⎢
+ ln 2 ⎥ σ1-2 − σ -22 ,
σ1 ⎦
⎣ (n − 1)
−1
⎡ ln A
σ ⎤
An = 2 ⎢
+ ln 2 ⎥ σ1-2 − σ -22 .
σ1 ⎦
⎣ (n − 1)
Рассмотрим маргинальный момент остановки N 0m ( Z ). Отметим,
(
)
(
)
что статистика z при любом m следует нормальному распределению, зависящему от мешающего параметра σ. Для построения
N 0m ( Z ) можно использовать следующий подход [35].
α ⎤
⎡
Как известно, условие t ≤ t ⎢n − 1, 1 − 0 ⎥ решающего правила фик2⎦
⎣
сированного объема относительно среднего эквивалентно выражению:
190
α ⎤
α ⎤
⎡
⎡
t ⎢ n − 1, 1 − 0 ⎥ s
t ⎢ n − 1, 1 − 0 ⎥ s
2⎦
2⎦
m1 − ⎣
≤ z ≤ m1 + ⎣
.
n
n
Статистика
t=
(
n z − m2
)
s
при справедливости m = m2 так же следует t — распределению с
(n – 1) степенями свободы. Тогда условная (при данном s) вероятность ошибки второго рода есть
⎧ m − m2
α ⎤
⎡
β ( m2 s ) = P ⎨ 1
n − t ⎢ n − 1, 1 − 0 ⎥ ≤ t ≤
2⎦
⎣
⎩ s
α ⎤⎫
m − m2
⎡
≤ 1
n + t ⎢ n − 1, 1 − 0 ⎥ ⎬ .
s
2 ⎦⎭
⎣
По сравнению с безусловной вероятностью ошибки β(m2 ) усло-
вная вероятность β ( m2 s ) имеет тот недостаток, что ее величина
становится известной после окончания испытаний (когда известна s)
и, следовательно, не пригодна для построения статических планов
испытаний. Вместе с тем безусловная вероятность ошибки β при
заданной альтернативе m2 минимизируется до заданного значения
β 0 последовательным проведением испытаний в тот момент, когда
β ( m2 s ) ≤ β 0 . Этот факт позволяет построить остановочное правило
в классе последовательных многошаговых процедур, когда процесс
испытаний состоит по крайней мере из двух стадий (двухвыборочная процедура Стейна). Момент остановки ищется в виде:
N 0m ( Z ) = max {n1 , n2 ( Z )} ,
где n1 — число реализаций на первой стадии испытаний, ( n2 − n1 ) —
число дополнительных реализаций, выполняемых на второй стадии
испытаний.
Пусть s12 — оценка дисперсии на первой стадии, а z — среднее,
построенное по общему объему испытаний n2 . Поскольку
191
V=
(
n2 z − m2
)
σ
следует нормированному нормальному распределению N(0, 1), а
V1
n1 − 1) s12
(
=
σ2
следует χ 2 — распределению с n1 − 1 степенями свободы, то статистика t вида
t=
V
V1 ( n1 − 1)
−1
=
(
n2 z − m2
)
s1
снова следует t-распределению с n1 − 1 степенями свободы. Тогда
вероятность ошибки второго рода, соответствующая любому фиксированному моменту n на второй стадии испытаний определяется
как
⎧ m − m2
α ⎤
⎡
n − t ⎢ n1 − 1, 1 − 0 ⎥ ≤ t ≤
β ( m2 , n s1 ) = P ⎨ 1
2⎦
⎣
⎩ s1
≤
α ⎤⎫
m1 − m2
⎡
n + t ⎢ n1 − 1, 1 − 0 ⎥ ⎬ .
s1
2 ⎦⎭
⎣
Таким образом, в зависимости от s1 , полученной на первой стадии, подбирается общий объем испытаний n2 ( Z ) такой, чтобы ми-
нимизировать β ( m2 , n s1 ) до допустимого уровня β 0 :
{
}
n2 ( Z ) = min n ≥ n1 : β ( m2 , n s1 ) ≤ β 0 .
Поскольку точностные характеристики m, σ анализируются совместно, то объем испытаний на первой стадии n1 определяется
усеченным последовательным моментом остановки N 0 ( Z ). Тогда
параметрическое правило остановки процесса испытаний получается в виде:
{
}
N 0 ( Z ) = max N 0σ ( Z ), n2 ( Z ) .
192
При остановке процесса испытаний в соответствии с последним
правилом решение о состоянии точностных характеристик принимается на основе последовательного решающего правила:
⎧⎪a1 ,
s 2 , t ∈ G1 ,
aN ( Z ) = ⎨
s 2 , t ∉ G2 ,
⎪⎩a2 ,
где
N 0 z − m1
,
t=
s1
α ⎤⎫
⎧
⎡
G1 = ⎨ s 2 , t : s 2 < Bn , t ≤ t ⎢ n1 − 1, 1 − 0 ⎥ ⎬ ,
2 ⎦⎭
⎣
⎩
(
(
(
(
)
)
)
)
⎧
α ⎤⎫
⎡
G2 = ⎨ s 2 , t : s 2 < An , t ≤ t ⎢ n1 − 1, 1 − 0 ⎥ ⎬ .
2 ⎦⎭
⎣
⎩
(
)
Рассмотрим оптимальное последовательное правило остановки
процесса испытаний, которое может быть применено для оценки
соответствия точностных характеристик бокового движения заданным требованиям при автоматическом пробеге и разбеге самолета.
Очевидно, что если реализация случайного процесса на интервале длительностью Т находится в допустимой области, то количество выходов k процесса за эту область на интервале Т равно нулю.
Тогда условие
Pr {Z (t ) ∈ D t ∈ T } ≥ PT
может быть представлено в следующей эквивалентной форме:
Pr{k (T ) = 0} ≥ PT .
Общее выражение для распределения числа выходов случайного процесса за допустимый уровень дается законом Пуассона:
Λk
exp{−Λ},
Λ = λT ,
k!
где λ и Λ — среднее число пересечений процессом заданного уровня в единицу времени и на интервале Т соответственно. Тогда вероятность отсутствия выходов за допуск на интервале Т равна:
P(k , T ) =
P (0, T ) = exp{−Λ}.
193
На основе этого соотношения условие соответствия точностных
характеристик заданным требованиям может быть сформулировано
в виде:
Λ ≤ ΛT = − ln PT .
Формальная постановка задачи анализа соответствия точностных характеристик заданным требованиям на основе результатов
испытаний сводится к принятию одного из двух решений: a1 : Λ ≤ Λ1
(система соответствует требованиям) или a2 : Λ > Λ 2 , где
Λ1 ≤ Λ < Λ 2 ; Λ1 = − ln P1 , Λ 2 = − ln P2 ;
P1 ≥ PT > P2 .
Пусть в результате n независимых испытаний получена выборка
значений числа выходов реализаций определяющего параметра
движения самолета за допустимую область {k1 , k2 , ..., kn } . Функция
правдоподобия дискретной случайной величины есть произведение
вероятностей P ( ki Λ ) появления равенств K i = ki , i = 1, 2, ..., n [16]:
P ( k1 ,..., kn Λ ) =
Λ k1 −Λ Λ kn −Λ
Λk
e ...
e =
e−Λn ,
k1 !
kn !
k1 !...kn !
где k = ∑ ki число выходов параметра за допустимую область в соi
вокупности n испытаний.
Отношение правдоподобия выборки для двух альтернативных
состояний Λ 2 и Λ1 точностных характеристик имеет вид:
k
⎛Λ ⎞
Ln = ⎜ 2 ⎟ exp {( Λ1 − Λ 2 ) n} ,
⎝ Λ1 ⎠
а логарифм отношения записывается в виде:
ln Ln = k ln
Λ2
+ ( Λ1 − Λ 2 ) n.
Λ1
Последовательное ( α 0 , Λ1 , β 0 , Λ 2 ) — правило остановки процесса испытаний имеет вид:
N 0 (k ) = min {n ≥ 1: k ∉ ( d n , cn )} ,
194
где
d n = g1 + g 0 n,
g0 =
Λ 2 − Λ1
,
Λ2
ln
Λ1
cn = g 2 + g 0 n,
β
1 − β0
ln 0
ln
1 − α0
α0
g1 =
, g2 =
.
Λ2
Λ2
ln
ln
Λ1
Λ1
При остановке процесса испытаний в соответствии с правилом
N 0 (k ) решение о состоянии точностных характеристик принимается в соответствии с алгоритмом:
k ≤ dn ,
⎧a ,
aN ( k ) = ⎨ 1
k ≥ cn .
⎩a2 ,
Рассмотренные выше последовательные моменты остановки испытаний при достижении заданной точности и достоверности контроля могут быть использованы при построении динамических планов испытаний при оптимальном планировании комплекса испытаний, а также в информационной вычислительной системе сопровождения технической эксплуатации самолетов гражданской авиации.
4.6. Прогнозирующий контроль точностных
характеристик
Рассмотрим возможность прогнозирования точностных характеристик системы автоматического управления с использованием
статистических методов по результатам измерений определяющих
параметров, характеризующих автоматическую посадку, проведенных на момент прогноза [40, 55]. При наличии современной информационной базы прогнозирующий контроль может быть использован наиболее эффективно на этапе эксплуатации.
Измерение определяющих параметров процесса автоматического приземления в точке касания позволяет оценить качество посадки и, следовательно, техническое состояние системы автоматической посадки. Хотя в современных бортовых системах управления
используются различные виды резервирования (аппаратного и программного), но это не исключает возникновения особых ситуаций
из-за возможных отказов в системе управления, что приводит к необходимости прогнозирования технического состояния системы
управления для повышения безопасности полетов.
195
Возможность прогнозирования технического состояния основана на том, что отказы сложных динамических систем возникают
обычно не из-за выхода из строя отдельных элементов или блоков,
а из-за ухудшения и выхода за допустимые пределы их характеристик, которые отражают функциональное назначение системы. При
решении задач прогнозирования целесообразно использовать не
модель системы, а модель параметров, которые характеризуют работоспособность этой системы.
Прогнозирование технического состояния системы управления
конкретного самолета называют индивидуальным вероятностным
[29]. Индивидуальное прогнозирование основано на неявной аппроксимации изменения моментных характеристик прогнозируемого процесса: условного математического ожидания
M Z {Z n Z1 , Z 2 , ..., Z N } = M n
и условной дисперсии
σ 2Z {Z n Z1 , Z 2 , ..., Z N } = σ n2 ,
которые отображают процесс смены технического состояния объекта в ожидаемых условиях эксплуатации. Аппроксимация осуществляется по ряду независимых значений определяющих параметров Z n , измеренных в моменты посадок (n = 1, 2, …, N) с целью
последующей экстраполяции этих параметров на будущие посадки
N + T, (T — интервал упреждения, обусловленный количеством будущих посадок).
Пусть априорные сведения про вид аппроксимирующих функций M n и σ 2n отсутствуют. Допустим, что среднее значение и дисперсия прогнозируемого параметра могут быть аппроксимированы
полиномами невысокого порядка. В этом случае модель прогнозируемого параметра будет иметь вид:
Zn = M n + ξn ,
где
j
M n = ∑ ai ni ,
i =0
а ξ n — некоррелированная случайная составляющая с нулевым математическим ожиданием, в общем случае нестационарная по дисперсии, j — максимальная степень полинома.
196
Исходя из того, что для вероятностного прогноза необходимо
иметь упрежденные оценки математического ожидания и дисперсии,
на интервале наблюдения необходимо выявить тенденцию их изменения. Для этого нужно разбить весь интервал наблюдения на равные подынтервалы и в каждом из них определять оценки средних и
дисперсий. При этом необходимо решить вопрос про объем выборки
в подынтервале. Очевидно, что чем больше объем, тем точнее оценки,
однако в этом случае можно не заметить изменения оценок во времени.
Шаг прогноза должен быть равен интервалу дискретизации исследуемого ряда на интервале наблюдения. В данном случае прогноз на один шаг вперед соответствует упреждению на количество
посадок в подынтервале (объему мгновенной выборки). Пусть объем подвыборки равен 10, а минимальный объем общей выборки, по
которой определяется характер модели, равен 100. Таким образом,
упреждение на один шаг вперед будет составлять десять посадок, а
интервал упреждения оценок среднего и дисперсии будет равен
единице. Далее рассмотрим пример прогнозирования значений бокового отклонения самолета в точке касания. Он состоит из следующих этапов.
Расчет оценок математических ожиданий и среднеквадратических отклонений. Оценки в пределах одной подвыборки для всех
подвыборок по очереди (объем подвыборки N = 10 при i = 1, 2, …,
N, количество подвыборок L = 10 при l = 1, 2, …, L, общее переменное количество значений исследуемого ряда n = l × N) определяются по стандартным формулам:
Zl =
1 N
∑ Zi ,
N i =1
Sl =
(
N
1
∑ Zi − Z l
N − 1 i =1
).
2
Аппроксимация трендов. В результате аппроксимации трендов
полиномами первого порядка с помощью метода наименьших квадратов определяют их коэффициенты:
Z l = a0 + a1l ,
Sl = b0 + b1l.
После аппроксимации трендов проводится прогнозирование.
При построении любой прогнозирующей модели выдвигают гипотезу о динамике величины ξ n , т.е. о характере тренда. В рассматриваемом случае задача имеет ряд отличительных черт.
197
Хотя прогнозирование ведется на основании ряда средних в
подвыборках, однако оно должно отражать свойства всего ряда n =
100. Поэтому используемый метод должен быть эффективным при
исследовании рядов с большим количеством наблюдений.
Процесс изменения характеристик исследуемого ряда имеет достаточно большую инерцию, в результате которой в прогнозируемом
периоде процесс будет происходить приблизительно в тех же условиях, что и в анализируемом. Следовательно, используемый метод
должен придавать большую значимость старшим значениям ряда.
Кроме того, с приходом новой информации в объеме подвыборки L = 10, выборка (n = 100) смещается вперед на один шаг (одну
подвыборку), а значение первой (самой ранней подвыборки) опускается., т.е. исследуемый ряд постоянно обновляется. Таким образом, используемый метод должен быть адаптивным к изменению
значений исследуемого ряда.
Исходя из этого, для прогнозирования целесообразно выбирать
адаптивный метод экспоненциального сглаживания, идея которого
состоит в том, что ряд динамики сглаживается с помощью взвешенной экспоненциальной средней, вес которой подчиняется экспоненциальному закону и характеризует последние значения ряда.
Основным содержанием процедуры экспоненциального сглаживания является вычисление по рекуррентным формулам коэффициентов сглаживающего полинома, выбор начальных значений и оптимального значения параметра θ.
Определение начальных значений и параметра сглаживания.
Экспоненциальную среднюю можно определить с помощью рекуррентной формулы Брауна :
Stk ( y ) = θStk −1 ( y ) + (1 − θ)Stk−1 ( y ).
Точных рекомендаций по выбору оптимальной величины параметра сглаживания θ и начальных значений нет. С учетом особенностей рассматриваемой задачи, логично выбрать значение θ, исходя из длины интервала сглаживания [71]:
2
,
θ=
L +1
где L — количество подвыборок ряда.
Начальные значения первой и второй степени для выбранной
линейной модели определяются из соотношений (соответственно
для значений среднего и среднеквадратического отклонения):
198
(1)
S z 0 = a0 − a1
1− θ
,
θ
(2)
S z 0 = a0 − a1
2(1 − θ)
,
θ
1− θ
2(1 − θ)
,
Ss0(2) = b0 − b1
,
θ
θ
а значение S (0) , исходя из длины исследуемого ряда, рекомендуется определять по первым значениям рассчитанных трендов соответствующих подвыборок [54]:
Ss0(1) = b0 − b1
S z
(0)
1 5
= ∑Zi,
5 i =1
1 5
Ss (0) = ∑ Si .
5 i =1
Определение моделей прогноза и оценок их коэффициентов.
Для прогнозирования значений среднего оценки коэффициентов
a0∗ и a1∗ определяются из выражений:
(1)
(2)
a0∗ = 2 S z l − S z l ,
(1)
(2)
θ
a1∗ =
S z l − S z l
1− θ
Аналогично для прогноза значений среднеквадратического отклонения рассчитываются оценки коэффициентов b0∗ и b1∗ :
)
(
b0∗ = 2Ssl(1) − Ssl(2) ,
θ
b1∗ =
Ssl(1) − Ssl(2) .
1− θ
Расчет прогнозных значений. Прогнозные значения средних и
среднеквадратических отклонений на один шаг вперед определяются в соответствии с выражениями:
Z L +1 = a0∗ + a1∗ ( L + 1),
S = b∗ + b∗ ( L + 1).
(
L +1
0
)
1
Определение ошибок прогноза. Среднеквадратические ошибки
прогнозных значений определяют как произведение среднеквадратических ошибок, вычисленных для соответствующих отклонений
от линейных трендов исследуемых рядов и коэффициента Δ, который учитывает значения выбранного ранее параметра сглаживания
θ и периода упреждения Т [54]:
199
σ∗ZT = σ Z Δ,
σ∗ST = σ S Δ,
где
Δ=
θ
⎡1 + 4(1 − θ) + 5(1 − θ) 2 + 2θ(4 − 3θ)T + 2θ 2T 2 ⎤⎦ .
3 ⎣
(2 − θ)
Таким образом, интервалы прогнозных значений с учетом ошибки прогнозирования определяются как
н
в
Z T = Z L +1 ± σ∗ZT = ⎡⎢ Z T ; Z T ⎤⎥ ,
⎣
⎦
ST = SL +1 ± σ∗ST = ⎡⎣ STн ; STв ⎤⎦ .
Оценка результатов прогнозирования. Оценку полученного прогноза целесообразно проводить с помощью проверки гипотезы о
среднеквадратическом отклонении H 0σ : σ ≤ σ 0 против альтернативы H1σ : σ > σ1 , а также проверки гипотезы о математическом ожидании H 0m : m = 0 против альтернативы H1m : m > m1 (см раздел 4.2)
при заданных уровнях ошибок α и β, таких что
αm = ασ =
α
β
, πm = πσ = 1 − .
2
2
Проверка гипотезы о среднеквадратическом отклонении. При
проверке гипотезы H 0σ величина σ берется равной верхнему значению интервального прогноза S в . Значение σ как предельно
T
1
значение задается нормативными документами. Значение σ 0 определяется с помощью интеграла вероятностей χ 2 :
⎧⎪
Cкр σ 02 ⎫⎪
P ⎨χ 2 >
⎬ =1− β ,
σ12 ⎭⎪
⎩⎪
где Cкр (α σ , L − 1) — квантиль χ 2 — распределения.
Наблюденное значение статистики определяется выражением
Cнσ =
( L − 1)σ 2
.
σ 02
200
При Cнσ ≤ Скр принимается гипотеза H 0 и делается вывод, что
разброс прогнозируемого значения бокового отклонения на принятом уровне значимости находится в допустимых пределах. В случае если Cнσ > Скр гипотеза H 0 отвергается и делается вывод, что
ожидаемый разброс прогнозного значения может превысить допустимые пределы.
Проверка гипотезы о математическом ожидании. Альтернативное значение m1 определяется решением уравнения:
⎛Z −m⎞
⎛ Zн − m ⎞
Φ⎜ в
⎟ − Φ⎜
⎟ = РТ .
⎝ σ0 ⎠
⎝ σ0 ⎠
Наблюденное значение статистики критерия определяется формулой:
в
Z T − 0
C =
n ,
σ0
m
н
а критическое значение статистики Cкрm определяется как квантиль
1 − αm
. Если Cнm ≤ Cкрm , то ги2
потеза H 0 не отвергается на уровне значимости α m . В случае
Cнm > Cкрm делается вывод о возможном смещении приземлений на
момент прогноза. При наличии систематического смещения приземлений (при условии, что STв < σ 0 ) проверяется гипотеза о допустимости такого смещения. Для этого определяется критическое
значение mкр из уравнения
нормального распределения уровня
⎛ mкр − m1
⎞
⎛ − mкр − m1
⎞
Φ⎜
n ⎟ − Φ⎜
n ⎟ = βm .
σ0
⎝ σ0
⎠
⎝
⎠
в
Если Z T < mкр , то делается вывод о допустимости возможного
смещения приземлений на момент прогноза.
На рис. 4.19 показаны результаты работы алгоритма по обработке результатов статистического моделирования автоматического приземления самолета.
201
По результатам прогнозирования среднеквадратического отклонения и интервала ошибки Cнσ = 13,33 при Cкрσ = 16,92, и, следовательно, принимается гипотеза H : σ = S в < σ .
T
0
0
0,5
0,5
средние
подвыборок
границы 00
прогноза
прогнозное
значение -0,5
–0,5
-1,0
–1,0
22
4
6
6
8
10
10
LL
Рис. 4.19. Результаты прогнозирования бокового отклонения
самолета при автоматической посадке
По результатам прогнозирования среднеквадратического отклонения и интервала ошибки Cнm = 2, 25 при Cкрm = 1,96 , и, следовательно, принимается альтернативная гипотеза H1 : m > m1 , т.е. делается вывод о возможном наличии смещения на момент прогноза.
Однако на уровне значимости α m = 0,05, при мощности критерия
π = 0,95 критическое значение mкр = 11,9. Так как полученное значев
в
ние верхней границы прогноза Z T = −1,16, то Z T < mкр и делается
вывод о допустимости смещения приземлений на момент прогноза.
202
5
ОЦЕНКА ВЕРОЯТНОСТНЫХ
ХАРАКТЕРИСТИК
ПРИ СТАТИСТИЧЕСКОМ
МОДЕЛИРОВАНИИ
5.1. Метод статистических испытаний
В начале шестидесятых годов в литературе на английском языке
появился термин «simulation». Он возник в связи с использованием
метода Монте-Карло (в нашей литературе этот метод чаще называют
методом статистических испытаний) для исследования процессов, зависящих от случайных параметров или функций. Рассмотрим уравнение
z = f ( z , t , ξ),
где z — фазовая переменная (переменная состояния), ξ — случайный параметр, закон распределения которого известен. Предположим, что рассматривается задача Коши для этого уравнения: определить решение уравнения, удовлетворяющее условию
z(0) = η,
где η — некоторая случайная величина с известным законом распределения. В этом случае решение z(t) будет некоторой случайной
функцией времени, а значение z (t0 ) в некоторый фиксированный
момент времени t0 будет случайной величиной.
Если функция f является существенно нелинейной, то для решения этой задачи нет никаких универсальных методов решения.
Тем не менее в распоряжении исследователя всегда есть один
прием: использование метода статистических испытаний.
С помощью датчика случайных чисел можно определить последовательность случайных чисел
⎧ξ1 , ξ 2 , ..., ξ n ,
⎨η , η , ..., η ,
n
⎩ 1 2
и для каждой пары чисел {ξ i , ηi } стандартным способом решить
задачу Коши и находить последовательность
z1 (t0 ), z2 (t0 ),..., zn (t0 ).
203
Этот прием анализа легко распространяется и на более сложные
случаи, когда уравнение содержит не только случайные параметры,
но и случайные функции.
Необходимо отметить два обстоятельства. Во-первых, описанный прием анализа можно рассматривать как экспериментальное
определение статистических характеристик случайного процесса
Z(t) с помощью машинного эксперимента. Во-вторых, приведенный способ исследования можно трактовать как анализ динамического процесса, заданного системой дифференциальных уравнений
с помощью вариантных расчетов. Оба обстоятельства сыграли важную роль в развитии техники имитации и имитационных систем.
Под имитационной системой понимается совокупность моделей, имитирующих протекание изучаемого процесса, объединенная
специальной системой вспомогательных программ и информационной базой, позволяющих достаточно просто и оперативно реализовать вариантные расчеты.
Заметим, что использование имитационных систем в автоматизированных системах управления становится все более и более необходимым по мере того, как они из систем обработки данных постепенно превращаются в системы принятия решений.
Таким образом, метод статистических испытаний можно определить как метод решения математических задач и задач исследования
сложных систем при помощи моделирования случайных реализаций
и имитации случайных процессов, происходящих в сложных системах, с последующей оценкой их вероятностных характеристик.
Известны три метода статистического исследования сложных
систем:
• метод статистических испытаний,
• метод эквивалентных возмущений,
• метод статистических узлов (интерполяционный метод).
Схема метода статистических испытаний наиболее проста и состоит в следующем (рис. 5.1):
• Моделируется вектор случайных величин Λ = {λ1 , λ 2 , ..., λ n } ,
входящих в систему дифференциальных уравнений, в соответствии
с заданными законами распределения.
• Для конкретных значений λ1 , λ 2 , ..., λ n решается система дифференциальных уравнений, в результате чего получаются реализации zi (t , Λ) , как функции времени.
• Вычисление приближеного значения вероятностной характеристики вектора выходных координат
204
G
1 N
∑ Φ k ⎡⎣ Z i (t , Λ i ) ⎤⎦, k = 1, n ,
N i =1
где некоторый функционал Φ k определяется соотношением
G
Φ k = Φ k ⎡⎣ Z (t ), t ⎤⎦ .
M {Φ k } =
Ввод исходных
данных
Получение реализаций
случайных воздействий
Датчик случайных
чисел
Решение уравнений
динамики системы
Предварительная
обработка статистических
данных
Cсетчик числа
испытаний N
N < Nзад
Оценка точностных
характеристик
процесса управления
Вывод
результатов
Рис. 5.1. Общая структура моделирования сложных
динамических систем
Например, если
то
G
Φ k ⎡⎣ Z (t ) ⎤⎦ = Z k (t ), k = 1, n,
M {Φ k } = M {Z k (t )}
и, следовательно, в данном случае определяются оценки математических ожиданий вектора выходных координат объекта.
205
Для вычисления оценки дисперсии необходимо положить
JG
2
Φ k [ Z (t ), t ] = ⎣⎡ Z k (t ) − M {Z k (t )}⎤⎦ , k = 1, n,
тогда
M {Φ k } = D {Z k (t )} .
Рассмотрим случай, когда основным критерием оценки качества
функционирования системы управления является вероятность нахождения вектора выходных координат в заданной области. Пусть
пределы, в которых по условиям эксплуатации системы управления
JG
должны находиться определяющие параметры вектора Z (t ) в интервале времени [t1 , t2 ] , заданы системой неравенств
li (t ) ≤ Z i (t ) ≤ ui (t ), i = 1, n .
Тогда функционал Фk в данном случае может быть выбран в виде
Φ=
z (t ) − ui (t ) ⎤ ⎡
zi (t ) − li (t ) ⎤
1 n ⎡
1− i
⎥ ⎢1 +
⎥,
n ∏⎢
zi (t ) − ui (t ) ⎥⎦ ⎢⎣
zi (t ) − li (t ) ⎥⎦
4 i =1 ⎢⎣
откуда следует, что при выполнении всех неравенств Ф = 1, а при
нарушении неравенства хотя бы при одном индексе Ф = 0.
Таким образом, математическое ожидание функционала определяет JG
вероятность нахождения вектора координат системы управления Z (t ) в заданной области [L, U], определяемой системой неравенств, т.е.
JG
M {Φ} = Pr Z (t ) ∈ D[ L, U ] .
{
}
Вычисление же приближенного значения вероятностной характеристики вектора выходных координат системы методом статистического моделирования осуществляется простым алгоритмом
M {Φ k } ≈
1 N
∑ Φk ,
N i =1
k = 1, n.
Структура алгоритма метода эквивалентных возмущений проще, чем в методе статистического моделирования. Расчетная формула имеет вид:
N
G
M {Φ k } ≅ ∑ ai Φ k ⎡⎣ Z i (t , Λ i ) ⎤⎦,
i =1
206
где коэффициенты ai и составляющие вектора Λ i связаны специальной системой алгебраических уравнений по заданным моментным характеристикам случайной величины Λ[31, 32].
Существуют задачи, для решения которых метод эквивалентных
возмущений оказывается более эффективным, чем метод статистического моделирования.
Например, если рассматривается система с одним случайным
параметром Θ , функциональная связь которого с выходной координатой может быть с достаточной точностью описана квадратичным полиномом вида
Z = A + BΘ + C Θ 2 , где А, В и С — неслучайные постоянные или же переменные коэффициенты.
Для определения математического ожидания M{Z} методом статистического моделирования необходимо получать случайные реализации параметра Θ, накапливать статистический материал о величине Z и по обычным формулам статистической обработки найти M{Z}.
Рассмотрим решение этой задачи методом эквивалентных возмущений. Переходя в записанной выше функциональной зависимости справа и слева от случайных величин к их математическим
ожиданиям, получим
(
)
M {Z } = A + BmΘ + C σ Θ2 + mΘ2 ,
где σ Θ2 — дисперсия, а mΘ — математическое ожидание Θ.
Предположим, что M{Θ} = 0. Это предположение, очевидно, не
нарушает общности рассуждений. Тогда
M {Z } = A + Cσ Θ2 .
Для того, чтобы вычислить M{Z} по этой формуле, достаточно в
исходную функциональную зависимость подставить всего два различных значения величины Θ, а именно:
ξ1 = σ Θ , ξ 2 = −σ Θ .
В результате подстановок получим
Z1 = A + Bσ Θ + Cσ Θ2 ,
Z 2 = A − Bσ Θ + Cσ Θ2 .
207
Определив полусумму величин Z1 и Z 2 находим
Z1 + Z 2
= A + Cσ Θ2 .
2
Сравнивая это выражение с полученным ранее выражением для
M[Z], очевидно, можем записать:
M {Z } =
Z1 + Z 2
.
2
Таким образом, в результате только двух подстановок (а не тысяч или десятков тысяч, как в методе статистического моделирования) получено точное значение M{Z}. Величины ξ1 и ξ 2 в данном
случае являются эквивалентными возмущениями.
В общем случае уравнения динамики системы имеют вид:
dz1
= f1 ( z1 , z2 , ..., zn ; Θ1 , Θ2 , ..., Θ m ; t ) ,
dt
dz2
= f 2 ( z1 , z2 , ..., zn ; Θ1 , Θ 2 , ..., Θm ; t ) ,
dt
...........................................................
dzn
= f n ( z1 , z2 , ..., zn ; Θ1 , Θ2 , ..., Θm ; t ) ,
dt
где роль случайных возмущений выполняют случайные параметры
Θi , i = 1, m , не зависящие от времени t и выходных координат
zi , i = 1, n.
Не нарушая общности можно считать, что M {Θi } = 0. Будем рассматривать одну из выходных координат системы, обозначив ее
просто Z. Тогда решение для Z имеет общий вид:
Z = φ ( t ; Θ1 , Θ 2 , ..., Θm ) .
Функция φ может быть разложена в ряд Маклорена по величинам Θr . Ограничиваясь членами q-й степени, получаем:
∂k φ
1 m m m ⎛
∑ ∑ ... ∑ ⎜⎜
k =1 k ! r1 =1 r2 =1 rk =1 ∂θ r ∂θ r 2 ...∂θ r
k
⎝ 1
q
Z = φ0 + ∑
208
⎞
⎟ θ r1 θ r2 ...θ rk ,
⎟
⎠0
где φ0 = φ(t ; 0, 0, ..., 0) . Индекс ноль у частных производных означает, что они вычисляются в точке (t; 0, 0, …, 0).
Переходя от случайных величин к их математическим ожиданиям, можно получить:
∂k φ
1 m m m ⎛
...
⎜
∑∑ ∑
k =1 k ! r1 =1 r2 =1 rk =1 ⎜ ∂θ r ∂θ r 2 ...∂θ r
k
⎝ 1
q
M {Z } = φ 0 + ∑
{
⎞
⎟ μ r1r2 ...rk ,
⎟
⎠0
}
где μ r1r2 ...rk = M θ r1 θ r2 ... θ rk , k = 1, q; r1 = ... = rk = 1, 2, ..., m — центральные моменты высших порядков.
Метод эквивалентных возмущений позволяет избежать трудностей в вычислении частных производных. Подставляя в выражение
для Z частные реализации ξ rs параметров θ r , и проводя его разложение по этим параметрам, получаем подобное выражение:
∂k φ
1 m m m ⎛
∑ ∑ ... ∑ ⎜⎜
k =1 k ! r1 =1 r2 =1 rk =1 ∂θ r ∂θ r 2 ...∂θ r
k
⎝ 1
q
Z s = φ0 + ∑
⎞
⎟ ξ r1s ξ r2 s ...ξ rk s
⎟
⎠0
Величины ξ rk s называются эквивалентными возмущениями.
Далее выбирают N различных комбинаций эквивалентных возмущений ξ rk s ( s = 1, 2, ..., N ) :
ξ11 , ξ 21 ,...,ξ m1 ,
ξ12 , ξ 22 ,...,ξ m 2 ,
.......................
ξ1N , ξ 2N ,...,ξ mN ,
и подставляют их в равенство для Z. Получаются N равенств вида
Z s . Умножая обе части их на некоторые коэффициенты (пока не
определенные) as , и суммируя их почленно, находим
N
1 m m m
∑ ∑ ... ∑ ×
k =1 k ! r1 =1 r2 =1 rk =1
q
N
S = ∑ a s Z s = φ 0 ∑ as + ∑
s =1
s =1
⎛
∂ φ
×⎜
⎜ ∂θ r ∂θ r 2 ...∂θ r
k
⎝ 1
k
⎞ N
⎟ ∑ as ξ r1s ξ r2 s ...ξ rk s .
⎟ s =1
⎠0
209
Сопоставляя равенства для M{Z} и S, можно заметить, что сумма S будет приближенно равна математическому ожиданию M{Z}
выходной координаты системы, если величины as и ξ rk s удовлетворяют следующей системе алгебраических уравнений:
⎧ N a = 1,
s
⎪ s∑
=1
⎪N
⎨ ∑ a ξ ξ ...ξ = μ
r1r2 ...rk ,
⎪ s =1 s r1s r2 s rk s
⎪
⎩k = 1, q; r1 , r2 , ..., rk = 1, 2, ..., m.
Действительно, выбирая в качестве величин as и ξ rk s какое-либо
действительное решение этой системы уравнений, получаем, что
N
S = ∑ as Z s = M {Z }.
s =1
В [32] показано, что для N = Cmq + q система уравнений при надлежащем выборе величин ξ rk s имеет действительное решение. Однако при этом число N будет, как правило, весьма значительным.
При практических вычислениях целесообразно в каждом конкретном случае в зависимости от числа учитываемых случайных величин m и степени q аппроксимирующего полинома выбрать такую
совокупность эквивалентных возмущений ξ rk s , чтобы по возможности большее число коэффициентов as обратить в нуль.
При сравнительно небольших числах m и q метод эквивалентных возмущений оказывается достаточно простым и экономичным
с точки зрения объема вычислительной работы. Однако, прямая
попытка применения метода при большом (порядка десятков) числе случайных параметров, влияющих на динамику системы, а также при учете связей между этими параметрами, приводит к столь
сложным вычислениям, что оказывается более целесообразным использование методы статистического моделирования.
Отметим также, что метод эквивалентных возмущений разработан лишь для расчета моментных характеристик вектора выходных
характеристик, в то время как метод статистического моделирования в принципе можно применять и для определения законов распределения выходных координат системы.
210
Расчетные формулы интерполяционного метода имеют аналогичный вид [75, 76]:
N
G
M {Φ k } ≅ ∑ ρi Φ k ⎡⎣ Z i (t , Λ i ) ⎤⎦ ,
i =1
где ρ i — некоторые постоянные числа (числа Кристоффеля).
Как в методе эквивалентных возмущений, так и в интерполяционном методе нет необходимости генерировать выборки случайных величин. Но узлы интерполирования должны выбираться оптимальным образом в соответствии с конкретными законами
распределения случайной величины Λ. Имеются таблицы оптимальных чисел ρ i и оптимальных вариантов узлов интерполирования (узлов Чебышева) для случайных величин, имеющих равномерный или нормальный законы распределения.
В тех случаях, когда закон распределения вероятностей отличается от равномерного или нормального, применение интерполяционного метода предполагает предварительное нелинейное преобразование вида λ = Ψ(θ), приводящее заданное распределение вероятностей к какому-либо из указанных выше распределений. Функция
Ψ(θ) определяется уравнением
Pθ (θ) = Pλ [Ψ (θ)],
где Pλ — интегральный закон распределения вероятностей случайной величины λ, Pθ (θ) — интегральный закон распределения случайной величины, для которой таблицы узлов Чебышева имеются
(или есть аналитические формулы).
Все вычисления могут быть проделаны заранее, а результаты
использованы во время решения основной задачи в качестве исходных данных. Также как и в методе эквивалентных возмущений,
при увеличении числа возмущающих воздействий в интерполяционном методе число требуемых реализаций существенно возрастает.
Не останавливаясь подробно на достоинствах и недостатках
рассмотренных методов отметим, что из приведенных в [56] рекомендацией следует, что при большом числе случайных воздействий
единственно применимым является метод статистического моделирования.
Укажем на основные особенности статистического моделирования бортовых систем управления, влияющие на его эффективность:
211
• подтверждение высокой точности функционирования системы
управления, определяемой вероятностями порядка 0,94 ÷ 0,96 , требующее огромного количества статистических данных;
• большое число случайных факторов, определяющее многомерность факторного пространства и влияющее на точность управления.
Отметим также некоторые достоинства метода статистического
моделирования:
• при определении статистических характеристик полученные
значения реализаций суммируются последовательно и независимо
от их требуемого числа N; при необходимости увеличения числа
реализаций (по результатам оценки погрешности вычислений) все
вычисленные ранее значения используются для оценки характеристики (рекуррентный алгоритм);
• порядок убывания погрешности оценки статистической характеристики не зависит от числа случайных воздействий;
• алгоритмы оценки погрешности достаточно просты и используются параллельно с основными вычислениями.
Хотя алгоритм статистического моделирования имеет медленную сходимость, т.е. для решения ряда задач требуется достаточно
большое число реализаций, однако можно предложить некоторые
модификации метода, которые в зависимости от конкретной задачи
позволяют значительно повысить порядок сходимости при определенных условиях, что будет рассмотрено ниже.
Как уже отмечалось, метод статистических испытаний предусматривает многократный проигрыш различных условий полета.
Поскольку на модели получить выборку неограниченного объёма
нельзя, то в результатах моделирования будут присутствовать случайные ошибки, обусловленные конечным числом реализаций. Характеристики распределения этих ошибок зависят в первую очередь от принятого способа обработки полученных результатов.
Так, если используемая модель динамики полёта предназначена
для оценки математического ожидания некоторого показателя точности R(t), то среди всех линейных несмещенных оценок среднее
арифметическое
1 N
R* = ∑ ηi
N i =1
будет эффективной оценкой истинного значения в том смысле, что
R* имеет наименьшую дисперсию.
212
Оценку погрешности R* для независимых реализаций статистического моделирования на модели можно получить с помощь неравенства Чебышева
1
P R* − R ≥ ε ≤ 2 D R* ,
ε
где ε — некоторая заданная относительная погрешность расчета.
Так как
1
D R* = D {η} ,
N
то, следовательно,
{
}
{ }
{ }
⎧ R* − R
⎫
1
⎪
⎪
Pr ⎨
≥ ε⎬ ≤ 2 .
*
⎪3 D R
⎪ 9ε N
⎩
⎭
{ }
В общем случае число требуемых реализаций N, зависящее от
погрешности ε и заданной доверительной вероятности γ, может
быть выражено приближенной формулой [67, 75]:
N≥
1
.
9(1 − γ )ε 2
Таким образом, имеет место сходимость по вероятности среднего арифметического R* к математическому ожиданию при весьма
широких предположениях.
Кроме того, если σ2 < ∞ и существует третий момент μ3 =
{
= M ξi − R
3
} < ∞, то центральная предельная теорема утверждает,
что распределение
SN 1 N
= ∑ ξk
N N k =1
σ2
и средним R. Более
N
асимптотически нормально с дисперсией
точно, имеет место неравенство
{
}
P S N − RN > σ Nx −
213
1
∞
2π
x
−
t2
2
∫ e dt ≤
co μ 3
σ3 N
,
где со — абсолютная константа, относительно которой известно,
что
0,9051 > co >
1
2π
.
Характерной особенностью этого соотношения является то, что
1
. Очевидно, что ошибпорядок убывания погрешности равен
N
ки, обусловленные конечным числом реализаций на модели, являются контролируемыми в том смысле, что при необходимости они
могут быть уменьшены за счет увеличения объёма моделирования.
Безусловно, это приводит к увеличению затрат, но в разумных пределах этим фактором можно пользоваться для уменьшения суммарной ошибки моделирования.
В то же время известно [17, 63], что погрешность оценивания
среднего значения некоторой случайной величины ξ
M {ξ} =
1
∑ ξi
N i =1
Dξ
, где Dξ — дисперсия несмещенной оценки
N
среднего. Очевидно, что добиться требуемой точности определения
статистических характеристик можно, не только увеличивая число
реализаций N, но и уменьшая значение дисперсии Dξ . Можно так-
пропорциональна
же уменьшая дисперсию Dξ , уменьшить количество реализаций N
при сохранении той же погрешности.
Существует ряд методов задания несмещенной оценки статистической характеристики, обеспечивающих малое значение дисперсии Dξ [34], в частности, использование априорного знания о
характеристиках возмущающих воздействий (см. раздел 5.3).
В заключение отметим, что в качестве критерия точности систем автоматической посадки принимается
критерий заданной вероG
ятности нахождения вектора Z выходных координат самолета в
допустимой области D m на ВПП в момент касания, в процессе разбега и в момент отрыва при взлете. При решении задачи анализа
точности такой критерий приводит к необходимости оценки пара214
метров распределения приземлений в плоскости ВПП
G и определения вероятностной меры Р распределения вектора Z определяющих параметров в допустимой области D m , где m — размерность
G
вектора Z . Поскольку границы допустимой области и требуемые
G
значения вероятностей задаются по каждой координате вектора Z
в отдельности, многомерная задача
K
P {Z ∈ D m } ≥ PT
сводится к последовательности одномерных задач определения вероятностей Pj нахождения каждой составляющей вектора z j в соответствующей допустимой области. Рекомендуемые ICАО величины фактических вероятностей составляют 0,94 ÷ 0,96 , что и обусловливает применение метода статистического моделирования для
оценки точности автоматического приземления, пробега и автоматизированного разбега.
Метод статистических испытаний позволяет более достоверно
имитировать внешние условия для оценивания и прогнозирования
динамических характеристик системы автоматической посадки. Как
правило, в процессе моделирования используется цифровая модель
с 6 степенями свободы для описания продольного и бокового движения с учетом нелинейных связей и с одновременным вводом
всех возмущений, что обеспечивает истинное соотношение между
возмущениями и распределениями возмущений.
Модель системы автоматической посадки воспроизводит реальные условия посадки, состоящие из установившегося ветра, сдвига и
турбулентности, отклонений луча ILS, искривлений и смещений характеристик посадочной полосы, различных конфигураций самолета.
Как правило, входными случайными величинами являются:
• случайные величины с равномерным законом распределения (вес
самолета, момент инерции, центр тяжести, воздушная скорость, место
пересечения глиссады продольное и боковое, высота, трение ВПП);
• случайные величины с нормальным (гауссовским) распределением (установочное значение ILS, крутизна глиссады, ошибка
юстировки угла наклона глиссады, ошибка центрирования глиссадного приемника, шум глиссадного маяка, ошибка настройки крутизны курсового маяка над порогом ВПП, ошибка центрирования
приемника курсового маяка, шум луча курсового маяка, угол захвата глиссады, ошибка радиовысотомера);
215
• случайные величины с табличным заданием распределения
(высота ВПП над уровнем моря, наклон ВПП, длина ВПП). Например, данные о наклонах ВПП мировых аэропортов II и III категории показывают, что распределение сосредоточено в пределах ±0,8%
наклона. Эти данные могут быть нормализованы и представлены в
виде таблицы значений наклона.
Модель ветра и турбулентности включает в себя следующие
элементы:
• установившиеся или постоянные компоненты ветра;
• логарифмическая компонента сдвига ветра;
• турбулентная компонента;
• направление ветра.
Величина и направление ветра рассматриваются как независимые
случайные величины. Независимые комбинации величины и направления ветра порождают все возможные реализации вектора среднего
ветра. Истинное значение скорости среднего ветра раскладывается
на горизонтальную, поперечную и вертикальную компоненты.
Как уже отмечалось, для достижения высокой достоверности
полученных статистических распределений выходных сигналов,
определяемых ограничениями и приближениями моделируемого
процесса, требуется большое число реализаций моделируемых посадок, что обусловлено большим разбросом стохастических входных воздействий и большим количеством их комбинаций. Требуемое число реализаций моделируемой посадки зависит прежде всего
от требований к рабочим характеристикам системы управления,
которые определяются статистически при сертификации, и от ожидаемого уровня доверия (доверительного интервала, вероятностей
ошибок первого и второго рода).
5.2. Особенности статистического моделирования
процессов автоматической посадки
Для статистической оценки математического ожидания
∞
M {ξ} = ∫ x dF ( x)
−∞
случайной величины ξ при отсутствии информации о функции распределения
x
F ( x) = Fξ ( x) = Pr{ξ ≤ x} = ∫ f ( x)dx
−∞
216
применяется формула статистического среднего
1 n
(5.1)
∑ ξ k ≅ M {ξ},
n k =1
где ξk — значения случайной величины ξ в серии n независимых
испытаний, которые могут рассматриваться как независимые случайные величины с одной и той же функцией распределения F(x).
Оценка ξ имеет математическое ожидание, совпадающее с искомым математическим ожиданиям M {ξ}:
ξ=
{}
M ξ =
1 n
1
∑ M {ξ k } = M {ξ}n = M {ξ}
n k =1
n
и дисперсию:
{}
{
}
2
D ξ = M ξ − M {ξ} =
1 n
nD{ξ} D{ξ}
=
D {ξ k } =
.
2 ∑
n k =1
n2
n
Отсюда видно, что дисперсия оценки среднего в n раз меньше
дисперсии исходной случайной величины, т.е. чем больше число
испытаний, тем точнее (с меньшей дисперсией) определяется величина M {ξ} из соотношения (5.1).
Необходимо отметить, что оценка математического ожидания с
использованием метода статистических испытаний является сходящейся (по вероятности). Если рассмотреть произвольную величину ξ, у которой существует математическое ожидание M {ξ} = m
(математическое ожидание существует тогда и только тогда, когда
существует M { ξ }), то для оценки величины m выбирается N независимых реализаций ξ1 , ..., ξ N случайной величины ξ и вычисляется среднее как
ξ=
1 N
∑ ξi .
N i =1
Так как последовательность одинаково распределенных независимых случайных величин, у которых существуют математические
ожидания, подчиняется закону больших чисел [24], то среднее арифметическое этих величин сходится по вероятности к математическому ожиданию при N → ∞ :
P
ξ ⎯⎯
→ m,
217
т.е
{
}
P ξ − m ≥ ε → 0, N → ∞.
Погрешность метода статистических испытаний можно оценить, предположив, что случайная величина ξ имеет конечную
дисперсию
{ }
D {ξ} = M ξ 2 − ⎡⎣ M {ξ}⎤⎦ .
2
Из курса теории вероятностей известно, что последовательность
одинаково распределенных независимых случайных величин с конечными дисперсиями подчиняется центральной придельной теореме, т.е для любых x1 < x2
⎧⎪
lim P ⎨ x1 <
N →∞
⎪⎩
2
⎫⎪
1 x2 − t2
∑ ( ξi − a ) < x2 ⎬ =
∫ e dt.
2π x1
ND {ξ} i =1
⎪⎭
1
N
Выбирая x2 = − x1 = x, можно получить
⎧⎪ 1 N
D {ξ} ⎫⎪
lim P ⎨ ∑ ( ξi − a ) < x
⎬ = Ф ( х),
N →∞
N ⎪
⎪⎩ N i =1
⎭
где Φ ( x) — интеграл вероятностей.
Следовательно, при достаточно больших значениях N
⎧⎪
D {ξ} ⎫⎪
Р⎨ ξ − а < x
⎬ ≈ Ф ( х ).
N ⎪
⎩⎪
⎭
Полученное соотношение зависит от параметра x . Если задать
коэффициент доверия γ , то можно найти корень x = xγ уравнения
Φ ( x) = γ Тогда вероятность неравенства
ξ − а < xγ
приблизительно равна γ , т.е.
Pr ξ − а < xγ
218
D {ξ}
N
D {ξ}
N
= γ.
В частности для xγ = 3 коэффициент доверия γ = 0,997 («правило трех сигм»), а для xγ = 1,96 имеем γ = 0,95.
Как правило, при расчете M {ξ} значение дисперсии D{ξ} неизвестно, поэтому в большинстве задач величину D{ξ} оценивают
эмпирически (при больших n ):
2
1N
⎡1 N ⎤
D {ξ} ≈ ∑ ξi2 − ⎢ ∑ ξi ⎥ ,
n i =1
⎣ n i =1 ⎦
имея в виду, что D{ξ} используется только для оценки ошибки, так
что погрешность порядка 5–10% в значении D{ξ} большого значения не имеет.
Пусть требуется подтвердить с доверительной вероятностью
γ = 1 − δ, δ << 1, что математическое ожидание M {ξ} не превосходит допустимую величину Mдоп, т.е.
Pr {M {ξ} ≥ M доп ξ1 ,..., ξ n } ≤ 1 − γ = δ
или
{
}
Pr M {ξ} − ξ ≥ M доп − ξ ≤ δ.
В соответствии с центральной предельной теоремой закон распределения статистического среднего при n → ∞ стремится к нормальному (формула нормального распределения ошибки ξ − M {ξ}
практически применима уже при n ≥ 50 ) [14]:
{
}
⎛ х
Pr ⎡⎣ ξ − M {ξ}⎤⎦ ≥ x ≈ Ф 0 ⎜
⎜ D ξ
⎝
{}
⎞
⎛ х
⎟ =1− Ф⎜
⎟
⎜ D ξ
⎠
⎝
{}
{}
⎞
⎟, х < 3 D ξ ,
⎟
⎠
где Φ (•) — функция стандартного нормального распределения:
2
1 ( •) − t2
Ф (•) =
∫ е dt ,
2π −∞
а Φ 0 (•) — вероятностная функция.
219
Таким образом:
⎛ М −ξ
⎞
Ф ⎜ доп
n⎟≤δ
⎜ D {ξ}
⎟
⎝
⎠
или
М доп − ξ
D {ξ}
n ≥ Ψ (δ) ⇒ n ≥
D {ξ}
⎡ М доп − ξ ⎤
⎣
⎦
2
Ψ2 (δ),
(5.2)
где Ψ (δ) = Φ −1 (δ) — функция, обратная функции нормального распределения (квантиль нормального распределения).
Очевидно, что число испытаний n сильно зависит от величины
«запаса» M доп − ξ , т.е. с чем большим запасом выполняется условие M {ξ} < M доп , тем меньше испытаний требуется для его подтверждения.
Пусть требуется методом статистических испытаний оценить
функцию распределения
Fξ ( c ) = Pr {ξ ≤ c}
или вероятностную функцию
∞
Fξ ( c ) = Pr {ξ ≥ c} = ∫ dFξ ( x ) = 1 − Fξ ( c )
c
как вероятность превышения случайной величиной ξ порога с. Такая задача сводится к статистической оценке математического
ожидания случайной величины
⎧0, ξ ≤ c
ω = ω( c − ξ) = ⎨
⎩1, ξ ≥ c
как индикатора случайной величины ξ − c.
Покажем, что математическое ожидание случайной величины
ω совпадает с искомой вероятностной функцией F0ξ (c) :
∞
∞
−∞
−∞
M {ω} = ∫ xdFω ( x ) = ∫ ω ( c − ξ ) dFξ ( x ) =
220
∞
= ∫ dFξ ( x ) = Fξ ( ∞ ) − Fξ ( c ) = 1 − Fξ ( c ) = F0 ξ ( c ) ,
−∞
где Fξ ( x) и Fω ( x) — функции распределения случайных величин ξ
и ω(c − ξ).
Отсюда следует, что вероятностная функция F0 ξ (c) для любого
фиксированного значения с может быть оценена по формуле статистического среднего величины ω (как индикатора):
F0 ξ ( c ) = M {ω} = M {ω ( c − ξ )} ≈ ω =
1 n
∑ ω ( c − ξ k ),
n k =1
(5.3)
где ξk — значения случайной величины ξ, получаемые в n статистических испытаниях, что определяет отношение числа m =
n
= ∑ ω(c − ξ k ) случаев выполнения неравенства ξk ≥ c в серии из n
k =1
испытаний к числу этих испытаний, что совпадает со статистическим определением вероятности как относительной частоты события при большом числе статистических испытаний [34].
Количество испытаний n, требуемое для подтверждения неравенства
F0ξ (c) = Pr {ξ ≥ c} ≤ Pдоп
с заданной доверительной вероятностью γ = 1 − δ может быть определено из соотношения (5.2), в котором величины M {ξ} и D{ξ}
заменяются величинами M {ω} и D{ω}. Из определения индикаторной функции следует, что
ω2 (a − ξ) = ω(a − ξ).
Тогда:
M {ω2 (a − ξ)} = M {ω(a − ξ)} = F0 ξ (c),
а дисперсия случайной величины ω равна:
{
D{ω} = D{ω(a − ξ)} = M [ ω(a − ξ) − M {ω(a − ξ)}]
{
2
}=
= M [ω(a − ξ)]2 − 2ω(a − ξ) M {ω(a − ξ)} + [ M {ω(a − ξ)}]
2
{
= M [ω(a − ξ)]2 − [ M {ω(a − ξ)}]
2
221
} = M {ω(a − ξ)} −
}=
− [ M {ω(a − ξ)}] = F0ξ (c) − F0ξ2 (c).
2
В результате соотношение (5.2) для числа испытаний применительно к случайной величине ω принимает вид (пренебрегая F02ξ (c)
для F0 ξ (c) << 1 ):
n≥
F0ξ (c)
⎡⎣ Pдоп − F0ξ ⎤⎦
2
Ψ 2 (δ).
Применительно к оценке точности бортовых систем управления
(например, при оценке безопасности автоматической посадки) неравенство
Pr {ξ ≥ c} ≤ Pдоп ,
то есть
F0ξ (c) ≤ Pдоп ,
должно выполняться с некоторым «запасом», который определяется коэффициентом запаса
P
kзап = доп = 2 ÷ 3.
F0ξ (c)
Тогда полученное выше соотношение для объёма испытаний
n приведем к виду:
F0 ξ (c)
Ψ 2 (δ) =
n≥
[ Pдоп − F0 ξ (c)][ Pдоп − F0 ξ (c)]
=
F0 ξ (c )
⎡ P
⎤
F0 ξ (c) 2 ⎢ доп − 1⎥
⎢⎣ F0 ξ (c ) ⎥⎦
⎡ Pдоп
⎤
− 1⎥
⎢
⎢⎣ F0 ξ (c) ⎥⎦
Ψ 2 ( δ) =
Ψ 2 (δ)
F0 ξ (c)( kзап − 1) 2
.
Обозначая
Ψ 2 (δ)
= k,
(kзап − 1) 2
получим неравенство для объема испытаний
n≥k
1
.
F0 ξ (c)
222
(5.4)
Например, для доверительной вероятности γ = 0,975, коэффициента запаса kзап = 3 имеем
k=
Ψ 2 (0,025)
≈ 1,
4
так что
n≥
1
,
F0 ξ (c)
т.е. число испытаний равно величине, обратной оцениваемой вероятности.
Очевидно, что объем испытаний можно уменьшить за счет использования априорной информации о вероятностных характеристиках случайной величины.
5.3. Определение объемов испытаний
при наличии априорной информации
Пусть требуется оценить вероятностную функцию
∞
F0 ξ ( x) = Pr {ξ ≥ x} = ∫ f (t )dt
(5.5)
x
случайной величины ξ , представляющей собой сумму случайных
величин
ξ = ξ1 + ξ 2 ,
(5.6)
при известной плотности распределения f1 (t ) и вероятностной
функции
∞
F0 ξ1 ( x) = Pr {ξ1 ≥ x} = ∫ f1 (t ) dt
(5.7)
x
случайной величины ξ1 с нулевым математическим ожиданием.
Плотность распределения f 2 (t ) и вероятностная функция
∞
F0 ξ2 ( x) = Pr {ξ 2 ≥ x} = ∫ f 2 (t )dt
x
неизвестны (либо информация о них не используется).
223
Введем обозначения для дисперсий случайных величин и их отношений:
σ12 = M {ξ12 } , σ 22 = M {ξ 22 } ,
σ 2 = M {ξ 2 } = σ12 + σ 22 ,
α=
σ2
σ2
=
,
2
σ
σ1 + σ 22
а также нормированные случайные величины
ξ1н =
ξ1
,
σ1
ξ 2н =
ξ2
σ2
такие, что
σξ21н = σξ2 2н = 1
В терминах нормированных величин соотношение (5.6) может
быть записано в виде
ξ = ξ1 + ξ 2 = ξ1н σ1 + ξ2н σ 2 .
Так как
⎛ σ2 ⎞
σ2 = ασ, σ12 = σ 2 − σ 22 = σ 2 ⎜ 1 − 22 ⎟ = σ 2 (1 − α 2 ) ,
⎝ σ ⎠
(5.7/)
σ1 = σ 1 − α 2 ,
то
(
)
ξ = ξ1н σ 1 − α 2 + ξ 2н ασ = σ ξ1н 1 − α 2 + ξ 2н α .
Коэффициент α характеризует степень неопределенности вероятностной функции случайной величины ξ при заданной информации о случайной величине ξ1.
Действительно:
при α = 0
ξ = ξ1 ⇒ F0 ξ ( x) = F0ξ1 ( x)
и вероятностная функция Fξ (x) полностью определена;
при α = 1
ξ = ξ 2 ⇒ F0ξ ( x) = F0 ξ2 ( x)
и информация о вероятностной функции отсутствует.
224
Все другие случаи соответствуют неравенству
0 < α < 1.
Чем меньше α, тем меньше неопределенность функции F0 ξ ,
т.е. тем меньше она отличается от известной функции распределения F0 ξ1 . И наоборот, чем ближе α к 1, тем больше вклад случайной величины ξ2 с неизвестной функцией распределения, и тем
сильнее различаются функции F0 ξ и F0 ξ 2 .
Искомую вероятностную функцию F0 ξ (см. (5.5)) для фиксированных значений аргумента х можно определить по стандартной
статистической формуле (5.3), не использующей информацию (5.6)
и (5.7):
F0ξ ( x) = M ξ {ω( x − ξ)} = M ξ1ξ 2 {ω( x − ξ1 − ξ 2 )} ≈
≈
1 n
∑ ω( x − ξ k ), ξ k = ξ1k + ξ 2 k .
n k =1
Отсюда видно, что имеется возможность сократить объем статистических испытаний, если учесть априорную информацию (5.6)
и (5.7). Вероятностная функция суммы случайных величин (5.6)
выражается формулой свертки через законы распределения случайных величин ξ1 и ξ2 [44]:
∞
F0 ξ ( x) = Pr {ξ1 + ξ2 ≥ x} = ∫ F0 ξ1 ( x − ξ 2 )dF0 ξ2 (ξ 2 ) =
−∞
∞
∞
= ∫ F0 ξ2 ( x − ξ1 )dF0 ξ1 (ξ1 ) = ∫ F0 ξ1 ( x − ξ2 ) f 2 (ξ 2 ) d ξ 2 =
−∞
−∞
∞
= ∫ F0 ξ2 ( x − ξ1 ) f1 (ξ1 ) d ξ1 .
(5.8)
−∞
Рассмотрим два варианта использования полученного соотношения
∞
F0 ξ ( x) = ∫ F0 ξ1 ( x − ξ 2 ) f 2 (ξ 2 )d ξ2 .
−∞
• Первый способ состоит в том, что по формуле статистической
оценки (5.3) определяется вероятностная функция случайной величины ξ 2 :
225
F0ξ 2 ( x) = Pr {ξ 2 ≥ x} = M ξ 2 {ω( x − ξ 2 )} ≈
1 n2
∑ ω( x j − ξ 2 k )
n2 k =1
(5.9)
в дискретных точках
x j = x0 + j Δ, j = 0, 1, 2, ..., n ,
т.е. получаем ряд значений функции распределения F2 ( x) в дискретных точках, а каждое значение функции распределения вычисляется по n2 точкам.
После этого вычисляется свертка как сумма значений подынтегральной функции в указанных дискретных точках.
Недостаток:
• сильная зависимость погрешности вычисления свертки от шага дискретизации,
• сложность оценки погрешности, связанной с количеством (конечностью) числа реализаций при расчете функции F0 ξ 2 ,
• неприменимость способа в случае зависимости слагаемых ξ1н
и ξ2н от общего случайного параметра.
• Второй способ основан на том, что согласно соотношению
(5.8) вероятность F0 ξ представляет собой математическое ожидание
некоторой случайной величины:
∞
∞
−∞
−∞
F0 ξ ( x) = ∫ F0 ξ1 ( x − ξ 2 ) f 2 (ξ2 )d ξ 2 = ∫ x f ( x) dx = M { x} =
{
}
= M ξ2 F0 ξ1 ( x − ξ 2 ) .
Обозначим через λ случайную величину
F0 ξ1 ( x − ξ2 ) = λ(ξ2 ) = λ,
так что
{
}
F0ξ ( x) = M ξ2 F0ξ1 ( x − ξ 2 ) = M {λ} ,
и λ может быть оценена по статистической формуле (5.1):
{
} {
}
F0 ξ ( x) = M ξ2 F0 ξ1 ( x − ξ 2 ) ≈ F0 ξ1 ( x − ξ 2 )
ср
=
/
=
1 n2
∑ F0ξ ( x − ξ2 k ) = F0 ξср .
n2/ k =1 1
226
(5.10)
Требуемое число испытаний n2/ определяется соотношением
вида (5.2)
D2/
n2/ =
Ψ 2 (δ),
(5.11)
2
( Pдоп − P )
где D2/ — дисперсия величины λ , определяемая как
{
}
D2/ = Dλ = M ξ2 F0 ξ1 ( x − ξ 2 ) − F0 ξ ( x)
∞
{
2
=
}
= ∫ [ F0 ξ1 ( x − t ) − Fо (t )]2 f 2 (t )dt = M ξ2 F0 ξ1 ( x − ξ 2 ) − F0 ξ 2 ( x), (5.12)
−∞
где
{
}
∞
M ξ2 F0 ξ1 2 ( x − ξ2 ) = ∫ F0 ξ1 2 ( x − t ) f 2 (t ) dt = I1 .
(5.12/)
−∞
При оценке требуемого числа реализаций в процессе статистического моделирования в соотношении (5.11) вместо неизвестной
функции распределения P = F0 ξ ( x) и дисперсии Dλ подставляются
вычисленные приближенно значения F0 ξ ( x) из (5.10) и
/
Dλ ≈ D λ =
1 n2
2
∑ [ F0 ξ ( x − ξ2 k ) − F0 ξср ] .
/
n2 − 1 k =1 1
Для предварительной оценки числа испытаний (до проведения
статистического моделирования) в формулу (5.11) подставляются
значения функции Р и дисперсии D, вычисленные по формулам
(5.8) и (5.12), где вместо неизвестной функции f 2 (ξ2 ) подставляется её предполагаемое априорное распределение. В этом случае
формула (5.11) приводится к виду:
n2/ =
/
D2/ Ψ 2 (δ)
/ D2
,
=
k
P 2 (kзап − 1) 2
P2
(5.13)
Pдоп
— коэффициент запаса по величине риска, γ = 1 − δ —
P
заданная доверительная вероятность ( δ << 1 ).
Важно отметить, что число испытаний n2/ при использовании
соотношения (5.11) заведомо меньше, чем число испытаний n при
использовании соотношения (5.4), т.е.
где kзап =
227
n2/ < n .
Для доказательства этого неравенства достаточно доказать, что
дисперсии случайных величин ω и λ соответственно связаны соотношением
Dω ( x) > Dλ ( x).
Определим дисперсию Dω ( x)
Dω ( x) = M ξ {ω2 ( x − ξ)} − F0ξ1 2 ( x) = M ξ1 ,ξ 2 {ω2 ( x − ξ1 − ξ 2 )} − F0ξ2 ( x) =
{
= M ξ 2 M ξ1 ⎡⎣ ω( x − ξ1 − ξ 2 ) − M ξ1 {ω( x − ξ1 − ξ 2 )} +
{
+ M ξ1 {ω( x − ξ1 − ξ 2 )}⎤⎦
2
} − F ( x) =
2
0ξ
{
}
= M ξ 2 M ξ1 ω( x − ξ1 − ξ 2 ) − F0ξ1 ( x1 − ξ 2 )
2
}
+ F0ξ1 2 ( x1 − ξ 2 ) −
− F0ξ2 ( x) = M ξ1 ,ξ 2 {ω( x − ξ1 − ξ 2 ) − F0ξ1 ( x − ξ 2 )} +
2
2
+ M ξ 2 { F0ξ1
( x − ξ 2 )} − F0ξ2 ( x) =
= Dλ ( x) + M ξ1 , ξ2 {ω( x − ξ1 − ξ 2 ) − F0 ξ1 ( x − ξ2 )} ,
2
где Dλ ( x) — дисперсия случайной величины λ (см. (5.12)), а математическое ожидание M ξ1 , ξ2 {•} > 0, следовательно
2
Dω ( x) > Dλ ( x).
Коэффициент
n2/
сокращения числа испытаний при изменении
n2
σ2
, характеризующего степень неопределенности
σ1
функции распределения F ( x), изменяется от 0 (при α = 0 ) до 1 (при
α = 1 ), и зависит от вида распределений F0 ξ ( x) и F0 ξ ( x) слагаемых
параметра α =
1
2
ξ1 и ξ2 . Получение количественной оценки сокращения числа
испытаний сводится к вычислению интегралов (5.8) и (5.12).
228
Априорная информация о равномерном распределении
Плотность распределения f 2 ( x), входящая в выражения интегралов (5.12) и (5.12/), не известна. Поэтому в формулу подставляется ожидаемое выражение распределения f 2 ( x). Найденное значение числа испытаний указывает, какое число испытаний потребовалось бы для оценки распределения суммы по формуле (5.10),
если бы величина ξ 2 была распределена по закону f 2 ( x). В принципе можно поставить вопрос о наихудшем распределении f 2 ( x)
при данной дисперсии σ2 , при котором число испытаний n2/ максимально.
Рассмотрим случай равномерного распределения величин ξ1 и
ξ 2 в интервале [0, 1] при
1
α=
.
2
Известно, что случайная величина ξ = ξ1 + ξ2 распределена в
интервале [0, 2] по закону Симпсона (треугольному закону) [24].
Определим плотности равномерного распределения как:
⎧1,
f1 ( x) = f 2 ( x) = ⎨
⎩0,
x ≤ 0 ≤ 1,
x < 0, x > 1
на интервале [0,1] для независимых случайных величин ξ1 и ξ2 .
Интегральные законы распределения этих величин зададим в
виде:
x<0
⎧1,
1
⎪
F0 ξ1 ( x) = F0 ξ2 ( x) = Pr {ξ ≥ x} = ∫ f1 (t )dt = ⎨1 − x, 0 ≤ x ≤ 1
0
⎪0,
x >1
⎩
Рассчитаем интегралы, входящие в полученные ранее выражения (5.8) и (5.12/):
∞
∞
−∞
−∞
F0 ξ ( x) = ∫ F0 ξ1 ( x − y ) f 2 ( y )dy = ∫ F0 ξ 2 ( y ) f1 ( x − y )dy,
∞
Dλ = D( x) = ∫ [ F0 ξ1 ( x − y ) − Fо ( x)]2 f 2 ( y )dy =I1 ( x) − Fо2 ( x),
−∞
229
где
∞
I1 ( x) = ∫ F0 ξ12 ( x − y ) f 2 ( y )dy.
−∞
С учетом определения плотности распределения f 2 ( x) представляем интегралы в виде:
1
1
0
0
F0ξ = ∫ F0ξ1 ( x − y ) f 2 ( y )dy = f 2 ( y ) = 1 = ∫ F0ξ1 ( x − y ) =
x −1
x
x − y = t, y = 0 → t = x
= − ∫ F0 ξ1 dt = ∫ F0 ξ1 (t )dt ,
− dy = dt , y = 1 → t = x − 1
x
x −1
∞
x
−∞
x −1
I1 ( x) = ∫ F0 ξ12 ( x − y ) dy = ∫ F0 ξ1 2 (t )dt.
В соответствии с определением интегральных функций F0 ξ1 ( x)
и F0 ξ2 ( x) получаем:
• для x < 0
x
x
F0 ξ = ∫ F0 ξ1 (t )dt = F0 ξ1 (t ) = 1 = ∫ 1 dt = 1 ,
x −1
x −1
x
I1 ( x) = ∫ F0 ξ1 (t )dt = 1.
2
x −1
• для 0 ≤ x ≤ 1
0
x
0
0
x −1
x
F0 ξ = ∫ F0 ξ1 (t )dt + ∫ F0 ξ1 (t )dt = ∫ 1 dt + ∫ (1 − t )dt =
x −1
x
x
= 1 − x + ∫ 1 dt − ∫ t dt = 1 − x + x −
0
0
0
2 x
t
2
= 1−
0
0
x
0
x
x −1
0
x −1
0
x2
,
2
I1 = ∫ F0 ξ1 2 (t )dt + ∫ F0 ξ1 2 (t )dt = ∫ 1 dt + ∫ (1 − t ) 2 dt =
1
x3
= 1 − x + ∫ (1 − 2t + t 2 )dt = 1 − x + x − x 2 + x3 = 1 − x 2 + .
3
3
0
x
• для 1 ≤ x ≤ 2
x
1
x
x −1
x −1
1
F0 ξ = ∫ F0 ξ1 (t )dt = ∫ F0 ξ1 (t )dt + ∫ F0 ξ1 (t )dt =
230
1
x
1
= ∫ (1 − t ) dt + ∫ 0 dt = ∫ (1 − t ) dt =
x −1
1 − t = τ, t = x − 1 → τ = 2 − x
−dt = d τ, t = 1 → τ = 0
0
2− x
(2 − x) 2
= − ∫ τ dτ = ∫ τ dτ =
,
2
2− x
0
1
x
2 − x1
1
I1 ( x) = ∫ (1 − t ) 2 dt + ∫ 0 dt = ∫ τ2 dt = (2 − x)3 .
3
x −1
1
0
1
=
x −1
• для x > 2
x
x
x −1
x
x −1
F0 ξ = ∫ F0 ξ1 (t )dt = ∫ 0 dt = 0,
x
I1 ( x) = ∫ F0 ξ1 2 (t )dt = ∫ 0 dt = 0.
x −1
x −1
Таким образом, справа от точки х = 1 вероятностная функция
F0 ξ ( x) = F0 ξ {ξ1 + ξ2 > x} задается выражением:
1
Δ2
F0 ξ ( x) = (2 − x) 2 =
,
2
2
где Δ = 2 − x есть расстояние до граничной пороговой точки х = 2.
Тогда количество испытаний, требуемое для оценки этой вероятности, составляет величину, определяемую соотношением (5.4):
n2 =
1
2k
k= 2 .
Fξ ( x)
Δ
Для расчета количества статистических испытаний n2/ для оценки этой же вероятности по соотношению (5.13)
n2/ = k
D2/
D( x)
=k 2
2
P
F0 ξ ( x)
определим дисперсию D( x) с помощью вычисленных интегралов как
1
1
D( x) = I1 ( x) − Fо2 ( x) = (2 − x)3 − (2 − x) 4 =
3
4
3
x
1
1
1
⎡
⎤
⎛
⎞
= (2 − x)3 ⎢ − (2 − x) ⎥ = ⎜ − ⎟ 2 − x = x ≈ 2 ≅
⎣3 4
⎦ ⎝ 4 6⎠
(
231
)
1
1
≅ (2 − x)3 = Δ 3
3
3
для 0 < 2 − x = δ << 1.
Таким образом
1 3
Δ
4 1 4
n =k 3
= k = k Δ −1.
1 4 3 Δ 3
Δ
4
Коэффициент сокращения объёма статистических испытаний определим как
n2 3 −1
= Δ .
(5.14)
n2/ 2
/
2
Пример 5.1. Пусть величина Δ = 0,05, т.е. Δ = 2 − x = 2 − 1,95 =
= 0,05.
Тогда для оценки вероятности уровня
1
1
F0 ξ ( x) = Pr {ξ1 + ξ2 ≥ x} = (2 − x) 2 = Δ 2 = 1, 25 ⋅ 10-3
2
2
как вероятности превышения некоторого порогового значения х
n
случайной величины ξ = ξ1 + ξ2 требуемое число реализаций в 2/
n2
раз меньше, чем в случае отсутствия (или не использования) априорной информации, т.е. в
n2 3 −1
1
= Δ = 1,5
= 30
/
n2 2
0,05
раз. Для Δ=0,01 имеем уровень оцениваемой вероятности F0ξ (x) = 5⋅10–5
и коэффициент сокращения объёма статистических испытаний равен
n2
1
= 1,5
= 150.
/
0,01
n2
Ниже в табл.5.1 приведены результаты расчета требуемого объёма статистического моделирования для различных уровней оцениваемых вероятностей безопасности P = 1 − F0 ξ ( x) автоматического захода на посадку и посадки самолетов без учета и с учетом
232
априорной информации (о равномерном распределении случайных
величин ξ1 и ξ 2 ). Коэффициент k, входящий в выражения (5.4) и
(5.13) и зависящий от коэффициента запаса k зап и доверительной
вероятности γ, был принят равным 1(при γ = 0,975 и kзап = 3 ) из
соотношения
2
⎡ Ψ (1 − γ ) ⎤
k=⎢
⎥ .
⎣ kзап − 1 ⎦
Таблица 5.1
Уровень
оцениваемой
вероятности
Расстояние ∆
до порогового
значения
Количество
реализаций
без учета априорной
информации
Количество
реализаций
с учетом априорной
информации
10−3
0,14
100
10
10−3
0,045
1000
30
Fξ ( x)
10
−4
0,014
10
4
95
5
300
−5
0,0045
10
−6
0,0014
10 6
950
10−7
0,00045
10 7
3 ⋅ 103
10−8
0,00014
108
9,5 ⋅ 103
10
10
Априорная информация о нормальном распределении
В случае нормального распределения нормированных случай⎛
ξ
ξ ⎞
ных величин ξ1н и ξ2н ⎜ ξ1н = 1 , ξ 2н = 2 ⎟ соотношения (5.8) для
σ1
σ2 ⎠
⎝
расчета вероятности F0ξ ( x) и (5.12) для вычисления дисперсии
Dλ ( x) могут быть рассчитаны с учетом распределения суммы нормальных величин.
Известно [24, 62], что если двумерная случайная величина
( ξ1 , ξ2 ) распределена по нормальному закону
⎧
⎡
2
1
⎪
⎢ ( x − a) −
f ( x, y ) =
exp ⎨ −
⎢
⎪ 2(1 − r 2 ) ⎢ σ 2
2πσ σ 1 − r 2
1
⎣
⎩
1 2
1
233
⎤⎫
( x − a)( y − b) ( y − b) 2 ⎥ ⎪
,
−2r
+
⎥⎬
σσ
σ2 ⎥ ⎪
1 2
2 ⎦⎭
то распределение суммы ξ = ξ1 + ξ 2 , определяемое соотношением
(5.12) также подчиняется нормальному закону с плотностью
f ξ ( x) =
1
(
2π σ12 + 2rσ1σ 2 + σ 22
)
⎧⎪
( x − a − b) 2
exp ⎨−
2
2
⎪⎩ 2 σ1 + 2rσ1σ 2 + σ 2
(
)
⎫⎪
⎬.
⎭⎪
В частности, для нашего случая, если случайные величины ξ1 и
ξ2 независимы, то коэффициент корреляции r = 0 и при нулевых
математических ожиданиях (a = 0, b = 0) формула для f ξ ( x) принимает вид
⎧
⎫
1
x2
exp ⎨−
f ξ ( x) =
⎬.
2
2
2π(σ12 + σ 22 )
⎩ 2(σ1 + σ 2 ) ⎭
Таким образом, соотношение для расчета вероятности F0 ξ ( x)
может быть записано в виде:
∞
⎛ x− y⎞ 1 ⎛ y ⎞
F0ξ ( x) = ∫ Φ о ⎜
f 2 ⎜ ⎟ dy =
⎟
−∞
⎝ σ1 ⎠ σ2 ⎝ σ2 ⎠
⎛
⎞
x
x
⎟ = Φ о ⎛⎜ ⎞⎟ = Φ о ( xн ) ,
= Φо ⎜
⎜ σ2 + σ 2 ⎟
⎝σ⎠
2 ⎠
⎝ 1
где
x
xн = ,
σ
σ= σ +σ ,
2
1
2
2
(5.15)
2
Φ о (•) = 1 − Φ (•),
1 ( •) − t2
Φ (•) =
∫ e dt
2π −∞
Соотношение для расчета дисперсии Dλ ( x) принимает вид:
2
⎡ ⎛ x− y⎞
⎛ x ⎞⎤ 1 ⎛ y ⎞
Dλ ( x) = ∫ ⎢Φ о ⎜
f 2 ⎜ ⎟ dy.
⎟ − Φо ⎜ ⎟⎥
−∞ ⎣
⎝ σ ⎠⎦ σ2 ⎝ σ2 ⎠
⎝ σ1 ⎠
∞
234
С учетом соотношения (5.7/)
σ1 = σ 1 − σ 2 , σ 2 = ασ
мы можем записать, что
2
⎡ ⎛ x σ − yн σ 2 ⎞
⎤
Dλ ( x) = ∫ ⎢Φ о ⎜ н
− Φ о ( xн ) ⎥ f 2 ( yн ) dyн =
⎟
2
−∞ ⎢
⎥⎦
⎣ ⎝ σ 1− α ⎠
∞
⎡ ⎛ x − αyн
= ∫ ⎢Φ о ⎜ н
−∞ ⎣
⎢ ⎝ 1 − α2
∞
∞
⎛ x − αyн
= ∫ Φ о2 ⎜ н
2
−∞
⎝ 1− α
2
⎤
⎞
⎟ − Φ о ( xн ) ⎥ f 2 ( yн ) dyн =
⎠
⎦⎥
(5.16)
⎞
2
⎟ f 2 ( yн ) dyн − Φ о ( xн ) = D( xн ,α).
⎠
Таким образом, дисперсия D( xн , α) определяется выражением
D( xн , α) = I ( xн , α) − Φ о2 ( xн ),
(5.17)
где
∞
⎛ x − αyн ⎞
I ( xн ,α) = ∫ Φ о2 ⎜ н
⎟ f 2 ( yн ) dyн ,
2
−∞
⎝ 1− α ⎠
2
1 − t2
f2 ( y) =
e ,
2π
(5.18)
∞
Φ о ( x) = ∫ f (t )dt.
x
В общем случае интегралы (5.17) и (5.18) через элементарные
функции не выражаются, а рассчитываются численными методами, заложенными в соответствующее программное обеспечение.
Для получения количественных результатов по сокращению объёмов статистических испытаний для некоторых частных случаев
можно получить аналитические выражения, в частности, для значений α близких к нулю или к единице. Малые значения параметра α соответствуют случаю малой априорной информации, а
значения α близкие к единице соответствуют максимальной априорной информации.
1. Для малых значений α получим разложение интегралов (5.17)
и (5.18) как функций переменных α и хн по степеням α в окрестности точки α = 0 (левая граница диапазона изменения α ).
235
Аргумент вероятностной функции Φ 0 (•)
xн − α y н
1− α
2
= ( xн − α y н )
1
1 − α2
в выражении (5.18) можно представить рядом Тейлора по степеням
коэффициента α .
Учитывая, что функция (1 − x) − n может быть разложена по степеням х как [44]
n(n + 1) 2 n(n + 1)(n + 2) 3
(1 − x) − n = 1 + nx +
x +
x + ...,
2!
3!
1
запишем ряд Тейлора для случая x = α 2 , n = . Тогда
2
1
=1+
α2 3 4
α2
+ α + ... = 1 +
+ o(α 4 ),
2 8
2
1 − α2
а аргумент функции Лапласа представим в виде:
⎛ α2
⎞
= ( xн − αyн ) ⎜1 +
+ o(α 4 ) ⎟ .
2
1 − α2
⎝
⎠
xн − αyн
Теперь получим разложение самой вероятностной функции Φ о ( х)
в ряд Тейлора в соответствии с общим выражением
1
1
Φ о ( xн + h) = Φ о ( xн ) + Φ о/ ( xн ) h + Φ о// ( xн ) h 2 + Φ о/// ( xн ) h3 + ...
2
6
при малых значениях h. Тогда
⎡
⎛ x − αyн ⎞
⎛ α2
⎞⎤
Φо ⎜ н
= Φ о ⎢ ( xн − αyн ) ⎜ 1 +
+ o(α 4 ) ⎟ ⎥ =
⎟
2
2
⎝
⎠⎦
⎝ 1− α ⎠
⎣
⎡
⎛ α2
α2
= Φ 0 ⎢ xн + xн
− yн α ⎜1 +
2
2
⎝
⎣
⎤
⎞
4
⎟ + o(α ) ⎥ =
⎠
⎦
2
⎡ α2
⎛ α2 ⎞⎤ 1
⎡ α2
⎤
= Φ о ( xн ) + Φ ( xн ) ⎢ xн
− yн α ⎜1 + ⎟ ⎥ + Φ о// ( xн ) ⎢ xн
− yн α ⎥ +
2 ⎠⎦ 2
⎝
⎣ 2
⎦
⎣ 2
1 ///
+ Φ о ( xн )( yн α)3 + o(α 4 ).
6
/
о
236
Получим разложение в ряд подынтегральной функции в выражении для дисперсии D ( xí , α ) (5.16):
2
⎡ ⎛ xн − αyн ⎞
⎤
− Φ 0 ( xн ) ⎥ =
⎢Φ 0 ⎜
⎟
⎢⎣ ⎝ 1 − α 2 ⎠
⎥⎦
2
⎡
⎡ α2
⎛ α2 ⎞⎤ 1
⎛ α2
⎞
= ⎢ Φ′0 ( xн ) ⎢ xн
− yн α ⎜ 1 + ⎟ ⎥ + Φ′′0 ( xн ) ⎜ xн
− yн α ⎟ −
2 ⎠⎦ 2
⎢⎣
⎝
⎝ 2
⎠
⎣ 2
2
1
⎤
− Φ′′′0 ( xн )( yн α)3 + o(α 4 ) ⎥ =
6
⎦
⎡
1
⎛1
⎞
= ⎢ −Φ′0 ( xн ) yн α + ⎜ Φ′0 ( xн ) xн + Φ ′′0 ( xн ) yн2 ⎟ α 2 +
2
⎝2
⎠
⎣
2
⎤
1
1
1
⎛
⎞
+ ⎜ −Φ ′0 ( xн ) yн − Φ ′′0 ( xн ) xн yн − Φ′′′0 ( xн ) yн 3 ⎟ α 3 + o(α 4 ) ⎥ .
2
2
6
⎝
⎠
⎦
Отбрасывая члены высшего порядка малости после возведения
в квадрат, окончательно можно записать
2
⎡ ⎛ xн − αyн ⎞
⎤
⎢Φ 0 ⎜
⎟ − Φ ( xн ) ⎥ =
2
⎣⎢ ⎝ 1 − α ⎠
⎦⎥
2
2
3
2
= α ⎡⎣(Φ′0 ( xн ) yн ) ⎤⎦ − α ⎡⎣Φ ′0 ( xн ) yн xн + Φ ′0 ( xн )Φ ′′( xн ) yн 3 ⎤⎦ +
1
1
⎡1
+α 4 ⎢ Φ′0 2 ( xн ) xн 2 + Φ ′′0 2 ( xн ) yн + Φ ′0 ( xн )Φ ′′0 ( xн ) xн yн 2 +
4
2
⎣4
1
⎤
+Φ ′0 2 ( xн ) yн 2 + Φ ′0 Φ ′′0 ( xн ) xн yн 2 + Φ ′0 ( xн )Φ ′′′0 ( xн ) yн 4 ⎥ + o(α 4 ).
3
⎦
Подставляя полученное разложение в выражение для дисперсии
(5.16) и учитывая, что для нормированных случайных величин xн
и yн выполняются соотношения:
∞
∞
−∞
−∞
∞
∞
−∞
−∞
∫ yн f 2 ( yн )dyн = myн = 0 ,
2
2
∫ yн f 2 ( yн )dyн = σ yн = 1,
3
3
∫ yн f 2 ( yн )dyн = myн = 0 ,
4
4
∫ yн f 2 ( yн )dyн = 3σ yн = 3,
237
получим разложение искомого интеграла:
3
⎧1
D( x,α) = α 2 Φ′0 2 ( xн ) + α 4 ⎨ Φ ′0 2 ( xн ) xн 2 + Φ ′′0 2 ( xн ) +
4
⎩4
1
+ Φ′0 ( xн )Φ′′0 ( xн ) xн + Φ ′0 2 ( xн ) + Φ ′0 ( xн )Φ ′′0 ( xн ) xн +
2
+ Φ′0 ( xн )Φ′′′0 ( xн )} + o(α 4 ).
Определим производные вероятностной функции
F0 ξ ( xн ) = Pr {ξ ≥ xн } ,
так что первая производная будет иметь отрицательный знак:
Φ′0 ( xн ) = − f 2 ( xн ) = −
Φ′′0 ( xн ) = xн
1
1
2π
e
x2
− н
2
,
x2
− н
2
e = xн f 2 ( xн ) ,
2π
Φ′′′0 ( xн ) = xн f 2′( xн ) + f 2 ( xн ) = f 2 ( xн ) − xн2 f 2 ( xн ) = 1 − xн2 f 2 ( xн ).
(
)
Подставляя полученные значения производных в разложение
получаем:
3
1
⎡1
⎤
D ( xн ,α) = α 2 f 22 ( xн ) + α 4 f 22 ( xн ) ⎢ xн2 + xн2 − xн2 + 1 − xн2 − 1 − xн2 ⎥ =
4
2
⎣4
⎦
⎡ 1
⎤
= α 2 f 22 ( xн ) ⎢1 + α 2 xн2 + o(α3 ) ⎥ .
⎣ 2
⎦
Таким образом, дисперсия случайной величины Fξ1 ( x − ξ 2 ) представляется разложением
(
)
⎡ 1
⎤
Dλ ( x) = D ( xн , α) = α 2 f 22 ( xн ) ⎢1 + α 2 xн2 + o(α 3 ) ⎥
⎣ 2
⎦
по степеням α с точностью до α 4 .
Соотношение для коэффициента сокращения объема статистических испытаний для этого случая при
n2 =
D (x )
k
, n2/ = k 2λ н
F0 ξ ( xн )
F0 ξ ( xн )
238
принимает вид
n2 F0ξ ( xн )
=
≈
n2/ D ( xн ,α)
F0ξ ( xн )
.
⎛ 1
⎞
α 2 f 22 ( xн ) ⎜ 1 + α 2 xн2 ⎟
⎝ 2
⎠
Известно [62], что для расчета функции Φ ( x) при больших значениях x( x > 5) можно воспользоваться рядом
x2
2
1 1⋅ 3 1⋅ 3 ⋅ 5
⎡
⎤
1 − 2 + 4 − 6 + ...⎥ =
⎢
x
x
x 2π
⎣ x
⎦
f ( x) ⎡
1
3 15
⎤
=1−
− + ...⎥ .
1− +
x ⎢⎣ x 2 x 4 x 6
⎦
Так как вероятностная функция F0ξ ( xн ) определяется соотношением
F0 ξ ( xн ) = 1 − Φ ( xн ) = Pr {ξ ≥ xн } ,
то
⎛ 1 ⎞⎤ f ( x )
f (x ) ⎡
F0ξ ( xн ) = 2 н ⎢1 − o ⎜ ⎟ ⎥ ≅ 2 н ,
xн ⎣
xн
⎝ xн ⎠ ⎦
1
Φ ( x) = 1 −
e
−
и формула для коэффициента сокращения объема статистических
испытаний принимает вид
n2
1
1
= 2
≈
.
/
2
n2
α f2 (xн )xн 1 + α2 xн2 + o(α3 ) α xн f2 ( xн )
(
)
(5.19)
2. Для значений α близких к единице сделаем замену 1 − α 2 = β,
так что β << 1. В этом случае интеграл в (2.18) преобразуется к виду:
2
∞
∞
⎡
⎤
⎡ x − αyн ⎤
2 xн − 1 −β yн
=
Φ
I ( xн ) = ∫ Φ02 ⎢ н
f
y
dy
(
)
⎢
⎥ f2 ( yн )dyн =
⎥ 2 н н ∫ 0
2
β
−∞
−∞
⎢⎣
⎣ 1− α ⎦
⎦⎥
= (1 − β 2 )
1
2
=1−
β2 β4
β2
− − ... = 1 − + o(β 2 ) =
2 8
2
⎡
⎤
⎛ β2 ⎞
x
1 − ⎟ yн
−
⎢
⎥
⎜
н
∞
2⎠
⎝
= ∫ Φ 02 ⎢
+ o(β 2 ) ⎥ f 2 ( yн )dyн =
⎢⎣
⎥⎦
β
−∞
239
∞
⎡ x − yн β ⎤ ⎡ xн − yн β ⎤
= ∫ Φ0 ⎢ н
+ yн ⎥ Φ 0 ⎢
+ yн ⎥ f 2 ( yн )dyн =
2 ⎦ ⎣ β
2 ⎦
−∞
⎣ β
= Φ 0 (a + h) ≅ Φ 0 ( a ) + Φ ′0 (a ) ⋅ h = Φ 0 (a + h)Φ 0 (a + h) = Φ 02 (a ) +
∞
⎡ x − yн ⎤
+2Φ 0 (a )Φ ′0 (a )h + o(h), Φ ′0 (a) = − f (a ) = ∫ Φ 02 ⎢ н
⎥ f 2 ( yн )dyн −
−∞
⎣ β ⎦
∞
⎡ x − yн ⎤ ⎛ xн − yн ⎞
2
f2 ⎜
−β ∫ Φ 0 ⎢ н
⎟ f 2 ( yн ) yн dyн + o(β ) =
⎥
−∞
⎣ β ⎦ ⎝ β ⎠
= I1 + βI 2 + o(β 2 ),
(5.20)
∞
⎡ x − yн ⎤
I1 = ∫ Φ 02 ⎢ н
⎥ f 2 ( yн )dyн = I1 ( xн , β),
−∞
⎣ β ⎦
(5.21)
∞
⎡x − y ⎤ ⎛ x − y ⎞
I2 = ∫ Φ0 ⎢ н н ⎥ fн ⎜ н н ⎟ f2 ( yн ) yнdyн .
−∞
⎣ β ⎦ ⎝ β ⎠
(5.22)
где
Интеграл I1 = I1 ( xн , β) можно разложить в ряд Тейлора в окрестности точки β = 0 :
I1 ( xн , β) = I1 ( xн , 0) +
∂I1 ( xн , β)
1 ∂ 2 I1 ( xн , β) 2
β+
β + o(β 2 ).
∂β
∂β 2
β =0 2
β =0
Рассчитаем каждое слагаемое:
I1 ( xн , 0) = lim I1 ( xн , β) = Φ 0 ( xн ).
β→ 0
xн − y н = t
∞
∂I1 ( xн , β) ∂
2 ⎡ xн − y н ⎤
=
Φ0 ⎢
⎥ f 2 ( yн )dyн = − dyн = dt =
∂β
∂β −∞ ⎣ β ⎦
y н = xн − t
∫
∂ ∞ 2⎛ t ⎞
=
∫ Φ 0 ⎜ ⎟ f 2 ( xн − t )(−1) dt =
∂β −∞ ⎝ β ⎠
/
⎧⎪ 2 ⎛ t ⎞ ⎫⎪
⎛t⎞ ⎛t⎞ t
⎨Φ 0 ⎜ ⎟ ⎬ = −2Φ 0 ⎜ ⎟ f 2 ⎜ ⎟ 2 =
⎪⎩ ⎝ β ⎠ ⎪⎭
⎝β ⎠ ⎝β ⎠β
∞
⎛t⎞ ⎛t⎞ t
t
= 2 ∫ Φ 0 ⎜ ⎟ f 2 ⎜ ⎟ 2 f 2 ( xн − t )dt = = τ, t = βτ, dt = βdτ =
β
−∞
⎝β ⎠ ⎝β ⎠β
240
∞
= 2 ∫ Φ 0 (τ) f 2 (τ)τf 2 ( xн − βτ)dτ.
(5.23)
−∞
Определяем значение производной в точке β = 0 :
∞
∂I ( xн , β)
= β = 0 = 2 ∫ Φ 0 (τ) f 2 (τ)τf 2 ( xн )dτ =
∂β
−∞
∞
f ′( x) = − xf ( x)
−∞
f 2 (τ)τ ⇒ d (− f 2 (τ))
= 2 f 2 ( xн ) ∫ Φ 0 ( τ) f 2 (τ)τd τ =
=
∞
Φ 0 ( τ) = u
Φ′0 (τ) d τ = du
−∞
d (− p (τ)) = dv
v = − f ( τ)
= 2 f 2 ( xн ) ∫ Φ 0 ( τ)d (− p (τ)) =
=
∞
∞
⎡
⎤
= 2 f 2 ( xн ) ⎢ −Φ 0 (τ) f 2 (τ) −∞ + ∫ f 2 (τ)Φ ′0 (τ) dτ ⎥ =
−∞
⎣
⎦
∞
1
= −2 f 2 ( xн ) ∫ f (τ)dτ = f 2 (τ) =
−∞
2
2
2π
u = 2τ
e
−
τ2
2
1 1 ∞
=
= −2 f 2 ( xн )
∫e
2π 2 −∞
du = 2dτ
1 ∞
= −2 f 2 ( xн )
∫e
2π −∞
−
u2
2
du = −
1
2π
−
2τ 2
2
dτ =
f 2 ( xн ).
Определим значение второй производной в точке β = 0 с учетом:
∂ 2 I ( xн , β)
∂ ∞
=2
∫ Φ о (τ) f 2 (τ)τf 2 ( xн − βτ)dτ =
2
β
∂β
∂
−∞
β =0
β =0
∞
= 2 ∫ Φ 0 (τ) f 2 (τ)τf 2/ ( xн )(− τ) dτ = f 2′( xн ) = − xн f 2 ( xн ) =
−∞
∞
= 2 f 2 ( xн ) xн ∫ Φ 0 (τ) f 2 (τ)τ 2 dτ.
−∞
Представим интеграл в полученном выражении в виде:
∞
∞
⎡1 ⎧
1 ⎫⎤
2 ∫ Φ 0 (τ) f 2 (τ)τ2 d τ = 2 ∫ ⎢ + ⎨Φ 0 (τ) − ⎬⎥ f 2 (τ)τ 2 d τ =
2 ⎭⎦
−∞
−∞ ⎣ 2
⎩
241
∞
∞
1⎤
⎡
= ∫ f 2 (τ)τ 2 d τ + 2 ∫ ⎢Φ 0 (τ) − ⎥ f 2 (τ)τ 2 d τ.
2⎦
−∞
−∞ ⎣
Здесь первый интеграл равен 1 в виду четности функции в подынтегральном выражении, а второй интеграл равен нулю вследст1
вие нечетности функции Φ 0 ( τ) − , т.е.:
2
∞
2 ∫ Φ 0 (τ) f 2 (τ) τ2 d τ = 1,
−∞
а значение второй производной в точке β = 0 равно:
∂ 2 I ( xн , β)
= f 2 ( xн ) xн .
∂β2
β= 0
Таким образом, окончательное выражение для интеграла (5.21)
представляется в виде:
I1 ( xн ,β) = Φ 0 ( xн ) −
1
π 2
f 2 ( xн )β + f 2 ( xн ) xнβ 2 + o(β 2 ) .
Вычислим второй интеграл в (5.20):
∞
x − yн = t
⎡ x − yн ⎤ ⎡ xн − yн ⎤
I2 = ∫ Φ0 ⎢ н
f2 ⎢
f 2 ( yн ) yн dyн = н
=
⎥
⎥
yн = xн − t
−∞
⎣ β ⎦ ⎣ β ⎦
t
= τ, t = τβ
⎛t⎞ ⎛t⎞
=
= − Φ 0 ⎜⎜ ⎟⎟ f 2 ⎜⎜ ⎟⎟ f 2 ( xн − t )( xн − t )dt = β
⎝β⎠ ⎝β⎠
−∞
dt = β dτ
∞
∫
∞
∫
= −β Φ 0 (τ) f 2 (τ) f 2 ( xн − βτ)( xн − βτ) dτ.
−∞
Очевидно, что при малых значениях β (β → 0) этот интеграл
также стремится к нулю, т.е. I 2 = 0.
Таким образом, окончательное выражение для интеграла (5.20)
принимает вид:
I ( xн ,β) = Φ 0 ( xн ) −
1
π 2
242
f 2 ( xн )β + o(β 2 ) ,
а выражение для дисперсии с учетом (5.17) записывается в виде:
Dλ ( x) = D ( xн , β) = Φ 0 ( xн ) − Φ 02 ( xн ) −
1
π 2
f 2 ( xн )β + o(β 2 )
с точностью до β2 .
Соотношение для коэффициента сокращения объема статистических испытаний для рассмотренного случая (α → 1) при
n2 =
D (x )
k
, n2′ = k 2λ н
F0ξ ( xн )
F0ξ ( xн )
принимает вид:
F0ξ ( xн )
n2 F0ξ ( xн )
=
≈
.
n2′ D( xн ,β) Φ ( x ) − Φ 2 ( x ) − 1 f ( x )β
0
н
0
н
2
н
π 2
(5.24)
Асимптотические формулы (5.19) и (5.24) применимы только
вблизи концов интервала изменения 0 ≤ α ≤ 1, т.е. для случаев малой априорной информации и априорной информации близкой к
максимальной.
Полученные выражения позволяют грубо оценить необходимый
объём статистических испытаний перед их проведением, имея ту
или иную информацию (например, полученную на предыдущих
этапах испытаний исследуемой системы управления, или информацию об системах-аналогах).
Для задачи оценки уровня безопасности практический интерес
представляет случай, соответствующий примерно одинаковому
вкладу составляющих ξ1 и ξ2 , что соответствует параметру
σ
σ
1
2
α= 2 =
≈
≈ 0,7.
σ
2
2
2
σ +σ
1
2
Для этого случая и возможных других коэффициент сокращения
объема испытаний может быть определен соответствующим программным обеспечением с использованием численных методов
расчета интегралов (в частности интегралов (5.16)–(5.18)) при изменении параметра xн ∈ [0, 6] , что соответствуют уровням безопасности 10−2 ÷ 10−8 , и α ∈ [0, 1].
243
В табл. 5.2 приведены результаты расчета необходимого объема
статистических испытаний для важных практических случаев,
когда параметр α = 0,7 (одинаковый вклад дисперсий, т.е. σ12 = σ22 , так
σ
σ2
1
=
= 0,7 ) и α = 0,5 (в этом случае σ12 = 3σ22 )
что α = 2 =
2
2
σ
2
σ1 + σ2
для различных пороговых значений хн.
На примере автоматического захода на посадку и посадки самолетов координаты движения самолета могут быть представлены в
виде суммы двух составляющих ξ = ξ1 + ξ 2 , где первая составляющая ξ1 = xв вызывается флуктуациями (турбулентность, шумы измерений), а вторая ξ2 = xп разбросом случайных параметров (средний ветер, угол наклона глиссады, разброс передаточных чисел и т.п.).
Таблица 5.2
Число реализаций
с учетом априорной
информации
Отношение
порогового
значения
координаты
к ее дисперсии
Уровень
оцениваемой
вероятности
Число реализаций
без учета
априорной
информации
β = 0,001 → 0
α = 0,5
α = 0,7
xн = 3
10−3
740
8
42
xн = 3,5
10−4
xн = 4
xн = 4,5
xн = 5
xн = 5,5
4300
17
130
10
−5
31500
37
450
10
−6
290000
88
1800
10
−7
6
220
7900
0,5 ⋅ 108
640
64000
10−8
3,5 ⋅ 10
Закон распределения составляющей ξ1 выражается в аналитической форме, и по большинству координат близок к нормальному.
В случае, если закон распределения составляющей ξ1 = xв зависит от тех
же случайных параметров, что и вторая составляющая ξ2 , т.е.
Pr {ξ1 ≥ x} = F0 ξ1 ( x, П),
то оценка вероятностей функции F0 ξ ( x) может быть определена
следующим образом:
244
⎪⎧
⎪⎫
F ( x) = Pr ξ = ξ + ξ ≥ x = M ⎨ F [ x − ξ (П); П]⎬ ≈
0ξ
1 2
п ⎪ 0ξ
2
⎩ 1
⎭⎪
/
n
1 2
≈ { F0ξ [ x − ξ 2 (П); П]} = / ∑ F0ξ1 [ x − ξ 2 (Пi ); П i ],
ср
n2 i =1
{
}
при этом определение ведется по реализациям вектора параметров П,
моделируемых в соответствии с их законом распределения.
Для приближенной предварительной оценки требуемого числа
испытаний можно применять полученные выше соотношения в предположении нормального закона распределения слагаемых ξ1 и ξ2 ,
а также независимости первой составляющей от параметров.
Фактические значения коэффициента α могут быть определены
в результате расчета дисперсий координат системы посадки с учетом разброса случайных параметров и действия турбулентности
(по отдельности и вместе), а фактически необходимое число реализаций может уточняться в процессе самого статистического моделирования. За отсутствием достоверных данных о соотношении
между флуктуационной составляющей и составляющей, зависящей
от случайных параметров, можно принять предположение о примерно одинаковом их вкладе в разброс координат при автоматическом заходе на посадку и посадке.
5.4. Методы уменьшения дисперсии оценок
вероятностных характеристик
Как уже отмечалось, основной вычислительной задачей, решаемой методом статистических испытаний, является задача оценки
среднего значения некоторой случайной величины, т.е. задача вычисления интеграла по некоторой вероятностной мере [34]. Вычисляется N независимых реализаций случайной величины и ее математическое ожидание оценивается с помощью среднего арифметического этих реализаций, поскольку среди линейных несмещенных
оценок среднее арифметическое имеет наименьшую дисперсию.
Погрешность оценивается неравенством Чебышева
⎧ 1 N
⎫
σ2
, ∀ε > 0, σ 2 = D{ξ i }.
P ⎨ ∑ ξi − m > ε ⎬ ≤
2
(
ε)
N
n
⎩ i =1
⎭
и имеет вероятностный характер.
245
Если задать некоторое достаточно малое α, положив α =
(т.е. ε =
σ2
nε 2
σ
), то можно записать:
nα
⎧1 n
σ ⎫
P ⎨ ∑ ξ i − M {ξ} ≤
⎬ ≥1− α ,
nα ⎭
⎩ n i =1
т.е. с вероятностью 1 – α среднее арифметическое независимых
σ
. Очевидно,
реализаций ξ отличается от M {ξ} не более чем на
nα
что при фиксированных α и σ погрешность убывает пропорцио−
1
нально n 2 .
Если выполнены условия применимости центральной предель1 n
ной теоремы, то при достаточно большом n величину ∑ ξ i можно
n i =1
считать распределенной нормально со средним M{ξ} и дисперсией
σ2
, что дает возможность построить доверительный интервал для
n
погрешности. При этом, строго говоря, необходимо, чтобы распре1 n
деление величины ∑ ξ i отличалось от нормального распределеn i =1
−
1
ния не более чем на величину порядка n 2 .
Величина дисперсии, которой определяется погрешность, может
быть также оценена в процессе вычислений. Таким образом, имеется
возможность определить в процессе вычислений число n, гарантирующее необходимую точность с заданной вероятностью (надежностью). Таким образом оценка математического ожидания дает решение задачи, а оценка дисперсии обеспечивает оценку погрешности.
Малый порядок убывания погрешности метода может не позволить оценить малую вероятность с приемлемой относительной погрешностью. В этом случае необходимо использовать различные
способы преобразования случайных величин, сохраняющие их среднее значение, но уменьшающие дисперсию.
Одним из таких способов является так называемая «выборка по
группам», когда результаты статистического моделирования груп246
пируются некоторым образом на несколько непересекающихся
групп (подмножеств), таких, что
A = A1 + A2 + ... + Ak ,
а окончательная вероятностная оценка осуществляется усреднением по этим группам:
k
∫ f ( x) p( x)dx = ∑ ∫ f ( x) p ( x) dx.
i =1 Ai
A
Введем обозначения:
p j = ∫ p ( x)dx; ∫ f ( x) p( x)dx = I j .
Aj
Очевидно, что
Aj
p1 + p2 + ... + pk = 1.
Каждый из интегралов в сумме может быть оценен с помощью
обычного метода Монте – Карло:
{
}
( j)
∫ f ( x) p( x)dx = M p j f ( Q ) ,
Aj
где Q ( j ) — случайная точка с датчика случайных чисел, имеющая
p( x)
плотность
. Выбрав случайным образом n j таких чисел Q1( j ) ,
pj
Q2( j ) , ..., Qn( jj ) , можно записать оценку интеграла:
⎡ nj
⎤ pj
I ∗j (n j ) = ⎢ ∑ f Qi( j ) ⎥
.
⎣ i =1
⎦ nj
(
)
Суммируя такие оценки для всех k групп, можно получить несмещенную оценку всего интеграла:
∫
A
k
f ( x) p ( x)dx ≈ ∑
pj
∑ f (Qi( j ) ) ,
nj
j =1 n j i =1
где общее количество случайных точек равно N:
n1 + n2 + ... + nk = N .
247
Дисперсия полученной оценки интеграла в соответствии с известным выражением D{ax} = a 2 D{x} будет равна:
⎧⎪ k p j n j
D ⎨ ∑ ∑ f Qi( j )
⎩⎪ j =1 n j i =1
(
)
2
⎫⎪ k ⎡ p j ⎤ n j
( j)
.
⎬ = ∑ ⎢ ⎥ ∑ D f Qi
⎭⎪ j =1 ⎣⎢ n j ⎦⎥ i =1
{ ( )}
Так как случайные числа Qi( j ) независимы, то дисперсия суммы
равна сумме дисперсий и, следовательно:
⎧⎪ k p j n j
D ⎨ ∑ ∑ f Qi( j )
⎪⎩ j =1 n j i =1
(
)
⎫⎪ k p 2j
D f Qi( j ) .
⎬= ∑
⎪⎭ j =1 n j
{ ( )}
Пусть k = 2, p1 = P ( A1 ), p2 = P ( A2 ), n1 + n2 = N и
k
pj
j =1
nj
∫ f ( x) p ( x)dx ≈ ∑
A
nj
∑ f ( Qi( j ) ) = I ∗ ( f ).
i =1
Будем считать p1 , p2 , n1 и n2 такими, что и n2 = p2 N — целые
числа. Тогда дисперсия суммы I ∗ ( f ) определяется как
2
2
⎧
⎤
⎤ ⎫⎪
1⎪ 2
1 ⎡
1 ⎡
⎨ f ( x) p( x)dx − ⎢ ∫ f ( x) p( x)dx ⎥ − ⎢ ∫ f ( x) p( x)dx ⎥ ⎬ .
N ⎪ ∫A
p1 ⎢ A
p1 ⎢ A
⎥⎦
⎥⎦ ⎪
⎣ 1
⎣ 1
⎩
⎭
Для обычного метода Монте–Карло, применяемого для оценки
интеграла по всему множеству А, дисперсия определяется в соответствии с выражением:
1
D{I ( f )} =
N
2
⎧⎪
⎡
⎤ ⎫⎪
2
⎨ ∫ f ( x) p( x)dx − ⎢ ∫ f ( x) p ( x)dx + ∫ f ( x) p( x)dx ⎥ ⎬ =
A2
⎣ A1
⎦ ⎪⎭
⎪⎩ A
⎡
⎤
1 ⎧⎪ 2
⎨ ∫ f ( x) p( x)dx − ⎢ ∫ f ( x) p ( x)dx ⎥ −
N ⎪A
⎣ A1
⎦
⎩
2
=
2
⎡
⎤
⎡
⎤⎡
⎤ ⎫⎪
− ⎢ ∫ f ( x) p( x)dx ⎥ − 2 ⎢ ∫ f ( x) p( x) dx ⎥ ⎢ ∫ f ( x) p ( x)dx ⎥ ⎬ .
⎣ A2
⎦
⎣ A1
⎦ ⎣ A2
⎦ ⎪⎭
248
1
1
>1 и
> 1, то очевидно, что D I ∗ ( f ) ≤ D { I ( f )} ,
p1
p2
а знак равенства имеет место, лишь в случае, когда
{
Так как
}
∫ f ( x) p( x)dx = ∫ f ( x) p( x)dx.
A1
A2
Таким образом, любое разбиение при выборе числа точек, пропорциональном вероятностной мере множеств A1 и A2 (в общем
случае n j = Np j ), ведет к уменьшению дисперсии по сравнению с
обычным методом Монте–Карло.
В [34] рассматриваются и другие методы уменьшения дисперсии вероятностных характеристик, определяемых методом статистических испытаний. К основным методам следует отнести: метод
выделения главной части, метод существенной выборки, метод выделения по группам и метод случайных квадратурных формул.
Наиболее простым в смысле создания вычислительного алгоритма
является рассмотренный выше метод выделения по группам.
Сущность метода выделения главной части заключается в следующем. Если при вычислении интеграла ∫ f ( x) p( x)dx можно найти
некоторую функцию g(x) близкую к f(x), для которой интеграл
∫ g ( x) p( x)dx = I1 легко вычисляется аналитически, т.е.
I = ∫ f ( x) p ( x)dx = I1 + ∫ [ f ( x) − g ( x)] p ( x)dx,
то достаточно оценить интеграл в правой части с помощью суммы
1 N
∑ [ f ( xi ) − g ( xi )] ,
N i =1
где xi — независимые случайные величины, распределенные по
закону p(x).
Дисперсия оценки определяется как
I 2∗ =
D {I 2∗ } =
{
}
1
2
2
∫ [ f ( x) − g ( x)] p ( x)dx − [ f ( x) − g ( x)] p ( x)dx ] .
N
{ }
Как правило, дисперсию D I 2∗
оценивают либо аналитически,
либо на основе выборки небольшого объема и устанавливают, насколько выгодно использовать для рассматриваемой задачи метод
выделения главной части.
249
Метод существенной выборки представляет собой адаптивный
метод, позволяющий вычислять интегралы вида
I = ∫ f ( x)dx,
G
где область G может быть неограниченной. Тогда область G разбивается на две области: G = G0 + G∗, где G0 — область, в которой
функция f(x) обращается в нуль. Если рассмотреть функцию
⎧ f ( x)
,
⎪
Ψ ( x) = ⎨ φ( x)
⎪0,
⎩
x ∈ G∗ ,
x ∈ G0 ,
где x — случайная точка, определенная в S с плотностью ϕ(x), то
M {Ψ ( x)} = ∫ Ψ ( x)φ( x) dx = ∫ f ( x)dx = S .
G∗
G
Очевидно, что оценкой величины M[ψ(x)] является величина
SN =
1 N
∑ Ψ ( xi ),
N i =1
где xi — реализация случайной величины x с плотностью ϕ(x).
В этом случае дисперсия оценки определяется как
D= ∫
G∗
f 2 ( x)
dx − S 2 ,
φ( x)
причем минимум дисперсии, равный
2
⎡
⎤
Dmin = ⎢ ∫ f ( x) dx ⎥ − S 2 ,
⎣G
⎦
обеспечивается в случае, когда плотность ϕ(x) пропорциональна
f ( x) .
Необходимо отметить, что рассмотренные выше два метода
можно комбинировать, выделяя, например, сначала из подынтегральной функции главную часть, а затем применяя метод существенной выборки.
Самым универсальным методом, который дает существенное
уменьшение дисперсии, является метод с использованием случай250
ных квадратурных формул. Недостатком метода является сложность моделирования случайных чисел Q с заданной для этого метода плотностью, сложности в оценке модуля определителя при
большом числе слагаемых в случайной квадратурной формуле, которые ограничивают возможности его применения. Тем не менее
этот метод следует рекомендовать при статистическом моделировании высокоточных систем управления, для которых вероятность
превышения определяющим параметром допустимого значения
меньше чем 10−6. Иллюстрация примера, приведенного в [34] показывает большие возможности этого метода. Например, для вычисления интеграла
1
1
0
0
−7
∫ .....∫ ⎡⎣exp ( x1 ...x20 ) − 1⎤⎦dx1 ...dx20 ≈ 9,538 ⋅ 10
с точностью 1% обычным методом Монте – Карло требуется около
трех миллионов испытаний (дисперсия на одно испытание имеет
величину 3 ⋅ 10−10 ). Если соответствующим образом выбрать систему ортонормированных функций φi ( x) (в примере n = 1, φ1 ≡ 1,
φ 2 ≡ x1 ... x20 ), то не представляет сложности моделирование необходимой совместной плотности распределения случайных точек Q.
Дисперсия же полученной квадратурной суммы уменьшается до
3 ⋅ 10−15 на одно испытание. Это означает, что для достижения точности 1% требуется только около 30 испытаний. Хотя это пример
очень удачного выбора функций φi ( x), однако он указывает на возможности метода.
В заключение рассмотрим вопрос учета погрешностей при моделировании самих случайных величин.
Одним из основных методов формирования непрерывной случайной величины является метод обратных функций, получивший
наиболее широкое распространение среди методов нелинейного
преобразования. Пусть непрерывная случайная величина Х задана
своей функцией распределения P { X < x} = F ( x) и пусть Х является
корнем уравнения F(x) = R, где R — случайная величина, распределенная равномерно на интервале [0, 1]. Найдем ее функцию распределения P{ X < x}. Если X < x, то R < F ( x). Справедливо и обратное
утверждение. Следовательно,
P{ X < x} = P{R < F ( x)} = F ( x)
251
и определение значения непрерывной случайной величины с функцией распределения F(x) сводится в общем случае к нелинейному
преобразованию случайной величины R:
X = F −1 ( R ),
где F −1 (⋅) — функция, обратная к функции F.
Например, случайную величину с показательным распределением
F ( x) = 1 − e− λx ,
0≤ x≤∞
можно сформировать, используя преобразование:
1 − e − λxi = ri ,
откуда
e − λxi = 1 − ri .
Поскольку R является случайной величиной, распределенной на
интервале [0, 1], то и случайная величина 1 − ri также распределена
равномерно на [0, 1]. Таким образом,
1
xi = − ln ri .
λ
Полученное выражение и определяет алгоритм моделирования
случайной величины с показательным законом распределения.
Во многих случаях уравнение X = F −1 ( R ) не разрешается в явном виде, так что в общем случае необходимо учитывать ошибки
моделирования случайной величины, влияющие на оценку выходного показателя, который рассчитывается путем статистического
моделирования.
Под оценкой точности результатов статистического моделирования сложных систем управления понимается оценка точностных
характеристик, определяемых на соответствующей математической
модели [61, 77], которая представляет собой сложный оператор
преобразования входных величин в выходные. Если входные случайные величины обозначить через ξ1 , ξ 2 , ..., ξ k , а выходную величину через η , то
η = Φ ( ξ1 , ξ 2 , ..., ξk ) .
e − λxi = ri
⇒
Пусть оцениваемый точностный показатель системы управления есть математическое ожидание. В этом случае выходная харак252
теристика модели представляет собой математическое ожидание от
Φ ( ξ1 , ..., ξ k ) . В качестве выходной характеристики можно использовать величину
1 N
η* = ∑ Φ j ( ξ1 , ..., ξk ) .
N j =1
Рассмотрим случай с единственной входной случайной величиной ξ т.е.
η = Φ (ξ).
Пусть ξ имеет плотность f ( x). Тогда показатель системы может быть записан в виде
R = ∫ Φ ( x) f ( x)dx.
В модели реализуется не ξ , а ξ M с плотностью распределения
f M ( x), являющейся некоторой аппроксимацией f ( x). Следовательно, при бесконечном числе реализаций на модели будет получена
величина RM как
RM = ∫ Φ ( x) f M ( x)dx.
При конечном числе реализаций N вид оценки будет
η* =
1 N
(i )
∑ Φ ξM ,
N i =1
{ }
где ξ(Mi ) — значение ξ M в і-той реализации моделирования. По величине оценки η* судят о величине показателя. Требуется определить точность этой оценки.
Смещение Δη* равно
{ }
Δη* = M η* − R = RM − R = ∫ Φ ( x)[ f M ( x) − f ( x)]dx =
∫ Φ ( x)
f M ( x) − f ( x)
f M ( x)dx .
f M ( x)
Оценка этого смещения:
( ) ( )
( )
f M ξ (Mi ) − f ξ (Mi )
1 N
(i )
Δη = ∑ Φ ξ M
.
N i =1
f M ξ (Mi )
∗
( )
253
Несмещенная оценка η*н величины показателя R определяется как
( ) ( ) ⎞⎟ =
( ) ⎟⎠
f M ξ (Mi ) − f ξ (Mi )
1 N⎛
(i )
(i )
⎜
η = η − Δη = ∑ Φ ξ M − Φ ξ M
N i =1 ⎜
f M ξ (Mi )
⎝
f ξ (Mi )
1 N
(i )
= ∑ Φ ξM
,
N i =1
f M ξ (Mi )
*
н
*
( )
∗
( )
( )
( )
( )
в чем легко убедиться, определив величину математического ожидания
⎧
f (ξ M ) ⎫
f ( x)
M η*н = M ⎨Φ (ξ M )
f M ( x)dx =
⎬ = ∫ Φ ( x)
f M (ξ M ) ⎭
f M ( x)
⎩
= ∫ Φ ( x) f ( x)dx = R .
{ }
Таким образом, для получения несмещенной оценки необходимо полученное значение моделируемой функции усреднить с весами
( ) , где
(ξ )
f ξ (Mi )
(i )
M
fM
f ( x) и f M ( x) — известные функции. Очевидно,
что если аппроксимация f M ( x) достаточно хорошая, то это отно-
{ }
шение близко к единице и дисперсия D η*н
{ }
близка к дисперсии
D η* . Если аппроксимация не очень хорошая, то может оказать-
{ }
{ }
ся, что D η*н >> D η* .
Дисперсия несмещенной оценки η*н определяется выражением:
{ }
*
н
D η
( ) ⎫⎪ = 1 D ⎧Φ ξ f (ξ
⎬
⎨ { }
f (ξ
( ) ⎪⎭ N ⎩
⎧⎪ 1 N
f ξ (Mi )
(i )
= D ⎨ ∑ Φ ξM
f M ξ (Mi )
⎪⎩ N i =1
{ }
)⎫
⎬.
M )⎭
M
M
M
Для дисперсии оценки η* можно записать:
1
D {η* } = D {ξ M }.
N
В [77] доказывается, что дисперсия несмещенной оценки стремится к величине дисперсии, которая была бы у оценки η при условии, что случайная величина ξ с плотностью распределения
254
f (x) абсолютно точно моделируется на ЭВМ. Следовательно, аппроксимация плотностей распределений при моделировании случайных чисел на ЭВМ должна осуществляться таким образом, что-
⎧ f (ξ M ) ⎫
⎬ была минимальна исходя из допустимых воз⎩ f M (ξ M ) ⎭
бы D ⎨
можностей аппроксимации. Учитывая, что
⎧ f (ξ M ) ⎫ [ f ( x ) − f M ( x ) ]
D⎨
f M ( x)dx,
⎬=∫
f M2 ( x)
⎩ f M (ξ M ) ⎭
2
можно сделать вывод, что минимальным должен быть интеграл
[ f ( x) − f M ( x)]
2
∫
f M ( x)
255
dx.
СПИСОК ЛИТЕРАТУРЫ
1. Введение всепогодной эксплуатации воздушных судов: Циркуляр ИКАО 121–AN/90, 1974. — 28 с.
2. Временные британские требования к всепогодным операциям
категорий ІІ, ІІІА, ІІІВ. Технический перевод №3918И, МГА, 1976. —
24 с.
3. Временные нормы для установления минимума ІІІА категории (0 × 200м) для посадки магистральных самолетов с ГТД гражданской авиации СССР, МГА, 1973. — 12 с.
4. Единые западно-европейские нормы летной годности. Всепогодные полеты (ЕЗНЛГС-ВП). Технический перевод №466. Источник: JAR-AWO. Публикация издательства управления гражданской
авиации Великобритании, 1985. — 98 с.
5. Инструктивные материалы ИКАО по сертификации систем
автоматической посадки, систем автоматического управления полетом и летной годности: Материалы ИКАО/Технический перевод
№4445-Ф, Регистрационный номер №2503. — М.: 1981. — 68 с.
6. Критерии для утверждения погодных посадочных минимумов
категории ІІІА: Рекомендательный циркуляр федерального авиационного управления США ACN120-28A/Технический перевод
№218. — М.: 1974. — 36 с.
7. Проект инструктивного материала по сертификации систем
автоматической посадки AN 3/36-78/195. Монреаль, ИКАО, 1979. —
18 с.
8. Техническое руководство ИКАО по летной годности. Часть ІІІ.
Раздел 6. Сертификация автоматических систем. Документ ИКАО
№9051-А №986, 1985. — 79 с.
9. Айвазян С.А. Прикладная статистика. Основы моделирования и
первичная обработка данных / С. А. Айвазян, Енюков И.С., Мешалкин Л.Д. — М.: Финансы и статистика, 1983. — 471 с.
10. Белогородский С.Л. Автоматизация управления посадкой самолета / С. Л. Белогородский. — М.: Транспорт, 1972. — 352 с.
256
11. Белогородский С.Л., Зеленков А.А., Мирошниченко О.Г. Вероятностная структура процесса автоматического захода на посадку и
ее применение к оценке точностных характеристик // Наука и техника
гражданской авиации. Серия: Системы навигации, посадки и УВД.
Научно-технический сборник ЦНТИ ГА. — М., 1980. — Вып 1. — с. 3–8.
12. Белогородский С.Л., Зеленков А.А., Мирошниченко О.Г. Оценка
точности автоматического захода на посадку по частоте выходов
траекторных параметров за допустимые пределы // Проблемы повышения безопасности и регулярности полетов в сложных метеоусловиях и автоматизации управления посадкой самолетов ГА. Тр.
ГосНИИ ГА. Вып.189, 1980. — с. 26–31.
13. Бендат Дж. Измерение и анализ случайных процессов /
Дж. Бендат, А. Пирсол. Перевод с английского Г.В. Матушевского
и В.Е. Привальского. — М.: Мир, 1974. — 464 с.
14. Большев Л.Н. Таблицы математической статистики / Л.Н.
Большев, Н.В. Смирнов. — М.: Наука, 1983. — 416 с.
15. Бортовая телеметрическая аппаратура космических летательных аппаратов / С.М. Переверткин, А.В. Кантор, Н.Ф. Бородин
и др. — М.: Машиностроение, 1977. — 208 с.
16. Браунли К.А. Статистическая теория и методология в науке и
технике / К.А. Браунли: пер. с англ. М.С. Никулина: под ред. Л.Н. Большева. — М.: Наука, 1977. — 407 с.
17. Вентцель Е.С. Курс теории случайных процессов / Е.С. Вентцель. — М.: Наука, 1975. — 318 с.
18. Вероятностные методы в вычислительной технике: Учеб.
пособие для вузов по спец. ЭВМ / А.В. Крайников, Б.А. Курдиков,
А.Н. Лебедев и др. — М.: Высш. шк., 1986. — 312 с.
19. Видуев Н.Г., Кондра Г.С. Вероятностно-статистический анализ погрешностей измерений / Н.Г. Видуев, Г.С. Кондра. — М.: Недра, 1969. — 320 с.
20. Виленкин С.Я. Об оценке среднего в стационарных процессах // В кн.: Теория вероятностей и ее применение. — Т. 4, вып. 4,
1959. — с.451–453.
21. Виленкин С.Я. Статистическая обработка исследований случайных функций / С.Я. Виленкин. — М.: Энергия, 1979. — 320 с.
22. Гаек Я. Теория ранговых критериев / Я. Гаек, З. Шидак: пер.
с англ. Д.М. Чибисова, под ред. Л.Н. Большева. — М.: Наука, 1971. —
376 с.
23. Галушкин А.И. Оперативная обработка экспериментальной
информации / А.И. Галушкин, Ю.Я. Зотов, Ю.А. Шикунов. — М.:
Энергия, 1972. — 360 с.
257
24. Гнеденко Б.В. Курс теории вероятностей / Б.В. Гнеденко. —
М.: Наука, 1969. — 400 с.
25. Грибанов Ю.И. Выборочные оценки спектральных характеристик стационарных случайных процессов / Ю.И. Грибанов, В.Л.
Мальков. — М.: Энергия, 1978. — 152 с.
26. Гумбель Э. Статистика экстремальных значений / Э. Гумбель. — М.: Мир, 1965. — 356 с.
27. Де Гроот М. Оптимальные статистические решения / Де
Гроот М.: пер. с англ. А. Л. Рухина, под ред. Ю.В. Линника и А.М.
Кагана. — М.: Мир, 1974. — 492 с.
28. Дейвид Г. Порядковые статистики / Г. Дейвид: пер. с англ.
В.А. Егорова и В.Б. Невзорова, под ред. В.В. Петрова. — М.: Наука, 1979. — 336 с.
29. Диагностирование и прогнозирование технического состояния авиационного оборудования / под ред. И.М. Синдеева. — М.:
Транспорт, 1984. — 191 с.
30. Домарацкий А.Н. Многоцелевой статистический анализ случайных сигналов / А.Н. Домарацкий, Л.Н. Иванов, Ю.И. Юрлов. —
Новосибирск.: Наука, 1975. — 164 с.
31. Доступов Б.Г. Основы статистических методов исследования нелинейных систем / В кн.: Статистические методы в проектировании нелинейных систем автоматического управления. — М.:
Машиностроение, 1970. — с. 9–23.
32. Доступов Б.Г. Метод эквивалентных возмущений / В кн.: Статистические методы в проектировании нелинейных систем автоматического управления. — М.: Машиностроение, 1970. — с. 97–123.
33. Дунин-Барковский Н.В. Теория вероятностей и математическая статистика в технике (общая часть) / Н.В. Дунин-Барковский,
Н.В. Смирнов. — М.: ГИТТЛ, 1955. — 548 с.
34. Ермаков С.М. Метод Монте–Карло и смежные вопросы /
С.М. Ермаков. — М.: Наука, 1971. — 328с.
35. Закс Ш. Теория статистических выводов / Ш. Закс: пер. с англ.
Е.В. Чепурина, под ред. Ю.К. Беляева. — М.: Мир, 1975. — 776 с.
36. Зеленков А.А. Алгоритмы оценки точностных характеристик
автоматизированного взлета и посадки на участках стабилизации //
Проблеми підвищення ефективності інфраструктури.: зб. наук.
праць: Випуск 8. — К.: НАУ, 2002. — 73–78.
37. Зеленков А.А. Алгоритмы оценки соответствия точностных
характеристик системы автоматического приземления заданным
требованиям // Електроніка та системи управління. — К.: 2004. —
№2. — с. 59–66.
258
38. Зеленков А.А., Голик А.П. Количественная оценка объемов
испытаний отказоустойчивых систем управления // Електроніка та
системи управління. — К.: 2007. — №4. — с. 59–66.
39. Зеленков А.А. Статистические информационные системы оперативного анализа / А.А. Зеленков, С.Ф. Козубовский, Б.С. Синицын. — К.: Наук. думка, 1979. — 180 с.
40. Зеленков О.А., Масловський Б.Г. Розробка інтегрованої системи комп’ютерного моніторингу систем автоматичної посадки літаків на етапі експлуатації // Вісник НАУ. — К.: 2002. — №1. —
с. 107–113.
41. Зеленков А.А., Мирошниченко О.Г., Синицын Б.С. К задаче
статистического анализа точности систем автоматического приземления // Моделирование полета в задачах эксплуатации воздушных
судов гражданской авиации: сб. науч. тр. — К.: КИИГА, 1985. —
с. 91–96.
42. Кендалл М. Дж., Стьюарт А. Статистические выводы и связи / пер. с англ. Э.Л. Пресмана, под ред. А.Н. Колмогорова и Ю.В.
Прохорова. — М.: Наука, 1973. — 900 с.
43. Коваленко И.Н. Краткий курс теории случайных процессов /
И.Н. Коваленко, О.В. Сарманов. — К.: Выща шк., 1978. — 264 с.
44. Корн Г. Справочник по математике (для научных работников и инженеров) / Г. Корн, Т. Корн. Перевод со второго американского переработанного издания И.Г. Арамановича А.М. Березмана. —
М.: Наука, 1977. — 832 с.
45. Котельников Г.Н. Динамика и безопасность полетов / Г.Н.
Котельников, Н.М. Лысенко, М.И. Радченко. — К.: Выща шк.,
1989. — 336 с.
46. Котик М.Г. Динамика взлета и посадки самолетов / М.Г. Котик. — М.: Машиностроение, 1984. — 206 с.
47. Крамер Г. Математические методы статистики / Г. Крамер:
пер. с англ. А.С. Монина и А.А. Петрова под ред. А.Н. Колмогорова. — М.: Мир, 1975. — 648 с.
48. Кринецкий Е.И. Летные испытания систем управления летательными аппаратами / Е.И. Кринецкий, Л.Н. Александровская. —
М.: Машиностроение, 1975. — 192 с.
49. Левин Б.Р. Теоретические основы статистической радиотехники. Книга первая. — М.: Сов. Радио, 1969. — 752 с.
50. Левин Б.Р. Теоретические основы статистической радиотехники / Б.Р. Левин. Кн. ІІ. — М.: Сов. Радио, 1968. — 504 с.
51. Леман Э. Проверка статистических гипотез / Э. Леман: пер. с
англ. Ю.В. Прохорова. — М.: Наука, 1979. — 408 с.
259
52. Летные испытания ракет и космических аппаратов: учебное
пособие для технических вузов / Е.И. Кринецкий, Л.Н. Александровская, А.В. Шаронов, А.С. Голубков. — М.: Машиностроение,
1979. — 464 с.
53. Летные испытания систем пилотажно — навигационного
оборудования / Е.Г. Харин, П.М. Цветков, В.К. Волков и др. — М.:
Машиностроение, 1986. — 136 с.
54. Лукашин Ю.П. Адаптивные методы краткосрочного прогнозирования / Ю.П. Лукашин. — М.: Статистика, 1979. — 254 с.
55. Масловський Б.Г., Зеленков О.А. Прогнозування точнісних
характеристик систем автоматичної посадки літаків // Вісник НАУ. —
К.: 2002. — №4. — с. 88–95.
56. Метод статистических испытаний / под ред. Ю.А. Шрейдера. — М.: Физматгиз, 1962. — 331 с.
57. Методология летных испытаний пилотажно — навигационного оборудования самолетов и вертолетов / Д.Е. Новодворский,
Г.И. Поярков, Е.Г. Харин [и др.]. — М.: Машиностроение, 1984. —
136 с.
58. Мирский Г.Я. Аппаратурное определение характеристик случайных процессов / Г.Я. Мирский. — М.: Энергия, 1972. — 456 с.
59. Моррис У. Наука об управлении. Байесовский подход /
У. Моррис. — М.: Мир, 1971. — 304 с.
60. Натурный эксперимент: Информационное обеспечение экспериментальных исследований / А.Н. Белюнов, Г.М. Солодихин,
В.А. Солодовников [и др.]. — М.: Радио и связь, 1982. — 304 с.
61. Поцелуев А.В. Статистический анализ и синтез сложных динамических систем / А.В. Поцелуев. — М.: Машиностроение, 1984. —
208 с.
62. Прохоров Ю.В. Теория вероятностей: Основные понятия. Предельные теоремы. Случайные процессы / Ю.В. Прохоров, Ю.А. Розанов. — М.: Наука, 1973. — 494 с.
63. Пугачев В.С. Теория вероятностей и математическая статистика / В.С. Пугачев. — М.: Наука, 1979. — 496 с.
64. Райфа Г., Шлейфер Р. Прикладная теория статистических
решений. Перевод с английского Л.К. Звонкина, З.Г. Маймина под
редакцией Ю.Н. Благовещенского. — М.: Статистика, 1977. —
307 с.
65. Рао С.Р. Линейные статистические методы и их применение /
Пер. с англ. А.М. Кагана, В.М. Калинина и К.М. Латышева, под
ред. Ю.В. Линника — М.: Наука, 1968. — 548 с.
260
66. Синицын Б.С., Белогородский, Зеленков А.А., Мирошниченко О.Г.
Применение методов математической статистики для анализа точности бортовых систем автоматизированного управления // Измерения, контроль и автоматизация (ИКА). — М.: 1981. — №3(37). —
с. 43–53.
67. Соболь И. М. Численные методы Монте-Карло / И. М. Соболь. — М.: Наука, 1970. — 311 с.
68. Тихонов В.И. Выбросы случайных процессов / В.И. Тихонов. —
М.: Наука, 1970. — 392 с.
69. Уилкс С. Математическая статистика / С. Уилкс. — М.: Наука, 1967. — 632 с.
70. Фомин Я.А. Теория выбросов случайных процессов / Я.А.
Фомин. — М.: Связь, 1980. — 212 с.
71. Френкель А.А. Прогнозирование производительности труда:
методы и модели. — М.: Экономика, 1989. — 214 с.
72. Химмельблау Д. Анализ процессов статистическими методами. — М.: Мир, 1973. — 957 с.
73. Холлендер М., Вулф Д.А. Непараметрические методы статистики / М. Холлендер, Д.А. Вулф: пер. с англ. Д.С. Шмерлинга, под
ред. Ю.П. Адлера и Ю.Н. Тюрина. — М.: Финансы и статистика,
1983. — 520 с.
74. Цветков Э.И. Основы теории статистических измерений /
Э.И. Цветков. — Л.: Энергия, 1979. — 288 с.
75. Чернецкий В.И. Анализ точности нелинейных систем управления / В.И. Чернецкий. — М.: Машиностроение, 1969. — 346 с.
76. Чернецкий В.И. Интерполяционный метод анализа точности
систем автоматического регулирования при случайных воздействиях //
Aвтоматика и телемеханика. — М.: 1960. — №4. — с.481 — 488.
77. Шаракшанэ А.С. Сложные системы / А.С. Шаракшанэ, И.Г. Железнов, В.А. Ивницкий. — М.: Высш. шк., 1977. — 248 с.
78. Ширяев А.Н. Статистический последовательный анализ. Оптимальные правила остановки / А.Н. Ширяев. — М.: Наука, 1976. —
272 с.
79. Anderson T., Lee P.A. Fault Tolerance. Principles and Practice. —
New Jersey: Prentice Hall, 1981. — 369 p.
80. Dantzig G.B. On the Non-existence of Tests of “Student’s” Hypothesis Having Power Functions Independent of σ // Ann. Math. Stat.
11, 1940. — pp. 186–192.
81. Levene H. Robust Tests for Equality of Variances. In: Contributions to Probability and Statistics, Stanford University Press. 1960, —
pp. 278–292.
261
82. Shakarian A. Application of Monte — Karlo Techniques to the
757 / 767 Autoland Dispersion Analysis by Simulation // AIAA Guidance and Control Conference. A Collection of Technical Papers, N. —
Y., 1983, — pp. 181–194.
83. Siegel S., Tukey J.W. A Nonparametric Sum of Ranks Procedure
for Relative Spread in Unpaired Samples. — J. Amer. Statist. Ass.,
1960. — pp. 429–445.
84. Stein C. A Two — Samples Test for a Linear Hypothesis Whose
Power Is Independent of the Variance // Ann. Math. Stat. 16, 1945. —
pp. 243–258.
262
Наукове видання
ЗЕЛЕНКОВ Олександр Аврамович
СИНЄГЛАЗОВ Віктор Михайлович
БОРТОВІ СИСТЕМИ
АВТОМАТИЧНОГО КЕРУВАННЯ.
ОЦІНКА ТОЧНОСТІ ЗА РЕЗУЛЬТАТАМИ
ВИПРОБУВАНЬ
Монографія
(Російською мовою)
В авторській редакції
Технічний редактор А. І. Лавринович
Верстка О. М. Іваненко
263
Підп. до друку 08.12.09. Формат 60×84/16. Папір офс.
Офс. друк. Ум. друк. арк. 15,34. Обл.-вид. арк. 16,5.
Тираж 100 пр. Замовлення № 298-1
Видавництво Національного авіаційного університету «НАУ-друк»
03680, Київ-58, просп. Космонавта Комарова, 1
Свідоцтво про внесення до Державного реєстру ДК № 977 від 05.07.2002
Тел. (044) 406-78-28. Тел./факс: (044) 406-71-33
E-mail: publish@nau.edu.ua
264